
 Périphériques technologiques
IA
Percée importante ! L'équipe de l'Université de Westlake et le deuxième hôpital du Zhejiang ont réalisé conjointement le décodage chinois de l'interface cerveau-ordinateur
Périphériques technologiques
IA
Percée importante ! L'équipe de l'Université de Westlake et le deuxième hôpital du Zhejiang ont réalisé conjointement le décodage chinois de l'interface cerveau-ordinateur
Percée importante ! L'équipe de l'Université de Westlake et le deuxième hôpital du Zhejiang ont réalisé conjointement le décodage chinois de l'interface cerveau-ordinateur

L'équipe du professeur Mohammed Sawan de l'Advanced Neural Chip Center, l'équipe du professeur Zhang Yue et l'équipe du professeur Zhu Junming du Natural Language Processing Laboratory ont publié conjointement leurs derniers résultats de recherche : "Une communication cérébrale-phrase haute performance conçue pour le langage logosyllabique" Cette recherche réalise un décodage chinois à spectre complet par interface cerveau-ordinateur, qui comble dans une certaine mesure le vide de la technologie internationale d'interface cerveau-ordinateur de décodage chinois.

L'interface cerveau-ordinateur (BCI) est reconnue comme le principal champ de bataille pour l'intersection et l'intégration futures des sciences de la vie et des technologies de l'information. Il s'agit d'une direction de recherche ayant une valeur sociale importante et une importance stratégique.
La technologie d'interface cerveau-ordinateur fait référence à la création d'un chemin de connexion pour l'échange d'informations entre le cerveau humain ou animal et des appareils externes. Son essence est un nouveau type de canal de transmission d'informations qui permet aux informations de contourner les voies musculaires et nerveuses périphériques d'origine. parvenir à la communication avec le cerveau. La connexion avec le monde extérieur remplace ainsi dans une certaine mesure le mouvement humain, le langage et d’autres fonctions.
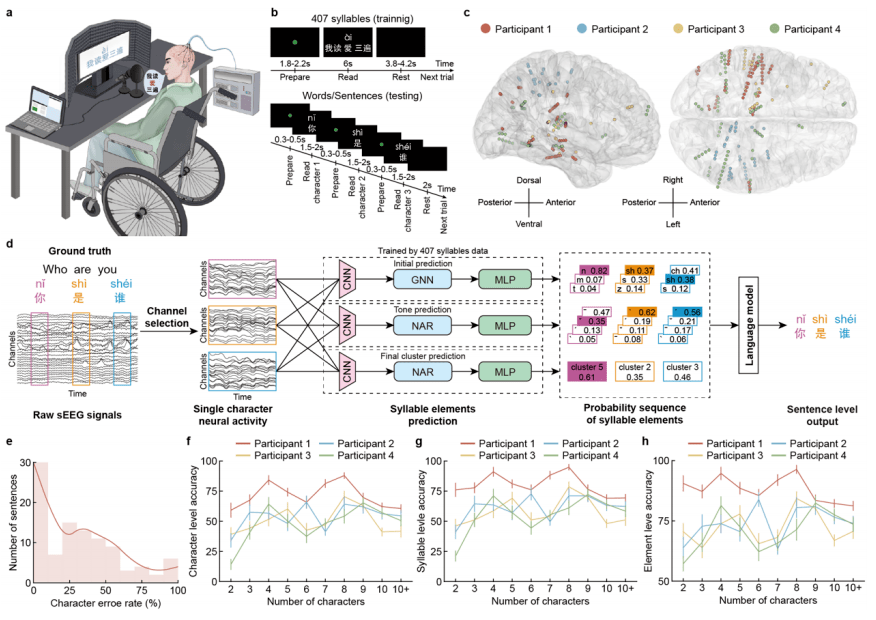 Conception et performances d'un décodeur chinois à spectre complet d'interface cerveau-ordinateur
Conception et performances d'un décodeur chinois à spectre complet d'interface cerveau-ordinateur
En août de cette année, deux articles consécutifs de Nature ont démontré le pouvoir des interfaces cerveau-ordinateur dans la récupération du langage. Cependant, la plupart des technologies d’interface langage cerveau-ordinateur existantes sont conçues pour les systèmes linguistiques alphabétiques tels que l’anglais, et la recherche sur les systèmes d’interface langage cerveau-ordinateur pour les systèmes non alphabétiques tels que les caractères chinois est encore vierge.
Dans cette étude, l'équipe de recherche a utilisé l'électroencéphalographie stéréotaxique (SEEG) pour collecter des signaux d'activité neuronale dans le cerveau correspondant au processus de prononciation de tous les caractères chinois mandarin, et les a combinés avec des algorithmes d'apprentissage profond et des modèles linguistiques pour parvenir à décoder le spectre complet de Prononciation des caractères chinois. Un système d'interface cerveau-ordinateur chinois couvrant la prononciation de tous les caractères chinois mandarin a été établi, permettant d'obtenir une sortie de bout en bout de l'activité cérébrale pour compléter des phrases en mandarin.
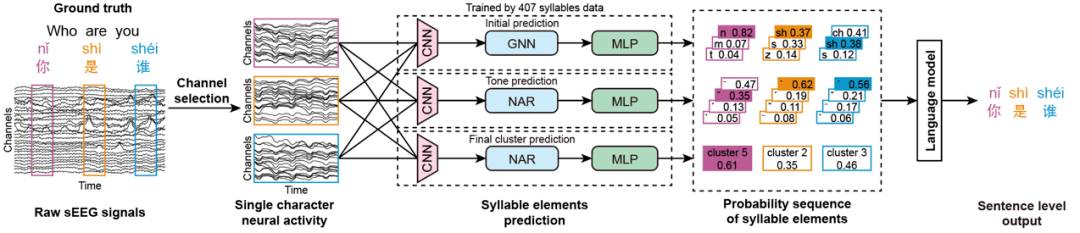
Le chinois, en tant que langue qui combine des pictogrammes et des syllabes, compte plus de 50 000 caractères, ce qui est très différent de l'anglais, qui est composé de 26 lettres. Il s'agit donc d'un énorme défi pour les systèmes d'interface cerveau-ordinateur existants. Afin de résoudre ce problème, au cours des trois dernières années, l’équipe de recherche a mené une analyse approfondie des règles de prononciation et des caractéristiques de la langue chinoise elle-même. À partir des trois éléments que sont les consonnes initiales, les tons et les finales des syllabes de prononciation chinoise, et en combinant les caractéristiques du système de saisie Pinyin, un nouveau système d'interface cerveau-ordinateur de langue adapté au chinois a été conçu. L'équipe de recherche a construit une base de données vocale-SEEG chinoise de plus de 100 heures en concevant une base de données vocale couvrant les 407 syllabes chinoises du pinyin et les caractéristiques de prononciation chinoise et en collectant simultanément des signaux EEG. Grâce à la formation d'un modèle d'intelligence artificielle, le système a construit un modèle de prédiction pour les trois éléments des syllabes de prononciation des caractères chinois (y compris les consonnes initiales, les tons et les finales), et a finalement intégré tous les éléments prédits via un modèle linguistique, combinant des informations sémantiques pour générer le plus probable. Complétez des phrases en chinois.
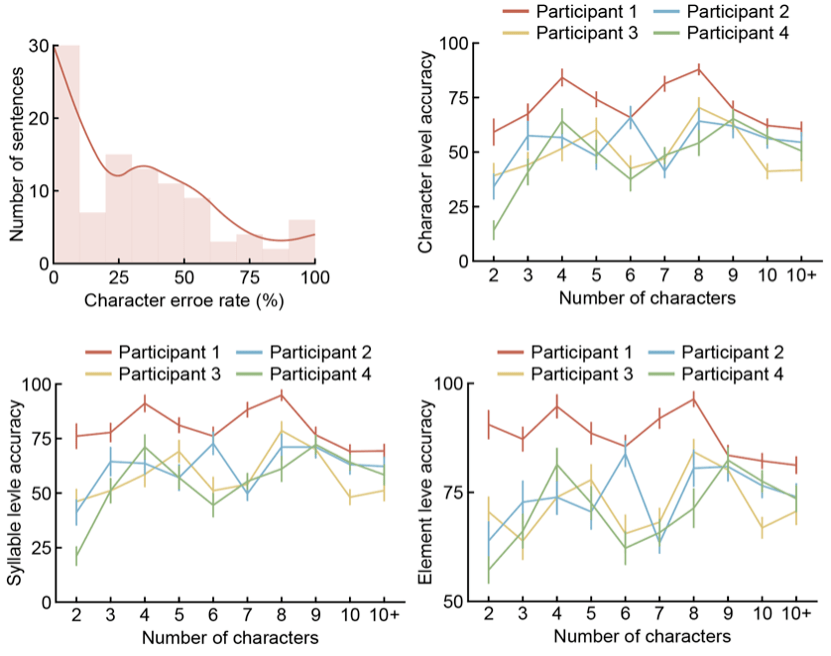
L'équipe de recherche a évalué la capacité de décodage de ce système d'interface cerveau-ordinateur dans un environnement chinois quotidien simulé. Après plus de 100 tests de décodage de scènes de communication complexes sélectionnés au hasard de 2 à 15 caractères, le taux d'erreur médian sur les caractères de tous les participants n'était que de 29 %, et certains participants ont obtenu des phrases complètement correctes grâce au décodage EEG. Les performances de décodage relativement efficaces bénéficient des excellentes performances des trois décodeurs d’éléments syllabiques indépendants et de la parfaite coopération du modèle de langage intelligent. En particulier, en termes de classification de 21 consonnes initiales, la précision du décodeur de consonnes initiales dépasse 40 % (plus de 3 fois la ligne de base), et le taux de précision du Top 3 atteint presque 100 % tandis que le décodeur de tonalité est utilisé pour distinguer 4 tonalités ; La précision a également atteint 50 % (plus de 2 fois la valeur de référence). En plus des contributions exceptionnelles des trois décodeurs d'éléments syllabiques indépendants, les puissantes capacités de correction automatique des erreurs et les capacités de connexion contextuelle du modèle de langage intelligent rendent également les performances de l'ensemble du système d'interface cerveau-ordinateur du langage encore plus remarquables.
Cette recherche offre une nouvelle perspective pour l'étude du décodage BCI du chinois, une langue phonétique, et prouve également que les performances des systèmes d'interface langage cerveau-ordinateur peuvent être considérablement améliorées grâce à de puissants modèles de langage, ouvrant la voie à de futures recherches sur les prothèses neuronales du langage phonétique. .une nouvelle direction. Ces travaux indiquent également que les patients atteints de maladies neurologiques pourront bientôt contrôler par leur pensée des phrases chinoises générées par ordinateur et retrouver la capacité de communiquer !
Contenu de référence
https://www.biorxiv.org/content/10.1101/2023.11.05.562313v1.full.pdf
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Meilleurs générateurs d'art AI (gratuit & amp; payé) pour des projets créatifs
Apr 02, 2025 pm 06:10 PM
Meilleurs générateurs d'art AI (gratuit & amp; payé) pour des projets créatifs
Apr 02, 2025 pm 06:10 PM
L'article passe en revue les meilleurs générateurs d'art AI, discutant de leurs fonctionnalités, de leur aptitude aux projets créatifs et de la valeur. Il met en évidence MidJourney comme la meilleure valeur pour les professionnels et recommande Dall-E 2 pour un art personnalisable de haute qualité.
 Début avec Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Début avec Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
META'S LLAMA 3.2: un bond en avant dans l'IA multimodal et mobile Meta a récemment dévoilé Llama 3.2, une progression importante de l'IA avec de puissantes capacités de vision et des modèles de texte légers optimisés pour les appareils mobiles. S'appuyer sur le succès o
 Meilleurs chatbots AI comparés (Chatgpt, Gemini, Claude & amp; plus)
Apr 02, 2025 pm 06:09 PM
Meilleurs chatbots AI comparés (Chatgpt, Gemini, Claude & amp; plus)
Apr 02, 2025 pm 06:09 PM
L'article compare les meilleurs chatbots d'IA comme Chatgpt, Gemini et Claude, en se concentrant sur leurs fonctionnalités uniques, leurs options de personnalisation et leurs performances dans le traitement et la fiabilité du langage naturel.
 Chatgpt 4 o est-il disponible?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o est-il disponible?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 est actuellement disponible et largement utilisé, démontrant des améliorations significatives dans la compréhension du contexte et la génération de réponses cohérentes par rapport à ses prédécesseurs comme Chatgpt 3.5. Les développements futurs peuvent inclure un interg plus personnalisé
 Assistants d'écriture de l'IA pour augmenter votre création de contenu
Apr 02, 2025 pm 06:11 PM
Assistants d'écriture de l'IA pour augmenter votre création de contenu
Apr 02, 2025 pm 06:11 PM
L'article traite des meilleurs assistants d'écriture d'IA comme Grammarly, Jasper, Copy.ai, WireSonic et Rytr, en se concentrant sur leurs fonctionnalités uniques pour la création de contenu. Il soutient que Jasper excelle dans l'optimisation du référencement, tandis que les outils d'IA aident à maintenir le ton
 Choisir le meilleur générateur de voix d'IA: les meilleures options examinées
Apr 02, 2025 pm 06:12 PM
Choisir le meilleur générateur de voix d'IA: les meilleures options examinées
Apr 02, 2025 pm 06:12 PM
L'article examine les meilleurs générateurs de voix d'IA comme Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson et Descript, en se concentrant sur leurs fonctionnalités, leur qualité vocale et leur aptitude à différents besoins.
 Top 7 Système de chiffon agentique pour construire des agents d'IA
Mar 31, 2025 pm 04:25 PM
Top 7 Système de chiffon agentique pour construire des agents d'IA
Mar 31, 2025 pm 04:25 PM
2024 a été témoin d'un simple passage de l'utilisation des LLM pour la génération de contenu pour comprendre leur fonctionnement intérieur. Cette exploration a conduit à la découverte des agents de l'IA - les systèmes autonomes manipulant des tâches et des décisions avec une intervention humaine minimale. Construire
 Comment accéder à Falcon 3? - Analytique Vidhya
Mar 31, 2025 pm 04:41 PM
Comment accéder à Falcon 3? - Analytique Vidhya
Mar 31, 2025 pm 04:41 PM
Falcon 3: un modèle révolutionnaire de grande langue open source Falcon 3, la dernière itération de la célèbre série Falcon de LLMS, représente une progression importante de la technologie de l'IA. Développé par le Technology Innovation Institute (TII), cet ouvert
