
 Périphériques technologiques
IA
SDXL Turbo et LCM ouvrent l'ère de la génération en temps réel de dessins IA : aussi rapides que la saisie, et les images apparaissent instantanément
Périphériques technologiques
IA
SDXL Turbo et LCM ouvrent l'ère de la génération en temps réel de dessins IA : aussi rapides que la saisie, et les images apparaissent instantanément
SDXL Turbo et LCM ouvrent l'ère de la génération en temps réel de dessins IA : aussi rapides que la saisie, et les images apparaissent instantanément

Stability AI a lancé mardi une nouvelle génération de modèle de synthèse d'image - Stable Diffusion XL Turbo, qui a suscité une réponse enthousiaste de la part du public. De nombreuses personnes ont dit qu'utiliser ce modèle pour la génération d'image en texte n'a jamais été aussi simple
Entrez vos idées dans la zone de saisie, SDXL Turbo répondra rapidement et générera le contenu correspondant sans aucune autre opération. Peu importe que vous saisissiez plus ou moins de contenu, cela n'affectera pas sa vitesse


Vous pouvez utiliser des images existantes pour compléter votre création plus en détail. Prenez simplement un morceau de papier blanc et dites à SDXL Turbo que vous voulez un chat blanc. Avant de finir de taper, le petit chat blanc est déjà apparu entre vos mains
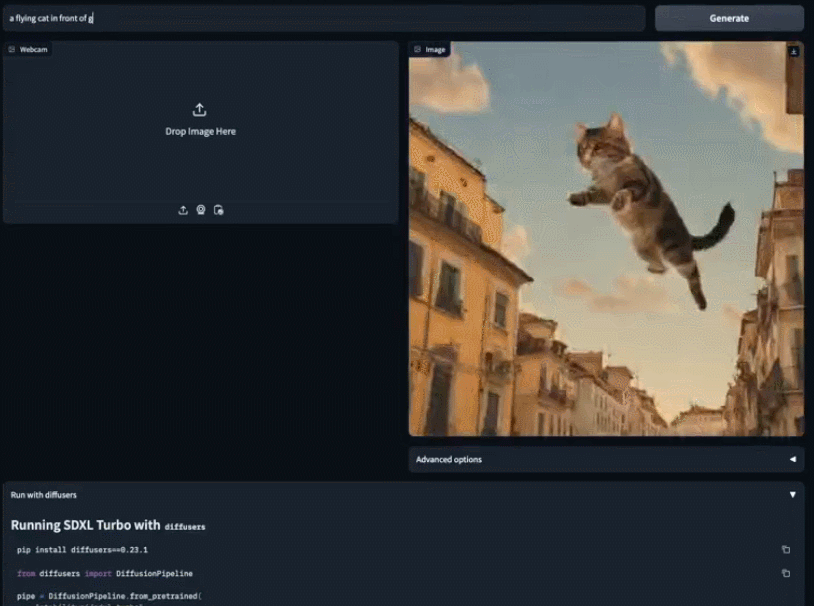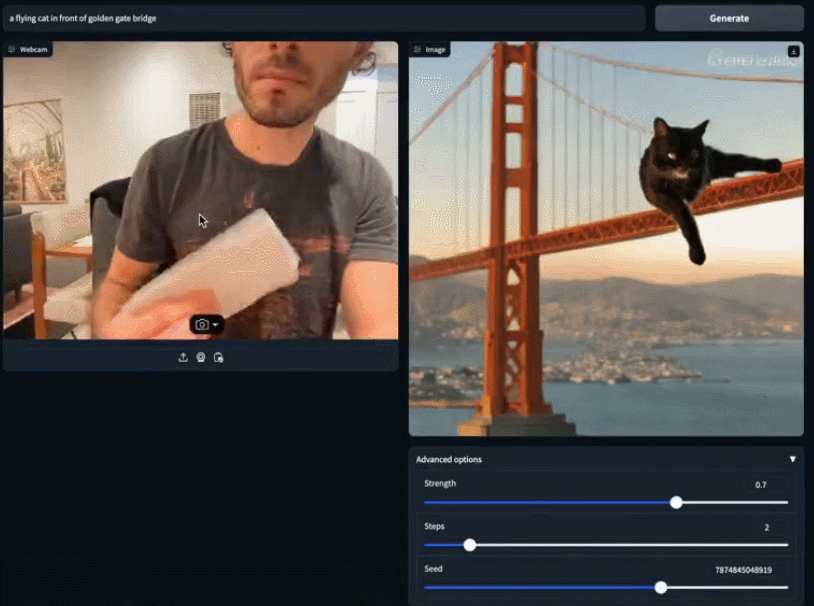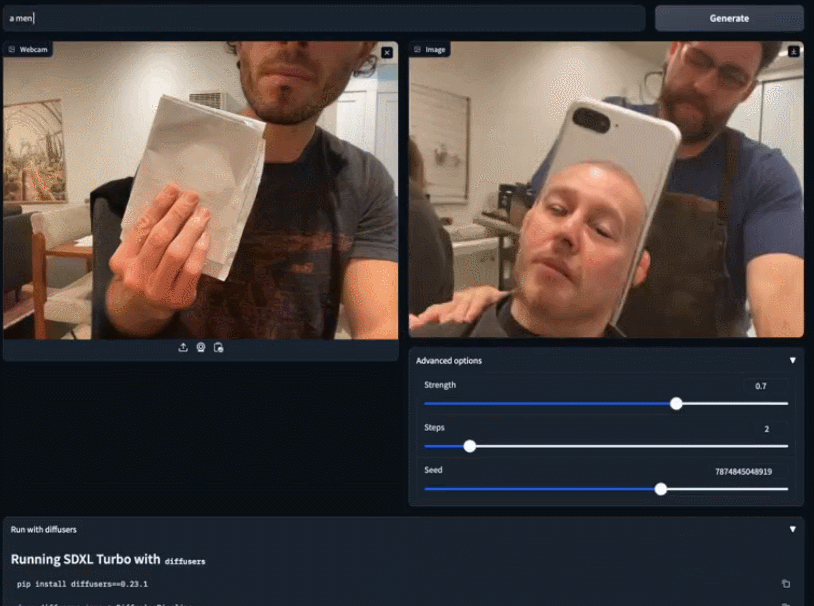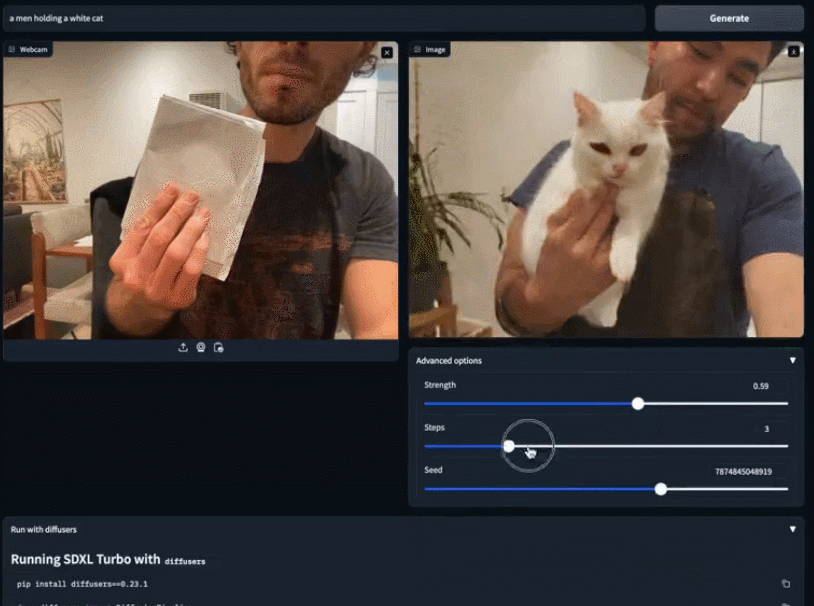
La vitesse du modèle SDXL Turbo atteint C'est. presque « en temps réel », et les gens ne peuvent s'empêcher de se demander : le modèle de génération d'images peut-il être utilisé à d'autres fins ? Quelqu'un directement connecté au jeu et ayant obtenu un écran de transfert de style 2fps :
D'après le officiel Selon le blog, sur l'A100, SDXL Turbo peut générer une image 512x512 en 207 millisecondes (codage à la volée + étape de débruitage unique + décodage, fp16), dont une seule évaluation directe UNet prend 67 millisecondes. 
On peut ainsi juger que Vincent Picture est entré dans l'ère du "temps réel".
Une telle efficacité de « génération instantanée » ressemble quelque peu au modèle Tsinghua LCM qui est devenu populaire il n'y a pas si longtemps, mais le contenu technique derrière eux est différent. Stability a détaillé le fonctionnement interne du modèle dans un document de recherche publié au même moment. La recherche se concentre sur une technologie appelée Distillation par diffusion contradictoire (ADD). L'un des avantages revendiqués de SDXL Turbo est sa similitude avec les réseaux contradictoires génératifs (GAN), en particulier dans la génération de sorties d'images en une seule étape.
Adresse papier : https://static1.squarespace.com/static/6213c340453c3f502425776e/t/65663480a92fba51d0e1023f/1701197769659/adversarial_diffusion_distillation. pdf 
Détails papier
En bref, la distillation par diffusion contradictoire est une méthode générale qui peut réduire le nombre d'étapes d'inférence d'un modèle de diffusion pré-entraîné à 1 à 4 étapes d'échantillonnage tout en maintenant une fidélité d'échantillonnage élevée et en améliorant potentiellement encore les performances globales du modèle.
À cette fin, les chercheurs ont introduit une combinaison de deux objectifs de formation : (i) la perte contradictoire et (ii) la perte de distillation correspondant au SDS. La perte contradictoire oblige le modèle à générer directement des échantillons qui se trouvent sur le collecteur d’images réelles à chaque passage avant, évitant ainsi le flou et d’autres artefacts courants dans d’autres méthodes de distillation. La perte de distillation utilise un autre modèle de diffusion pré-entraîné (et fixe) comme enseignant, exploitant efficacement ses connaissances approfondies et conservant la forte compositionnalité observée dans les grands modèles de diffusion. Au cours du processus d’inférence, les chercheurs n’ont pas utilisé de guidage sans classificateur, réduisant ainsi les besoins en mémoire. Ils conservent la capacité du modèle à améliorer les résultats grâce à un raffinement itératif, un avantage par rapport aux précédentes approches basées sur le GAN en une seule étape.
Les étapes de formation sont présentées dans la figure 2 :
Le tableau 1 montre les résultats de l'expérience d'ablation. Voici les principales conclusions : 
.
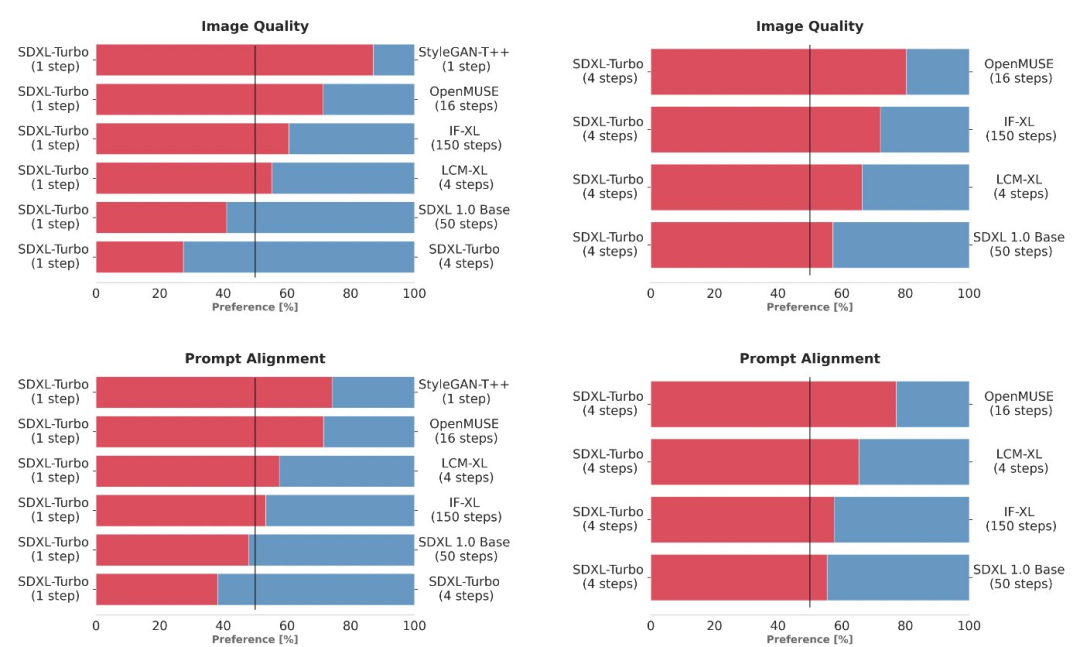
Ce qui suit est une comparaison avec d'autres modèles SOTA. Ici, les chercheurs n'ont pas utilisé d'indicateurs automatisés, mais ont choisi une méthode d'évaluation des préférences des utilisateurs plus fiable, l'objectif étant d'évaluer la conformité rapide et l'image globale.
Pour comparer plusieurs variantes de modèles différentes (StyleGAN-T++, OpenMUSE, IF-XL, SDXL et LCM-XL), l'expérience utilise la même invite pour générer la sortie. Lors de tests à l'aveugle, le SDXL Turbo a battu la configuration en 4 étapes du LCM-XL en une seule étape, et a battu la configuration en 50 étapes du SDXL en seulement 4 étapes. À partir de ces résultats, on peut voir que SDXL Turbo surpasse les modèles multi-étapes de pointe tout en réduisant considérablement les besoins de calcul sans sacrifier la qualité de l'image. tracé des scores
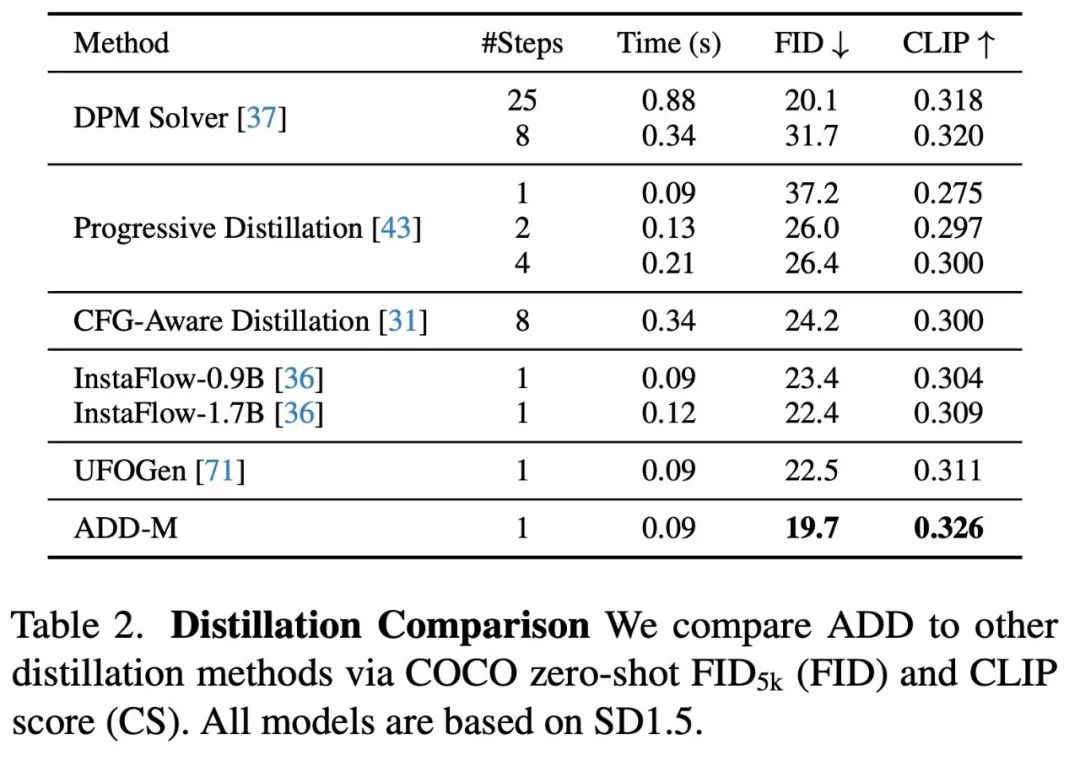
Dans le tableau 2, une comparaison de différentes méthodes d'échantillonnage et de distillation en quelques étapes utilisant le même modèle de base est effectuée. Les résultats montrent que la méthode ADD surpasse toutes les autres méthodes, y compris le solveur DPM standard en 8 étapes

En complément des résultats expérimentaux quantitatifs, l'article montre également des résultats expérimentaux qualitatifs, montrant ADD- Capacité de XL à améliorer les échantillons initiaux. La figure 3 compare ADD-XL (1 étape) avec la meilleure référence actuelle dans les schémas en quelques étapes. La figure 4 décrit le processus d'échantillonnage itératif d'ADD-XL. La figure 8 fournit une comparaison directe d'ADD-XL avec son modèle d'enseignant, SDXL-Base. Comme le montrent les études d'utilisateurs, ADD-XL surpasse le modèle enseignant en termes de qualité et d'alignement rapide.

 Pour plus de détails sur la recherche, veuillez vous référer à l'article original
Pour plus de détails sur la recherche, veuillez vous référer à l'article original
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
