
 Périphériques technologiques
IA
LCM : nouvelle façon de générer des images de haute qualité beaucoup plus rapidement
Périphériques technologiques
IA
LCM : nouvelle façon de générer des images de haute qualité beaucoup plus rapidement
LCM : nouvelle façon de générer des images de haute qualité beaucoup plus rapidement

Auteur丨Mike Young
Traduction : La langue pour recréer le contenu sans changer le sens original est le chinois, et la phrase originale n'a pas besoin d'apparaître
Révisez le contenu, sans changer le sens original, la langue doit être réécrit en chinois, et la phrase originale n'a pas besoin d'apparaître
Recommandé | 51CTO Technology Stack (WeChat ID: blog51cto)
 Pictures
Pictures
En raison de l'émergence d'une nouvelle technologie appelée Latent Consistency Model (LCM), l'IA va inaugurer la transformation du texte en Une avancée majeure dans le domaine graphique. Les méthodes traditionnelles telles que les modèles de diffusion latente (MLD) fonctionnent bien pour générer des images détaillées et créatives à l'aide d'indices textuels, mais leur inconvénient fatal est leur lenteur. Générer une seule image à l'aide de LDM peut nécessiter des centaines d'étapes, ce qui est tout simplement trop lent pour de nombreuses applications pratiques
Réécrit en chinois : LCM change la donne en réduisant le nombre d'étapes nécessaires pour générer une image. Comparé au LDM, qui nécessite des centaines d’étapes pour générer minutieusement des images, le LCM peut produire des résultats de qualité similaire en seulement 1 à 4 étapes. Pour atteindre cette efficacité, LCM affine le LDM pré-entraîné sous une forme plus concise, réduisant ainsi considérablement les ressources et le temps de calcul requis. Nous analyserons un article récent sur le fonctionnement du modèle LDM
L'article présente également une innovation appelée LCM-LoRA, un module d'accélération de diffusion stable à usage général. Ce module peut être branché sur divers modèles affinés Stable--Diffusion sans aucune formation supplémentaire. Il s’agit d’un outil universellement applicable qui peut accélérer diverses tâches de génération d’images, ce qui en fait un outil potentiel pour exploiter l’IA pour créer des images. Nous décortiquerons également cette partie du document.
1. Formation efficace du LCM
Dans le domaine des réseaux de neurones, il existe un défi énorme, qui nécessite une énorme puissance de calcul, en particulier lors de la formation de réseaux de neurones avec des équations complexes. Cependant, l'équipe à l'origine de cet article a réussi à résoudre ce problème en utilisant une méthode ingénieuse appelée raffinement
Contenu réécrit : La méthode de l'équipe de recherche était la suivante : Tout d'abord, ils ont utilisé un ensemble de données d'appariement texte-image pour former un modèle de diffusion latente standard ( LDM). Une fois le LDM opérationnel, ils l’utilisent comme mentor, générant de nouvelles données de formation. Ils ont ensuite utilisé ces nouvelles données pour former un modèle de cohérence latente (LCM). La chose la plus intéressante est que LCM peut apprendre des capacités de LDM sans avoir à s'entraîner à partir de zéro avec d'énormes ensembles de données
Ce qui compte vraiment, c'est l'efficacité de ce processus. Les chercheurs ont terminé la formation d’un LCM de haute qualité en 32 heures environ en utilisant un seul GPU. Ceci est important car c’est beaucoup plus rapide et plus pratique que les méthodes précédentes. Cela signifie que davantage de personnes et de projets peuvent désormais créer de tels modèles avancés, plutôt que uniquement ceux ayant accès aux ressources de calcul intensif.
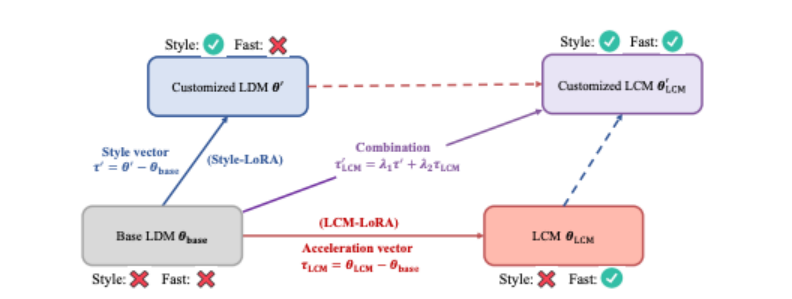 Figure 1, aperçu LCM-LoRA
Figure 1, aperçu LCM-LoRA
En introduisant LoRA dans le processus d'extraction LCM, nous réduisons considérablement la surcharge de mémoire de l'extraction, ce qui nous permet de former des ensembles de données plus volumineux avec des ressources limitées telles que des modèles. SDXL et SSD-1B. Plus important encore, les paramètres LoRA (« vecteurs d'accélération ») obtenus par la formation LCM-LoRA peuvent être directement combinés avec d'autres paramètres LoRA (« vecteurs de style ») obtenus en affinant un ensemble de données pour un style spécifique. Sans aucune formation, le modèle obtenu par la combinaison linéaire du vecteur d'accélération et du vecteur de style acquiert la capacité de générer des images d'un style de peinture spécifique avec un minimum d'étapes d'échantillonnage.
2. Résultats
Cette étude démontre des progrès significatifs dans l'utilisation de l'IA pour générer des images basées sur un modèle de cohérence latente (LCM). LCM excelle dans la création d'images 512 x 512 de haute qualité en seulement quatre étapes, une amélioration significative par rapport aux centaines d'étapes requises par les modèles traditionnels tels que les modèles de diffusion latente (MLD). Les images présentent des détails nets et des textures réalistes, ce qui est particulièrement évident dans les exemples ci-dessous.
 Photos
Photos
Figure 2. L'article affirme : "Images générées à l'aide de modèles de cohérence latente extraits de différents modèles de diffusion pré-entraînés. Nous utilisons LCM-LoRA-SD-V1.5 pour générer une résolution de 512 × 512 images, utilisez LCM-LoRA-SDXL et LCM-LoRA-SSD-1B pour générer des images de résolution 1024×1024 »
Ces modèles gèrent non seulement facilement des images plus petites, mais sont également efficaces pour générer des images plus grandes. Ils démontrent une capacité à s’adapter à des modèles de réseaux neuronaux beaucoup plus grands que ce qui était auparavant possible, démontrant ainsi leur adaptabilité. Dans les exemples de l'article (tels que les exemples des versions LCM-LoRA-SD-V1.5 et LCM-LoRA-SSD-1B), la large applicabilité du modèle dans divers ensembles de données et scénarios pratiques est clarifiée
3 , limites
La version actuelle de LCM présente plusieurs limitations. La chose la plus importante est le processus de formation en deux étapes : d'abord former le LDM, puis l'utiliser pour former le LCM. Dans des recherches futures, une méthode plus directe de formation LDM pourrait être explorée, dans laquelle le LDM pourrait ne pas être nécessaire. L'article traite principalement de la génération d'images inconditionnelles, les tâches de génération conditionnelle (telles que la synthèse texte-image) peuvent nécessiter plus de travail.
4. Principales révélations
Le modèle de cohérence latente (LCM) a franchi une étape importante dans la génération rapide d'images de haute qualité. Ces modèles peuvent produire des résultats comparables à ceux des LDM plus lents en seulement 1 à 4 étapes, révolutionnant potentiellement l'application pratique des modèles texte-image. Bien qu'il existe actuellement certaines limites, notamment en termes de processus de formation et d'étendue de la tâche de génération, le LCM marque une avancée significative dans la génération pratique d'images basées sur les réseaux de neurones. Les exemples fournis mettent en évidence le potentiel de ces modèles
5 LCM-LoRA en tant que module d'accélération général
Comme mentionné dans l'introduction, l'article est divisé en deux parties. La deuxième partie traite de la technologie LCM-LoRA, capable d'affiner les modèles pré-entraînés en utilisant moins de mémoire, améliorant ainsi l'efficacité
L'innovation clé ici est d'intégrer les paramètres LoRA dans LCM, générant ainsi une génération qui combine les avantages des deux modèles hybrides. Cette intégration est particulièrement utile pour créer des images d'un style spécifique ou répondre à une tâche spécifique. Si différents ensembles de paramètres LoRA sont sélectionnés et combinés, chacun étant affiné pour un style unique, les chercheurs ont créé un modèle polyvalent capable de générer des images avec un minimum d'étapes et sans formation supplémentaire.
Ils l'ont démontré dans leurs recherches à travers l'exemple de la combinaison de paramètres LoRA affinés pour des styles de peinture spécifiques avec des paramètres LCM-LoRA. Cette combinaison permet la création d'images de résolution 1 024 × 1 024 avec différents styles à différentes étapes d'échantillonnage (telles que 2 étapes, 4 étapes, 8 étapes, 16 étapes et 32 étapes). Les résultats montrent que ces paramètres combinés peuvent produire des images de haute qualité sans formation supplémentaire, soulignant l'efficacité et la polyvalence de ce modèle.
Une chose à noter ici est l'utilisation de ce que l'on appelle les « vecteurs d'accélération » (τLCM). et « vecteur de style » (τ), les deux sont combinés à l'aide de formules mathématiques spécifiques (λ1 et λ2 sont des facteurs ajustables dans ces formules). Cette combinaison donne naissance à un modèle capable de générer rapidement des images personnalisées.
La figure 3 de l'article (ci-dessous) démontre l'efficacité de cette approche en montrant les résultats d'un style spécifique de paramètres LoRA combinés avec les paramètres LCM-LoRA. Cela démontre la capacité du modèle à générer rapidement et efficacement des images avec différents styles.
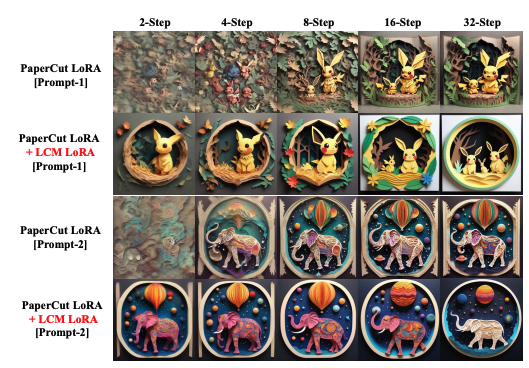 Figure 3
Figure 3
Dans l'ensemble, cette partie de l'article met en évidence la polyvalence et l'efficacité du modèle LCM-LoRA, qui peut être utilisé pour générer rapidement des images de style spécifique de haute qualité, tout en en utilisant seulement quelques ressources informatiques. La technologie a un large éventail d'applications et devrait révolutionner la façon dont les images sont générées dans des domaines allant de l'art numérique à la création automatisée de contenu
6. Conclusion
Nous avons étudié une nouvelle approche, le modèle de cohérence latente (LCM) ), utilisé pour accélérer le processus de génération d’images à partir de texte. Contrairement aux modèles de diffusion latente (MLD) traditionnels, le LCM peut générer des images de qualité similaire en seulement 1 à 4 étapes au lieu de centaines d'étapes. Cette amélioration significative de l'efficacité est obtenue grâce à la méthode de raffinement, qui utilise LDM pré-entraîné pour entraîner LCM, évitant ainsi une grande quantité de calculs
De plus, nous avons également étudié LCM-LoRA, qui est une méthode qui utilise de faibles Rank Technique d'augmentation adaptative (LoRA) qui affine les modèles pré-entraînés pour réduire les besoins en mémoire. Cette méthode d'ensemble peut créer des styles d'images spécifiques avec un minimum d'étapes de calcul sans nécessiter de formation supplémentaire.
Les principaux résultats mis en évidence incluent la capacité de LCM à créer des images 512 x 512 et 1 024 x 1 024 de haute qualité en quelques étapes seulement, tandis que LDM nécessite des centaines d'étapes. Cependant, la limitation actuelle est que LDM repose sur un processus de formation en deux étapes, vous avez donc toujours besoin de LDM pour commencer ! Des recherches futures pourraient simplifier ce processus.
LCM est une innovation très intelligente surtout lorsqu'elle est combinée avec LoRA dans le modèle LCM-LoRA proposé. Ils offrent l’avantage de créer des images de haute qualité plus rapidement et plus efficacement, et je pense qu’ils ont de larges perspectives d’application dans la création de contenu numérique.
Lien de référence : https://notes.aimodels.fyi/lcm-lora-a-new-method-for-generating-high-quality-images-much-faster/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment effacer l'historique des images récentes de l'arrière-plan du bureau dans Windows 11
Apr 14, 2023 pm 01:37 PM
Comment effacer l'historique des images récentes de l'arrière-plan du bureau dans Windows 11
Apr 14, 2023 pm 01:37 PM
<p>Windows 11 améliore la personnalisation du système, permettant aux utilisateurs d'afficher un historique récent des modifications précédemment apportées à l'arrière-plan du bureau. Lorsque vous entrez dans la section de personnalisation de l'application Paramètres système Windows, vous pouvez voir diverses options, la modification du fond d'écran en fait partie. Mais vous pouvez maintenant voir le dernier historique des fonds d’écran définis sur votre système. Si vous n'aimez pas voir cela et souhaitez effacer ou supprimer cet historique récent, continuez à lire cet article, qui vous aidera à en savoir plus sur la façon de le faire à l'aide de l'Éditeur du Registre. </p><h2>Comment utiliser la modification du registre
 Comment télécharger l'image de fond d'écran Windows Spotlight sur PC
Aug 23, 2023 pm 02:06 PM
Comment télécharger l'image de fond d'écran Windows Spotlight sur PC
Aug 23, 2023 pm 02:06 PM
Les fenêtres ne négligent jamais l’esthétique. Des champs verts bucoliques de XP au design tourbillonnant bleu de Windows 11, les fonds d’écran par défaut sont une source de plaisir pour les utilisateurs depuis des années. Avec Windows Spotlight, vous avez désormais un accès direct chaque jour à des images magnifiques et impressionnantes pour votre écran de verrouillage et votre fond d’écran. Malheureusement, ces images ne traînent pas. Si vous êtes tombé amoureux de l'une des images phares de Windows, vous voudrez savoir comment les télécharger afin de pouvoir les conserver comme arrière-plan pendant un certain temps. Voici tout ce que vous devez savoir. Qu’est-ce que WindowsSpotlight ? Window Spotlight est un programme de mise à jour automatique du fond d'écran disponible dans Personnalisation et dans l'application Paramètres.
 Comment utiliser la technologie de segmentation sémantique d'images en Python ?
Jun 06, 2023 am 08:03 AM
Comment utiliser la technologie de segmentation sémantique d'images en Python ?
Jun 06, 2023 am 08:03 AM
Avec le développement continu de la technologie de l’intelligence artificielle, la technologie de segmentation sémantique des images est devenue une direction de recherche populaire dans le domaine de l’analyse d’images. Dans la segmentation sémantique d'image, nous segmentons différentes zones d'une image et classons chaque zone pour obtenir une compréhension globale de l'image. Python est un langage de programmation bien connu. Ses puissantes capacités d'analyse et de visualisation de données en font le premier choix dans le domaine de la recherche sur les technologies d'intelligence artificielle. Cet article expliquera comment utiliser la technologie de segmentation sémantique d'images en Python. 1. Les connaissances préalables s’approfondissent
 Comment redimensionner par lots des images à l'aide de PowerToys sous Windows
Aug 23, 2023 pm 07:49 PM
Comment redimensionner par lots des images à l'aide de PowerToys sous Windows
Aug 23, 2023 pm 07:49 PM
Ceux qui doivent travailler quotidiennement avec des fichiers image doivent souvent les redimensionner pour les adapter aux besoins de leurs projets et de leurs tâches. Cependant, si vous avez trop d’images à traiter, les redimensionner individuellement peut prendre beaucoup de temps et d’efforts. Dans ce cas, un outil comme PowerToys peut s'avérer utile, entre autres, pour redimensionner par lots des fichiers image à l'aide de son utilitaire de redimensionnement d'image. Voici comment configurer vos paramètres de redimensionnement d'image et commencer le redimensionnement par lots d'images avec PowerToys. Comment redimensionner des images par lots avec PowerToys PowerToys est un programme tout-en-un doté d'une variété d'utilitaires et de fonctionnalités pour vous aider à accélérer vos tâches quotidiennes. L'un de ses utilitaires est les images
 iOS 17 : Comment utiliser le recadrage en un clic des photos
Sep 20, 2023 pm 08:45 PM
iOS 17 : Comment utiliser le recadrage en un clic des photos
Sep 20, 2023 pm 08:45 PM
Avec l'application iOS 17 Photos, Apple facilite le recadrage des photos selon vos spécifications. Lisez la suite pour savoir comment. Auparavant, dans iOS 16, le recadrage d'une image dans l'application Photos impliquait plusieurs étapes : appuyez sur l'interface d'édition, sélectionnez l'outil de recadrage, puis ajustez le recadrage à l'aide d'un geste de pincement pour zoomer ou en faisant glisser les coins de l'outil de recadrage. Dans iOS 17, Apple a heureusement simplifié ce processus afin que lorsque vous zoomez sur une photo sélectionnée dans votre bibliothèque Photos, un nouveau bouton Recadrer apparaisse automatiquement dans le coin supérieur droit de l'écran. En cliquant dessus, l'interface de recadrage complète s'affichera avec le niveau de zoom de votre choix. Vous pourrez ainsi recadrer la partie de l'image que vous aimez, faire pivoter l'image, inverser l'image, appliquer un rapport d'écran ou utiliser des marqueurs.
 Utilisez des images 2D pour créer un corps humain en 3D. Vous pouvez porter n'importe quel vêtement et modifier vos mouvements.
Apr 11, 2023 pm 02:31 PM
Utilisez des images 2D pour créer un corps humain en 3D. Vous pouvez porter n'importe quel vêtement et modifier vos mouvements.
Apr 11, 2023 pm 02:31 PM
Grâce au rendu différenciable fourni par NeRF, les modèles génératifs 3D récents ont obtenu des résultats époustouflants sur des objets stationnaires. Cependant, dans une catégorie plus complexe et déformable comme le corps humain, la génération 3D pose encore de grands défis. Cet article propose une représentation NeRF combinée efficace du corps humain, permettant la génération de corps humain 3D haute résolution (512 x 256) sans utiliser de modèles de super-résolution. EVA3D a largement surpassé les solutions existantes sur quatre ensembles de données du corps humain à grande échelle, et le code est open source. Nom de l'article : EVA3D : Génération humaine compositionnelle en 3D à partir de collections d'images 2D Adresse de l'article : http
 Une nouvelle perspective sur la génération d'images : discussion des méthodes de généralisation basées sur NeRF
Apr 09, 2023 pm 05:31 PM
Une nouvelle perspective sur la génération d'images : discussion des méthodes de généralisation basées sur NeRF
Apr 09, 2023 pm 05:31 PM
La nouvelle génération d'images en perspective (NVS) est un domaine d'application de la vision par ordinateur. Dans le jeu SuperBowl de 1998, le RI de la CMU a démontré la vision stéréo multi-caméras (MVS). À cette époque, cette technologie a été transférée à une chaîne de télévision sportive du pays. États-Unis, mais il n’a finalement pas été commercialisé ; la société britannique BBC Broadcasting a investi dans la recherche et le développement à cet effet, mais il n’a pas été véritablement commercialisé. Dans le domaine du rendu basé sur l'image (IBR), il existe une branche des applications NVS, à savoir le rendu basé sur l'image en profondeur (DBIR). De plus, la télévision 3D, qui était très populaire en 2010, devait également obtenir des effets stéréoscopiques binoculaires à partir de la vidéo monoculaire, mais en raison de l'immaturité de la technologie, elle n'est finalement pas devenue populaire. A cette époque, des méthodes basées sur l’apprentissage automatique commençaient déjà à être étudiées, comme
 Effacez les imperfections et les rides en un clic : interprétation approfondie du modèle de beauté de la peau haute définition ABPN de la DAMO Academy
Apr 12, 2023 pm 12:25 PM
Effacez les imperfections et les rides en un clic : interprétation approfondie du modèle de beauté de la peau haute définition ABPN de la DAMO Academy
Apr 12, 2023 pm 12:25 PM
Avec le développement vigoureux de l’industrie de la culture numérique, la technologie de l’intelligence artificielle a commencé à être largement utilisée dans le domaine de l’édition et de l’embellissement d’images. Parmi elles, l’embellissement de la peau en portrait est sans aucun doute l’une des technologies les plus utilisées et les plus demandées. Les algorithmes de beauté traditionnels utilisent une technologie d'édition d'images basée sur des filtres pour obtenir des effets automatisés de resurfaçage de la peau et d'élimination des imperfections, et ont été largement utilisés dans les réseaux sociaux, les diffusions en direct et d'autres scénarios. Cependant, dans le secteur de la photographie professionnelle, où les seuils sont élevés, en raison des exigences élevées en matière de résolution d'image et de normes de qualité, les retoucheurs manuels restent la principale force productive dans la retouche beauté des portraits, accomplissant des tâches telles que le lissage de la peau, l'élimination des imperfections, le blanchiment, etc. travail. Habituellement, le temps de traitement moyen nécessaire à un retoucheur professionnel pour effectuer des opérations d'embellissement de la peau sur un portrait haute définition est de 1 à 2 minutes. Dans des domaines tels que la publicité, le cinéma et la télévision, qui nécessitent une plus grande précision.
