
 Périphériques technologiques
IA
Multipliez par 40 les performances d'inférence de grands modèles à l'aide de la boîte à outils
Périphériques technologiques
IA
Multipliez par 40 les performances d'inférence de grands modèles à l'aide de la boîte à outils
Multipliez par 40 les performances d'inférence de grands modèles à l'aide de la boîte à outils

Intel® Qu'est-ce que l'extension pour Transformer ?
Intel® Extension for Transformers[1] est une boîte à outils innovante lancée par Intel qui peut être basée sur les plates-formes d'architecture Intel® , en particulier la quatrième génération de processeurs Intel® Xeon® évolutifs (nom de code Sapphire Rapids[2 ], SPR) accélère considérablement le modèle LLM (Large Language Model) basé sur Transformer. Ses principales fonctionnalités incluent :
- Offrir aux utilisateurs une expérience de compression de modèle transparente en étendant l'API des transformateurs Hugging Face[3] et en tirant parti de Intel® Neural Compressor[4]
- Fournir l'utilisation de noyaux de quantification à faible bit ( NeurIPS 2023 : le runtime d'inférence LLM qui implémente une inférence LLM efficace [5] sur le CPU prend en charge Falcon, LLaMA, MPT, Llama2, BLOOM, OPT, ChatGLM2, GPT-J-6B, Baichuan-13B-Base, Baichuan2-13B-Base , LLM courants tels que Qwen-7B, Qwen-14B et Dolly-v2-3B [6] ;
- Exécutions de détection compressées avancées [7] (NeurIPS 2022 : distillation rapide sur CPU et QuaLA-MiniLM : longueur quantifiée auto- Adaptation à MiniLM ; NeurIPS 2021 : élaguez une fois, oubliez ça : clairsemé/élaguez les modèles de langage pré-entraînés).
Cet article se concentrera sur le runtime d'inférence LLM (appelé « runtime LLM ») , et comment utiliser l'API basée sur Transformer pour implémenter un LLM plus efficace sur Intel® Xeon® processeurs évolutifs Raisonnement et comment pour traiter les problèmes d'application du LLM dans les scénarios de chat.
LLM Runtime (LLM Runtime)
Le LLM Runtime[8] fourni par Intel® Extension for Transformers est un runtime d'inférence LLM léger mais efficace, inspiré de GGML[9] et compatible avec lama.cpp[ 10] est compatible et possède les fonctionnalités suivantes :
- Le noyau a été optimisé pour les différentes technologies d'accélération de l'IA intégrées aux Intel® Xeon® CPU (tels qu'AMX, VNNI) et aux jeux d'instructions AVX512F et AVX2 ; Fournit plus d'options de quantification, telles que : différentes granularités (par canal ou par groupe), différentes tailles de groupe (telles que : 32/128) ;
- Possède de meilleures stratégies d'accès au cache KV et d'allocation de mémoire ; inférence dans les systèmes multicanaux.
- Le schéma d'architecture simplifié du LLM Runtime est le suivant :
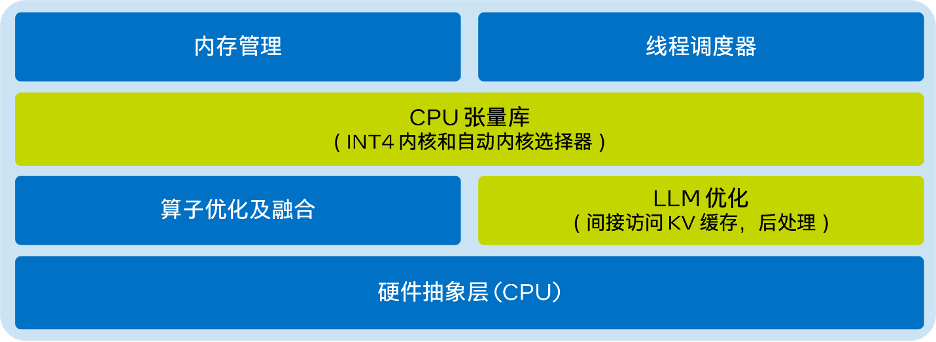 Utilisation basée sur Transformer API, implémentée sur le CPU LLM Efficient Inference
Utilisation basée sur Transformer API, implémentée sur le CPU LLM Efficient Inference
Avec moins de 9 lignes de code, vous pouvez obtenir de meilleures performances d'inférence LLM sur le CPU. Les utilisateurs peuvent facilement activer une API de type Transformer pour la quantification et l'inférence. Définissez simplement « load_in_4bit » sur true et importez le modèle à partir de l’URL HuggingFace ou du chemin local. Un exemple de code pour activer la quantification INT4 uniquement par poids est fourni ci-dessous :
from transformers import AutoTokenizer, TextStreamerfrom intel_extension_for_transformers.transformers import AutoModelForCausalLMmodel_name = "Intel/neural-chat-7b-v3-1” prompt = "Once upon a time, there existed a little girl,"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)inputs = tokenizer(prompt, return_tensors="pt").input_idsstreamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name, load_in_4bit=True)outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
Les paramètres par défaut sont : stocker les poids sur 4 bits, effectuer des calculs sur 8 bits. Mais il prend également en charge différentes combinaisons de types de données de calcul (dtype) et de types de données de poids, et les utilisateurs peuvent modifier les paramètres selon leurs besoins. Un exemple de code expliquant comment utiliser cette fonctionnalité est fourni ci-dessous :
from transformers import AutoTokenizer, TextStreamerfrom intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfigmodel_name = "Intel/neural-chat-7b-v3-1” prompt = "Once upon a time, there existed a little girl,"woq_config = WeightOnlyQuantConfig(compute_dtype="int8", weight_dtype="int4")tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)inputs = tokenizer(prompt, return_tensors="pt").input_idsstreamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name,quantization_cnotallow=woq_config)outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
Test de performances
Après des efforts continus, les performances INT4 du schéma d'optimisation ci-dessus ont été considérablement améliorées. Cet article effectue une comparaison des performances avec llama.cpp sur un système équipé de
Intel® Go (16 x 16 Go DDR5 4 800 MT/s [4 800 MT/s]), BIOS 3A14.TEL2P1, microcode 0x2b0001b0, CentOS Stream 8. Les résultats des tests de performances d'inférence sont présentés dans le tableau ci-dessous, où la taille d'entrée est de 32, la taille de sortie est de 32 et le faisceau est de 1
△Tableau 1. Comparaison des performances d'inférence entre le runtime LLM et llama.cpp (taille d'entrée = 32, taille de sortie = 32, faisceau = 1)
Les résultats des tests de performances d'inférence lorsque la taille d'entrée est de 1024, la taille de sortie est de 32 et le faisceau est de 1. Voir le tableau ci-dessous pour plus de détails : 
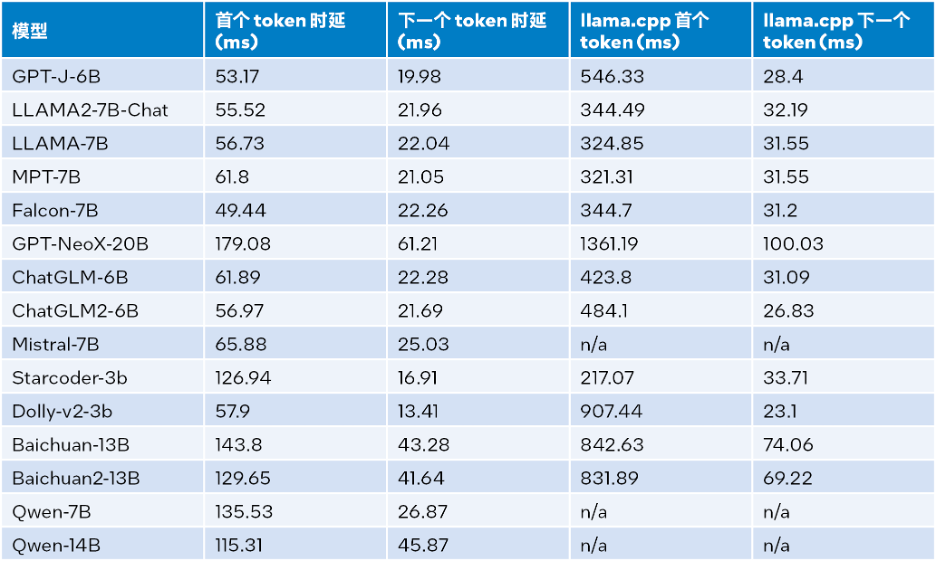
△Tableau 2. Comparaison du temps d'exécution LLM avec les performances d'inférence de llama.cpp (taille d'entrée = 1024, taille de sortie = 32, faisceau = 1)
Selon le tableau 2 ci-dessus : par rapport à llama.cpp fonctionnant également sur le processeur Intel® Xeon® Scalable de quatrième génération, qu'il s'agisse du premier jeton ou du jeton suivant, LLM Runtime peut réduire considérablement le délai et la vitesse d'inférence du premier le jeton et le jeton suivant sont augmentés jusqu'à 40 fois respectivement [a] (Baichuan-13B, l'entrée est 1024) et 2,68 fois [b] (MPT-7B, l'entrée est 1024). Le test de llama.cpp utilise la base de code par défaut [10]. En combinant les résultats des tests du tableau 1 et du tableau 2, on peut conclure que par rapport à llama.cpp fonctionnant également sur le processeur Intel® Xeon® Scalable de quatrième génération, LLM Runtime peut améliorer considérablement de nombreuses performances globales courantes de LLM : la taille d'entrée est de 1024, une amélioration de 3,58 à 21,5 fois est obtenue ; lorsque la taille d'entrée est de 32, une amélioration de 1,76 à 3,43 fois est obtenue
[c]. Test de précision
Intel®Extension for Transformers peut exploiter des méthodes de quantification telles que SignRound[11], RTN et GPTQ[12] dans
Intel®Neural Compressor et utiliser les ensembles de données lambada_openai, piqa, winogrande et hellaswag Inférence INT4 vérifiée précision. Le tableau ci-dessous compare les moyennes des résultats des tests à la précision du FP32.
△Tableau 3. Comparaison de précision entre INT4 et FP32
Comme le montre le tableau 3 ci-dessus, la perte de précision de l'inférence INT4 effectuée par plusieurs modèles basés sur LLM Runtime est très faible et peut presque être ignorée. Nous avons vérifié de nombreux modèles, mais seuls quelques-uns sont répertoriés ici en raison du manque d'espace. Si vous souhaitez plus d'informations ou de détails, veuillez visiter ce lien :
https://medium.com/@NeuralCompressor/llm-performance-of-intel-extension-for-transformers-f7d061556176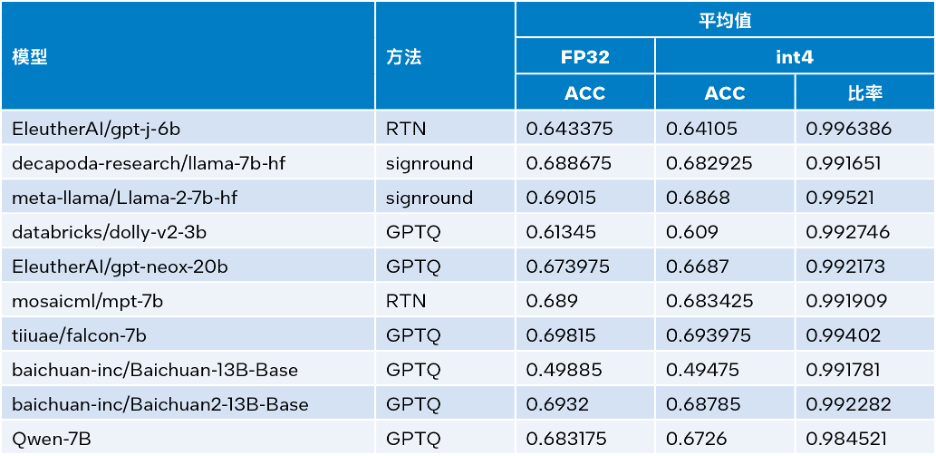 Comme le montre le tableau 3 ci-dessus, la perte de précision de l'inférence INT4 effectuée par plusieurs modèles basés sur LLM Runtime est très faible et peut presque être ignorée. Nous avons vérifié de nombreux modèles, mais seuls quelques-uns sont répertoriés ici en raison du manque d'espace. Si vous souhaitez plus d'informations ou de détails, veuillez visiter ce lien :
Comme le montre le tableau 3 ci-dessus, la perte de précision de l'inférence INT4 effectuée par plusieurs modèles basés sur LLM Runtime est très faible et peut presque être ignorée. Nous avons vérifié de nombreux modèles, mais seuls quelques-uns sont répertoriés ici en raison du manque d'espace. Si vous souhaitez plus d'informations ou de détails, veuillez visiter ce lien : .
Fonctions plus avancées : répondez aux besoins d'application de LLM dans plus de scénariosDans le même temps, LLM Runtime[8] dispose également de la fonction de parallélisation tenseur du processeur double canal, qui est l'un des premiers produits dotés d'une telle fonction. À l’avenir, les nœuds doubles seront davantage pris en charge.
Cependant, l'avantage de LLM Runtime n'est pas seulement ses meilleures performances et sa précision, nous avons également investi beaucoup d'efforts pour améliorer ses fonctionnalités dans les scénarios d'application de chat et résoudre les applications suivantes que LLM peut rencontrer dans les scénarios de chat Dilemme :
Le dialogue ne concerne pas seulement le raisonnement LLM, l'historique du dialogue est également utile. Durée de sortie limitée : la pré-formation du modèle LLM est principalement basée sur une durée de séquence limitée. Par conséquent, sa précision diminue lorsque la longueur de la séquence dépasse la taille de la fenêtre d’attention utilisée lors de la pré-entraînement.
- Inefficacité : pendant la phase de décodage, LLM basé sur Transformer stockera l'état clé-valeur (KV) de tous les jetons générés précédemment, ce qui entraînera une utilisation excessive de la mémoire et une latence de décodage accrue.
- Concernant le premier problème, la fonctionnalité de dialogue de LLM Runtime est résolue en incorporant davantage de données d'historique de dialogue et en générant plus de sorties, ce que lama.cpp n'est pas encore bien équipé pour gérer.
- Concernant les deuxième et troisième questions, nous avons intégré le streaming LLM (Steaming LLM) dans
Extension for Transformers, ce qui peut considérablement optimiser l'utilisation de la mémoire et réduire la latence d'inférence.
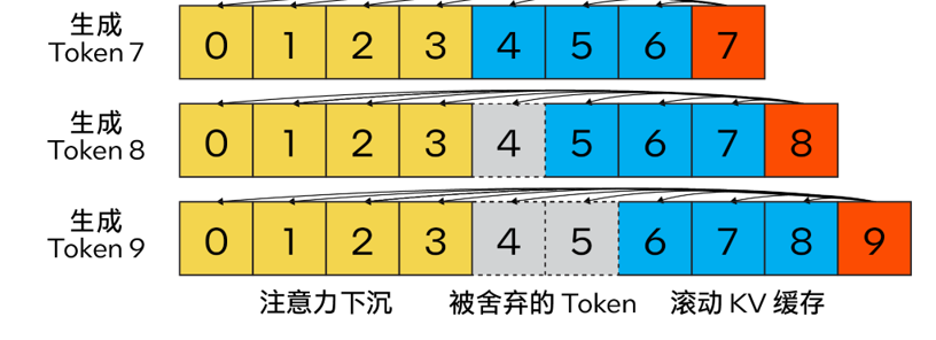
Streaming LLMDifférent de l'algorithme de cache KV traditionnel, notre méthode combine
Attention Sink (4 jetons initiaux)pour améliorer la stabilité du calcul de l'attention et conserve la dernière à l'aide du
rolling KV cache token, qui est crucial pour la modélisation du langage. La conception est très flexible et peut être intégrée de manière transparente dans des modèles de langage autorégressifs capables d'utiliser le codage de position de rotation RoPE et le codage de position relative ALiBi.
Le contenu qui doit être réécrit est : △ Figure 2. Cache KV de Steam LLM utilisant la détection d'attention pour implémenter un modèle de langage de streaming efficace (source de l'image : [13])
De plus, il est différent du lama. cpp , ce plan d'optimisation ajoute également de nouveaux paramètres tels que "n_keep" et "n_discard" pour améliorer la stratégie Streaming LLM. Les utilisateurs peuvent utiliser le paramètre « n_keep » pour spécifier le nombre de jetons à conserver dans le cache KV, et le paramètre « n_discard » pour déterminer le nombre à supprimer parmi les jetons générés. Afin de mieux équilibrer performances et précision, le système supprime par défaut la moitié du dernier numéro de jeton dans le cache KV.
 De plus, il est différent du lama. cpp , ce plan d'optimisation ajoute également de nouveaux paramètres tels que "n_keep" et "n_discard" pour améliorer la stratégie Streaming LLM. Les utilisateurs peuvent utiliser le paramètre « n_keep » pour spécifier le nombre de jetons à conserver dans le cache KV, et le paramètre « n_discard » pour déterminer le nombre à supprimer parmi les jetons générés. Afin de mieux équilibrer performances et précision, le système supprime par défaut la moitié du dernier numéro de jeton dans le cache KV.
De plus, il est différent du lama. cpp , ce plan d'optimisation ajoute également de nouveaux paramètres tels que "n_keep" et "n_discard" pour améliorer la stratégie Streaming LLM. Les utilisateurs peuvent utiliser le paramètre « n_keep » pour spécifier le nombre de jetons à conserver dans le cache KV, et le paramètre « n_discard » pour déterminer le nombre à supprimer parmi les jetons générés. Afin de mieux équilibrer performances et précision, le système supprime par défaut la moitié du dernier numéro de jeton dans le cache KV.Dans le même temps, pour améliorer encore les performances, nous avons également ajouté Streaming LLM au mode de fusion MHA. Si le modèle utilise le codage de position par rotation (RoPE) pour implémenter l'intégration de position, il vous suffit alors d'appliquer une « opération de décalage » au K-Cache existant pour éviter d'effectuer des opérations sur des jetons générés précédemment qui n'ont pas été ignorés. Cette méthode non seulement tire pleinement parti de la taille complète du contexte lors de la génération de texte long, mais n'entraîne pas non plus de surcharge supplémentaire jusqu'à ce que le contexte du cache KV soit complètement rempli.
“shift operation”依赖于旋转的交换性和关联性,或复数乘法。例如:如果某个token的K-张量初始放置位置为m并且旋转了m×θi for i ∈ [0,d/2),那么当它需要移动到m-1这个位置时,则可以旋转回到(-1)×θi for i ∈ [0,d/2)。这正是每次舍弃n_discard个token的缓存时发生的事情,而此时剩余的每个token都需要“移动”n_discard个位置。下图以“n_keep=4、n_ctx=16、n_discard=1”为例,展示了这一过程。

△图3.Ring-Buffer KV-Cache和Shift-RoPE工作原理
需要注意的是:融合注意力层无需了解上述过程。如果对K-cache和V-cache进行相同的洗牌,注意力层会输出几乎相同的结果(可能存在因浮点误差导致的微小差异)。
您可以使用下面的代码来启动Streaming LLM:
from transformers import AutoTokenizer, TextStreamer from intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfig model_name = "Intel/neural-chat-7b-v1-1" # Hugging Face model_id or local model woq_config = WeightOnlyQuantConfig(compute_dtype="int8", weight_dtype="int4") prompt = "Once upon a time, a little girl"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) inputs = tokenizer(prompt, return_tensors="pt").input_ids streamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name, quantization_cnotallow=woq_config, trust_remote_code=True) # Recommend n_keep=4 to do attention sinks (four initial tokens) and n_discard=-1 to drop half rencetly tokens when meet length threshold outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300, ctx_size=100, n_keep=4, n_discard=-1)
结论与展望
本文基于上述实践经验,提供了一个在英特尔® 至强® 可扩展处理器上实现高效的低位(INT4)LLM推理的解决方案,并且在一系列常见LLM上验证了其通用性以及展现了其相对于其他基于CPU的开源解决方案的性能优势。未来,我们还将进一步提升CPU张量库和跨节点并行性能。
欢迎您试用英特尔® Extension for Transformers[1],并在英特尔® 平台上更高效地运行LLM推理!也欢迎您向代码仓库(repository)提交修改请求 (pull request)、问题或疑问。期待您的反馈!
特别致谢
在此致谢为此篇文章做出贡献的英特尔公司人工智能资深经理张瀚文及工程师许震中、余振滔、刘振卫、丁艺、王哲、刘宇澄。
[a]根据表2 Baichuan-13B的首个token测试结果计算而得。
[b]根据表2 MPT-7B的下一个token测试结果计算而得。
[c]当输入大小为1024时,整体性能=首个token性能+1023下一个token性能;当输入大小为32时,整体性能=首个token性能+31下一个token性能。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1209
24
52
1209
24

 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
