



D'une part, toutes les scènes vidéo de l'application Baidu ont été mises à niveau vers une immersion unifiée (haut et bas) forme interactive ; d'autre part, sur la base du grand modèle unifié de Baidu, nous avons intégré l'expérience des données et des recommandations dans tous les scénarios. L'unification de l'interaction et des données permet de mieux réaliser un gagnant-gagnant écologique et de promouvoir le développement à long terme de Baidu Video.
Afin de mieux cultiver les habitudes de consommation vidéo des utilisateurs, nous avons également créé une entrée de premier niveau pour la consommation vidéo (entrée de la barre de navigation inférieure). Si vous êtes intéressé, vous pouvez télécharger l'application Baidu. Si vous avez de bonnes suggestions ou de mauvais cas, vous êtes toujours invités à nous faire part de vos commentaires.
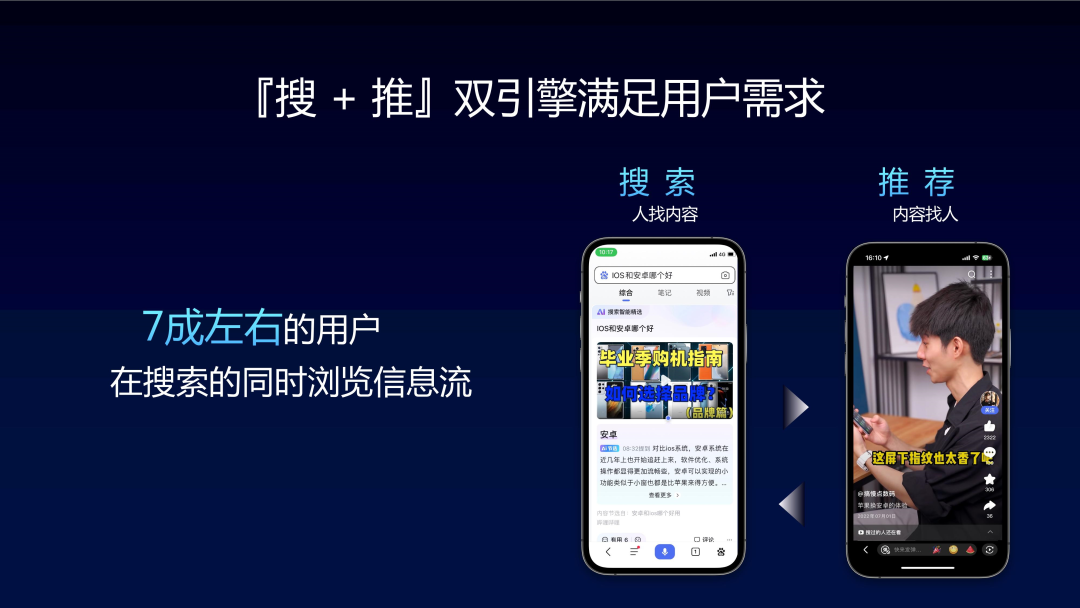
Il convient de mentionner que Baidu a commencé en tant que moteur de recherche et que le taux d'utilisation de la recherche est extrêmement élevé. dans les scénarios de recommandation. Les données sont utilisées pour répondre aux besoins des utilisateurs via le double moteur « recherche + push ». La recherche concerne principalement des "personnes recherchant du contenu", les utilisateurs entreront clairement leurs besoins, tandis que les recommandations sont des "contenus recherchant des personnes". L'intégration des signaux de recherche et des signaux de recommandation dans tous les domaines pour obtenir une meilleure intégration de la recommandation et de la recherche est également l'un des avantages de Baidu.
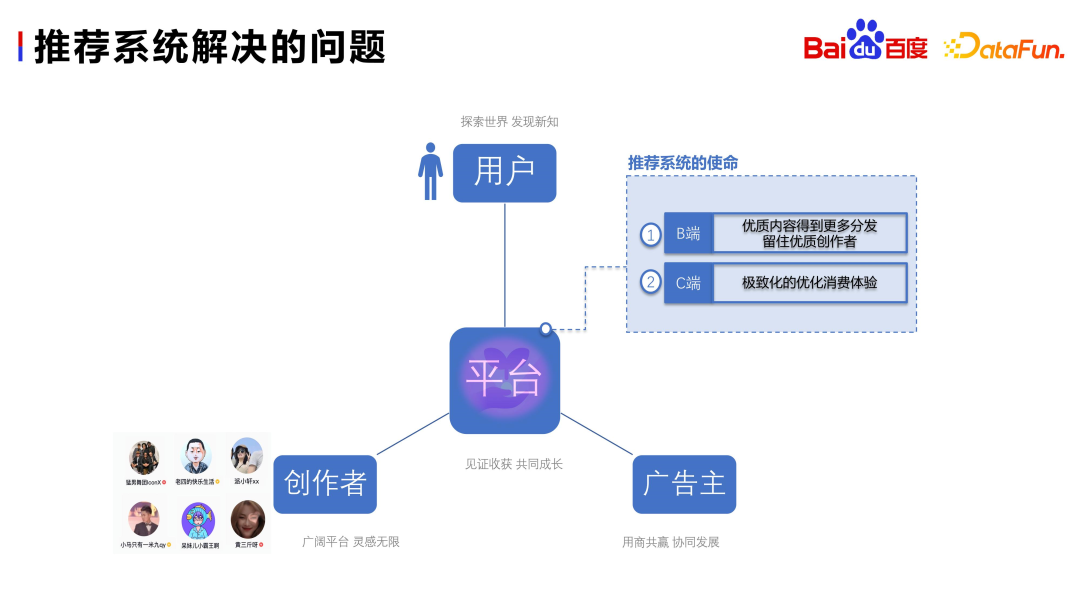
SCI, un nombre considérable de personnes dans le public manquent de compréhension de la recommandation technologie, il est nécessaire de présenter brièvement les problèmes à résoudre par la technologie recommandée. La plateforme recommandée compte trois acteurs :
La plateforme de recommandation espère parvenir à un cycle vertueux de production, de consommation et de revenus. En tant que composant central de la plateforme, le système de recommandation résout principalement deux problèmes :
Lors de la conception des objectifs, nous devons considérer de manière globale les deux missions du système de recommandation
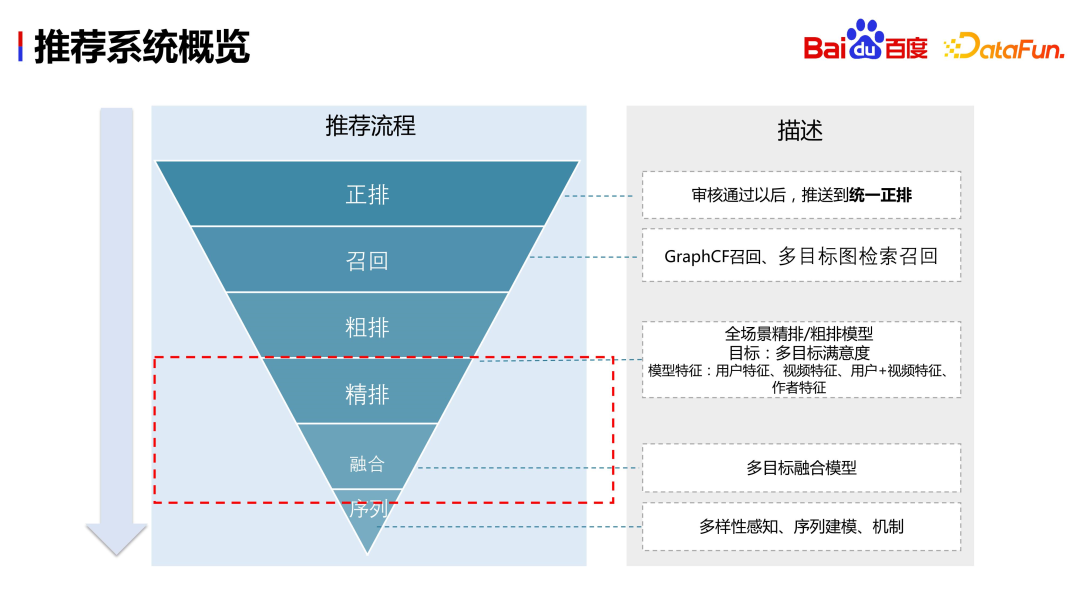
Le processus du système de recommandation est à peu près le suivant. : les ressources examinées seront d'abord poussées vers la base de données unifiée qui stocke les méta-informations ; après réception de la demande, le système de recommandation rappelle d'abord les ressources pertinentes via un moteur graphique, un rappel multi-cible, etc., il passera par deux ; des cycles de tri, à savoir un tri grossier et un tri fin, puis le modèle de fusion multi-objectif sélectionne certains contenus fortement pertinents pour l'utilisateur, enfin, grâce à la détection de la diversité, à la modélisation de séquences, au mécanisme de répartition du trafic et à d'autres stratégies, une liste de vidéos est créée ; généré et envoyé sur le téléphone mobile de l'utilisateur.
Le contenu suivant se concentrera principalement sur la fusion de conceptions et de modèles de cibles disposés avec précision
Tout d'abord, nous souhaitons introduire des Application de conception objective en recommandation vidéo
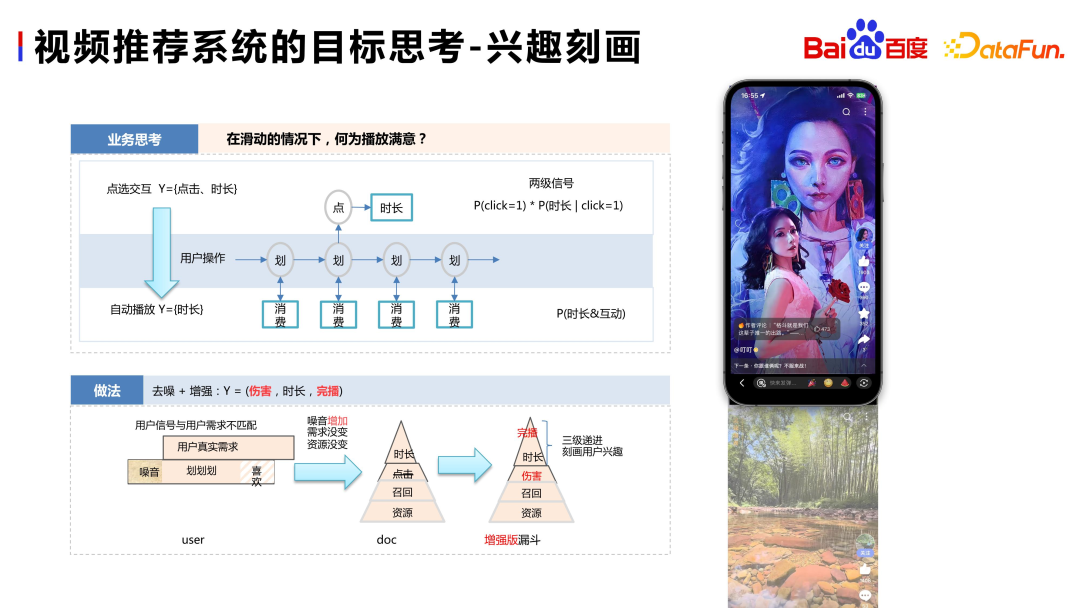
Tout d'abord, réfléchissez à la manière de concevoir la cible du système de recommandation dans le scénario vidéo immersif ?
Dans les systèmes de recommandation traditionnels, les utilisateurs consomment des ressources en cliquant sur du contenu ou des vidéos, exprimant ainsi clairement leur préférence pour la ressource. Par conséquent, dans les scénarios de recommandation traditionnels, le comportement de clic est un signal très important et une méthode de feedback claire et simple. Cependant, dans les scénarios immersifs, en raison du manque de retour clair, les préférences des utilisateurs s'expriment souvent à travers des comportements « cachés ». À l'heure actuelle, le temps de visionnage devient un signal extrêmement important dans les scénarios de recommandation immersifs

En plus de. ce qui précède En plus du temps de consommation, il est également nécessaire de prendre en compte le comportement des utilisateurs quittant activement le système, comme suivre, commenter, partager et aimer. Cependant, par rapport aux données de lecture, ces données comportementales sont très rares, peut-être seulement un millième de l'ordre. En plus de ces signaux interactifs, il existe également une partie très importante des données dans les recommandations de l'APP Baidu, qui est le signal de recherche. 70 % des utilisateurs de Baidu consomment à la fois des flux d'informations recommandés et des recherches. Par conséquent, le système de recommandation doit également décrire le signal de satisfaction du domaine de recherche de l'utilisateur.
Les créateurs de la face B ont besoin d'un mécanisme de concurrence pour éliminer les créateurs inférieurs en plus des signaux de consommation dont les utilisateurs de la face C sont satisfaits, stimuler le potentiel créatif des créateurs de haute qualité et parvenir ainsi à un cycle vertueux de production et consommation
2. Dimensions prises en compte dans la conception de la cible
Du point de vue du système de recommandation, l'utilisateur est l'annotateur de l'échantillon, et l'utilisateur a des expressions positives claires, telles que jouer, aimer, collectionner, commenter et autres comportements ; Il existe également des expressions négatives claires, telles que Je n'aime pas, les commentaires négatifs, les rapports, etc. En plus des expressions explicites, les utilisateurs auront également des expressions implicites, telles que l'appréciation exprimée lors de la fin de la lecture, la durée de la lecture, la consommation de la page de l'auteur, la lecture des recommandations associées, etc., ou l'aversion exprimée lors d'une lecture courte, d'une fenêtre contextuelle rapide, etc. . Par conséquent, lors de la conception des objectifs, nous devons réfléchir sous tous les aspects, équilibrer les signaux explicites et implicites et éviter de concevoir un système de recommandation « partiel ». 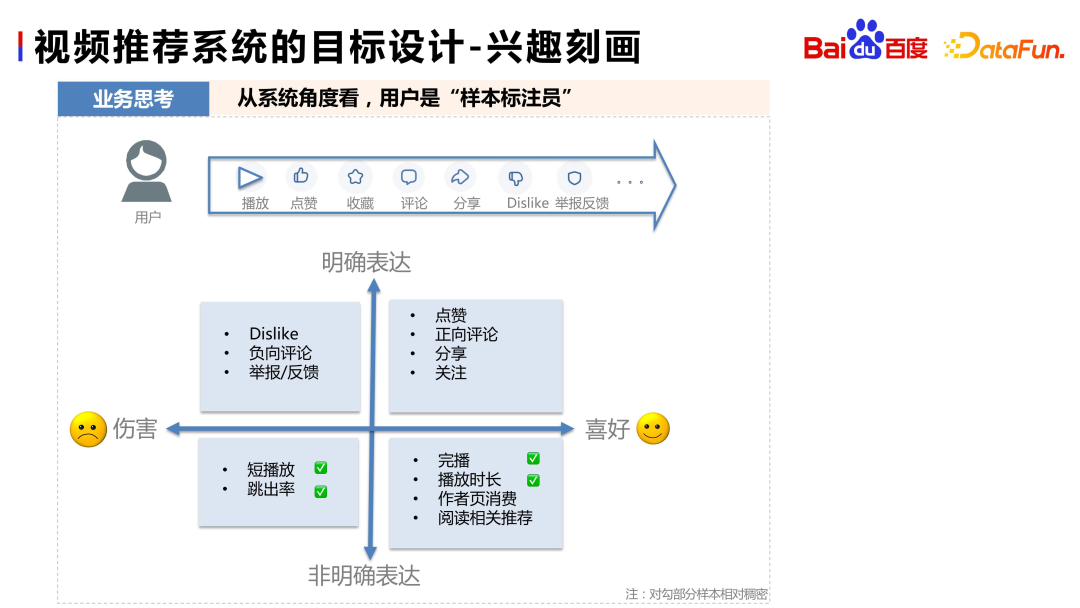
3. Modélisation globale de la satisfaction
En plus des objectifs de base ci-dessus, nous concevrons également des objectifs de haut niveau, en n'utilisant plus simplement les commentaires des utilisateurs. Par exemple, comme le montre le côté droit de la figure ci-dessus, nous avons lancé un modèle basé sur les retours de satisfaction des utilisateurs. Dans la première étape, grâce à des signaux denses tels que l'achèvement et la durée de la diffusion, des règles ou des modèles simples sont utilisés pour adapter les retours de satisfaction des utilisateurs afin d'obtenir une étiquette de satisfaction des utilisateurs relativement dense. Dans la deuxième étape, un modèle de satisfaction est construit sur la base de cette étiquette, en utilisant l'intégration générée par le modèle de recherche push à grande échelle, l'intégration sous-jacente Wenxin, et la modélisation des caractéristiques du portrait d'utilisateur et de la séquence comportementale pour évaluer le gain de satisfaction du domaine recommandé relatif. au domaine de recherche. Si un utilisateur a consommé un certain point d'intérêt dans la recherche, le système de recommandation peut recommander un contenu de meilleure qualité basé sur le modèle de satisfaction, ce qui peut rendre l'intégration de la recherche et pousser plus facilement et mieux migrer les intérêts de recherche vers le flux. 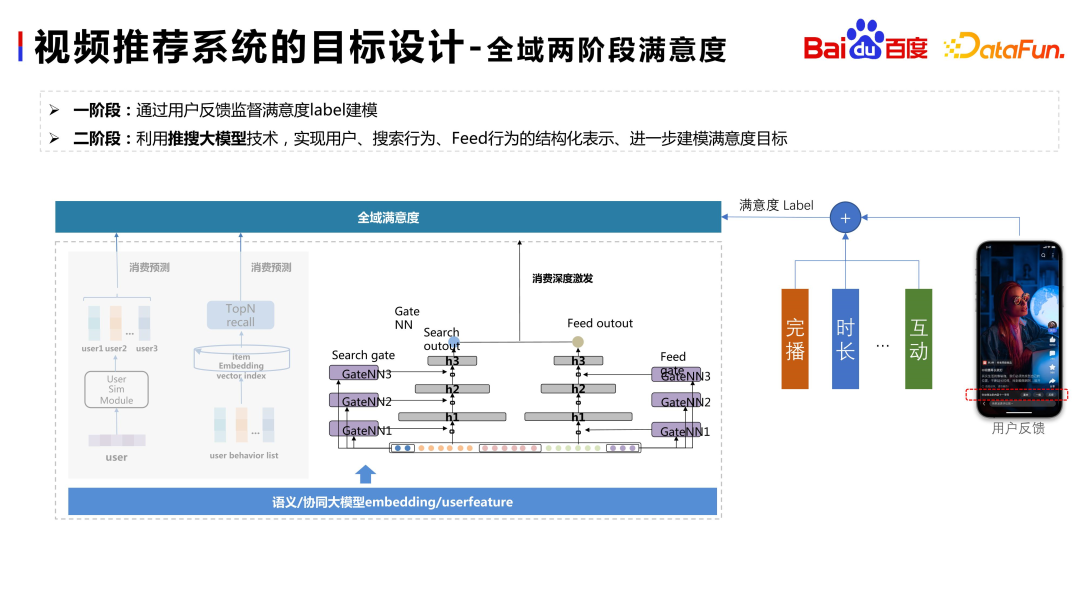
4. Modélisation de la valeur à long terme (Long Term Value)
Dans l'article précédent, nous avons présenté comment estimer le temps de lecture et l'interaction du contenu actuel. Nous pouvons utiliser le comportement de consommation historique des utilisateurs comme échantillons ou fonctionnalités pour prédire si le contenu à venir aura des commentaires positifs ou négatifs, et s'il y aura une interaction et une consommation satisfaisantes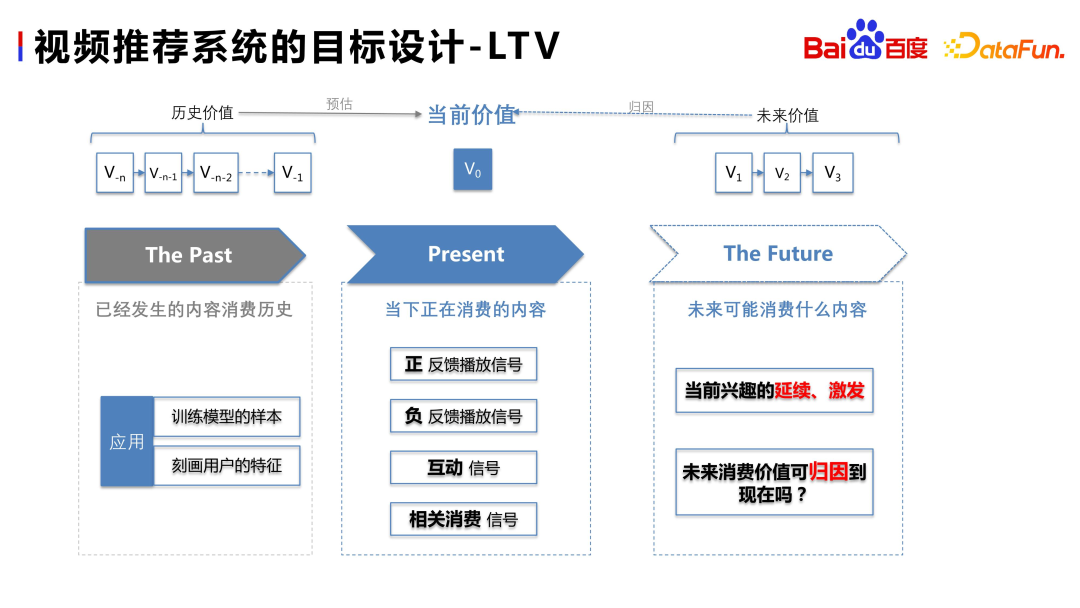
Nous pouvons en outre réfléchir à la question de savoir s'il existe une relation entre le contenu de consommation futur de l'utilisateur et le contenu de consommation actuel ? Par exemple, si les utilisateurs regardent les vidéos de Guo Degang maintenant et s'ils continuent à consommer les vidéos de Yu Qian le Nième jour suivant, ces vidéos de Yu Qian sont-elles « inspirées » par les vidéos de Guo Degang ? La consommation de points d’intérêt futurs peut-elle être considérée comme une « continuation » des points d’intérêt actuels ? La réponse est oui. Par conséquent, nous avons introduit le système LTV dans le système pour attribuer le futur contenu de valeur à long terme à la recommandation de la vidéo actuelle
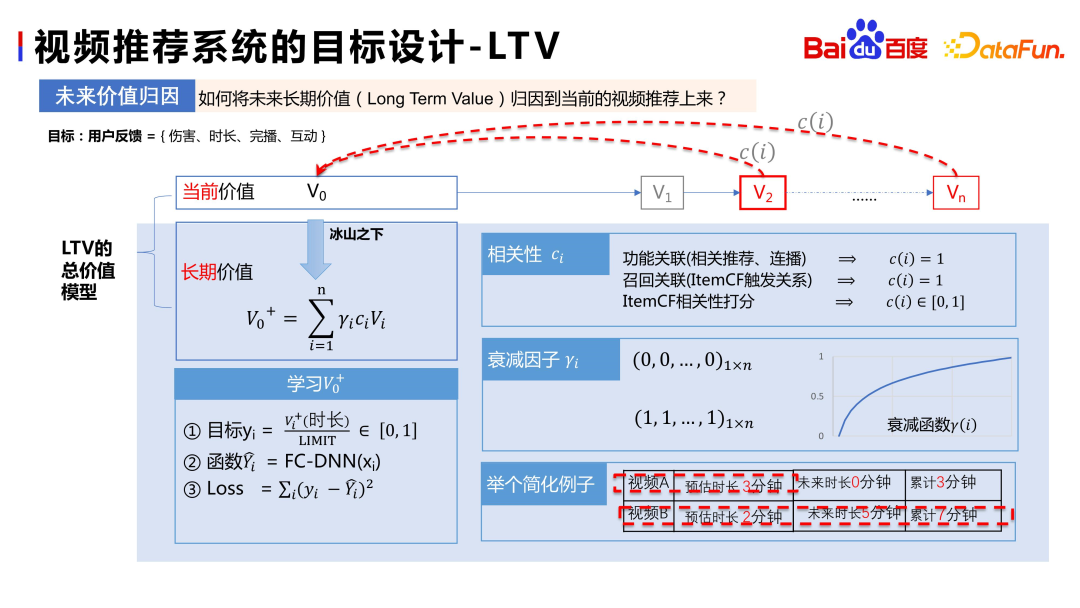
Supposons que V0 est la valeur de la vidéo actuelle, V1 , V 2,... Vn est la vidéo que l'utilisateur consommera dans le futur En supposant que V2 et Vn sont une consommation satisfaisante et une continuation de V0 . peut être attribué à V0 .
Il existe de nombreuses méthodes d'attribution. Selon le scénario commercial de Baidu Feed, l'attribution comprend les trois parties suivantes :
Bien entendu, cette attribution est pondérée. Nous utilisons l'intervalle de temps de V0 et la corrélation de V0 pour ajuster le poids d'attribution de la consommation future de vidéos de l'utilisateur, obtenant ainsi la valeur actuelle. valeur à long terme de la vidéo V0. Après avoir défini un objectif de valeur à long terme, l’apprentissage est relativement simple. La première étape consiste à normaliser l’objectif, puis à le modéliser directement.
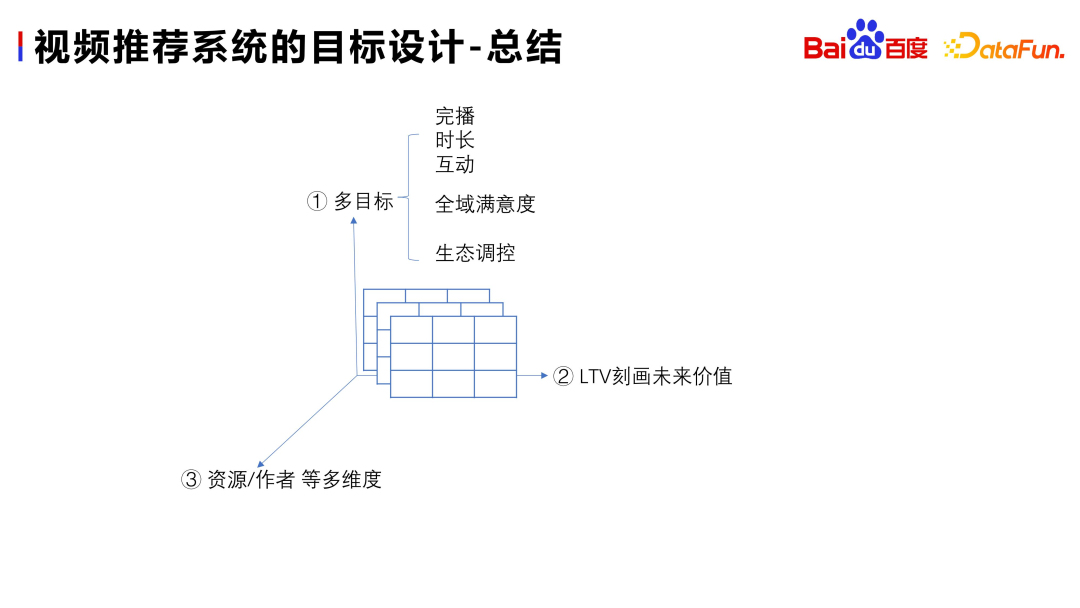
Sur la base de l'abstraction et du peignage de la situation commerciale actuelle, nous partirons des trois directions suivantes pour faire un résumé simple lors de la conception des objectifs du système de recommandation
Pour considérer de manière globale les différentes orientations de développement, les objectifs du système de recommandation doivent être abordés sous plusieurs angles
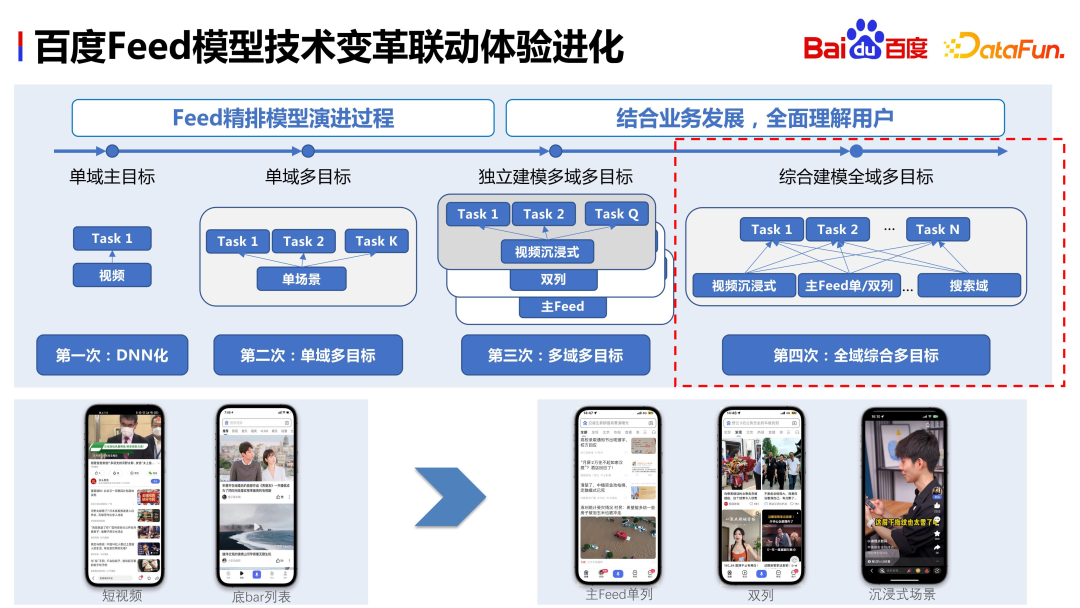
Le développement. des scénarios de recommandation actuels de Baidu Il a été divisé en trois scénarios principaux :
Le développement et l'évolution des produits Baidu ont conduit à un changement progressif des objectifs de classement. Initialement, il n'avait pour objectif principal qu'un seul domaine, puis s'est développé en plusieurs domaines et objectifs multiples. Il a désormais réalisé une modélisation complète de l'ensemble du domaine, intégrant des échantillons de plusieurs domaines pour parvenir à un partage complet des informations. Ce qui suit présentera le contenu spécifique de la modélisation complète dans tous les domaines
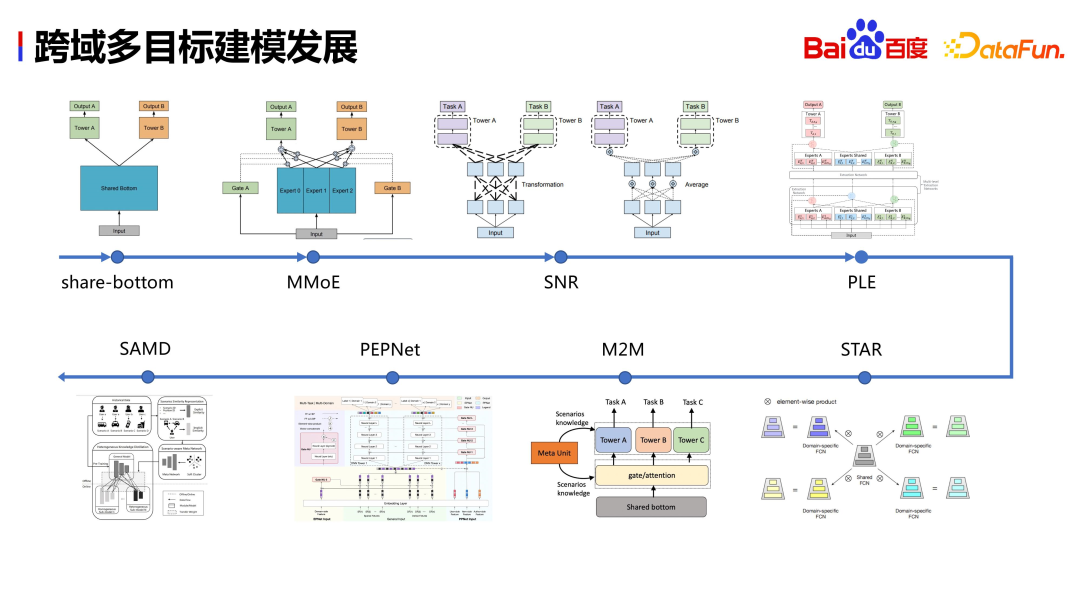
Tout d’abord, jetons un coup d’œil à ce que l’industrie a fait. Qu'il s'agisse de MMoE, PLE ou du réseau STAR, PEPNet et d'autres structures sur lesquelles travaille Alibaba, ainsi que des sociétés comme Google et Tencent, ils ne ménagent aucun effort pour concevoir diverses structures de réseau basées sur leurs propres activités, dans l'espoir de partagez-les dans des scénarios hétérogènes. Des informations plus utiles. Ces travaux résolvent principalement deux problèmes :
De même, le système de recommandation Baidu est également confronté à ces deux problèmes.
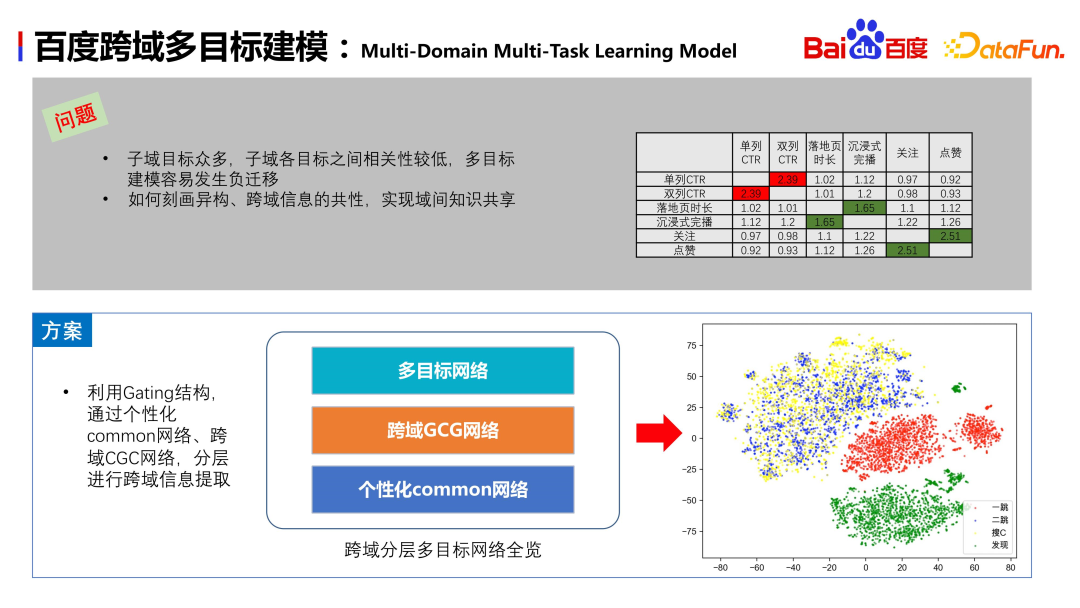
Il existe de nombreuses cibles de sous-domaines différentes dans le scénario de Baidu, et la corrélation entre ces cibles est faible, ce qui peut conduire à une migration négative entre plusieurs cibles. Pour résoudre ce problème, il faut analyser les PNR entre différentes cibles et découvrir les différences de corrélation entre elles. En d'autres termes, comment décrire les informations utilisateur dans des scénarios hétérogènes et comment mettre en œuvre la migration d'informations hétérogènes sont des problèmes qui doivent être résolus par la structure du modèle
Selon les besoins commerciaux de Baidu, nous avons conçu une superposition inter-domaines. La structure du réseau multi-objectifs adopte la structure Gating. Cette structure est principalement divisée en trois couches : la première est le réseau de partage personnalisé comme couche inférieure ; la deuxième couche est le réseau GCG pour l'extraction d'informations inter-domaines et la dernière couche est le réseau multi-objectifs de sous-domaines. Grâce à cette conception, nous pouvons effectuer une estimation multi-objectif pour chaque domaine tout en partageant des informations
Cette solution présente une amélioration significative par rapport au multi-objectif à domaine unique. L'AUC du premier lancement est environ 3 à 9 000 fois plus élevée. . indiquer. Comme le montre le coin inférieur droit de la figure ci-dessus, après avoir obtenu l'intégration des caractéristiques des utilisateurs dans plusieurs domaines et effectué une réduction de dimensionnalité TSNE, sauf que la recherche C et le deuxième saut sont relativement proches, la distinction entre les deux autres scénarios est encore relativement évident, indiquant que le modèle peut apprendre les différences entre les scènes. Il est raisonnable qu'il n'y ait pas beaucoup de différence entre les scénarios de recherche C et de deuxième saut. Ce sont tous deux des scénarios vidéo, et l'interaction et l'intérêt de l'utilisateur ne sont pas très différents.
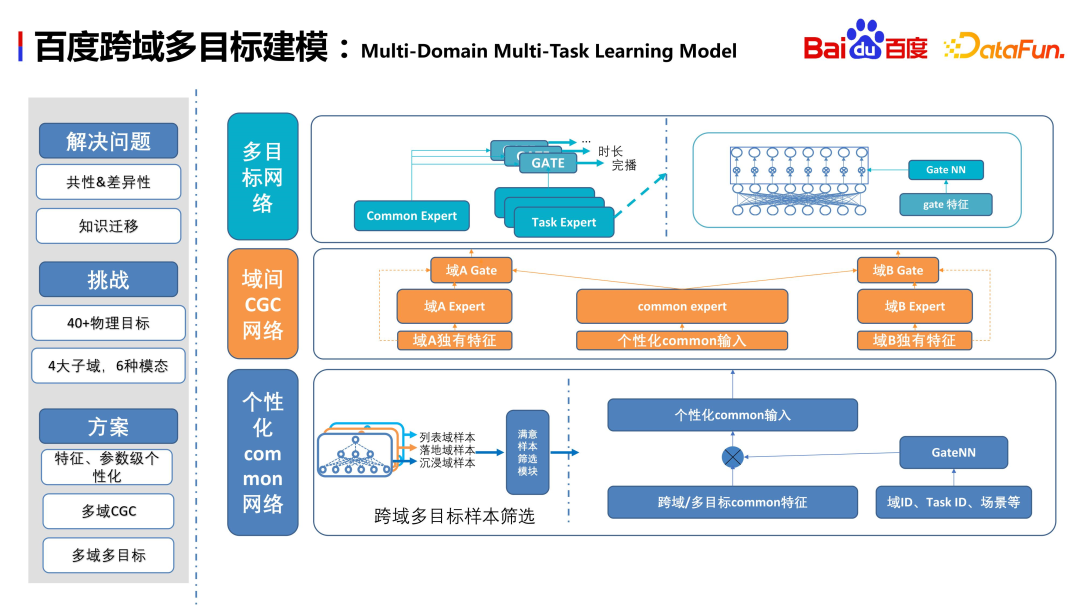
Le scénario commercial Baidu comporte plus de 40 cibles physiques, 4 grands sous-domaines et 6 formulaires, dont vidéo, graphiques, dynamiques, petits programmes, etc. Nous espérons que le modèle pourra fonctionner correctement dans de nombreuses entreprises complexes. Présentons brièvement la structure du modèle. La première couche est le réseau commun, qui sert de base à la division de domaine, sélectionnant des échantillons satisfaisants de plusieurs cibles dans chaque scène et réalisant une cartographie d'intégration personnalisée via le réseau de portes. La deuxième couche est l'extraction d'informations inter-domaines, qui implémente des fonctionnalités uniques et des fonctionnalités partagées personnalisées au sein du domaine via le réseau CGC. Les deux construisent conjointement l'extraction d'informations inter-domaines. L'avantage est qu'elle conserve non seulement la richesse des informations au sein du domaine, mais extrait également les informations partagées de scènes hétérogènes. La troisième couche est la modélisation multi-objectifs des sous-domaines. Nous avons également un article correspondant en cours de publication sur ce sujet. Les amis intéressés par les détails peuvent le lire.
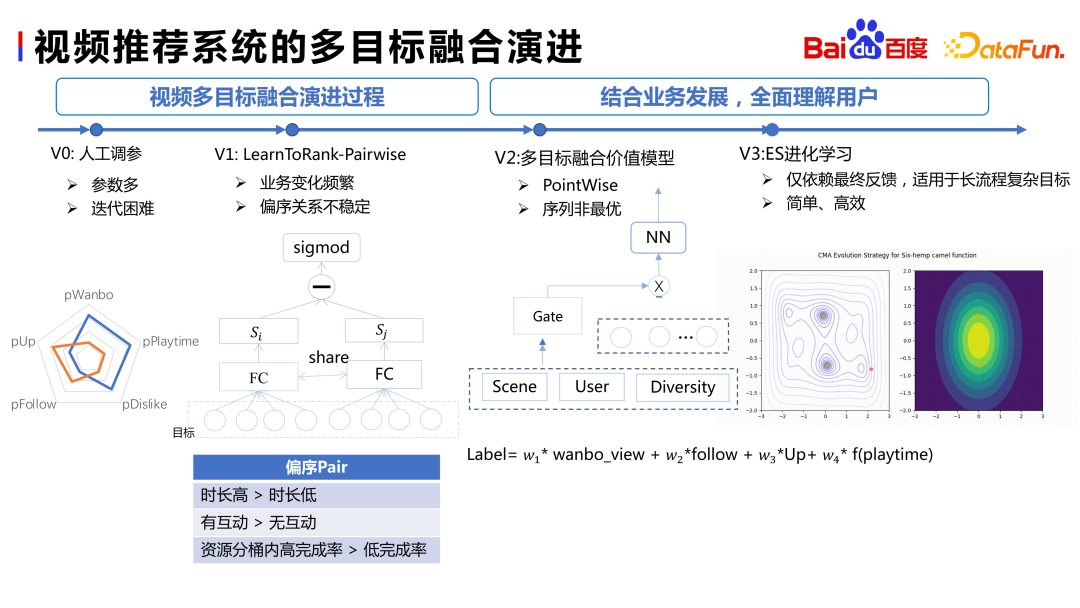
Le processus d'évolution de la fusion multi-objectifs de Baidu est similaire à celui de l'industrie. La première est la fusion des connaissances préalables, qui, bien que simple et directe, nécessite beaucoup de main d’œuvre. Ensuite, nous sommes passés à LTR, et l'effet a été remarquable. Cependant, l'inconvénient était que cela nécessitait des ajustements fréquents lorsque l'activité changeait. Dans le même temps, la relation de commande partielle changeait également avec les changements dans la stratification de l'activité et des utilisateurs. Ensuite, nous avons adopté un modèle de valeur de fusion multi-objectif, en utilisant une approche optimale séquentielle. Après une courte période d'utilisation, nous sommes passés à la méthode que nous utilisons actuellement - l'apprentissage évolutif ES (Evolution Strategy)
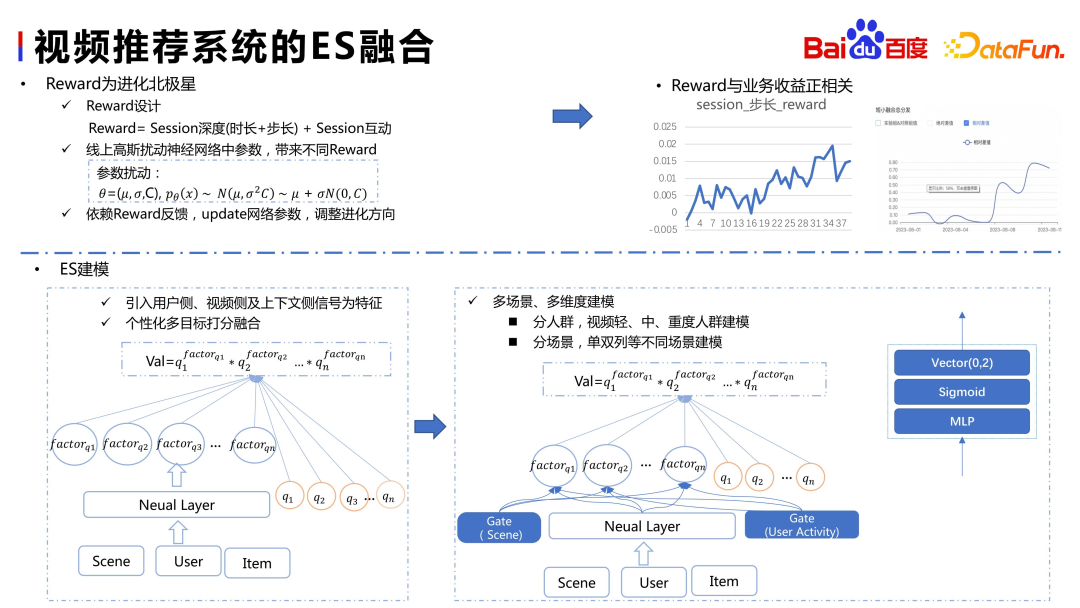
Pour utiliser ES, vous devez d'abord définir une récompense, qui est l'étoile du Nord. indicateur. Les récompenses de Baidu sont la profondeur de la session (durée + longueur de l'étape) et l'interaction. Les indicateurs commerciaux correspondant à la durée et à la longueur de l'étape sont la durée et le volume de lecture vidéo. Ces deux indicateurs reflètent la rétention des utilisateurs, c'est-à-dire LT. De plus, il existe des informations interactives, qui représentent l'accumulation d'actifs par l'utilisateur dans l'APP, comme le fait de prêter attention au comportement de l'auteur. En fait, il espère pouvoir retrouver l'auteur après sa mise à jour. Qu'il s'agisse d'augmenter le nombre de consommations ou d'interactions, nous espérons que les utilisateurs pourront utiliser cette application plus longtemps
Notre version initiale est un modèle heuristique simple, tandis que l'ES en ligne actuel effectue des calculs plus avancés, tels que l'introduction d'informations sur différents scénarios et groupes de personnes
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comparez les similitudes et les différences entre deux colonnes de données dans Excel
Comparez les similitudes et les différences entre deux colonnes de données dans Excel
 Tutoriel de récupération des icônes de mon ordinateur Win10
Tutoriel de récupération des icônes de mon ordinateur Win10
 utilisation de la fonction de tri
utilisation de la fonction de tri
 Comment installer le pilote d'imprimante sous Linux
Comment installer le pilote d'imprimante sous Linux
 Comment débloquer les restrictions d'autorisation Android
Comment débloquer les restrictions d'autorisation Android
 Marquage de couleur du filtre en double Excel
Marquage de couleur du filtre en double Excel
 qu'est-ce que l'optimisation
qu'est-ce que l'optimisation
 Comment réparer la base de données SQL
Comment réparer la base de données SQL
 Comment utiliser l'ajout en python
Comment utiliser l'ajout en python








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



