

Aujourd'hui, je souhaite partager avec vous les méthodes courantes de regroupement d'apprentissage non supervisé dans l'apprentissage automatique
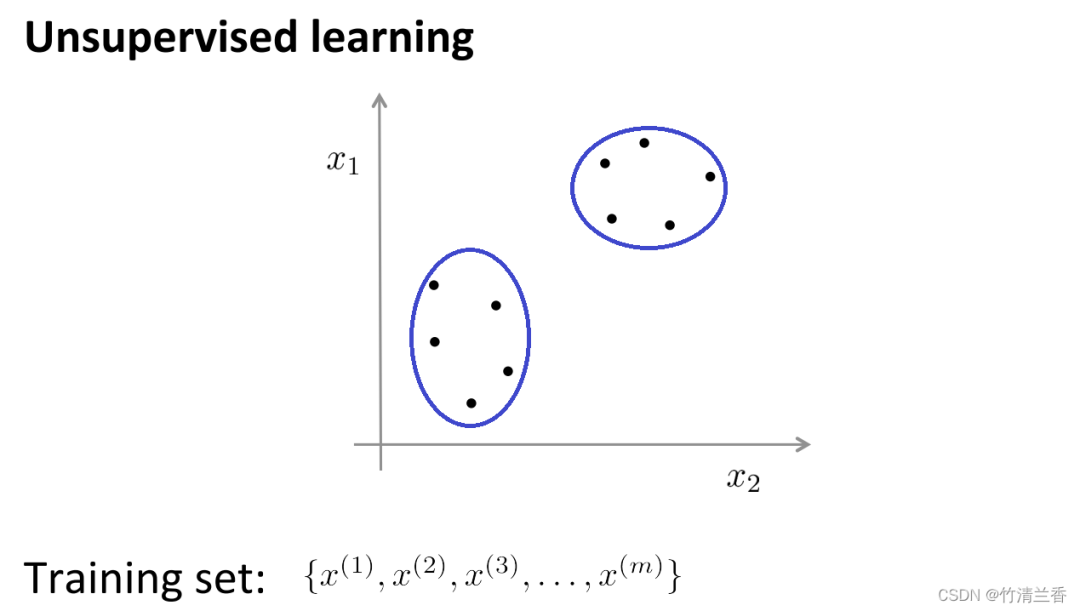
Dans l'apprentissage non supervisé, nos données ne portent aucune étiquette, donc ce que nous devons faire dans l'apprentissage non supervisé est de Cette série de données non étiquetées est entrée dans l'algorithme, puis l'algorithme est autorisé à trouver certaines structures implicites dans les données Grâce aux données de la figure ci-dessous, une structure qui peut être trouvée est que les points de l'ensemble de données peuvent être divisés en deux ensembles de points distincts. .(clusters), l'algorithme qui peut encercler ces clusters (cluster) est appelé algorithme de clustering.
L'objectif de l'analyse groupée est de diviser les observations en groupes (« clusters ») de sorte que les différences par paires entre les observations attribuées au même cluster ont tendance à être plus petites que les différences entre les observations de différents clusters. Les algorithmes de clustering sont divisés en trois types différents : les algorithmes combinatoires, la modélisation hybride et la recherche de modèles. Plusieurs algorithmes de clustering courants sont : DBSCAN
Supposons qu'il existe un ensemble de données non étiquetées (à gauche dans la figure ci-dessus), et nous Si vous souhaitez le diviser en deux clusters, exécutez maintenant l'algorithme K-means. L'opération spécifique est la suivante :
La première étape consiste à générer aléatoirement deux points (car vous souhaitez regrouper). les données en deux catégories) (à droite de l'image ci-dessus), ces deux points sont appelés centroïdes de cluster.
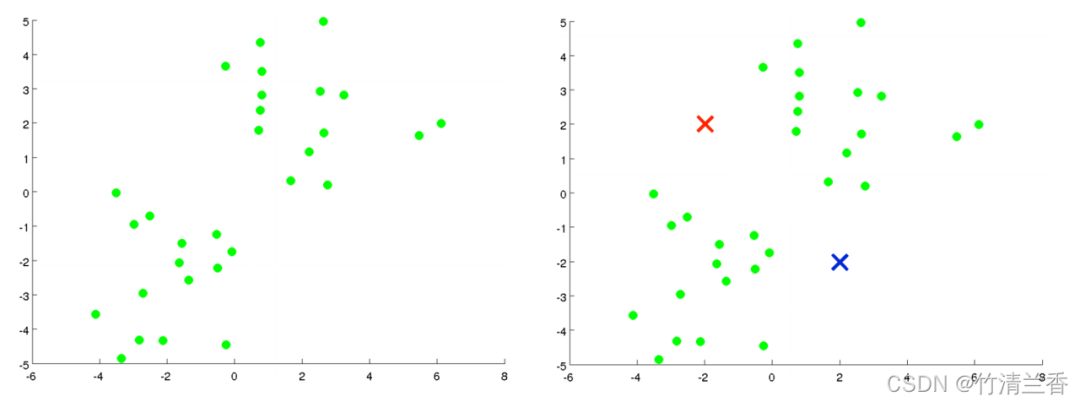
La deuxième étape de la boucle interne consiste à déplacer le centre du cluster afin que les centres du cluster rouge et bleu se déplacent vers la position moyenne des points auxquels ils appartiennent
Simple et facile à comprendre, vitesse de calcul rapide et adapté aux ensembles de données à grande échelle.
Le clustering hiérarchique est l'opération de regroupement d'ensembles d'échantillons selon un certain niveau. Le niveau ici fait en fait référence à la définition d'une certaine distance
Le but ultime du clustering est de réduire le nombre de classifications, son comportement est donc similaire au processus du dendrogramme consistant à s'approcher progressivement du nœud feuille au nœud racine. Ce type de comportement est également appelé « ascendant »
Plus communément, le clustering hiérarchique considère plusieurs clusters initialisés comme des nœuds d'arborescence. À chaque étape d'itération, deux clusters similaires sont fusionnés en un nouveau grand cluster. ce processus est répété jusqu'à ce qu'il ne reste finalement qu'un seul cluster (nœud racine).
Les stratégies de clustering hiérarchique sont divisées en deux paradigmes de base : l'agrégation (de bas en haut) et la division (de haut en bas).
Le contraire du clustering hiérarchique est le clustering divisif, également connu sous le nom de DIANA (Divise Analysis), dont le processus de comportement est "top-down"
Les résultats de l'algorithme K-means dépendent du cluster choisi pour rechercher Attribution du nombre de classes et configuration de départ. En revanche, les méthodes de clustering hiérarchique ne nécessitent pas une telle spécification. Au lieu de cela, ils exigent que l'utilisateur spécifie une mesure de dissimilarité entre des groupes (disjoints) d'observations basée sur la dissimilarité par paire entre les deux ensembles d'observations. Comme leur nom l'indique, les méthodes de clustering hiérarchique produisent une représentation hiérarchique dans laquelle les clusters de chaque niveau sont créés en fusionnant les clusters du niveau inférieur suivant. Au niveau le plus bas, chaque cluster contient une observation. Au plus haut niveau, un seul cluster contient toutes les données
Le contenu réécrit est le suivant : Le clustering aggloméré est un algorithme de clustering ascendant qui traite chaque point de données comme un cluster initial et le fusionne progressivement. Ils forment des clusters plus grands jusqu'à ce que la condition d'arrêt soit remplie. Dans cet algorithme, chaque point de données est initialement traité comme un cluster distinct, puis les clusters sont progressivement fusionnés jusqu'à ce que tous les points de données soient fusionnés en un seul grand cluster
Contenu modifié : L'algorithme de propagation d'affinité (AP) est généralement traduit par algorithme de propagation d'affinité ou algorithme de propagation de proximité
La propagation d'affinité est un algorithme de clustering basé sur la théorie des graphes, qui vise à identifier des "exemplaires". " (points représentatifs) et "clusters" (clusters) dans les données. Contrairement aux algorithmes de clustering traditionnels tels que K-Means, Affinity Propagation n'a pas besoin de spécifier le nombre de clusters à l'avance, ni d'initialiser de manière aléatoire les centres de cluster. Au lieu de cela, il obtient le résultat final du clustering en calculant la similarité entre les points de données.
Le clustering par décalage est un algorithme de clustering non paramétrique basé sur la densité. Son idée de base est de trouver l'emplacement avec la densité de points de données la plus élevée (appelée « maximum local » ou « pic »). , pour identifier les clusters dans les données. Le cœur de cet algorithme est d'estimer la densité locale de chaque point de données et d'utiliser les résultats de l'estimation de la densité pour calculer la direction et la distance du mouvement du point de données.
Bisecting K-Means est un algorithme de clustering hiérarchique basé sur l'algorithme K-Means. Son idée de base est de diviser tous les points de données en un cluster, puis de diviser le cluster en deux sous-clusters. , appliquez l'algorithme K-Means à chaque sous-cluster séparément et répétez ce processus jusqu'à ce que le nombre prédéterminé de clusters soit atteint.
L'algorithme traite d'abord tous les points de données comme un cluster initial, puis applique l'algorithme K-Means au cluster, divise le cluster en deux sous-clusters et calcule la somme des erreurs quadratiques (SSE) pour chaque sous-cluster. grappe. Ensuite, le sous-groupe avec la plus grande somme d'erreurs quadratiques est sélectionné et divisé à nouveau en deux sous-groupes, et ce processus est répété jusqu'à ce que le nombre prédéterminé de groupes soit atteint.
L'algorithme de clustering spatial basé sur la densité DBSCAN (Density-Based Spatial Clustering of Applications with Noise) est une méthode de clustering typique avec bruit
La méthode de densité ne dépend pas des caractéristiques de distance, mais dépend sur la densité. Par conséquent, il peut surmonter le problème selon lequel les algorithmes basés sur la distance ne peuvent trouver que des clusters « sphériques ». L'idée centrale de l'algorithme DBSCAN est la suivante : pour un point de données donné, si sa densité atteint un certain seuil, il appartient à un cluster. ; sinon, c'est considéré comme un point de bruit.
OPTICS (Ordering Points To Identity the Clustering Structure) est un algorithme de clustering basé sur la densité qui peut déterminer automatiquement le nombre de clusters, peut également découvrir des clusters de n'importe quelle forme et gérer des données bruyantes
L'idée principale de l'algorithme OPTICS est de calculer la distance entre un point de données donné et d'autres points pour déterminer son accessibilité en termes de densité et construire une carte de distance basée sur la densité. Ensuite, en scannant cette carte de distance, le nombre de clusters est automatiquement déterminé et chaque cluster est divisé.
BIRCH (Balanced Iterative Reduction and Hierarchical Clustering) est un algorithme de clustering basé sur le clustering hiérarchique qui peut gérer efficacement des ensembles de données à grande échelle et obtenir de bons résultats pour les clusters de toute forme. L'idée centrale du L'algorithme BIRCH consiste à réduire progressivement la taille des données grâce à un regroupement hiérarchique de l'ensemble de données, et enfin à obtenir la structure du cluster. L'algorithme BIRCH utilise une structure de type arbre B appelée arbre CF, qui peut rapidement insérer et supprimer des sous-clusters et peut être automatiquement équilibrée pour garantir la qualité et l'efficacité des clusters
Avantages :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Liste de prix du niveau Douyin 1-75
Liste de prix du niveau Douyin 1-75
 Qu'est-ce que la carte de contrôle d'accès NFC
Qu'est-ce que la carte de contrôle d'accès NFC
 Les photos Windows ne peuvent pas être affichées
Les photos Windows ne peuvent pas être affichées
 Qu'est-ce que le courrier électronique
Qu'est-ce que le courrier électronique
 Quels sont les cinq types de fonctions d'agrégation ?
Quels sont les cinq types de fonctions d'agrégation ?
 Site officiel de Binance
Site officiel de Binance
 Comment faire défiler les images en ppt
Comment faire défiler les images en ppt
 Comment résoudre le problème selon lequel le raccourci IE ne peut pas être supprimé
Comment résoudre le problème selon lequel le raccourci IE ne peut pas être supprimé








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



