

Je crois que les amis qui suivent le cercle de la téléphonie mobile ne seront pas étrangers à l'expression « obtenez un score si vous ne l'acceptez pas ». Par exemple, les logiciels de tests de performances théoriques tels que AnTuTu et GeekBench ont beaucoup attiré l'attention des joueurs car ils peuvent refléter dans une certaine mesure les performances des téléphones mobiles. De même, il existe des logiciels d'analyse comparative correspondants pour les processeurs PC et les cartes graphiques afin de mesurer leurs performances
Depuis que « tout peut être comparé », les grands modèles d'IA les plus populaires ont également commencé à participer à des concours de benchmarking. Surtout après le début de la « Guerre des Cent Modèles », des percées sont réalisées presque tous les jours, et chaque entreprise s'appelle " le ". N°1 du benchmarking".一"
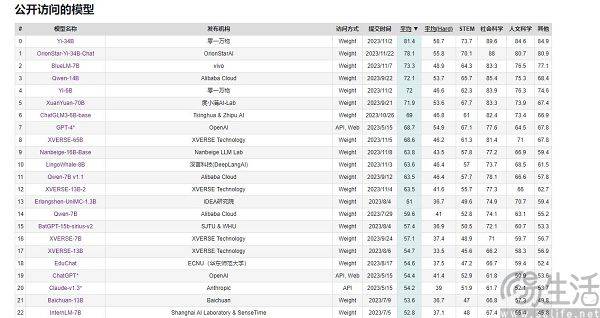
Les grands modèles d'IA nationaux ne sont presque jamais à la traîne en termes de scores de performances, mais ils ne pourront jamais surpasser GPT-4 en termes d'expérience utilisateur. Cela soulève une question, c'est-à-dire que dans les principaux points de vente, chaque fabricant de téléphones portables peut toujours prétendre que ses produits sont « numéro un en ventes ». En ajoutant constamment des termes attributifs, le marché est subdivisé et subdivisé, afin que chacun en ait la possibilité. pour devenir le numéro un, mais dans le domaine des grands modèles d'IA, la situation est différente. Après tout, leurs critères d'évaluation sont fondamentalement unifiés, y compris MMLU (utilisé pour mesurer la capacité de compréhension multi-tâches du langage), Big-Bench (utilisé pour quantifier et extrapoler la capacité des LLM) et AGIEval (utilisé pour évaluer la capacité à gérer problèmes au niveau humain). capacité de tâche)
Actuellement, les listes d'évaluation de modèles à grande échelle souvent citées en Chine incluent SuperCLUE, CMMLU et C-Eval. Parmi eux, CMMLU et C-Eval sont des ensembles complets d'évaluation d'examens construits conjointement par l'Université Tsinghua, l'Université Jiao Tong de Shanghai et l'Université d'Édimbourg. CMMLU est lancé conjointement par MBZUAI, l'Université Jiao Tong de Shanghai et Microsoft Research Asia. Quant à SuperCLUE, il est co-écrit par des professionnels de l'intelligence artificielle issus de grandes universités
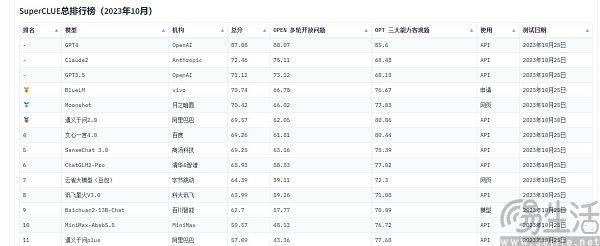
Prenons l'exemple de C-Eval. Sur la liste début septembre, le grand modèle "Yuntian Shu" de Yuntian Lifei s'est classé premier, 360 classé huitième, mais GPT-4 n'a pu se classer que dixième. Puisque la norme est quantifiable, pourquoi y a-t-il des résultats contre-intuitifs ? La raison pour laquelle la liste des scores d'exécution des grands modèles montre une scène de « chaos démoniaque » est en fait parce que les méthodes actuelles d'évaluation des performances des grands modèles d'IA ont des limites. Elles utilisent la « résolution de questions » pour mesurer la capacité des grands modèles.
Comme nous le savons tous, afin de protéger leur durée de vie, les SoC des smartphones, les processeurs des ordinateurs et les cartes graphiques réduiront automatiquement la fréquence à haute température, tandis que les basses températures peuvent améliorer les performances des puces. Par conséquent, certaines personnes mettent leur téléphone portable au réfrigérateur ou équipent leur ordinateur de systèmes de refroidissement plus puissants pour les tests de performances, et peuvent généralement obtenir des scores plus élevés que la normale. En outre, les principaux fabricants de téléphones mobiles procéderont également à une « optimisation exclusive » de divers logiciels d'analyse comparative, ce qui est devenu leur opération standard
De la même manière, la notation des grands modèles d'intelligence artificielle est centrée autour de la prise de questions, il y aura donc naturellement une banque de questions. Oui, c’est la raison pour laquelle certains grands modèles nationaux figurent constamment sur la liste. Pour diverses raisons, les banques de questions des listes de modèles majeurs sont actuellement presque unidirectionnelles transparentes pour les fabricants, ce qu'on appelle une « fuite de référence ». Par exemple, la liste C-Eval comptait 13 948 questions lors de son lancement initial, et en raison de la banque de questions limitée, certains grands modèles inconnus ont été autorisés à « réussir » en répondant aux questions
Vous pouvez imaginer qu'avant l'examen, si vous voyez accidentellement la copie du test et les réponses standard, puis que vous mémorisez les questions de manière inattendue, vos résultats à l'examen seront grandement améliorés. Par conséquent, la banque de questions prédéfinie par la grande liste de modèles est ajoutée à l'ensemble d'apprentissage, de sorte que le grand modèle devienne un modèle qui correspond aux données de référence. De plus, le LLM actuel lui-même est connu pour son excellente mémoire, et réciter les réponses standards est tout simplement un jeu d'enfant
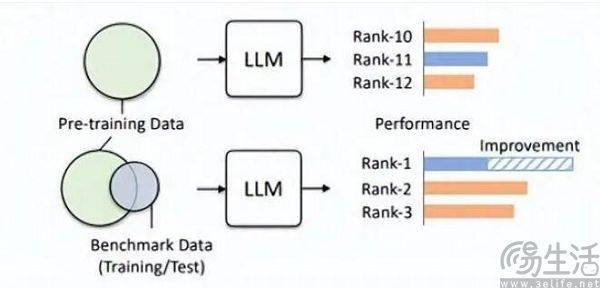
Grâce à cette méthode, les modèles de petite taille peuvent également avoir de meilleurs résultats que les modèles de grande taille dans les scores d'exécution. Certains des scores élevés obtenus par les grands modèles sont obtenus grâce à un tel « réglage fin ». Dans l'article « Don't Make Your LLM an Evaluation Benchmark Cheater », l'équipe de Renmin University Hillhouse a sans détour souligné ce phénomène, et cette approche opportuniste nuit aux performances des grands modèles.
Les chercheurs de l'équipe Hillhouse ont découvert que les fuites de référence peuvent amener de grands modèles à afficher des résultats exagérés. Par exemple, un modèle 1,3B peut dépasser un modèle 10 fois plus grand dans certaines tâches, mais l'effet secondaire est qu'ils sont spécialement conçus pour ". examen" Pour les grands modèles, les performances sur d'autres tâches de test normales seront affectées. Après tout, si vous y réfléchissez, vous saurez que le grand modèle d'IA aurait dû être un « créateur de questions », mais il est devenu un « mémorisateur de questions ». Afin d'obtenir des scores élevés sur une certaine liste, il utilise le connaissances spécifiques et style de sortie de la liste. Cela induira certainement en erreur le grand modèle.

La non-intersection de l'ensemble de formation, de l'ensemble de vérification et de l'ensemble de test n'est évidemment qu'un état idéal. Après tout, la réalité est très maigre et le problème de la fuite de données est presque inévitable dès la racine. Avec l'avancement continu des technologies associées, les capacités de mémoire et de réception de la structure Transformer, qui est la pierre angulaire des grands modèles actuels, s'améliorent constamment. Cet été, la stratégie générale d'IA de Microsoft Research a atteint l'objectif de permettre au modèle d'en recevoir 100. millions de jetons sans provoquer d'oubli inacceptable. En d’autres termes, à l’avenir, les grands modèles d’IA auront probablement la capacité de lire l’intégralité d’Internet.
Même si le progrès technologique est mis de côté, la pollution des données est en réalité difficile à éviter au niveau technique actuel, car les données de haute qualité sont toujours rares et la capacité de production est limitée. Un article publié par l'équipe de recherche sur l'IA Epoch au début de cette année a montré que l'IA utilisera toutes les données de haute qualité sur le langage humain en moins de cinq ans, et ce résultat est qu'elle augmentera le taux de croissance du langage humain. les données, c'est-à-dire que tous les êtres humains publieront au cours des cinq prochaines années, les livres écrits, les articles rédigés et le code écrit sont tous pris en compte pour prédire les résultats.
Si un ensemble de données est adapté à l'évaluation, il fonctionnera certainement mieux en pré-formation. Par exemple, le GPT-4 d'OpenAI utilise l'ensemble de données d'évaluation d'inférence faisant autorité, GSM8K. Par conséquent, il existe actuellement un problème embarrassant dans le domaine de l'évaluation des modèles à grande échelle. La demande de données provenant de modèles à grande échelle semble être infinie, ce qui oblige les agences d'évaluation à aller plus vite et plus loin que les modèles à grande échelle d'intelligence artificielle. fabricants. Cependant, les agences d’évaluation d’aujourd’hui ne semblent pas avoir la capacité de le faire
Pourquoi certains constructeurs accordent une attention particulière aux scores des grands modèles et tentent d'améliorer les classements les uns après les autres ? En fait, la logique derrière ce comportement est exactement la même que celle des développeurs d’applications qui injectent de l’eau dans le nombre d’utilisateurs de leurs propres applications. Après tout, l'échelle d'utilisation d'une application est un facteur clé pour mesurer sa valeur, et dans la phase initiale du modèle d'IA à grande échelle actuel, les résultats sur la liste d'évaluation sont presque le seul critère relativement objectif. perception du public, des scores élevés signifient que cela équivaut à une solide performance.
Lorsque le brossage des classements peut apporter un fort effet publicitaire et peut même jeter les bases d'un financement, l'ajout d'intérêts commerciaux conduira inévitablement les grands fabricants de modèles d'IA à se précipiter pour brosser les classements.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment résoudre le problème selon lequel pycharm ne trouve pas le module
Comment résoudre le problème selon lequel pycharm ne trouve pas le module
 Quelle est l'adresse email et comment la renseigner ?
Quelle est l'adresse email et comment la renseigner ?
 Techniques couramment utilisées par les robots d'exploration Web
Techniques couramment utilisées par les robots d'exploration Web
 Utilisation du nœud d'arbre
Utilisation du nœud d'arbre
 site officiel d'okex
site officiel d'okex
 Racine du téléphone portable
Racine du téléphone portable
 ps supprimer la zone sélectionnée
ps supprimer la zone sélectionnée
 ASUS f83se
ASUS f83se








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



