
 Périphériques technologiques
IA
DetZero : Waymo se classe premier sur la liste de détection 3D, comparable à l'annotation manuelle !
Périphériques technologiques
IA
DetZero : Waymo se classe premier sur la liste de détection 3D, comparable à l'annotation manuelle !
DetZero : Waymo se classe premier sur la liste de détection 3D, comparable à l'annotation manuelle !


Cet article propose un ensemble de cadres d'algorithmes de détection d'objets 3D hors ligne DetZero. Grâce à une recherche et une évaluation complètes de l'ensemble de données publiques de Waymo, DetZero peut générer des séquences de trajectoires d'objets continues et complètes et utiliser pleinement les nuages de points à long terme. Les fonctionnalités améliorent considérablement la qualité des résultats perçus. Dans le même temps, il s'est classé premier dans le classement de détection d'objets WOD 3D avec une performance de 85,15 mAPH (L2). De plus, DetZero peut fournir un étiquetage automatique de haute qualité pour la formation de modèles en ligne, et ses résultats ont atteint, voire dépassé, le niveau de l'étiquetage manuel.
Voici le lien papier : https://arxiv.org/abs/2306.06023
Le contenu qui doit être réécrit est : Lien de code : https://github.com/PJLab-ADG/DetZero
Veuillez visiter le lien de la page d'accueil : https://superkoma.github.io/detzero-page
1 Introduction
Afin d'améliorer l'efficacité de l'annotation des données, nous avons étudié une nouvelle méthode. Cette méthode est basée sur le deep learning et l’apprentissage non supervisé et peut générer automatiquement des données annotées. En utilisant de grandes quantités de données non étiquetées, nous pouvons entraîner un modèle de perception de conduite autonome pour reconnaître et détecter des objets sur la route. Cette méthode peut non seulement réduire le coût d’étiquetage des données, mais également améliorer l’efficacité du post-traitement. Nous avons utilisé la méthode de détection d'objets 3D hors ligne 3DAL[] de Waymo comme base de comparaison dans nos expériences, et les résultats montrent que la méthode proposée présente des améliorations significatives en termes de précision et d'efficacité. Nous pensons que cette méthode jouera un rôle important dans la future technologie de conduite autonome
- Détection d'objet (Détection) : saisir une petite quantité de données de cadre de nuage de points continu et afficher le cadre de délimitation et les informations de catégorie de l'objet 3D dans chaque cadre.
- Suivi de cibles multiples (Tracking) : associe les objets détectés dans chaque image pour former une séquence d'objets et attribue un ID d'objet unique
- Classification de mouvement) : en fonction des caractéristiques de la trajectoire de l'objet, détermine l'état de mouvement de l'objet ; (stationnaire ou en mouvement); Affinage centré sur l'objet
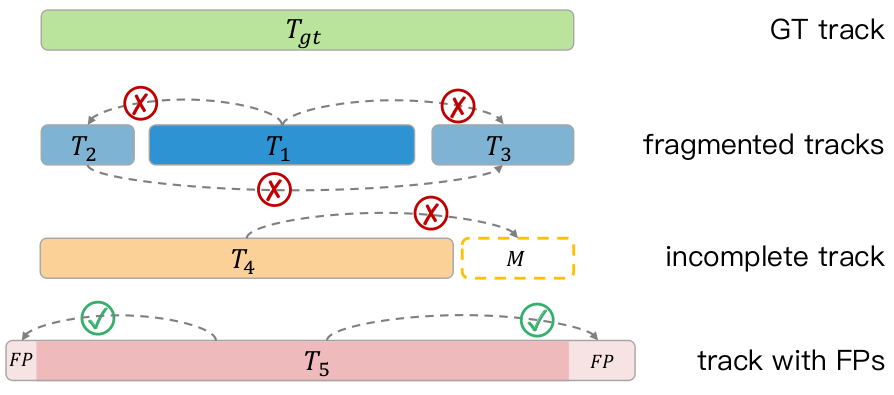
- : sur la base de l'état de mouvement prédit par le module précédent, extrayez les caractéristiques du nuage de points de la série chronologique des objets stationnaires et en mouvement respectivement pour prédire une boîte englobante précise. Enfin, le cadre de délimitation 3D optimisé est retransféré au système de coordonnées de chaque image où se trouve l'objet via la matrice de pose. Cependant, de nombreuses méthodes de détection d'objets 3D en ligne traditionnelles ont obtenu de meilleurs résultats que les méthodes de détection 3D hors ligne existantes en utilisant les fonctionnalités de contexte temporel des nuages de points. Cependant, nous avons réalisé que ces méthodes ne parvenaient pas à utiliser efficacement les caractéristiques des nuages de points à longue séquence. Les algorithmes actuels de détection et de suivi de cibles se concentrent principalement sur les indicateurs de performance au niveau du cadre de délimitation (niveau de la boîte), et l'algorithme de détection 3D en ligne est adopté. via TTA.Un grand nombre de trames redondantes générées après la fusion avec plusieurs modèles sont utilisées comme entrée dans l'algorithme de suivi, ce qui entraîne généralement facilement de graves problèmes tels que la segmentation de la trajectoire, la commutation d'ID et une association incorrecte. et des séquences d'objets complètes, entravant ainsi l'utilisation des fonctionnalités de nuage de points à long terme correspondant aux objets. Comme le montre la figure ci-dessous, la trajectoire originale d'un objet est divisée en plusieurs sous-séquences (T1, T2, T3), ce qui fait que les caractéristiques du segment T1 avec plus d'informations ne peuvent pas être partagées entre T2 et T3 ; dans le segment T4, les fragments perdus ne peuvent pas être rappelés ; la trame optimisée dans le fragment T5 reste FP après avoir été déplacée vers la position FP d'origine.
- La qualité de la séquence d'objets aura un grand impact sur le modèle d'optimisation en aval
- Le modèle d'optimisation basé sur l'état de mouvement prédit la taille de l'objet (a), et le modèle d'optimisation géométrique prédit la taille de l'objet après avoir agrégé tous les nuages de points sous différentes perspectives (b)
-
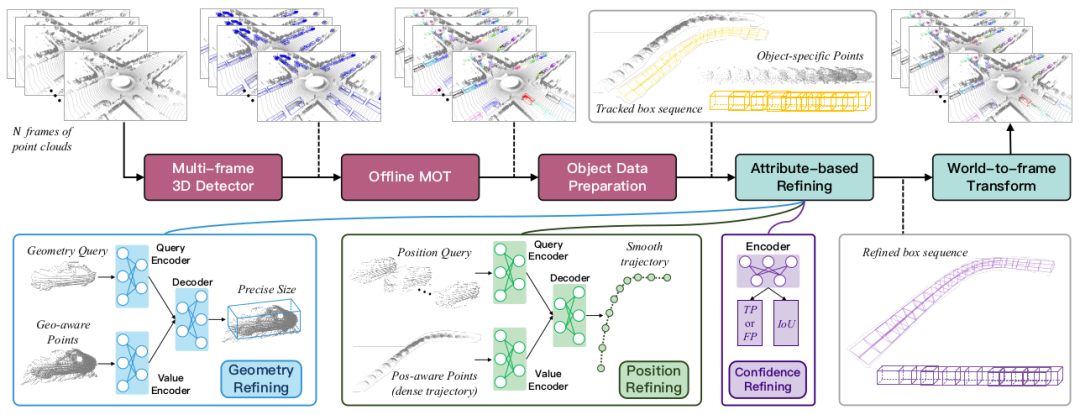
2 Méthode
Cet article propose un nouveau cadre d'algorithme de détection d'objets 3D hors ligne appelé DetZero. Ce cadre présente les caractéristiques suivantes : (1) Utiliser des détecteurs 3D multi-images et des trackers hors ligne comme modules en amont pour fournir un suivi d'objet précis et complet, en se concentrant sur un rappel élevé des séquences d'objets (rappel au niveau de la piste) ; comprend un modèle d'optimisation basé sur le mécanisme d'attention, qui utilise des fonctionnalités de nuage de points à long terme pour apprendre et prédire différents attributs des objets, notamment des dimensions géométriques affinées, des positions de trajectoire de mouvement fluide et des scores de confiance mis à jour

2.1 Générer un Séquence d'objets complète
Nous utilisons le CenterPoint[] public comme détecteur de base Afin de fournir davantage de trames candidates à la détection, nous l'avons amélioré sous trois aspects : (1) Utiliser différentes combinaisons de nuages de points de trame comme entrée pour maximiser les performances sans. réduire les performances ; (2) utiliser les informations de densité du nuage de points pour fusionner les caractéristiques du nuage de points d'origine et les caractéristiques de voxel dans un module en deux étapes afin d'optimiser les résultats des limites de la première étape (3) utiliser l'augmentation des données de l'étape d'inférence (TTA), multi ; -La fusion des résultats du modèle (Ensemble) et d'autres technologies sont utilisées pour améliorer l'adaptabilité du modèle aux environnements complexes. Une stratégie de corrélation en deux étapes est introduite dans le module de suivi hors ligne pour réduire les fausses correspondances. Les cadres sont divisés en groupes élevés et groupes faibles en fonction. à la confiance, et le groupe élevé est les associations mettant à jour les trajectoires existantes, et les trajectoires non mises à jour sont associées aux groupements faibles. Dans le même temps, la longueur de la trajectoire de l'objet peut durer jusqu'à la fin de la séquence, évitant ainsi les problèmes de commutation d'identification. De plus, nous exécuterons l'algorithme de suivi à l'envers pour générer un autre ensemble de trajectoires, les associerons via une similarité de position, et enfin utiliserons la stratégie WBF pour fusionner les trajectoires correctement appariées afin d'améliorer encore l'intégrité du début et de la fin de la séquence. Enfin, pour la séquence d'objets différenciés, le nuage de points correspondant à chaque image est extrait et enregistré ; les cases redondantes non mises à jour et certaines séquences plus courtes seront directement fusionnées dans la sortie finale sans optimisation en aval.
2.2 Module d'optimisation d'objets basé sur la prédiction d'attributsLe modèle d'optimisation centré sur l'objet précédent ignorait la corrélation entre les objets dans différents états de mouvement, comme la cohérence des formes géométriques et le mouvement des objets à des moments adjacents. Sur la base de ces observations, nous décomposons la tâche traditionnelle de régression de boîte englobante en trois modules : prédire respectivement la géométrie, l'emplacement et les attributs de confiance des objets
Interaction géométrique multi-vues : en épissant des nuages de points d'objets à partir de plusieurs vues, nous pouvons compléter le l'apparence et la forme de l'objet entier. Tout d'abord, une transformation de coordonnées locales est effectuée pour aligner le nuage de points de l'objet avec des boîtes locales à différentes positions, et la distance de projection de chaque point sur les six surfaces de la boîte englobante est calculée pour renforcer la représentation des informations de la boîte englobante, puis directement fusionner tous les nuages de points de différentes images En tant que clé et valeur des caractéristiques géométriques à vues multiples, t échantillons sont sélectionnés au hasard dans la séquence d'objets en tant que requêtes pour les caractéristiques géométriques à vue unique. La requête géométrique sera envoyée à la couche d'auto-attention pour voir les différences entre elles, puis envoyée à la couche d'attention croisée pour compléter les caractéristiques de la perspective requise et prédire la taille géométrique précise.- Interaction entre les positions locales et globales : sélectionnez aléatoirement n'importe quelle case de la séquence d'objets comme origine, transférez toutes les autres cases et les nuages de points d'objet correspondants vers ce système de coordonnées et calculez la somme de chaque point jusqu'au point central de la délimitation respective. box La distance entre les huit points d'angle sert de clé et de valeur de la fonction de position globale. Chaque échantillon de la séquence d'objets sera utilisé comme requête de position et envoyé à la couche d'auto-attention pour déterminer la distance relative entre la position actuelle et les autres positions. Il est ensuite entré dans la couche d'attention croisée pour simuler la relation contextuelle. les positions locales aux positions globales et prédire ce système de coordonnées. Le décalage entre chaque point central initial et le véritable point central, ainsi que la différence d'angle de cap.
- Optimisation de la confiance : la branche de classification est utilisée pour classer si l'objet est TP ou FP. La branche de régression IoU prédit la taille IoU entre un objet et la boîte de vérité terrain après avoir été optimisée par le modèle géométrique et le modèle de position. Le score de confiance final est la moyenne géométrique de ces deux branches.
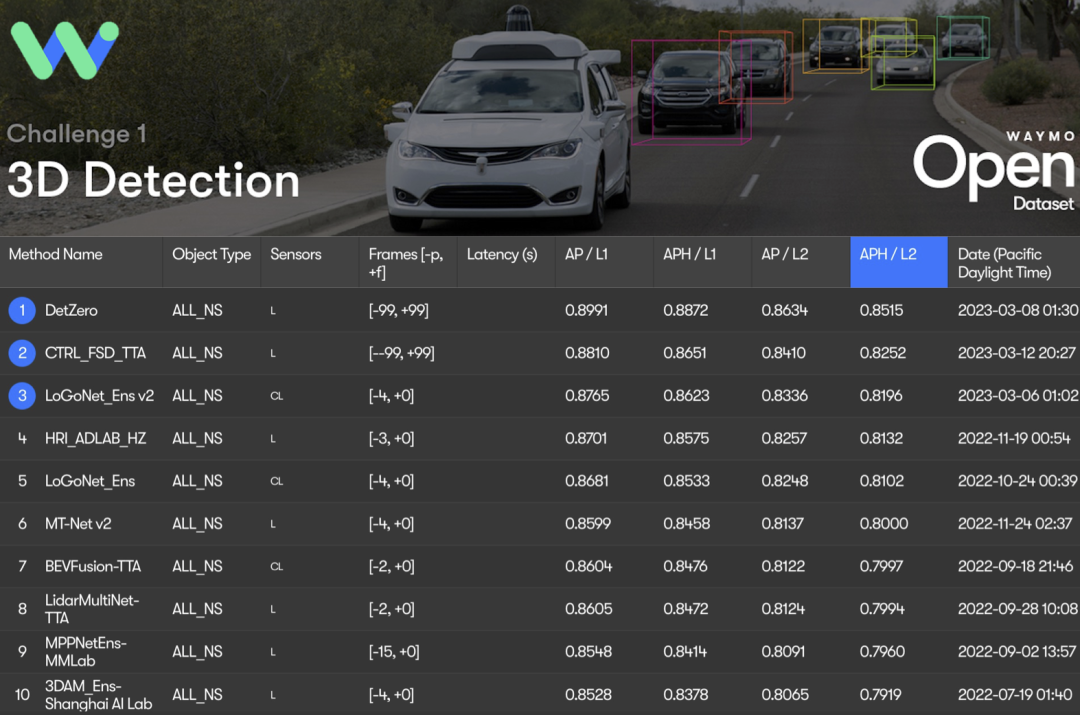
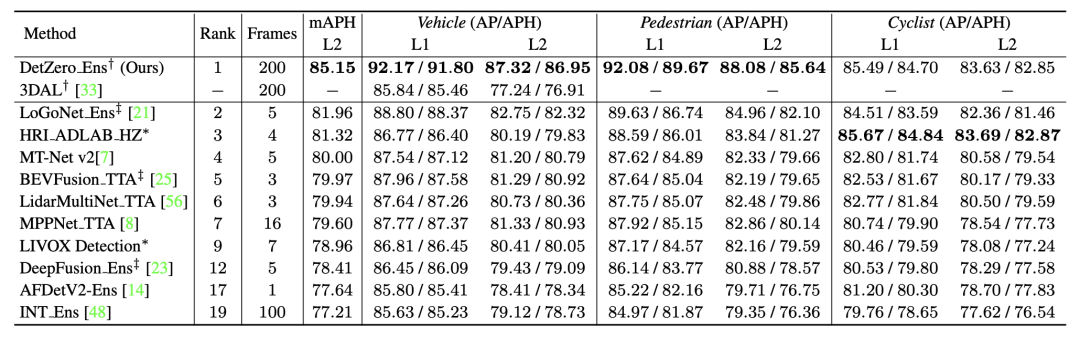
3.1 Performance principale
DetZero obtient le meilleur résultat du classement de détection 3D Waymo avec 85,15 mAPH (L2), tous deux comparés aux méthodes qui traitent des nuages de points en séries longues. Par rapport au plus grand nombre. Détecteurs 3D de fusion multimodaux avancés, DetZero a démontré des avantages de performance significatifs
Résultats du classement de détection 3D Waymo, tous les résultats utilisent la technologie TTA ou d'ensemble, † fait référence au modèle hors ligne, ‡ fait référence au modèle de fusion d'images en nuage de points, * indique une soumission anonyme résultats
Classement de suivi Waymo 3D, * indique la soumission anonyme des résultatsDe même, grâce à la précision du cadre de détection et à l'intégrité de la séquence de suivi des objets, nous avons obtenu la première performance au classement de suivi Waymo 3D avec 75,05 MOTA (L2). 3.2 Expérience d'ablation
Afin de mieux vérifier le rôle de chaque module que nous avons proposé, nous avons mené une expérience d'ablation sur l'ensemble de vérification Waymo et adopté un seuil IoU plus strict comme norme de mesure
Expériences de validation croisée de différentes combinaisons de modules en amont et en aval, les indices 1 et 2 représentent respectivement 3DAL et DetZero, et l'indicateur est 3D APHVérifié dans Waymo Nous Nous avons effectué cette opération sur les véhicules et les piétons et avons sélectionné la valeur standard (0,7 et 0,5) et la valeur stricte (0,8 et 0,6) pour le seuil IoU. Dans le même temps, pour le même ensemble de résultats de détection, nous avons sélectionné le tracker et l'optimisation. Le modèle en 3DAL et DetZero respectivement. Une vérification de combinaison croisée a été effectuée, et les résultats ont en outre prouvé que le tracker et l'optimiseur de DetZero fonctionnaient mieux et que la combinaison des deux présentait de plus grands avantages.
Comparaison des performances du tracker hors ligne (Trk2) et du tracker 3DAL (Trk1), performances de MOTA et Recall@trackNotre tracker hors ligne accorde plus d'attention à l'intégrité de la séquence d'objets, bien que le Les performances MOTA des deux sont différentes. C'est petit, mais les performances de Recall@track sont l'une des raisons de la grande différence dans les performances d'optimisation finale
Recall@track est le rappel de séquence traité par l'algorithme de suivi, 3D APH est la performance finale traitée par le même modèle d'optimisation De plus, cela est démontré par rapport à d'autres trackers de pointe
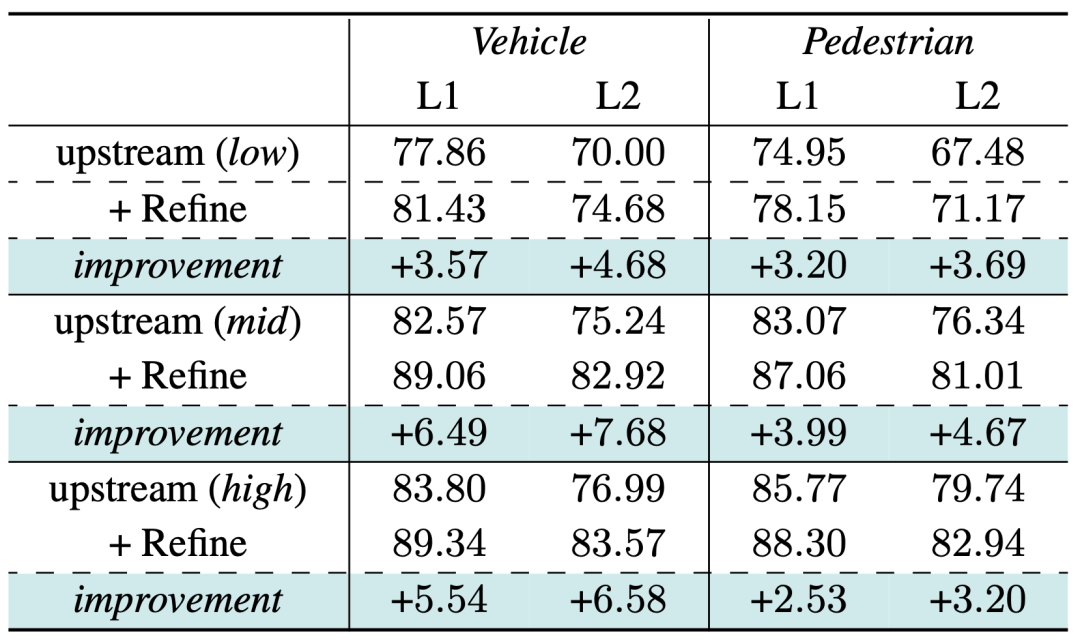
3.3 Performances de généralisationPour vérifier si notre modèle d'optimisation peut être adapté de manière fixe à un ensemble de résultats en amont spécifique, nous avons sélectionné des résultats de suivi de détection en amont avec des performances différentes en entrée. Les résultats montrent que nous avons obtenu des améliorations significatives des performances, prouvant en outre que tant que le module en amont peut rappeler des séquences d'objets de plus en plus complètes, notre optimiseur peut utiliser efficacement les caractéristiques de son nuage de points de série chronologique pour l'optimisation
Ensemble de validation Waymo Vérification des performances de généralisation, l'indicateur est 3D APH
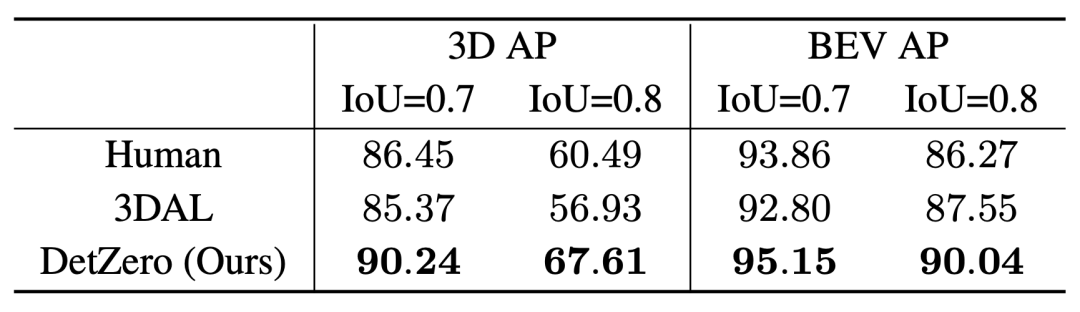
3.4 Comparaison avec la capacité d'étiquetage humaineNous rapporterons les performances AP de DetZero sur 5 séquences spécifiées basées sur les paramètres expérimentaux de 3DAL, en comparant sur la base d'images uniques. La performance humaine est mesurée par la cohérence des résultats ré-étiquetés avec les résultats originaux étiquetés selon la vérité terrain. Par rapport au 3DAL et aux humains, DetZero a montré des avantages dans différents indicateurs de performance
Comparaison des performances de 3D AP et BEV AP sous différents seuils IoU pour la catégorie Véhicule
Résultats expérimentaux semi-supervisés sur l'ensemble de validation Waymo Afin de vérifier si des résultats d'annotation automatique de haute qualité peuvent remplacer le manuel les résultats des annotations ont été utilisés pour la formation de modèles en ligne et nous avons effectué une vérification d'apprentissage semi-supervisée sur l'ensemble de vérification Waymo. Nous avons sélectionné au hasard 10 % des données de formation comme données de formation pour le modèle d'enseignant (DetZero) et effectué une inférence sur les 90 % de données restantes pour obtenir des résultats d'annotation automatique, qui seront utilisés comme étiquettes pour le modèle d'étudiant. Nous avons choisi CenterPoint à image unique comme modèle étudiant. Sur la catégorie véhicule, les résultats de l'entraînement utilisant 90% d'étiquettes automatiques et 10% d'étiquettes vraies sont proches des résultats de l'entraînement utilisant 100% d'étiquettes vraies, tandis que sur la catégorie piéton, les résultats du modèle entraîné avec des étiquettes automatiques sont déjà meilleurs. que ceux d'origine. Le résultat, qui montre que l'étiquetage automatique peut être utilisé pour la formation de modèles en ligne
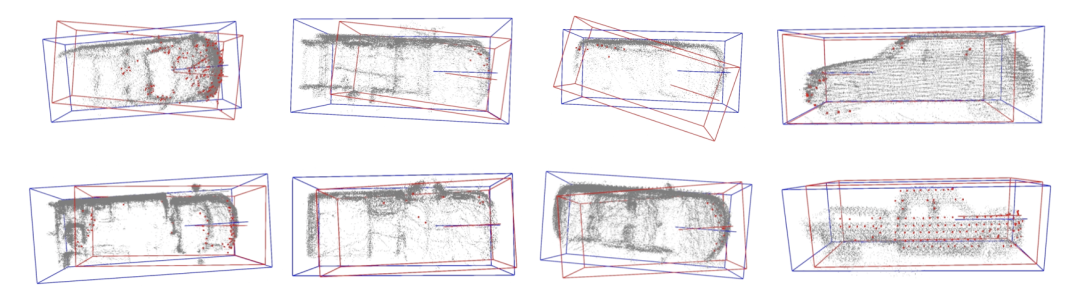
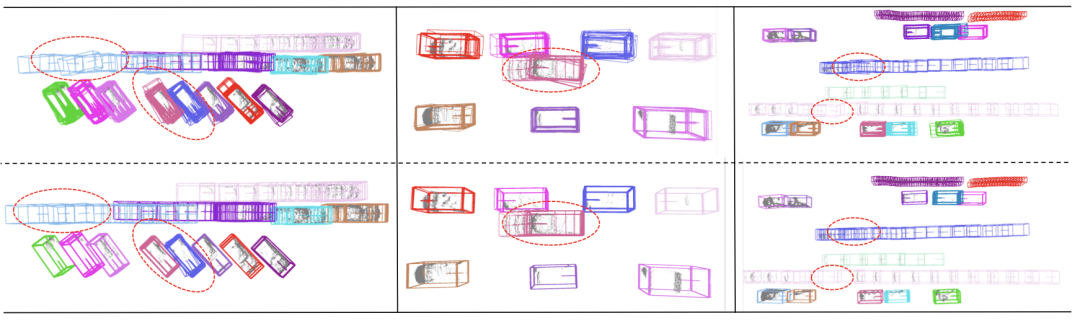
3.5 Résultats visualisésLa case rouge représente l'entrée en amont. résultats, et la boîte bleue représente le modèle optimisé. Les résultats de sortie
La première ligne représente les résultats d'entrée en amont, la deuxième ligne représente les résultats de sortie du modèle d'optimisation et les objets entre les lignes pointillées représentent les emplacements où la différence est évidente. avant et après optimisation
Lien original : https://mp.weixin.qq.com/s/HklBecJfMOUCC8gclo-t7Q
 De même, grâce à la précision du cadre de détection et à l'intégrité de la séquence de suivi des objets, nous avons obtenu la première performance au classement de suivi Waymo 3D avec 75,05 MOTA (L2).
De même, grâce à la précision du cadre de détection et à l'intégrité de la séquence de suivi des objets, nous avons obtenu la première performance au classement de suivi Waymo 3D avec 75,05 MOTA (L2). 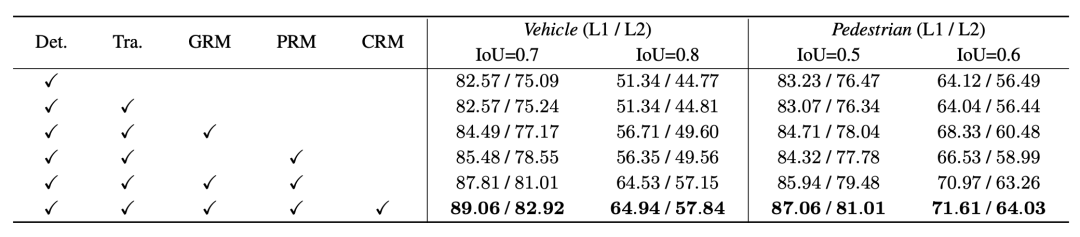 Vérifié dans Waymo Nous Nous avons effectué cette opération sur les véhicules et les piétons et avons sélectionné la valeur standard (0,7 et 0,5) et la valeur stricte (0,8 et 0,6) pour le seuil IoU. Dans le même temps, pour le même ensemble de résultats de détection, nous avons sélectionné le tracker et l'optimisation. Le modèle en 3DAL et DetZero respectivement. Une vérification de combinaison croisée a été effectuée, et les résultats ont en outre prouvé que le tracker et l'optimiseur de DetZero fonctionnaient mieux et que la combinaison des deux présentait de plus grands avantages.
Vérifié dans Waymo Nous Nous avons effectué cette opération sur les véhicules et les piétons et avons sélectionné la valeur standard (0,7 et 0,5) et la valeur stricte (0,8 et 0,6) pour le seuil IoU. Dans le même temps, pour le même ensemble de résultats de détection, nous avons sélectionné le tracker et l'optimisation. Le modèle en 3DAL et DetZero respectivement. Une vérification de combinaison croisée a été effectuée, et les résultats ont en outre prouvé que le tracker et l'optimiseur de DetZero fonctionnaient mieux et que la combinaison des deux présentait de plus grands avantages. 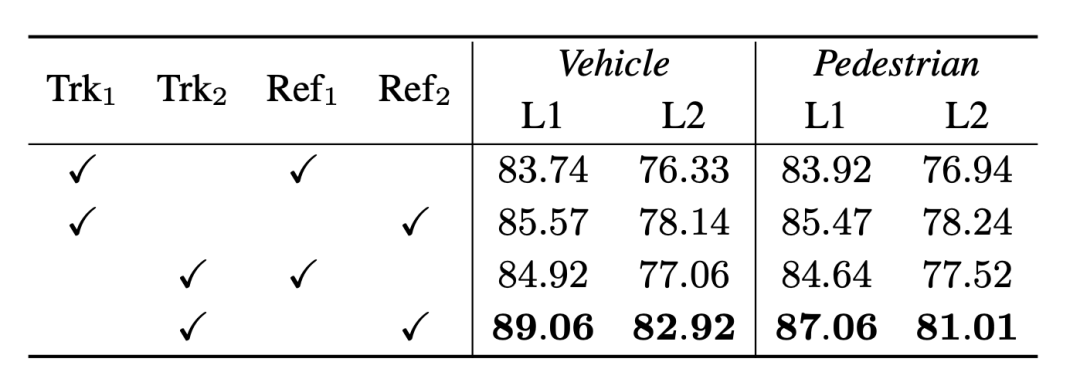 Notre tracker hors ligne accorde plus d'attention à l'intégrité de la séquence d'objets, bien que le Les performances MOTA des deux sont différentes. C'est petit, mais les performances de Recall@track sont l'une des raisons de la grande différence dans les performances d'optimisation finale
Notre tracker hors ligne accorde plus d'attention à l'intégrité de la séquence d'objets, bien que le Les performances MOTA des deux sont différentes. C'est petit, mais les performances de Recall@track sont l'une des raisons de la grande différence dans les performances d'optimisation finale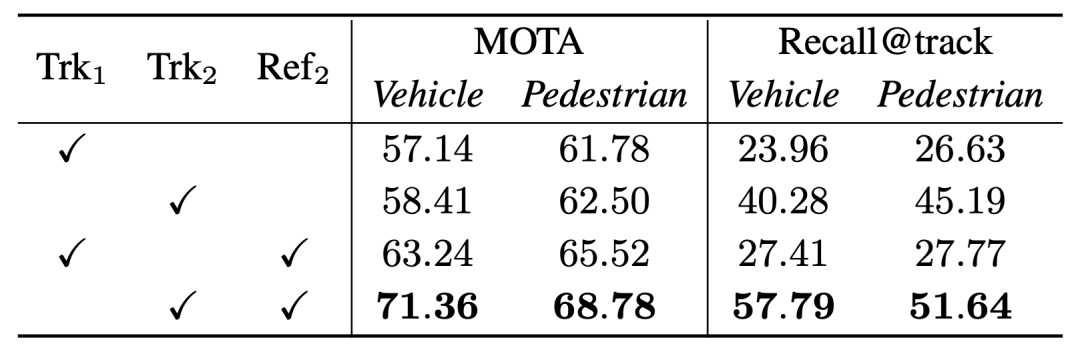 De plus, cela est démontré par rapport à d'autres trackers de pointe
De plus, cela est démontré par rapport à d'autres trackers de pointe 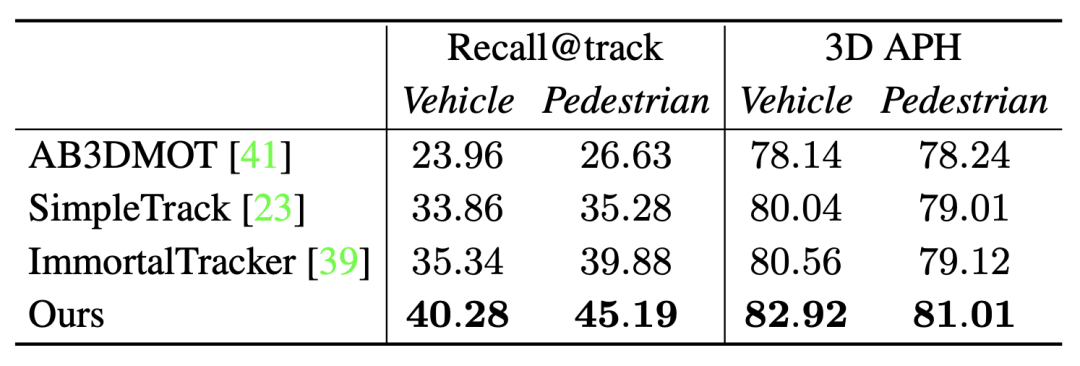
 Afin de vérifier si des résultats d'annotation automatique de haute qualité peuvent remplacer le manuel les résultats des annotations ont été utilisés pour la formation de modèles en ligne et nous avons effectué une vérification d'apprentissage semi-supervisée sur l'ensemble de vérification Waymo. Nous avons sélectionné au hasard 10 % des données de formation comme données de formation pour le modèle d'enseignant (DetZero) et effectué une inférence sur les 90 % de données restantes pour obtenir des résultats d'annotation automatique, qui seront utilisés comme étiquettes pour le modèle d'étudiant. Nous avons choisi CenterPoint à image unique comme modèle étudiant. Sur la catégorie véhicule, les résultats de l'entraînement utilisant 90% d'étiquettes automatiques et 10% d'étiquettes vraies sont proches des résultats de l'entraînement utilisant 100% d'étiquettes vraies, tandis que sur la catégorie piéton, les résultats du modèle entraîné avec des étiquettes automatiques sont déjà meilleurs. que ceux d'origine. Le résultat, qui montre que l'étiquetage automatique peut être utilisé pour la formation de modèles en ligne
Afin de vérifier si des résultats d'annotation automatique de haute qualité peuvent remplacer le manuel les résultats des annotations ont été utilisés pour la formation de modèles en ligne et nous avons effectué une vérification d'apprentissage semi-supervisée sur l'ensemble de vérification Waymo. Nous avons sélectionné au hasard 10 % des données de formation comme données de formation pour le modèle d'enseignant (DetZero) et effectué une inférence sur les 90 % de données restantes pour obtenir des résultats d'annotation automatique, qui seront utilisés comme étiquettes pour le modèle d'étudiant. Nous avons choisi CenterPoint à image unique comme modèle étudiant. Sur la catégorie véhicule, les résultats de l'entraînement utilisant 90% d'étiquettes automatiques et 10% d'étiquettes vraies sont proches des résultats de l'entraînement utilisant 100% d'étiquettes vraies, tandis que sur la catégorie piéton, les résultats du modèle entraîné avec des étiquettes automatiques sont déjà meilleurs. que ceux d'origine. Le résultat, qui montre que l'étiquetage automatique peut être utilisé pour la formation de modèles en ligne 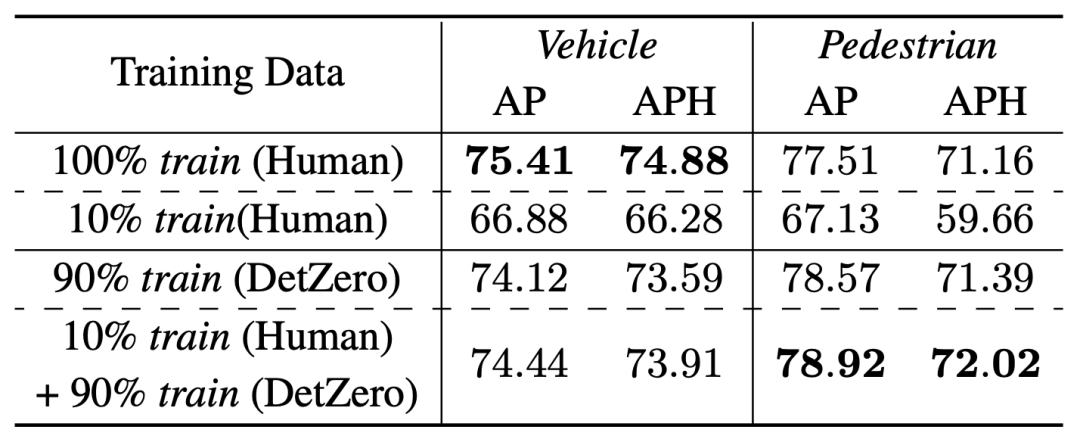
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
