
 Périphériques technologiques
IA
Réalisez 13 tâches de langage visuel ! L'Institut de technologie de Harbin lance le grand modèle multimodal « Jiutian », dont les performances augmentent de 5 %
Périphériques technologiques
IA
Réalisez 13 tâches de langage visuel ! L'Institut de technologie de Harbin lance le grand modèle multimodal « Jiutian », dont les performances augmentent de 5 %
Réalisez 13 tâches de langage visuel ! L'Institut de technologie de Harbin lance le grand modèle multimodal « Jiutian », dont les performances augmentent de 5 %

Afin de résoudre le problème de l'extraction insuffisante d'informations visuelles dans les grands modèles de langage multimodaux, des chercheurs de l'Institut de technologie de Harbin (Shenzhen) ont proposé un modèle de grand langage multimodal à double couche amélioré par les connaissances, JiuTian-LION.

Le contenu qui doit être réécrit est : Lien papier : https://arxiv.org/abs/2311.11860
GitHub : https://github.com/rshaojimmy/JiuTian
Page d'accueil du projet : https://rshaojimmy.github.io/Projects/JiuTian-LION
Par rapport aux travaux existants, JiuTian a analysé pour la première fois les conflits internes entre les tâches de compréhension au niveau de l'image et les tâches de positionnement au niveau de la région. , et a proposé une stratégie de réglage fin des instructions segmentées et un adaptateur hybride pour parvenir à une amélioration mutuelle des deux tâches.
En injectant une perception spatiale fine et des connaissances visuelles sémantiques de haut niveau, Jiutian a obtenu des améliorations significatives des performances sur 17 tâches de langage visuel, notamment la description d'image, les problèmes visuels et la localisation visuelle (par exemple jusqu'à 5 sur le raisonnement spatial visuel). ) % d'amélioration des performances), atteignant le premier niveau international dans 13 tâches d'évaluation. La comparaison des performances est présentée dans la figure 1.
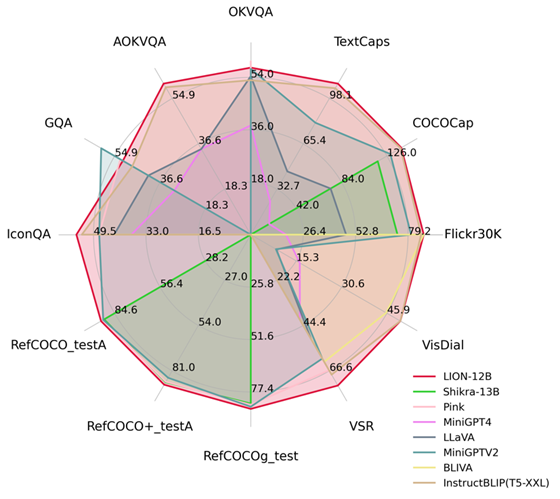
Figure 1 : Comparé à d'autres MLLM, Jiutian a atteint des performances optimales sur la plupart des tâches.
JiuTian-LION
En donnant aux grands modèles de langage (LLM) des capacités de perception multimodale, certains travaux ont commencé pour générer de grands modèles de langage (MLLM) multimodaux et ont fait des progrès révolutionnaires sur de nombreuses tâches de langage visuel. Cependant, les MLLM existants utilisent principalement des encodeurs visuels pré-entraînés sur des paires image-texte, tels que CLIP-ViT
La tâche principale de ces encodeurs visuels est d'apprendre l'alignement modal image-texte à gros grain au niveau de l'image, mais ils manquent de capacités complètes de perception visuelle et d'extraction d'informations, incapables d'effectuer une compréhension visuelle fine
Dans une large mesure, ce problème d'extraction d'informations visuelles insuffisante et de compréhension insuffisante entraînera un biais de positionnement visuel, un raisonnement spatial insuffisant et une insuffisance compréhension des MLLM. Il existe de nombreux défauts tels que l'illusion d'objet, comme le montre la figure 2
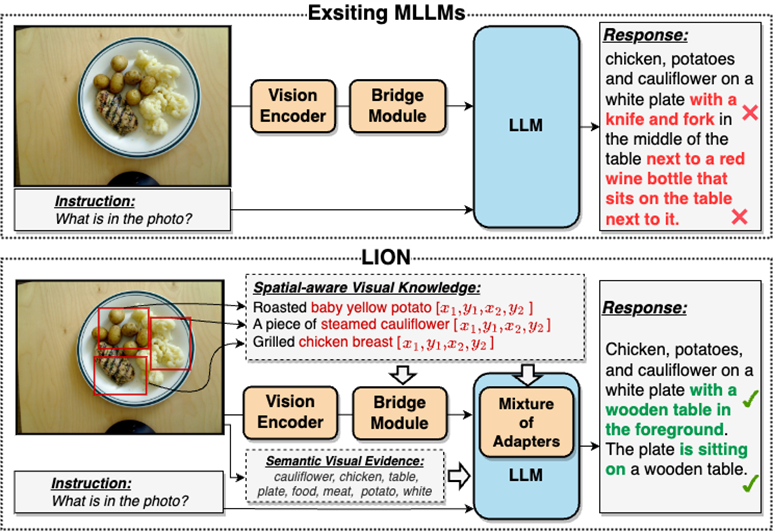
Veuillez vous référer à la figure 2 : JiuTian-LION est un grand modèle de langage multimodal amélioré avec des connaissances visuelles à double couche
Par rapport aux grands modèles de langage multimodaux (MLLM) existants, Jiutian améliore efficacement les capacités de compréhension visuelle des MLLM en injectant des connaissances visuelles de conscience spatiale à granularité fine et des preuves visuelles sémantiques de haut niveau, génère des réponses textuelles plus précises et réduit Le phénomène d'hallucination des MLLM
Modèle de grand langage multimodal à double couche amélioré par les connaissances visuelles-JiuTian-LION
Afin de résoudre les lacunes des MLLM dans l'extraction et la compréhension des informations visuelles, les chercheurs ont proposé un Une méthode MLLM améliorée de connaissances visuelles à double couche est proposée, appelée JiuTian-LION. Le cadre spécifique de la méthode est présenté dans la figure 3
Cette méthode améliore principalement les MLLM sous deux aspects, l'intégration progressive de connaissances visuelles spatiales à grain fin (Incorporation progressive de connaissances visuelles spatiales à grain fin) et de haut niveau. logiciel sous invites logicielles Invite douce de preuves visuelles sémantiques de haut niveau.
Plus précisément, les chercheurs ont proposé une stratégie de réglage fin des instructions segmentées pour résoudre le conflit interne entre la tâche de compréhension au niveau de l'image et la tâche de localisation au niveau de la région. Ils injectent progressivement des connaissances fines en matière de conscience spatiale dans les MLLM. Dans le même temps, ils ont ajouté des étiquettes d'image comme preuve visuelle sémantique de haut niveau aux MLLM et ont utilisé des méthodes d'invite douces pour atténuer l'impact négatif que des étiquettes incorrectes peuvent apporter. Le diagramme du cadre du modèle JiuTian-LION est le suivant :
.Ce travail utilise une stratégie de formation segmentée pour apprendre d'abord la compréhension au niveau de l'image et les tâches de positionnement au niveau de la région basées respectivement sur les branches Q-Former et Vision Aggregator-MLP, puis utilise un adaptateur hybride avec un mécanisme de routage pour fusionner dynamiquement différentes tâches. dans la phase finale de formation. Exécution du modèle d'amélioration des connaissances ramifiées sur deux tâches.
Ce travail extrait également les étiquettes d'image en tant que preuve visuelle sémantique de haut niveau via la RAM, puis propose une méthode d'invite douce pour améliorer l'effet de l'injection sémantique de haut niveau
Fusionner progressivement les visuels de conscience spatiale à granularité fine connaissances
Lors de l'exécution directe d'une formation mixte en une seule étape sur des tâches de compréhension au niveau de l'image (y compris la description de l'image et la réponse visuelle aux questions) et des tâches de localisation au niveau régional (y compris la compréhension d'expression dirigée, la génération d'expression dirigée, etc.), les MLLM rencontrera des conflits internes entre les deux tâches. En conséquence, une meilleure performance globale ne pourra pas être obtenue sur toutes les tâches.
Les chercheurs estiment que ce conflit interne est principalement causé par deux problèmes. Le premier problème est le manque de pré-formation à l'alignement modal au niveau régional. Actuellement, la plupart des MLLM dotés de capacités de positionnement au niveau régional utilisent d'abord une grande quantité de données pertinentes pour la pré-formation, sinon il sera difficile d'utiliser le niveau image. alignement modal basé sur des ressources de formation limitées. Adaptation des fonctionnalités visuelles aux tâches au niveau régional.
Un autre problème est la différence dans les modèles d'entrée-sortie entre les tâches de compréhension au niveau de l'image et les tâches de localisation au niveau de la région, ces dernières nécessitant que le modèle comprenne en outre des phrases courtes spécifiques sur les coordonnées des objets (sous la forme de 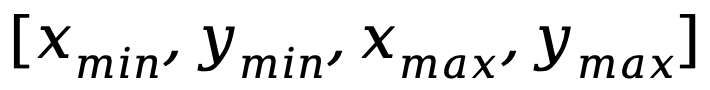 ) . Afin de résoudre les problèmes ci-dessus, les chercheurs ont proposé une stratégie de réglage fin des instructions segmentées et un adaptateur hybride avec un mécanisme de routage.
) . Afin de résoudre les problèmes ci-dessus, les chercheurs ont proposé une stratégie de réglage fin des instructions segmentées et un adaptateur hybride avec un mécanisme de routage.
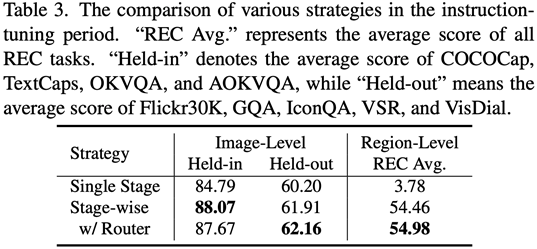
Comme le montre la figure 4, les chercheurs ont divisé le processus de réglage fin des instructions en une seule étape en trois étapes :
Utilisez ViT, Q-Former et l'adaptateur au niveau de l'image pour apprendre la tâche de compréhension au niveau de l'image de connaissances visuelles globales ; utiliser Vision Aggregator, MLP et les adaptateurs au niveau régional pour apprendre les tâches de positionnement au niveau régional avec des connaissances visuelles spatiales à granularité fine ; un adaptateur hybride avec un mécanisme de routage est proposé pour intégrer dynamiquement les connaissances visuelles de différentes granularités apprises dans différents branches. Le tableau 3 montre les avantages en termes de performances de la stratégie de réglage fin de l'instruction segmentée par rapport à la formation en une seule étape
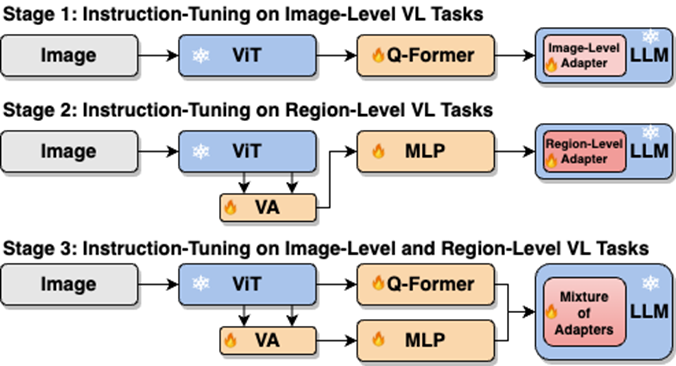
Figure 4 : La stratégie de réglage fin de l'instruction segmentée
pour l'injection de logiciels invites Les preuves visuelles sémantiques de haut niveau doivent être réécrites
Les chercheurs ont proposé d'utiliser des étiquettes d'images comme un complément efficace aux preuves visuelles sémantiques de haut niveau pour améliorer encore la capacité de compréhension de la perception visuelle globale des MLLM
Plus précisément, extrayez d'abord les balises de l'image via la RAM, puis utilisez le modèle de commande spécifique « Selon
Couplé à l'expression spécifique « utiliser ou utiliser partiellement » dans le modèle, le vecteur d'indice doux peut guider le modèle pour atténuer l'impact négatif potentiel des étiquettes incorrectes.
Résultats expérimentaux
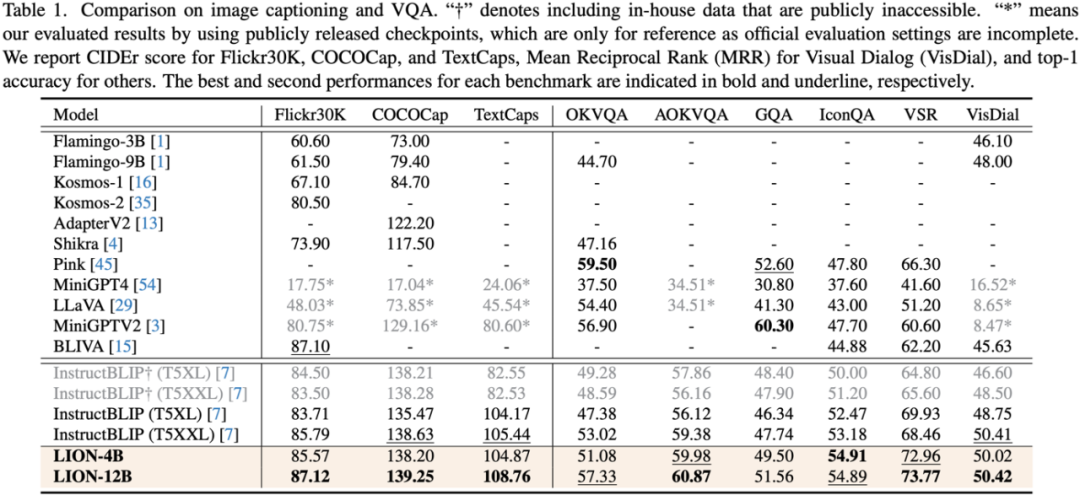
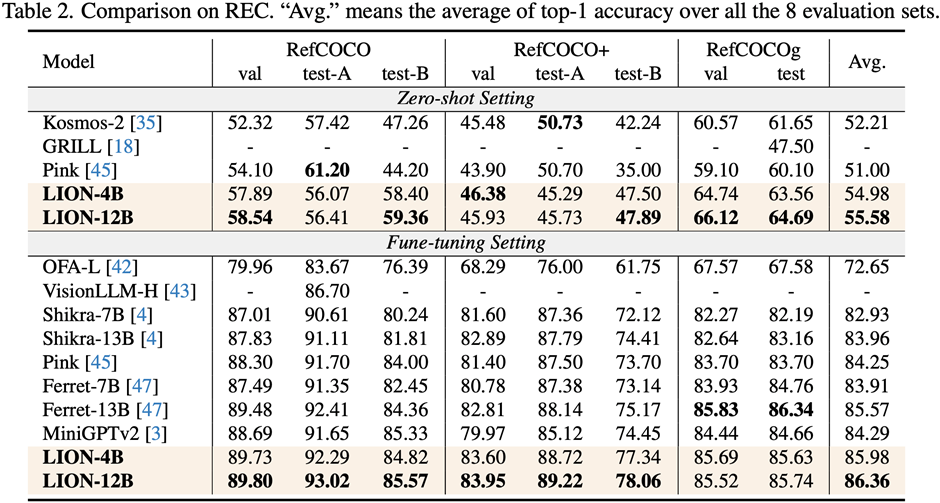
Les chercheurs ont mené des évaluations sur 17 ensembles de tâches de référence, notamment le sous-titrage d'images, la réponse visuelle aux questions (VQA) et la compréhension de l'expression pédagogique (REC).
Les résultats expérimentaux montrent que Jiutian a atteint le premier niveau international dans 13 ensembles d'évaluation. En particulier, par rapport à InstructBLIP et Shikra, Jiutian a obtenu des améliorations complètes et cohérentes des performances dans les tâches de compréhension au niveau de l'image et les tâches de positionnement au niveau de la région, respectivement, et peut atteindre jusqu'à 5 % d'amélioration dans les tâches de raisonnement visuel spatial (VSR).
Comme le montre la figure 5, il existe des différences dans les capacités de Jiutian et d'autres MLLM dans différentes tâches multimodales de langage visuel, indiquant que Jiutian est plus performant en termes de compréhension visuelle fine et de capacités de raisonnement spatial visuel, et est capable pour produire une sortie avec une réponse textuelle moins hallucinante

Le contenu réécrit est : La cinquième figure montre une analyse qualitative de la différence de capacités du grand modèle Jiutian, InstructBLIP et Shikra
Figure 6 Par analyse d'échantillon , Cela montre que le modèle Jiutian possède d'excellentes capacités de compréhension et de reconnaissance dans les tâches de langage visuel au niveau de l'image et au niveau régional.

La sixième image : Grâce à l'analyse de plus d'exemples, les capacités du grand modèle Jiutian sont démontrées du point de vue de l'image et de la compréhension visuelle au niveau régional
Résumé
(1) Ceci le travail propose Un nouveau modèle de grand langage multimodal - Jiutian : un grand modèle de langage multimodal amélioré par des connaissances visuelles à double couche.
(2) Ce travail a été évalué sur 17 ensembles de référence de tâches de langage visuel comprenant la description d'image, la réponse visuelle aux questions et la compréhension des expressions pédagogiques, parmi lesquels 13 ensembles d'évaluation ont obtenu la meilleure performance actuelle.
(3) Ce travail propose une stratégie de réglage fin de l'instruction segmentée pour résoudre le conflit interne entre les tâches de compréhension au niveau de l'image et de localisation au niveau de la région, et parvenir à une amélioration mutuelle entre les deux tâches
(4) Ce Le travail intègre avec succès la compréhension au niveau de l'image et les tâches de positionnement au niveau régional pour comprendre de manière globale les scènes visuelles à plusieurs niveaux. À l'avenir, cette capacité de compréhension visuelle complète pourra être appliquée aux scènes intelligentes incarnées pour aider les robots à fonctionner de manière plus efficace et plus intelligente. comprendre l’environnement actuel pour prendre des décisions efficaces.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Le réglage des performances de Zookeeper sur CentOS peut commencer à partir de plusieurs aspects, notamment la configuration du matériel, l'optimisation du système d'exploitation, le réglage des paramètres de configuration, la surveillance et la maintenance, etc. Assez de mémoire: allouez suffisamment de ressources de mémoire à Zookeeper pour éviter la lecture et l'écriture de disques fréquents. CPU multi-core: utilisez un processeur multi-core pour vous assurer que Zookeeper peut le traiter en parallèle.
 Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Une formation efficace des modèles Pytorch sur les systèmes CentOS nécessite des étapes, et cet article fournira des guides détaillés. 1. Préparation de l'environnement: Installation de Python et de dépendance: le système CentOS préinstalle généralement Python, mais la version peut être plus ancienne. Il est recommandé d'utiliser YUM ou DNF pour installer Python 3 et Mettez PIP: sudoyuMupDatePython3 (ou sudodnfupdatepython3), pip3install-upradepip. CUDA et CUDNN (accélération GPU): Si vous utilisez Nvidiagpu, vous devez installer Cudatool
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Lors de la sélection d'une version Pytorch sous CentOS, les facteurs clés suivants doivent être pris en compte: 1. CUDA Version Compatibilité GPU Prise en charge: si vous avez NVIDIA GPU et que vous souhaitez utiliser l'accélération GPU, vous devez choisir Pytorch qui prend en charge la version CUDA correspondante. Vous pouvez afficher la version CUDA prise en charge en exécutant la commande nvidia-SMI. Version CPU: Si vous n'avez pas de GPU ou que vous ne souhaitez pas utiliser de GPU, vous pouvez choisir une version CPU de Pytorch. 2. Version Python Pytorch
