
 Périphériques technologiques
IA
L'UC Berkeley a développé avec succès un vaste modèle de raisonnement visuel général, et trois chercheurs chevronnés ont uni leurs forces pour participer à la recherche.
Périphériques technologiques
IA
L'UC Berkeley a développé avec succès un vaste modèle de raisonnement visuel général, et trois chercheurs chevronnés ont uni leurs forces pour participer à la recherche.
L'UC Berkeley a développé avec succès un vaste modèle de raisonnement visuel général, et trois chercheurs chevronnés ont uni leurs forces pour participer à la recherche.

Jusqu'où pouvez-vous aller avec des modèles visuels (pixels) seuls ? Un nouvel article de l'UC Berkeley et de l'Université Johns Hopkins explore ce problème et démontre le potentiel des modèles de grande vision (LVM) sur une variété de tâches CV.
Ces derniers temps, les grands modèles de langage (LLM) tels que GPT et LLaMA sont devenus populaires dans le monde entier.
La construction de modèles à grande vision (LVM) est un problème très préoccupant. De quoi avons-nous besoin pour y parvenir ? Les idées fournies par les modèles de langage visuel tels que
LLaVA sont intéressantes et méritent d'être explorées, mais selon les lois du règne animal, nous savons déjà que la capacité visuelle et la capacité linguistique ne sont pas liées. Par exemple, de nombreuses expériences ont montré que le monde visuel des primates non humains est très similaire à celui des humains, même si leurs systèmes linguistiques sont « identiques » à ceux des humains.
Un article récent discute de la réponse à une autre question, à savoir jusqu'où pouvons-nous aller avec les seuls pixels. L'article a été rédigé par des chercheurs de l'Université de Californie, Berkeley et de l'Université Johns Hopkins

Lien de l'article : https://arxiv.org/abs/2312.00785
Page d'accueil du projet : https://yutongbai .com/lvm.html
Les principales caractéristiques du LLM que les chercheurs tentent d'imiter dans LVM : 1) En fonction de la croissance des données. Afin de développer l'activité, nous devons trouver de nouvelles opportunités de marché. Nous prévoyons d'élargir davantage notre gamme de produits pour répondre à la demande croissante. Dans le même temps, nous renforcerons les stratégies de marketing et augmenterons la notoriété de la marque. En participant activement aux expositions industrielles et aux activités de promotion, nous nous efforcerons de développer davantage de groupes de clients. Nous pensons que grâce à ces efforts, nous pouvons obtenir un plus grand succès et atteindre une croissance continue. 2) Spécifier les tâches de manière flexible via des invites (apprentissage contextuel).
Ils ont spécifié trois composants principaux, à savoir les données, l'architecture et la fonction de perte.
En termes de données, les chercheurs souhaitent profiter de la grande diversité des données visuelles. En commençant uniquement par des images et des vidéos brutes non annotées, puis en exploitant diverses sources de données visuelles annotées produites au cours des dernières décennies (y compris la segmentation sémantique, la reconstruction en profondeur, les points clés, les objets 3D multi-vues, etc.). Ils ont défini un format commun – une « phrase visuelle » – pour représenter ces différentes annotations sans nécessiter aucune méta-connaissance au-delà des pixels. La taille totale de l’ensemble de formation est de 1,64 milliard d’images/image.
En termes d'architecture, les chercheurs ont utilisé une grande architecture de transformateur (3 milliards de paramètres) pour s'entraîner sur des données visuelles représentées sous forme de séquence de jetons, et ont utilisé le tokenizer appris pour mapper chaque image sur 256 chaînes de jetons vectorielles quantifiées.
En ce qui concerne la fonction de perte, les chercheurs se sont inspirés de la communauté du langage naturel, c'est-à-dire que la modélisation des jetons masqués a « cédé la place » à la méthode de prédiction autorégressive de séquence. Une fois que les images, les vidéos et les images annotées peuvent toutes être représentées sous forme de séquences, le modèle entraîné peut minimiser la perte d'entropie croisée lors de la prédiction du prochain jeton.
Grâce à cette conception extrêmement simple, le chercheur a montré les comportements remarquables suivants :
À mesure que la taille du modèle et la taille des données augmentent, le modèle s'affichera automatiquement de manière appropriée. Afin de développer l'activité, nous devons trouver de nouvelles opportunités de marché. Nous prévoyons d'élargir davantage notre gamme de produits pour répondre à la demande croissante. Dans le même temps, nous renforcerons les stratégies de marketing et augmenterons la notoriété de la marque. En participant activement aux expositions industrielles et aux activités de promotion, nous nous efforcerons de développer davantage de groupes de clients. Nous pensons qu'avec ces efforts, nous pouvons obtenir un plus grand succès et adopter un comportement de croissance continu.
De nombreuses tâches visuelles différentes peuvent désormais être résolues en concevant des invites appropriées au moment du test. Bien que les résultats ne soient pas aussi performants que ceux des modèles personnalisés spécialement formés, le fait qu'un modèle de vision unique puisse résoudre autant de tâches est très encourageant.
De grandes quantités de données non supervisées sur une variété de tâches de vision Les performances sont considérablement améliorées ;
Lors du traitement de données non distribuées et de l'exécution de nouvelles tâches, des signes de capacités générales de raisonnement visuel ont été observés, mais des recherches plus approfondies sont encore nécessaires
Co-auteur de l'article, John Hope Yutong Bai, un Un doctorant en quatrième année de CS au Kings College et un doctorant invité à Berkeley ont tweeté pour promouvoir leurs travaux.
La source originale de l'image provient du compte Twitter : https://twitter.com/YutongBAI1002/status/1731512110247473608
Parmi les auteurs de l'article, les trois derniers sont des chercheurs chevronnés dans le domaine de CV à l'UC Berkeley. Le professeur Trevor Darrell est le codirecteur fondateur du BAIR, le laboratoire de recherche sur l'intelligence artificielle de Berkeley, le professeur Jitendra Malik a remporté le prix IEEE Computer Pioneer Award 2019 et le professeur Alexei A. Efros est particulièrement célèbre pour ses recherches sur son plus proche voisin.

De gauche à droite se trouvent Trevor Darrell, Jitendra Malik, Alexei A. Efros.
Introduction à la méthode
L'article utilise une approche en deux étapes : 1) formation d'un grand tokeniseur visuel (opérant sur une seule image), capable de convertir chaque image en une série de jetons visuels ; 2) formation sur ; phrases visuelles Modèle de transformateur autorégressif, chaque phrase est représentée comme une série de jetons. La méthode est illustrée dans la figure 2
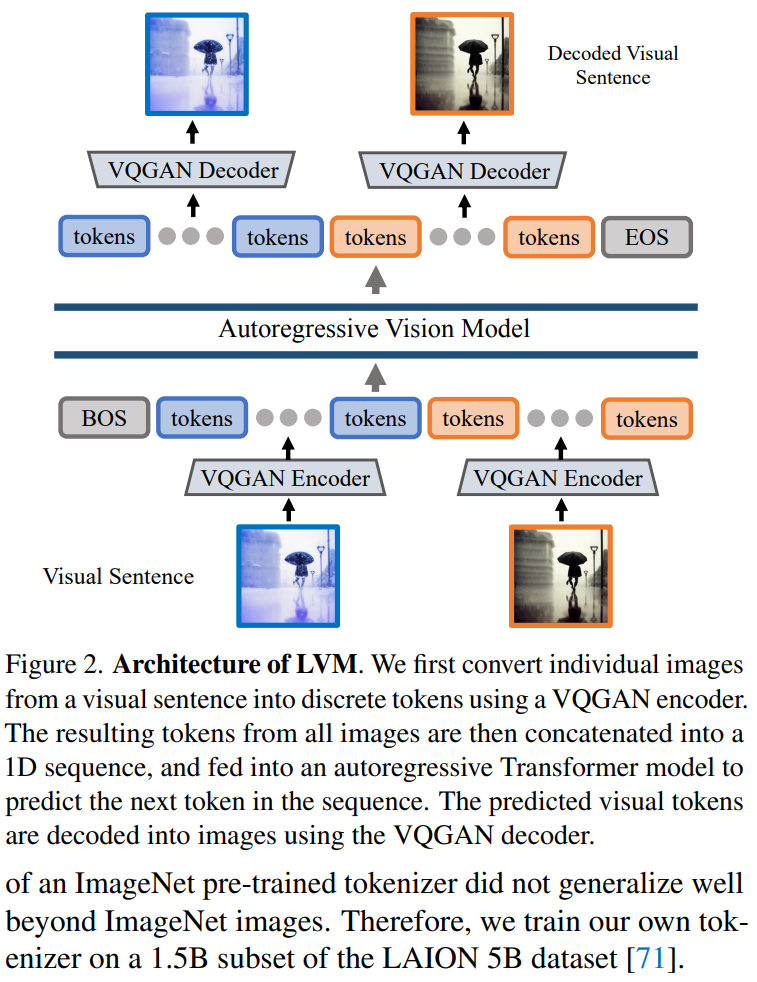
Tokénisation d'image
Afin d'appliquer le modèle Transformer aux images, les opérations typiques incluent : diviser l'image en patchs et les traiter comme des séquences ou utiliser des images pré-entraînées A ; un tokenizer, tel que VQVAE ou VQGAN, regroupe les caractéristiques de l'image dans une grille de jetons discrets. Cet article adopte cette dernière méthode, en utilisant le modèle VQGAN pour générer des jetons sémantiques.
Le framework LVM comprend des mécanismes d'encodage et de décodage et possède également des couches de quantification, où l'encodeur et le décodeur sont construits avec des couches convolutives. L'encodeur est équipé de plusieurs modules de sous-échantillonnage pour réduire les dimensions spatiales de l'entrée, tandis que le décodeur est équipé d'une série de modules de suréchantillonnage équivalents pour restaurer l'image à sa taille d'origine. Pour une image donnée, le tokenizer VQGAN génère 256 jetons discrets.
L'architecture VQGAN dans cet article adopte les détails d'implémentation proposés par Chang et al. Plus précisément, le facteur de sous-échantillonnage est f = 16 et la taille du livre de codes est de 8 192. Cela signifie que pour une image de taille 256×256, le tokenizer VQGAN générera 16×16=256 tokens, et chaque token pourra prendre 8192 valeurs différentes. De plus, cet article a entraîné le tokenizer sur un sous-ensemble de 1,5 B de l'ensemble de données LAION 5B
Modélisation de séquences de phrases visuelles
Après avoir utilisé VQGAN pour convertir des images en jetons discrets, cet article utilise des jetons discrets dans plusieurs images Concaténer en une seule. -séquences dimensionnelles et traiter les phrases visuelles comme des séquences unifiées. Il est important de noter qu'aucune des phrases visuelles n'a été spécialement traitée, c'est-à-dire qu'aucun jeton spécial n'a été utilisé pour indiquer une tâche ou un format spécifique.

La fonction des phrases visuelles est de formater différentes données visuelles dans une structure de séquence d'images unifiée
Détails de mise en œuvre. Après avoir tokenisé chaque image de la phrase visuelle en 256 jetons, cet article les concatène pour former une séquence de jetons 1D. Concernant la séquence de jetons visuels, le modèle Transformer dans cet article est en fait le même que le modèle de langage autorégressif, ils adoptent donc l'architecture Transformer de LLaMA.
Ce contenu utilise une longueur de contexte de 4096 jetons, similaire au modèle de langage. Ajoutez un jeton [BOS] (début de phrase) au début de chaque phrase visuelle et un jeton [EOS] (fin de phrase) à la fin, et utilisez l'épissage de séquence pendant la formation pour améliorer l'efficacité
Cet article fonctionne bien sur le l'ensemble de données UVDv1 complet (4 200 100 millions de jetons), un total de 4 modèles avec différents numéros de paramètres ont été formés : 300 millions, 600 millions, 1 milliard et 3 milliards.
Les résultats expérimentaux doivent être réécrits
L'étude a mené des expériences pour évaluer le modèle Afin de développer l'entreprise, nous devons trouver de nouvelles opportunités de marché. Nous prévoyons d'élargir davantage notre gamme de produits pour répondre à la demande croissante. Dans le même temps, nous renforcerons les stratégies de marketing et augmenterons la notoriété de la marque. En participant activement aux expositions industrielles et aux activités de promotion, nous nous efforcerons de développer davantage de groupes de clients. Nous pensons que grâce à ces efforts, nous pouvons obtenir un plus grand succès et une croissance continue de nos capacités et de notre aptitude à comprendre et à répondre à une variété de tâches.
Afin de développer notre activité, nous devons trouver de nouvelles opportunités de marché. Nous prévoyons d'élargir davantage notre gamme de produits pour répondre à la demande croissante. Dans le même temps, nous renforcerons les stratégies de marketing et augmenterons la notoriété de la marque. En participant activement aux expositions industrielles et aux activités de promotion, nous nous efforcerons de développer davantage de groupes de clients. Nous pensons que grâce à ces efforts, nous pouvons obtenir de plus grands résultats et atteindre une croissance soutenue. le modèle plus large présentait une complexité moindre dans toutes les tâches, ce qui suggère que les performances globales du modèle peuvent être transférées à une gamme de tâches en aval.
Comme le montre la figure 5, chaque composant de données a un impact important sur les tâches en aval. LVM bénéficie non seulement de données plus volumineuses, mais s'améliore également avec la diversité de l'ensemble de données
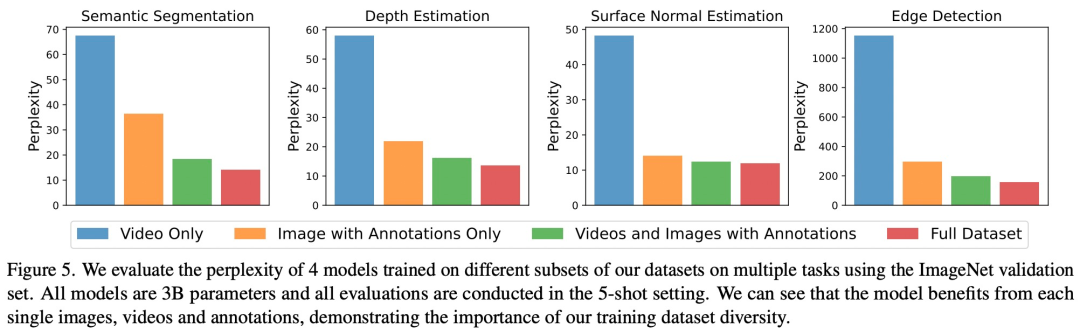
Réécrire le contenu sans changer le sens original nécessite de réécrire la langue en chinois. La phrase originale devrait apparaître
Afin de tester la capacité de LVM à comprendre diverses invites, cette étude a d'abord mené une expérience d'évaluation sur LVM sur une tâche de raisonnement séquentiel. Parmi eux, l'invite est très simple : fournissez au modèle une séquence de 7 images et demandez-lui de prédire l'image suivante. Les résultats expérimentaux doivent être réécrits comme le montre la figure 6 ci-dessous :

L'étude donnera également. une liste d'éléments dans la catégorie Traitez-la comme une séquence et laissez LVM prédire les images de la même catégorie. Les résultats expérimentaux doivent être réécrits comme le montre la figure 15 ci-dessous :

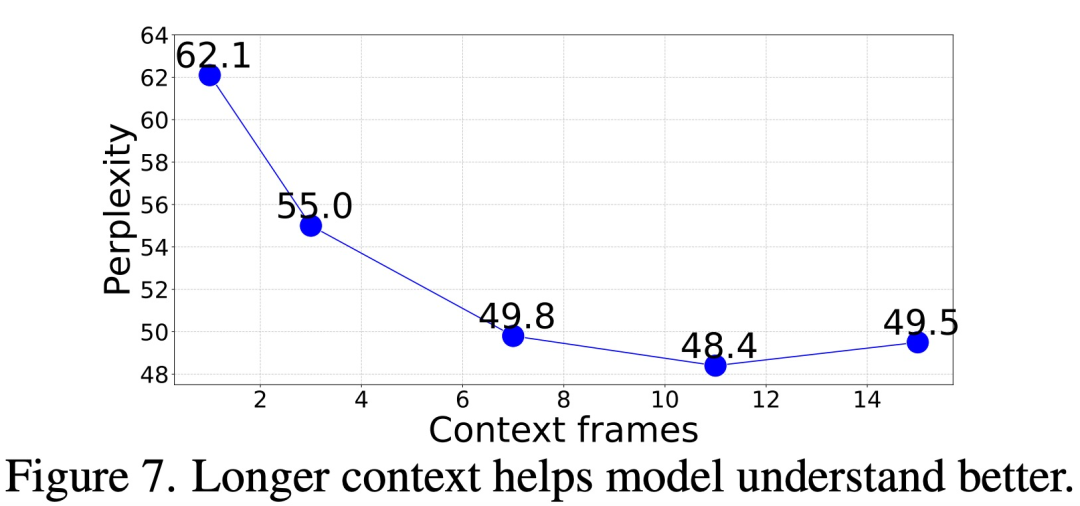
Donc, quelle quantité de contexte est nécessaire pour obtenir une précision. prédire les images suivantes ?
Dans cette étude, nous évaluons la perplexité de génération d'images de notre modèle en donnant des invites contextuelles de différentes longueurs (1 à 15 images). Les résultats montrent que la perplexité s'améliore progressivement à mesure que le nombre d'images augmente. Les données spécifiques sont présentées dans la figure 7 ci-dessous. La perplexité s'est améliorée de manière significative de l'image 1 à l'image 11, puis s'est stabilisée (62,1 → 48,4)
Invite d'analogie
Cette étude a également testé le niveau avancé de l'explication LVM. puissance, en évaluant des structures d'invite plus complexes telles que l'invite par analogie
La figure 8 ci-dessous montre les résultats qualitatifs de l'invite d'analogie pour un certain nombre de tâches :

Sur la base de la comparaison avec l'invite visuelle, on peut voir que la séquence LVM fonctionne mieux dans presque toutes les tâches sont meilleures que la méthode précédente

Tâches synthétiques. La figure 9 montre les résultats de la combinaison de plusieurs tâches à l'aide d'une seule invite

Autres invites
Les chercheurs ont tenté d'observer la mise à l'échelle du modèle en lui fournissant une variété d'invites qu'il n'avait jamais vues auparavant. nous devons trouver de nouvelles opportunités de marché. Nous prévoyons d'élargir davantage notre gamme de produits pour répondre à la demande croissante. Dans le même temps, nous renforcerons les stratégies de marketing et augmenterons la notoriété de la marque. En participant activement aux expositions industrielles et aux activités de promotion, nous nous efforcerons de développer davantage de groupes de clients. Nous pensons que grâce à ces efforts, nous pouvons obtenir de plus grands succès et parvenir à une croissance continue. La figure 10 ci-dessous montre certaines de ces invites qui fonctionnent bien.
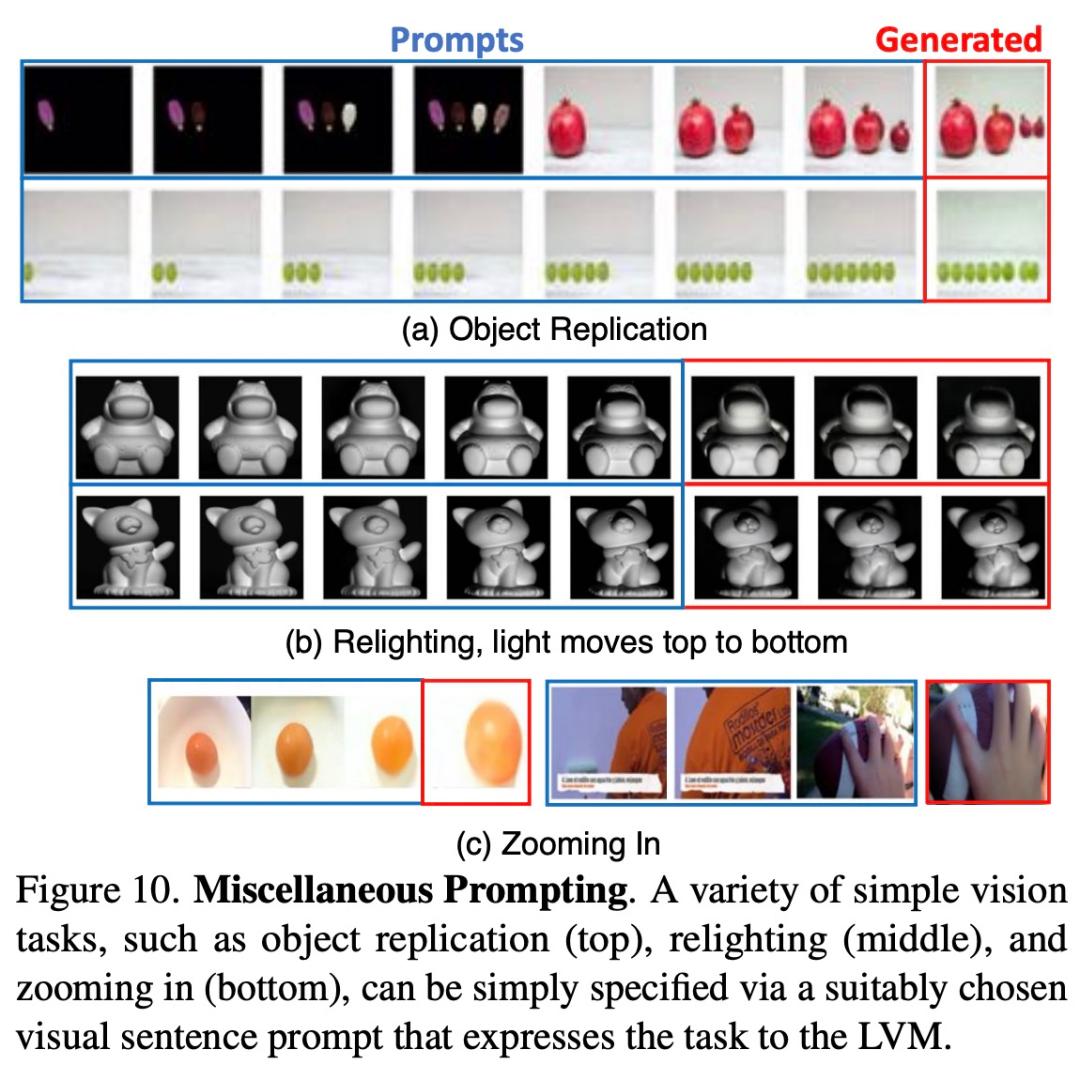
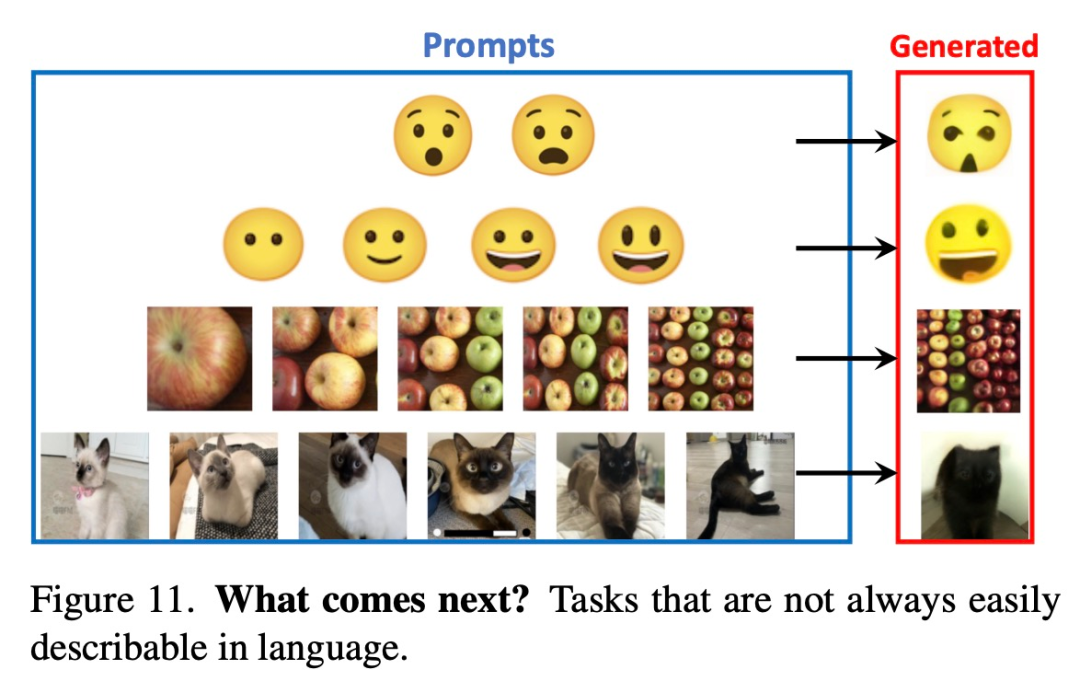
La figure 11 ci-dessous montre certaines invites difficiles à décrire avec des mots qui pourraient éventuellement surpasser LLM sur ces tâches.
La figure 13 montre les résultats qualitatifs préliminaires sur un problème de raisonnement visuel typique dans un test de QI humain non verbal

Lisez l'article original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Dans la fabrication moderne, une détection précise des défauts est non seulement la clé pour garantir la qualité des produits, mais également la clé de l’amélioration de l’efficacité de la production. Cependant, les ensembles de données de détection de défauts existants manquent souvent de précision et de richesse sémantique requises pour les applications pratiques, ce qui rend les modèles incapables d'identifier des catégories ou des emplacements de défauts spécifiques. Afin de résoudre ce problème, une équipe de recherche de premier plan composée de l'Université des sciences et technologies de Hong Kong, Guangzhou et de Simou Technology a développé de manière innovante l'ensemble de données « DefectSpectrum », qui fournit une annotation à grande échelle détaillée et sémantiquement riche des défauts industriels. Comme le montre le tableau 1, par rapport à d'autres ensembles de données industrielles, l'ensemble de données « DefectSpectrum » fournit le plus grand nombre d'annotations de défauts (5 438 échantillons de défauts) et la classification de défauts la plus détaillée (125 catégories de défauts).
 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les tâches de langage visuel.
 Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Editeur | KX À ce jour, les détails structurels et la précision déterminés par cristallographie, des métaux simples aux grandes protéines membranaires, sont inégalés par aucune autre méthode. Cependant, le plus grand défi, appelé problème de phase, reste la récupération des informations de phase à partir d'amplitudes déterminées expérimentalement. Des chercheurs de l'Université de Copenhague au Danemark ont développé une méthode d'apprentissage en profondeur appelée PhAI pour résoudre les problèmes de phase cristalline. Un réseau neuronal d'apprentissage en profondeur formé à l'aide de millions de structures cristallines artificielles et de leurs données de diffraction synthétique correspondantes peut générer des cartes précises de densité électronique. L'étude montre que cette méthode de solution structurelle ab initio basée sur l'apprentissage profond peut résoudre le problème de phase avec une résolution de seulement 2 Angströms, ce qui équivaut à seulement 10 à 20 % des données disponibles à la résolution atomique, alors que le calcul ab initio traditionnel
 Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Pour l’IA, l’Olympiade mathématique n’est plus un problème. Jeudi, l'intelligence artificielle de Google DeepMind a réalisé un exploit : utiliser l'IA pour résoudre la vraie question de l'Olympiade mathématique internationale de cette année, l'OMI, et elle n'était qu'à un pas de remporter la médaille d'or. Le concours de l'OMI qui vient de se terminer la semaine dernière comportait six questions portant sur l'algèbre, la combinatoire, la géométrie et la théorie des nombres. Le système d'IA hybride proposé par Google a répondu correctement à quatre questions et a marqué 28 points, atteignant le niveau de la médaille d'argent. Plus tôt ce mois-ci, le professeur titulaire de l'UCLA, Terence Tao, venait de promouvoir l'Olympiade mathématique de l'IA (AIMO Progress Award) avec un prix d'un million de dollars. De manière inattendue, le niveau de résolution de problèmes d'IA s'était amélioré à ce niveau avant juillet. Posez les questions simultanément sur l'OMI. La chose la plus difficile à faire correctement est l'OMI, qui a la plus longue histoire, la plus grande échelle et la plus négative.
 Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Editeur | ScienceAI Sur la base de données cliniques limitées, des centaines d'algorithmes médicaux ont été approuvés. Les scientifiques se demandent qui devrait tester les outils et comment le faire au mieux. Devin Singh a vu un patient pédiatrique aux urgences subir un arrêt cardiaque alors qu'il attendait un traitement pendant une longue période, ce qui l'a incité à explorer l'application de l'IA pour réduire les temps d'attente. À l’aide des données de triage des salles d’urgence de SickKids, Singh et ses collègues ont construit une série de modèles d’IA pour fournir des diagnostics potentiels et recommander des tests. Une étude a montré que ces modèles peuvent accélérer les visites chez le médecin de 22,3 %, accélérant ainsi le traitement des résultats de près de 3 heures par patient nécessitant un examen médical. Cependant, le succès des algorithmes d’intelligence artificielle dans la recherche ne fait que le vérifier.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 PRO | Pourquoi les grands modèles basés sur le MoE méritent-ils davantage d'attention ?
Aug 07, 2024 pm 07:08 PM
PRO | Pourquoi les grands modèles basés sur le MoE méritent-ils davantage d'attention ?
Aug 07, 2024 pm 07:08 PM
En 2023, presque tous les domaines de l’IA évoluent à une vitesse sans précédent. Dans le même temps, l’IA repousse constamment les limites technologiques de domaines clés tels que l’intelligence embarquée et la conduite autonome. Sous la tendance multimodale, le statut de Transformer en tant qu'architecture dominante des grands modèles d'IA sera-t-il ébranlé ? Pourquoi l'exploration de grands modèles basés sur l'architecture MoE (Mixture of Experts) est-elle devenue une nouvelle tendance dans l'industrie ? Les modèles de grande vision (LVM) peuvent-ils constituer une nouvelle avancée dans la vision générale ? ...Dans la newsletter des membres PRO 2023 de ce site publiée au cours des six derniers mois, nous avons sélectionné 10 interprétations spéciales qui fournissent une analyse approfondie des tendances technologiques et des changements industriels dans les domaines ci-dessus pour vous aider à atteindre vos objectifs dans le nouveau année. Cette interprétation provient de la Week50 2023
 Identifiez automatiquement les meilleures molécules et réduisez les coûts de synthèse. Le MIT développe un cadre d'algorithme de prise de décision en matière de conception moléculaire.
Jun 22, 2024 am 06:43 AM
Identifiez automatiquement les meilleures molécules et réduisez les coûts de synthèse. Le MIT développe un cadre d'algorithme de prise de décision en matière de conception moléculaire.
Jun 22, 2024 am 06:43 AM
Éditeur | L’utilisation de Ziluo AI pour rationaliser la découverte de médicaments explose. Ciblez des milliards de molécules candidates pour détecter celles qui pourraient posséder les propriétés nécessaires au développement de nouveaux médicaments. Il y a tellement de variables à prendre en compte, depuis le prix des matériaux jusqu’au risque d’erreur, qu’évaluer les coûts de synthèse des meilleures molécules candidates n’est pas une tâche facile, même si les scientifiques utilisent l’IA. Ici, les chercheurs du MIT ont développé SPARROW, un cadre d'algorithme de prise de décision quantitative, pour identifier automatiquement les meilleurs candidats moléculaires, minimisant ainsi les coûts de synthèse tout en maximisant la probabilité que les candidats possèdent les propriétés souhaitées. L’algorithme a également identifié les matériaux et les étapes expérimentales nécessaires à la synthèse de ces molécules. SPARROW prend en compte le coût de synthèse d'un lot de molécules à la fois, puisque plusieurs molécules candidates sont souvent disponibles
