
 Périphériques technologiques
IA
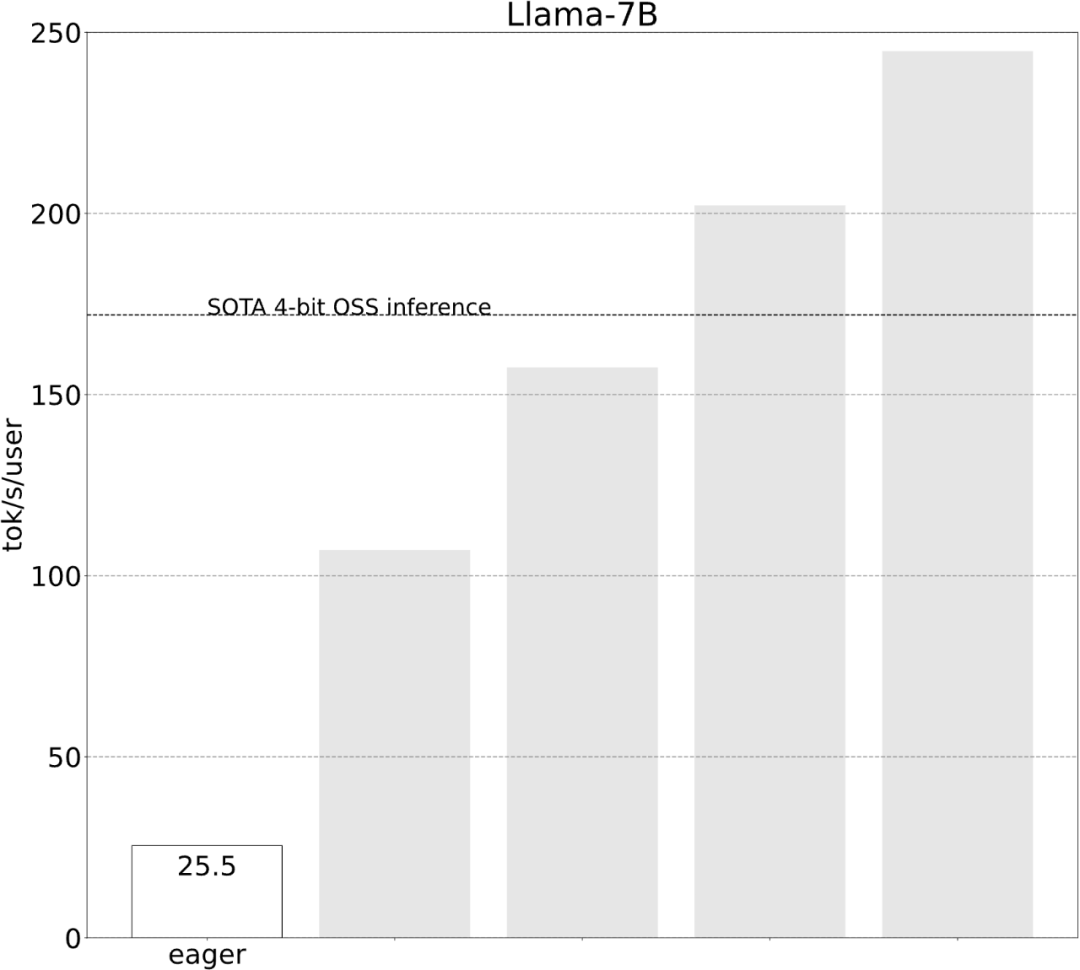
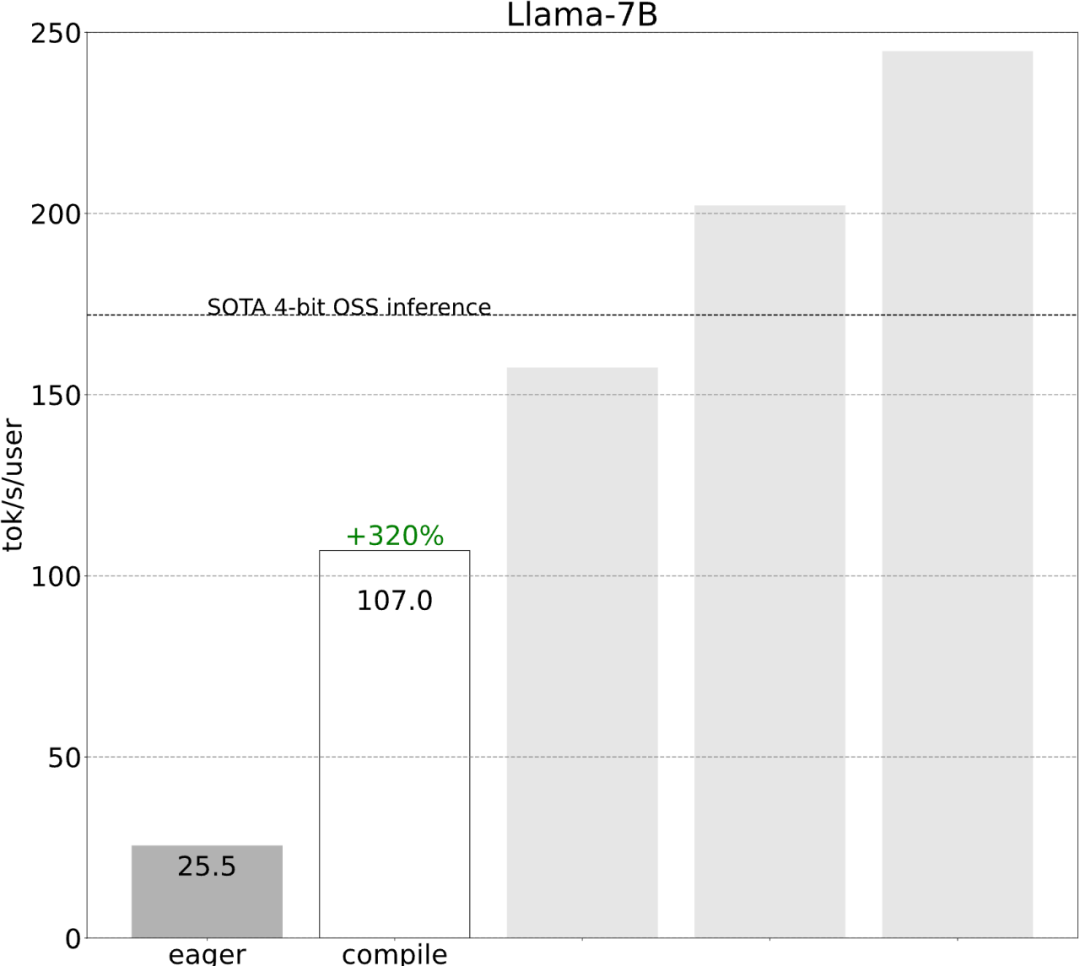
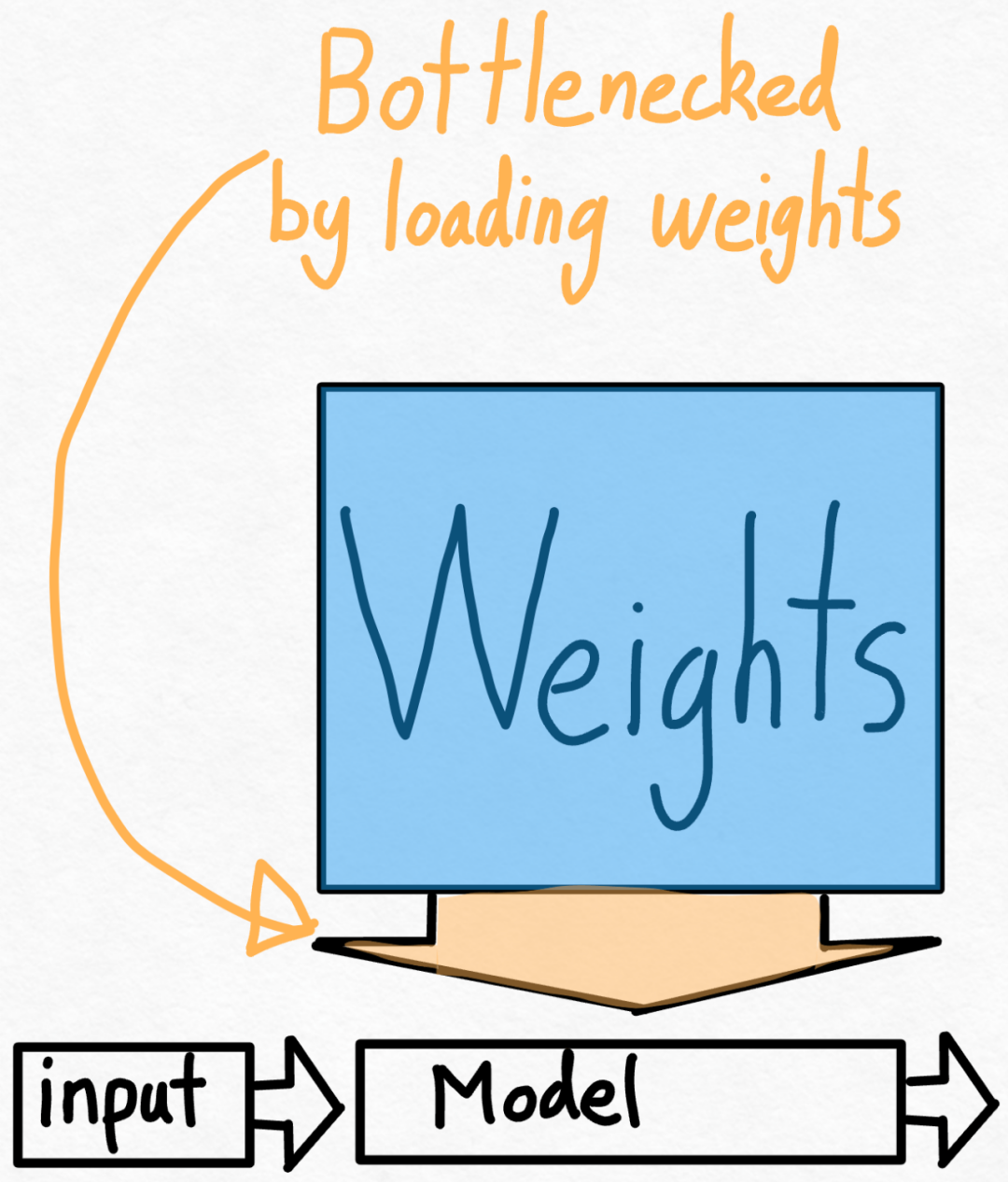
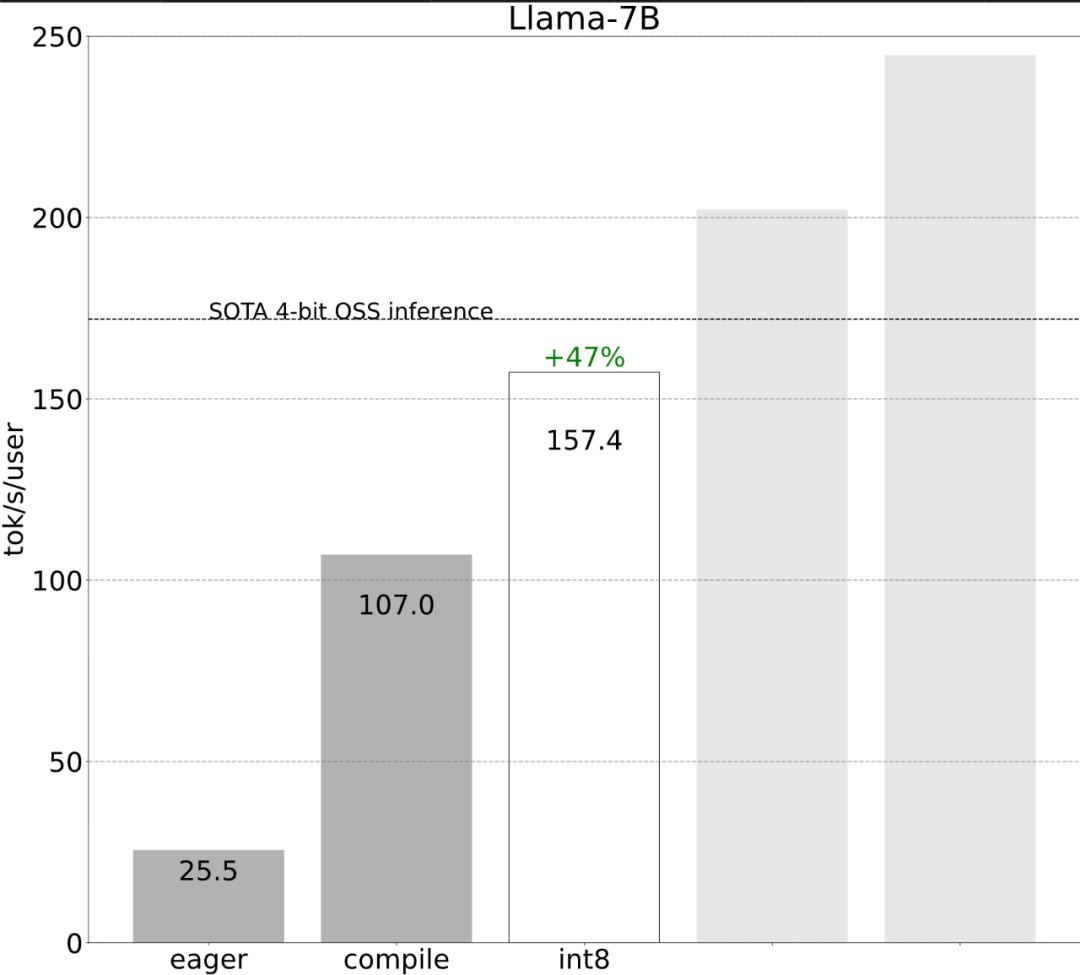
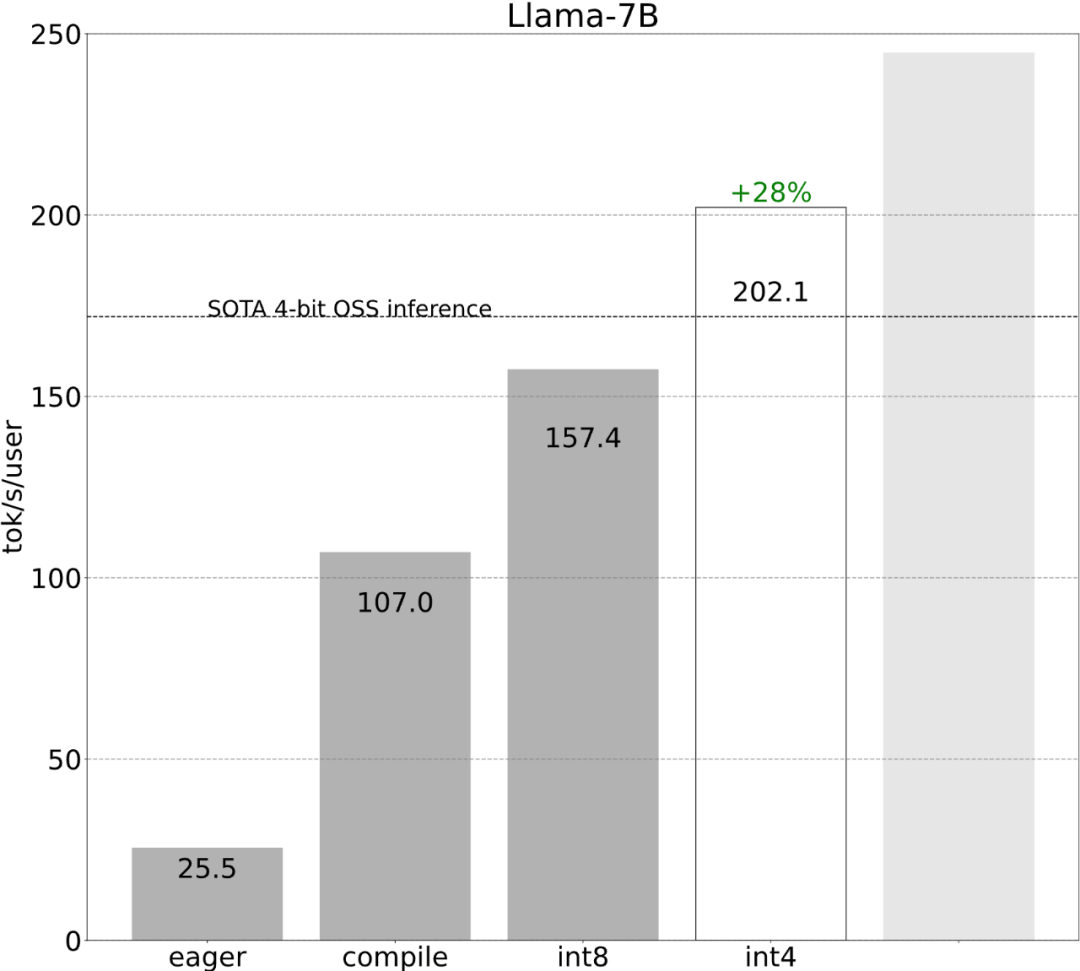
Avec moins de 1 000 lignes de code, l'équipe PyTorch a rendu Llama 7B 10 fois plus rapide
Périphériques technologiques
IA
Avec moins de 1 000 lignes de code, l'équipe PyTorch a rendu Llama 7B 10 fois plus rapide
Avec moins de 1 000 lignes de code, l'équipe PyTorch a rendu Llama 7B 10 fois plus rapide

L'équipe PyTorch vous apprend personnellement comment accélérer l'inférence de grands modèles.

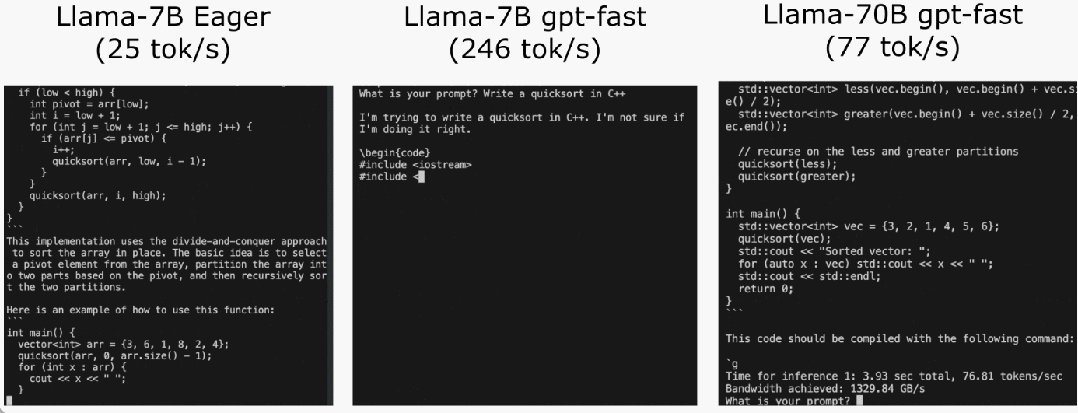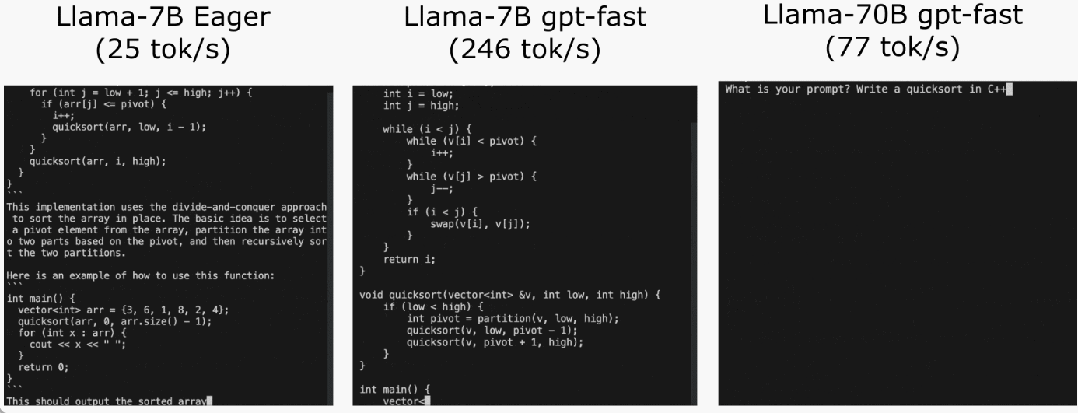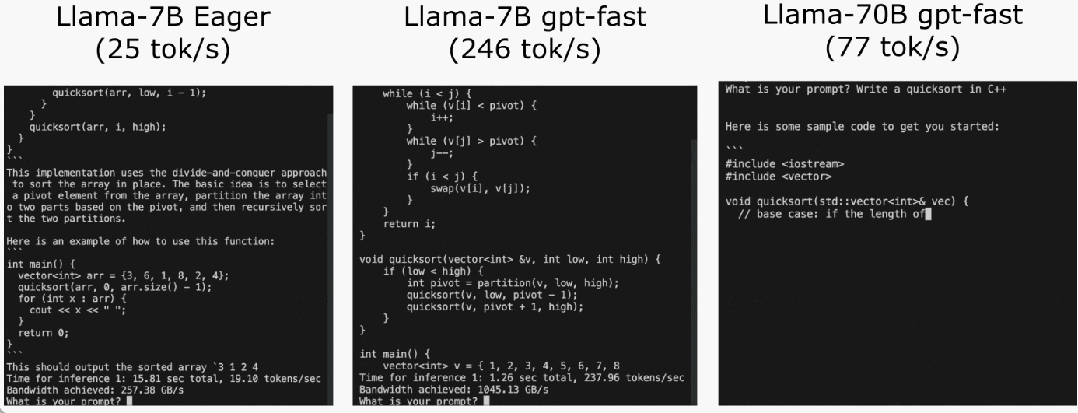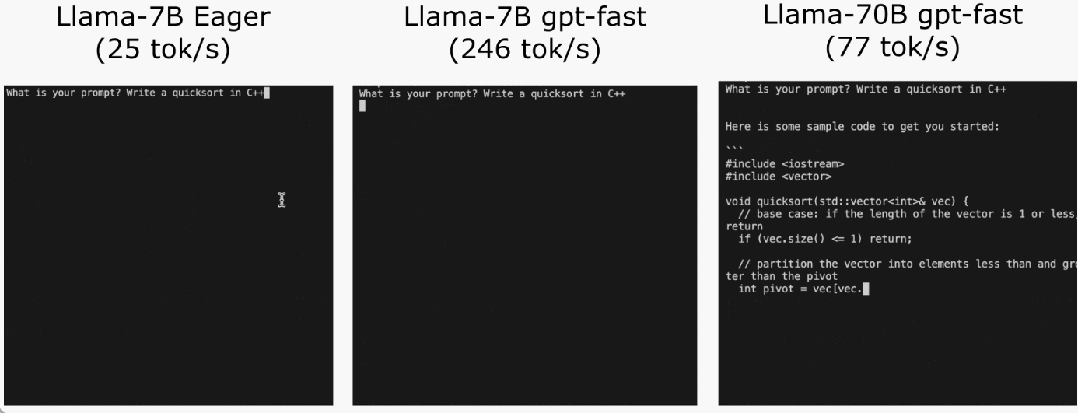
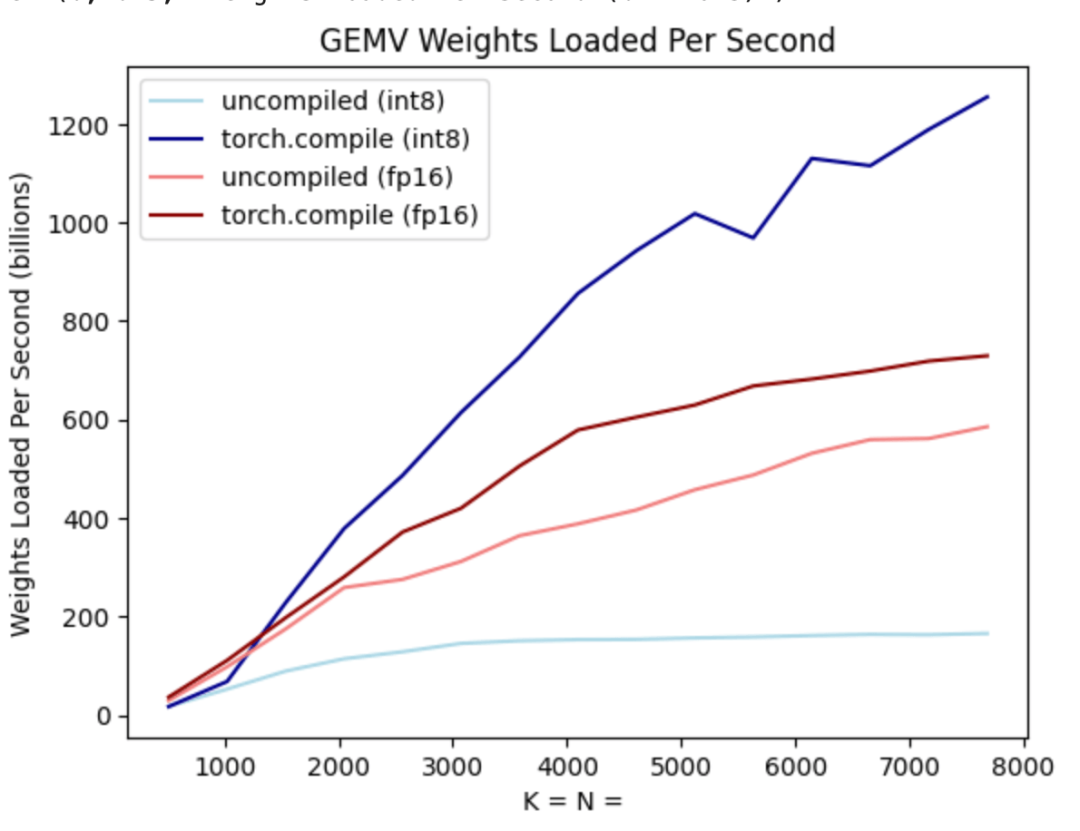
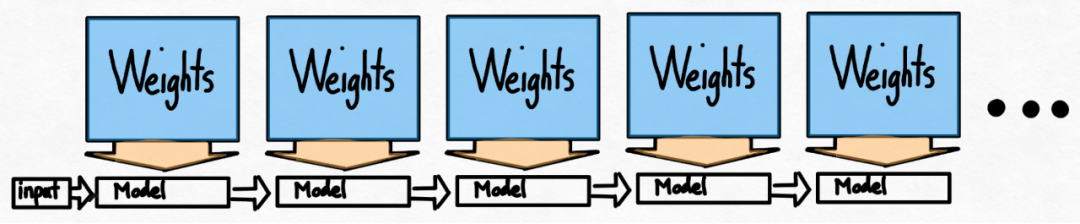
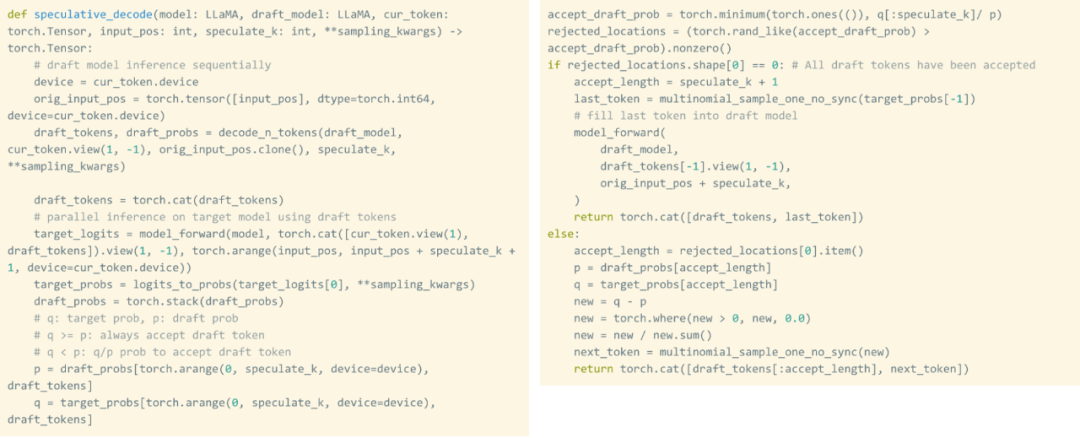
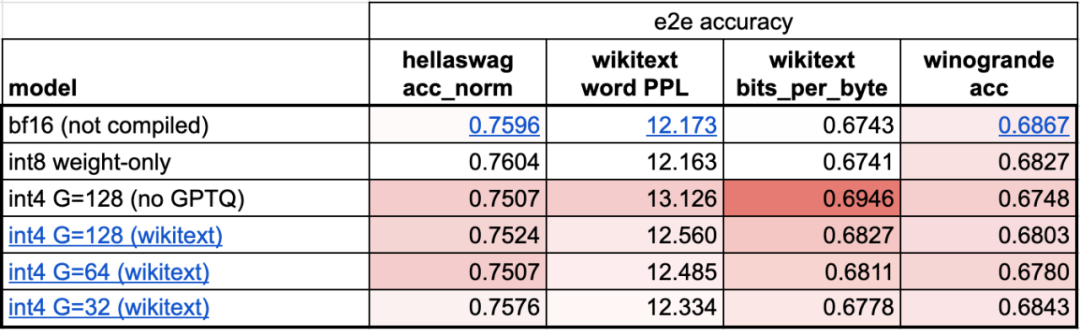
Torch.compile : compilateur de modèles PyTorch, PyTorch 2.0 ajoute une nouvelle fonction appelée torch.compile (), qui peut compiler des modèles existants avec une seule ligne de code. Accélérer le modèle ; Quantification GPU : accélère le modèle en réduisant la précision de calcul ; Décodage spéculatif : une méthode d'accélération d'inférence de grand modèle qui utilise un petit "projet" de modèle pour prédire de grandes "cibles" ; Tensor Parallel : accélérez l'inférence de modèle en exécutant le modèle sur plusieurs appareils.





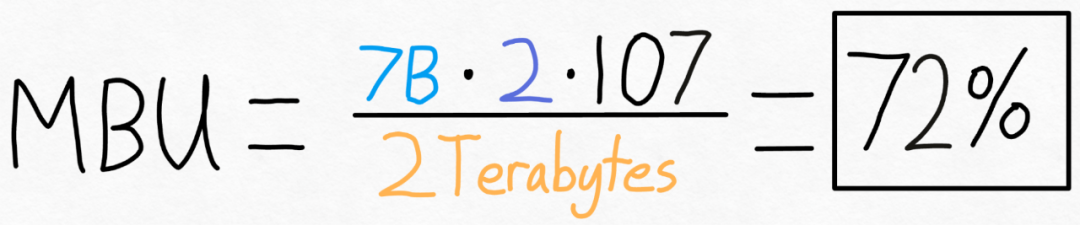


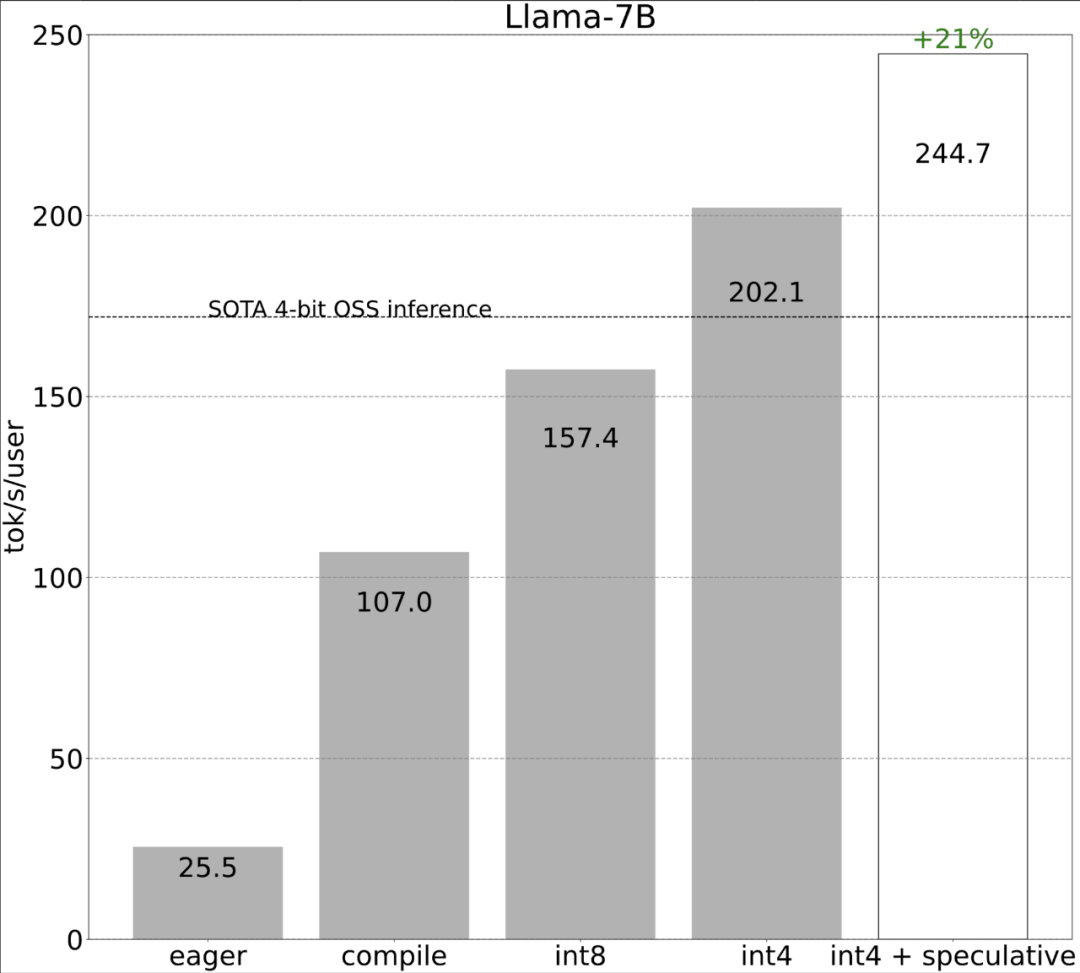

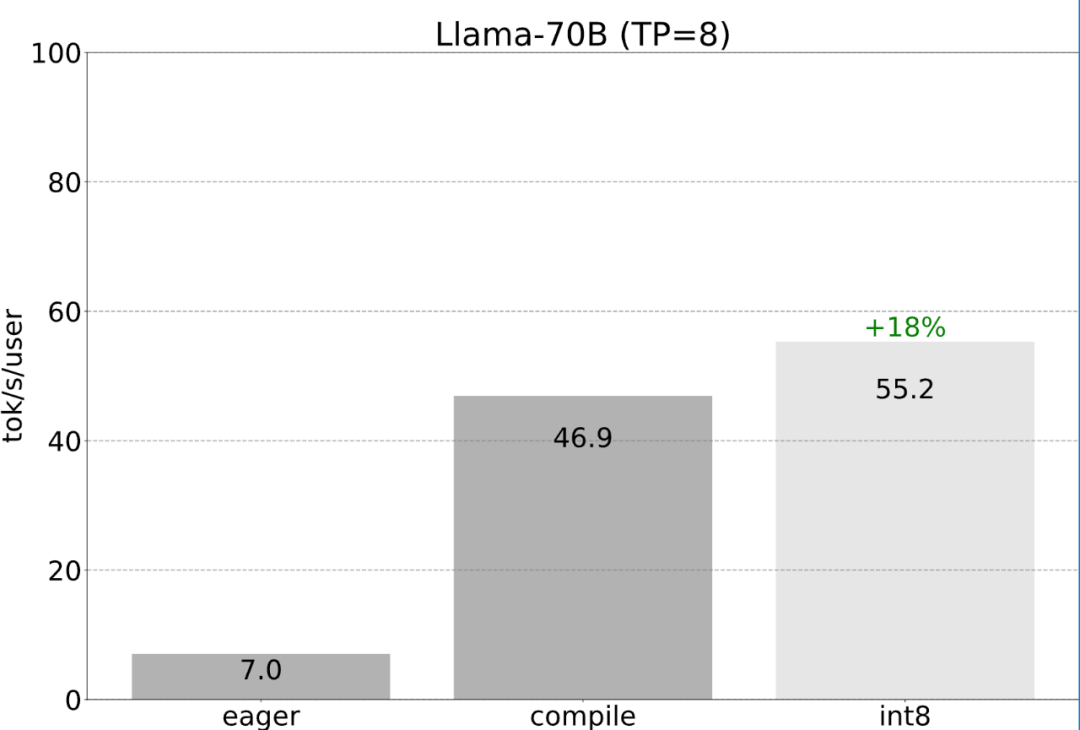
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Un didacticiel sur le modèle de diffusion qui vaut votre temps, de l'Université Purdue
Apr 07, 2024 am 09:01 AM
Un didacticiel sur le modèle de diffusion qui vaut votre temps, de l'Université Purdue
Apr 07, 2024 am 09:01 AM
La diffusion permet non seulement de mieux imiter, mais aussi de « créer ». Le modèle de diffusion (DiffusionModel) est un modèle de génération d'images. Par rapport aux algorithmes bien connus tels que GAN et VAE dans le domaine de l’IA, le modèle de diffusion adopte une approche différente. Son idée principale est un processus consistant à ajouter d’abord du bruit à l’image, puis à la débruiter progressivement. Comment débruiter et restaurer l’image originale est la partie centrale de l’algorithme. L'algorithme final est capable de générer une image à partir d'une image bruitée aléatoirement. Ces dernières années, la croissance phénoménale de l’IA générative a permis de nombreuses applications passionnantes dans la génération de texte en image, la génération de vidéos, et bien plus encore. Le principe de base de ces outils génératifs est le concept de diffusion, un mécanisme d'échantillonnage spécial qui surmonte les limites des méthodes précédentes.
 Générez du PPT en un seul clic ! Kimi : Que les « travailleurs migrants PPT » deviennent d'abord populaires
Aug 01, 2024 pm 03:28 PM
Générez du PPT en un seul clic ! Kimi : Que les « travailleurs migrants PPT » deviennent d'abord populaires
Aug 01, 2024 pm 03:28 PM
Kimi : En une seule phrase, un PPT est prêt en seulement dix secondes. PPT est tellement ennuyeux ! Pour tenir une réunion, vous devez avoir un PPT ; pour rédiger un rapport hebdomadaire, vous devez avoir un PPT ; pour solliciter des investissements, vous devez présenter un PPT ; même pour accuser quelqu'un de tricherie, vous devez envoyer un PPT ; L'université ressemble plus à une spécialisation PPT. Vous regardez le PPT en classe et faites le PPT après les cours. Peut-être que lorsque Dennis Austin a inventé le PPT il y a 37 ans, il ne s'attendait pas à ce qu'un jour le PPT devienne aussi répandu. Parler de notre dure expérience de création de PPT nous fait monter les larmes aux yeux. "Il m'a fallu trois mois pour réaliser un PPT de plus de 20 pages, et je l'ai révisé des dizaines de fois. J'avais envie de vomir quand j'ai vu le PPT." "À mon apogée, je faisais cinq PPT par jour, et même ma respiration." était PPT." Si vous avez une réunion impromptue, vous devriez le faire
 La combinaison parfaite de PyCharm et PyTorch : étapes détaillées d'installation et de configuration
Feb 21, 2024 pm 12:00 PM
La combinaison parfaite de PyCharm et PyTorch : étapes détaillées d'installation et de configuration
Feb 21, 2024 pm 12:00 PM
PyCharm est un puissant environnement de développement intégré (IDE) et PyTorch est un framework open source populaire dans le domaine de l'apprentissage profond. Dans le domaine de l'apprentissage automatique et de l'apprentissage profond, l'utilisation de PyCharm et PyTorch pour le développement peut améliorer considérablement l'efficacité du développement et la qualité du code. Cet article présentera en détail comment installer et configurer PyTorch dans PyCharm, et joindra des exemples de code spécifiques pour aider les lecteurs à mieux utiliser les puissantes fonctions de ces deux éléments. Étape 1 : Installer PyCharm et Python
 Introduction à cinq méthodes d'échantillonnage dans les tâches de génération de langage naturel et l'implémentation du code Pytorch
Feb 20, 2024 am 08:50 AM
Introduction à cinq méthodes d'échantillonnage dans les tâches de génération de langage naturel et l'implémentation du code Pytorch
Feb 20, 2024 am 08:50 AM
Dans les tâches de génération de langage naturel, la méthode d'échantillonnage est une technique permettant d'obtenir du texte à partir d'un modèle génératif. Cet article abordera 5 méthodes courantes et les implémentera à l'aide de PyTorch. 1. GreedyDecoding Dans le décodage gourmand, le modèle génératif prédit les mots de la séquence de sortie en fonction du temps de la séquence d'entrée pas à pas. À chaque pas de temps, le modèle calcule la distribution de probabilité conditionnelle de chaque mot, puis sélectionne le mot avec la probabilité conditionnelle la plus élevée comme sortie du pas de temps actuel. Ce mot devient l'entrée du pas de temps suivant et le processus de génération se poursuit jusqu'à ce qu'une condition de fin soit remplie, telle qu'une séquence d'une longueur spécifiée ou un marqueur de fin spécial. La caractéristique de GreedyDecoding est qu’à chaque fois la probabilité conditionnelle actuelle est la meilleure
 Tutoriel sur l'installation de PyCharm avec PyTorch
Feb 24, 2024 am 10:09 AM
Tutoriel sur l'installation de PyCharm avec PyTorch
Feb 24, 2024 am 10:09 AM
En tant que puissant framework d'apprentissage profond, PyTorch est largement utilisé dans divers projets d'apprentissage automatique. En tant que puissant environnement de développement intégré Python, PyCharm peut également fournir un bon support lors de la mise en œuvre de tâches d'apprentissage en profondeur. Cet article présentera en détail comment installer PyTorch dans PyCharm et fournira des exemples de code spécifiques pour aider les lecteurs à démarrer rapidement avec PyTorch pour des tâches d'apprentissage en profondeur. Étape 1 : Installer PyCharm Tout d’abord, nous devons nous assurer que nous avons
 Tous les prix CVPR 2024 annoncés ! Près de 10 000 personnes ont assisté à la conférence hors ligne et un chercheur chinois de Google a remporté le prix du meilleur article.
Jun 20, 2024 pm 05:43 PM
Tous les prix CVPR 2024 annoncés ! Près de 10 000 personnes ont assisté à la conférence hors ligne et un chercheur chinois de Google a remporté le prix du meilleur article.
Jun 20, 2024 pm 05:43 PM
Tôt le matin du 20 juin, heure de Pékin, CVPR2024, la plus grande conférence internationale sur la vision par ordinateur qui s'est tenue à Seattle, a officiellement annoncé le meilleur article et d'autres récompenses. Cette année, un total de 10 articles ont remporté des prix, dont 2 meilleurs articles et 2 meilleurs articles étudiants. De plus, il y a eu 2 nominations pour les meilleurs articles et 4 nominations pour les meilleurs articles étudiants. La conférence la plus importante dans le domaine de la vision par ordinateur (CV) est la CVPR, qui attire chaque année un grand nombre d'instituts de recherche et d'universités. Selon les statistiques, un total de 11 532 articles ont été soumis cette année, dont 2 719 ont été acceptés, avec un taux d'acceptation de 23,6 %. Selon l'analyse statistique des données CVPR2024 du Georgia Institute of Technology, du point de vue des sujets de recherche, le plus grand nombre d'articles est la synthèse et la génération d'images et de vidéos (Imageandvideosyn
 Cinq logiciels de programmation pour débuter l'apprentissage du langage C
Feb 19, 2024 pm 04:51 PM
Cinq logiciels de programmation pour débuter l'apprentissage du langage C
Feb 19, 2024 pm 04:51 PM
En tant que langage de programmation largement utilisé, le langage C est l'un des langages de base qui doivent être appris pour ceux qui souhaitent se lancer dans la programmation informatique. Cependant, pour les débutants, l’apprentissage d’un nouveau langage de programmation peut s’avérer quelque peu difficile, notamment en raison du manque d’outils d’apprentissage et de matériel pédagogique pertinents. Dans cet article, je présenterai cinq logiciels de programmation pour aider les débutants à démarrer avec le langage C et vous aider à démarrer rapidement. Le premier logiciel de programmation était Code :: Blocks. Code::Blocks est un environnement de développement intégré (IDE) gratuit et open source pour
 Du bare metal au grand modèle avec 70 milliards de paramètres, voici un tutoriel et des scripts prêts à l'emploi
Jul 24, 2024 pm 08:13 PM
Du bare metal au grand modèle avec 70 milliards de paramètres, voici un tutoriel et des scripts prêts à l'emploi
Jul 24, 2024 pm 08:13 PM
Nous savons que le LLM est formé sur des clusters informatiques à grande échelle utilisant des données massives. Ce site a présenté de nombreuses méthodes et technologies utilisées pour aider et améliorer le processus de formation LLM. Aujourd'hui, ce que nous souhaitons partager est un article qui approfondit la technologie sous-jacente et présente comment transformer un ensemble de « bare metals » sans même un système d'exploitation en un cluster informatique pour la formation LLM. Cet article provient d'Imbue, une startup d'IA qui s'efforce d'atteindre une intelligence générale en comprenant comment les machines pensent. Bien sûr, transformer un tas de « bare metal » sans système d'exploitation en un cluster informatique pour la formation LLM n'est pas un processus facile, plein d'exploration et d'essais et d'erreurs, mais Imbue a finalement réussi à former un LLM avec 70 milliards de paramètres et dans. le processus s'accumule
