
 Périphériques technologiques
IA
Le téléphone mobile exécute mieux le petit modèle de Microsoft que le grand modèle avec 2,7 milliards de paramètres
Périphériques technologiques
IA
Le téléphone mobile exécute mieux le petit modèle de Microsoft que le grand modèle avec 2,7 milliards de paramètres
Le téléphone mobile exécute mieux le petit modèle de Microsoft que le grand modèle avec 2,7 milliards de paramètres

Le PDG de Microsoft, Nadella, a annoncé lors de la conférence Ignite le mois dernier que le modèle à petite échelle Phi-2 serait entièrement open source. Cette décision améliorera considérablement les performances du raisonnement de bon sens, de la compréhension du langage et du raisonnement logique

Aujourd'hui, Microsoft a annoncé plus de détails sur le modèle Phi-2 et sa nouvelle base de données de technologie d'invite. Ce modèle avec seulement 2,7 milliards de paramètres surpasse Llama2 7B, Llama2 13B, Mistral 7B et comble l'écart (ou même mieux) avec Llama2 70B sur la plupart des tâches de raisonnement de bon sens, de compréhension du langage, de mathématiques et de codage.
En même temps, le Phi-2 de petite taille peut fonctionner sur des appareils mobiles tels que des ordinateurs portables et des téléphones mobiles. Nadella a déclaré que Microsoft était très heureux de partager son meilleur modèle de langage (SLM) et sa technologie d'invite SOTA avec les développeurs de R&D.
Microsoft a publié en juin de cette année un article intitulé "Just a Textbook" qui utilisait des données de "qualité de manuel" contenant seulement 7B de marqueurs pour former un modèle avec 1,3B de paramètres, à savoir phi-1. Malgré des ensembles de données et des tailles de modèles bien inférieurs à ceux de ses concurrents, phi-1 atteint un taux de réussite initial de 50,6 % dans HumanEval et une précision de 55,5 % dans MBPP. phi-1 a prouvé que même des « petites données » de haute qualité peuvent donner au modèle de bonnes performances
Microsoft a ensuite publié « Just a Textbook II : Phi-1.5 Technical Report » en septembre, axé sur le potentiel de haute qualité. de « petites données » est étudiée plus en détail. L'article propose Phi-1.5, qui convient au QA Q&A, au codage et à d'autres scénarios, et peut atteindre une échelle de 1,3 milliard
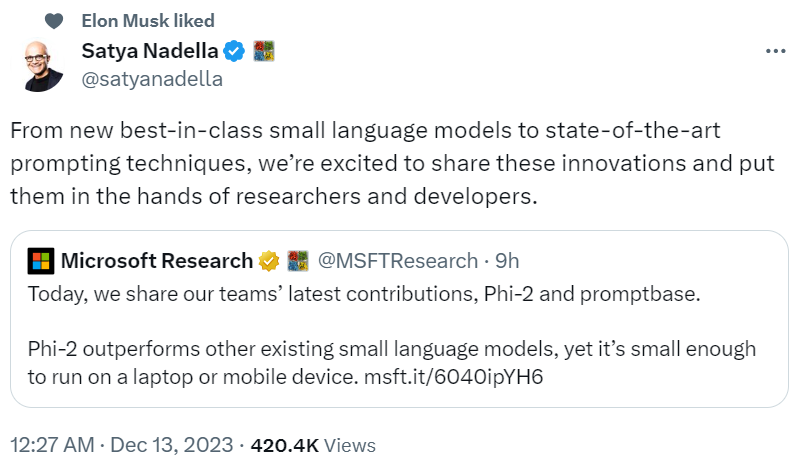
Aujourd'hui, Phi-2 avec 2,7 milliards de paramètres utilise à nouveau un « petit corps » pour fournir excellentes capacités de raisonnement et de compréhension du langage, démontrant les performances SOTA dans des modèles de langage de base sous 13 milliards de paramètres. Grâce aux innovations en matière de mise à l'échelle des modèles et de gestion des données de formation, Phi-2 correspond ou dépasse les modèles 25 fois sa propre taille sur des benchmarks complexes.
Microsoft affirme que Phi-2 sera un modèle idéal pour les chercheurs souhaitant mener des explorations d'interprétabilité, des améliorations de sécurité ou des expériences de réglage fin pour diverses tâches. Microsoft a rendu Phi-2 disponible dans le catalogue de modèles Azure AI Studio pour faciliter le développement de modèles de langage.
Phi-2 Key Highlights
L'augmentation de la taille du modèle de langage à des centaines de milliards de paramètres a en effet libéré de nombreuses nouvelles capacités et redéfini le paysage du traitement du langage naturel. Mais une question demeure : ces nouvelles capacités peuvent-elles également être obtenues sur des modèles à plus petite échelle grâce à la sélection de stratégies de formation (telles que la sélection de données) ?
La solution proposée par Microsoft consiste à utiliser la série de modèles Phi pour obtenir des performances similaires à celles des grands modèles en entraînant de petits modèles de langage. Phi-2 enfreint les règles de mise à l'échelle des modèles de langage traditionnels sous deux aspects
Premièrement, la qualité des données d'entraînement joue un rôle crucial dans les performances du modèle. Microsoft pousse cette compréhension à l'extrême en se concentrant sur les données de « qualité des manuels ». Leurs données de formation consistent en un ensemble de données complet spécialement créé qui enseigne au modèle des connaissances et un raisonnement de bon sens, tels que la science, les activités quotidiennes et la psychologie. De plus, ils ont élargi leur corpus de formation avec des données Web soigneusement sélectionnées qui ont été examinées pour leur valeur éducative et la qualité du contenu.
Deuxièmement, Microsoft a utilisé une technologie innovante pour passer de Phi-1.5 avec 1,3 milliard de paramètres. Au début, les connaissances ont été progressivement intégrées. dans Phi-2 avec 2,7 milliards de paramètres. Ce transfert de connaissances à grande échelle accélère la convergence de la formation et améliore considérablement les scores de référence de Phi-2.
Ce qui suit est le graphique de comparaison entre Phi-2 et Phi-1.5, à l'exception de BBH (3-shot CoT) et MMLU (5-shot), toutes les autres tâches sont évaluées en utilisant 0-shot
Détails de la formation
Phi-2 est un modèle basé sur Transformer dont le but est de prédire le mot suivant. Il a été formé sur des ensembles de données synthétiques et réseau, à l'aide de 96 GPU A100, et a duré 14 jours.
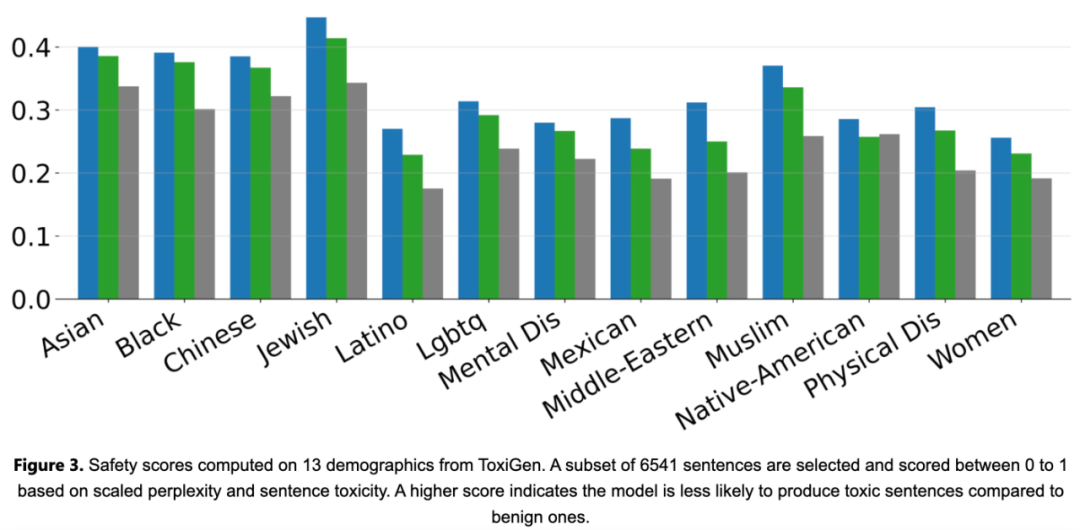
Phi-2 est un modèle de base sans alignement d'apprentissage par renforcement avec retour humain (RLHF) et sans réglage fin des instructions. Malgré cela, Phi-2 a toujours obtenu de meilleurs résultats en termes de toxicité et de biais par rapport au modèle open source existant optimisé, comme le montre la figure 3 ci-dessous.
Évaluation expérimentale
Tout d'abord, l'étude a comparé expérimentalement Phi-2 avec des modèles de langage courants sur des critères académiques, couvrant plusieurs catégories, notamment :
- Big Bench Hard (BBH) (3 plans avec CoT )
- Raisonnement de bon sens (PIQA, WinoGrande, ARC easy and challenge, SIQA),
- Compréhension du langage (HellaSwag, OpenBookQA, MMLU (5-shot), SQuADv2 (2-shot), BoolQ)
- Mathématiques (GSM8k (8 shot))
- Encoding (HumanEval, MBPP (3-shot))
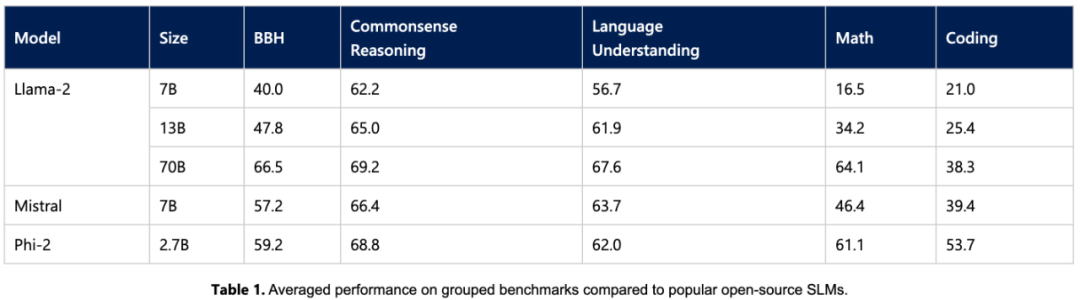
Le modèle Phi-2 n'a que 2,7 milliards de paramètres, mais il est dans diverses agrégations Sur le benchmark, les performances surpassent les modèles 7B et 13B Mistral et les modèles Llama2. Il convient de mentionner que Phi-2 est plus performant dans les tâches d'inférence en plusieurs étapes (c'est-à-dire codage et mathématiques) par rapport au modèle encombrant 25x Llama2-70B
De plus, malgré sa plus petite taille, les performances de Phi-2 2 sont comparables à celles de Phi-2. le Gemini Nano 2 récemment publié par Google Étant donné que de nombreux benchmarks publics peuvent s'infiltrer dans les données de formation, l'équipe de recherche estime que la meilleure façon de tester les performances des modèles de langage est de les tester sur des cas d'utilisation spécifiques. Par conséquent, l'étude a évalué Phi-2 à l'aide de plusieurs ensembles de données et tâches propriétaires internes de Microsoft et l'a de nouveau comparé à Mistral et Llama-2. En moyenne, Phi-2 a surpassé Mistral-7B et Mistral -7B surpasse le modèle Llama2 (7B, 13B, 70B).
L'équipe de recherche a également testé de manière approfondie les conseils communs de la communauté de recherche. Phi-2 a fonctionné comme prévu. Par exemple, pour une invite utilisée pour évaluer la capacité d'un modèle à résoudre des problèmes de physique (récemment utilisée pour évaluer le modèle Gemini Ultra), Phi-2 a donné les résultats suivants : 

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
