
 Périphériques technologiques
IA
Le populaire SSM de Mamba attire l'attention d'Apple et de Cornell : abandonnez le modèle de distraction
Périphériques technologiques
IA
Le populaire SSM de Mamba attire l'attention d'Apple et de Cornell : abandonnez le modèle de distraction
Le populaire SSM de Mamba attire l'attention d'Apple et de Cornell : abandonnez le modèle de distraction

Les dernières recherches de l'Université Cornell et d'Apple ont conclu que pour générer des images haute résolution avec moins de puissance de calcul, le mécanisme d'attention peut être éliminé
Comme nous le savons tous, le mécanisme d'attention est au cœur de Les composants de l'architecture Transformer sont cruciaux pour la génération de texte et d'images de haute qualité. Mais son défaut est également évident : la complexité du calcul augmentera de façon quadratique à mesure que la longueur de la séquence augmente. Il s’agit d’un problème épineux dans le traitement de textes longs et d’images haute résolution.
Afin de résoudre ce problème, cette nouvelle recherche a remplacé le mécanisme d'attention dans l'architecture traditionnelle par une base de modèle d'espace d'état (SSM) plus évolutive et a développé un modèle appelé Diffusion State Space Model (DIFFUSSM) ) nouvelle architecture. Cette nouvelle architecture peut utiliser moins de puissance de calcul pour égaler ou dépasser l'effet de génération d'images des modèles de diffusion existants avec des modules d'attention, et générer de manière excellente des images haute résolution.

Grâce à la sortie de « Mamba » la semaine dernière, le modèle spatial d'état SSM reçoit de plus en plus d'attention. Le cœur de Mamba est l'introduction d'une nouvelle architecture - le "modèle spatial d'état sélectif", qui rend Mamba comparable, voire supérieur à Transformer en matière de modélisation du langage. À l’époque, l’auteur de l’article, Albert Gu, avait déclaré que le succès de Mamba lui avait donné confiance dans l’avenir du SSM. Aujourd’hui, cet article de l’Université Cornell et d’Apple semble avoir ajouté de nouveaux exemples des perspectives d’application du SSM.
Shital Shah, ingénieur de recherche principal chez Microsoft, a averti que le mécanisme d'attention pourrait être retiré du trône sur lequel il est assis depuis longtemps.
Présentation de l'article
Les progrès rapides dans le domaine de la génération d'images ont été motivés par les modèles probabilistes de diffusion avec débruitage (DDPM). De tels modèles modélisent le processus de génération sous forme de variables latentes de débruitage itératives, et lorsque suffisamment d'étapes de débruitage sont effectuées, ils sont capables de produire des échantillons haute fidélité. La capacité des DDPM à capturer des distributions visuelles complexes les rend potentiellement avantageux pour la création de compositions photoréalistes haute résolution.
Des défis informatiques importants subsistent lors de la mise à l'échelle des DDPM vers des résolutions plus élevées. Le principal goulot d’étranglement est le recours à l’attention personnelle pour parvenir à une génération haute fidélité. Dans l'architecture U-Nets, ce goulot d'étranglement provient de la combinaison de ResNet avec des couches d'attention. Les DDPM vont au-delà des réseaux contradictoires génératifs (GAN) mais nécessitent des couches d'attention multi-têtes. Dans l'architecture Transformer, l'attention est l'élément central et donc essentielle pour obtenir des résultats de synthèse d'image de pointe. Dans les deux architectures, la complexité de l’attention évolue quadratiquement avec la longueur de la séquence, ce qui devient irréalisable lors du traitement d’images haute résolution.
Le coût de calcul a incité les chercheurs précédents à utiliser des méthodes de compression de représentation. Les architectures haute résolution utilisent souvent une résolution patchifiante ou multi-échelle. Le blocage peut créer des représentations à granularité grossière et réduire les coûts de calcul, mais au détriment des informations spatiales haute fréquence critiques et de l'intégrité structurelle. La résolution multi-échelle, tout en réduisant le calcul des couches d'attention, réduit également les détails spatiaux grâce au sous-échantillonnage et introduit des artefacts lors de l'application du suréchantillonnage.
DIFFUSSM est un modèle spatial d'états de diffusion qui n'utilise pas le mécanisme d'attention et est conçu pour résoudre les problèmes rencontrés lors de l'application du mécanisme d'attention dans la synthèse d'images haute résolution. DIFFUSSM utilise un modèle spatial à états contrôlés (SSM) dans le processus de diffusion. Des études antérieures ont montré que le modèle de séquence basé sur SSM est un modèle de séquence neuronale général efficace et efficient. En adoptant cette architecture, le cœur SSM peut être activé pour gérer des représentations d'images plus fines, éliminant ainsi la mosaïque globale ou les couches multi-échelles. Pour améliorer encore l'efficacité, DIFFUSSM adopte une architecture en sablier dans les composants denses du réseau
Les auteurs ont vérifié les performances de DIFFUSSM à différentes résolutions. Les expériences sur ImageNet démontrent que DIFFUSSM obtient des améliorations constantes du FID, du sFID et du Inception Score à différentes résolutions avec moins de Gflops totaux.

Lien papier : https://arxiv.org/pdf/2311.18257.pdf
Cadre DIFFUSSM
Afin de ne pas changer le sens original, le contenu doit être réécrit en chinois. L’objectif des auteurs était de concevoir une architecture de diffusion capable d’apprendre des interactions à longue portée à haute résolution sans avoir besoin d’une « réduction de longueur » comme le blocage. Semblable à DiT, cette approche fonctionne en aplatissant l'image et en la traitant comme un problème de modélisation de séquence. Cependant, contrairement à Transformer, cette méthode utilise des calculs sous-quadratiques lors du traitement de la longueur de cette séquence. DIFFUSSM est le composant central d'un SSM bidirectionnel contrôlé optimisé pour le traitement de longues séquences. Afin d'améliorer l'efficacité, l'auteur a introduit l'architecture du sablier dans la couche MLP. Cette conception étend et contracte alternativement la longueur de la séquence autour du SSM bidirectionnel tout en réduisant sélectivement la longueur de la séquence dans le MLP. L'architecture complète du modèle est illustrée à la figure 2
Plus précisément, chaque couche de sablier reçoit une séquence d'entrée raccourcie et aplatie I ∈ R^(J×D), où M = L/J est le rapport de réduction et élargissement. Dans le même temps, le bloc entier, y compris le SSM bidirectionnel, est calculé sur la longueur d'origine, tirant pleinement parti du contexte global. σ est utilisé dans cet article pour représenter la fonction d'activation. Pour l ∈ {1 . L}, où j = ⌊l/M⌋, m = l mod M, D_m = 2D/M, l'équation de calcul est la suivante : 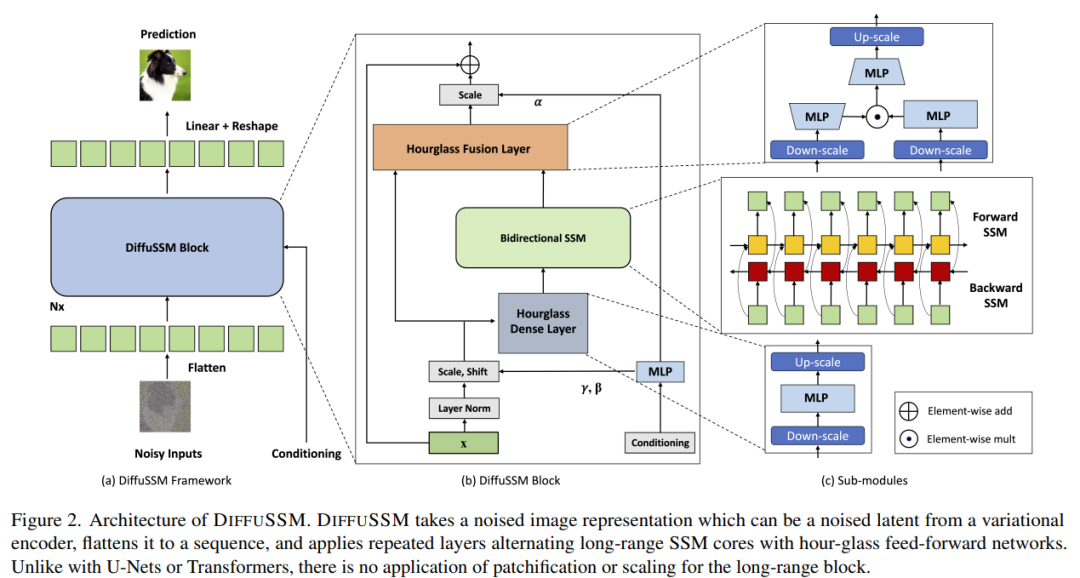
L'auteur dans chacun couche Intégrez des blocs SSM sécurisés à l'aide de connexions sautées. Les auteurs intègrent une combinaison d'étiquette de classe y ∈ R^(L×1) et de pas de temps t ∈ R^(L×1) à chaque emplacement, comme le montre la figure 2. 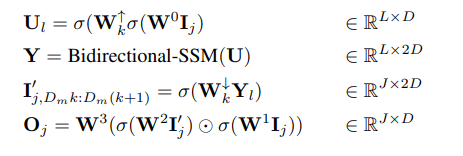
Paramètres : Le nombre de paramètres dans le bloc DIFFUSSM est principalement déterminé par la transformation linéaire W, qui contient 9D^2 + 2MD^2 paramètres. Lorsque M = 2, cela donne 13D^2 paramètres. Le bloc de transformation DiT a des paramètres 12D^2 dans sa couche de transformation principale ; cependant, l'architecture DiT a beaucoup plus de paramètres dans d'autres composants de couche (normalisation de couche adaptative). Les chercheurs ont fait correspondre les paramètres de leurs expériences en utilisant des couches DIFFUSSM supplémentaires.
FLOPs : la figure 3 compare les Gflops entre DiT et DIFFUSSM. Le total des Flops d'une couche DIFFUSSM est
, où α représente la constante implémentée par FFT. Cela donne environ 7,5LD^2 Gflops lorsque M = 2 et que les couches linéaires dominent le calcul. En comparaison, si l'auto-attention complète est utilisée à la place du SSM dans cette architecture en sablier, il y a 2DL^2 Flops supplémentaires. 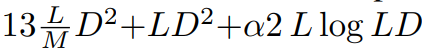
Considérez deux scénarios expérimentaux : 1) D ≈ L = 1024, ce qui entraînera 2LD^2 Flops supplémentaires, 2) 4D ≈ L = 4096, ce qui entraînera 8LD^2 Flops et augmentera considérablement le coût. . Étant donné que le coût de base du SSM bidirectionnel est faible par rapport au coût d’utilisation de l’attention, l’utilisation d’une architecture en sablier ne fonctionne pas pour les modèles basés sur l’attention. Comme indiqué précédemment, DiT évite ces problèmes en utilisant le chunking au détriment de la représentation compressée. 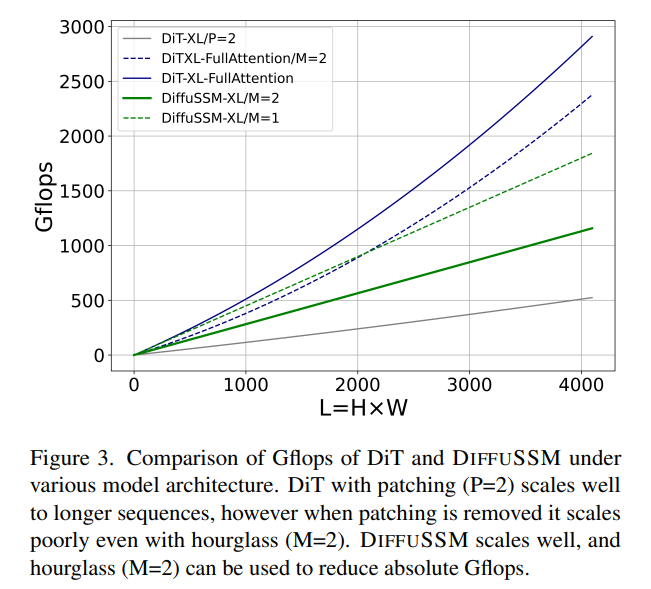
Résultats expérimentaux
Génération d'images conditionnelles de catégorie
Le tableau suivant présente les résultats de comparaison de DIFFUSSM avec tous les modèles de génération de condition de catégorie de pointe actuels
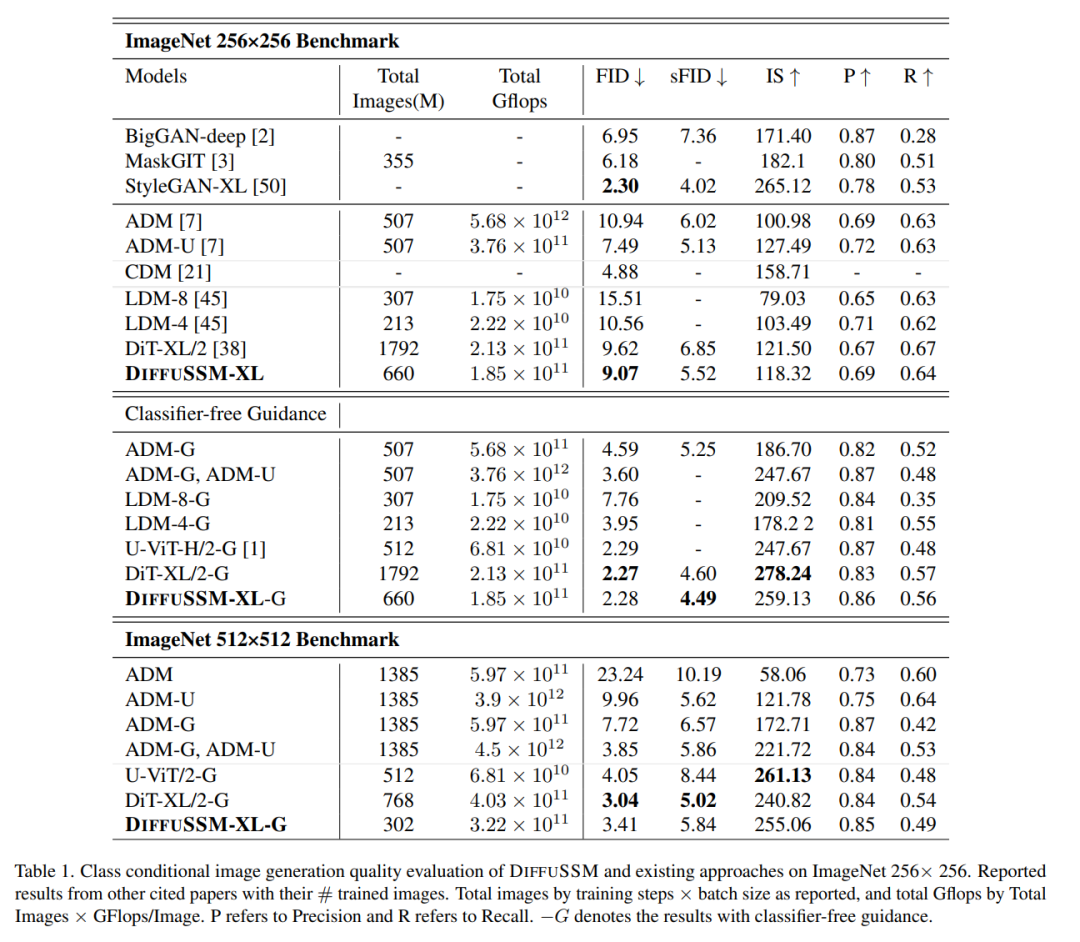 Lorsque Aucun n'est utilisé Lorsqu'il est guidé par un classificateur, DIFFUSSM surpasse les autres modèles de diffusion dans les deux FID et sFID, réduisant le meilleur score du modèle de diffusion potentiel précédent sans guidage du classificateur de 9,62 à 9,07, tout en réduisant le nombre d'étapes de formation utilisées. à 1/3 environ. En termes de nombre total de Gflops entraînés, le modèle non compressé réduit le total de Gflops de 20 % par rapport au DiT. Lorsque le guidage sans classificateur est introduit, le modèle obtient le meilleur score sFID parmi tous les modèles basés sur DDPM, surpassant ainsi les autres stratégies de pointe, indiquant que les images générées par DIFFUSSM sont plus robustes à la distorsion spatiale.
Lorsque Aucun n'est utilisé Lorsqu'il est guidé par un classificateur, DIFFUSSM surpasse les autres modèles de diffusion dans les deux FID et sFID, réduisant le meilleur score du modèle de diffusion potentiel précédent sans guidage du classificateur de 9,62 à 9,07, tout en réduisant le nombre d'étapes de formation utilisées. à 1/3 environ. En termes de nombre total de Gflops entraînés, le modèle non compressé réduit le total de Gflops de 20 % par rapport au DiT. Lorsque le guidage sans classificateur est introduit, le modèle obtient le meilleur score sFID parmi tous les modèles basés sur DDPM, surpassant ainsi les autres stratégies de pointe, indiquant que les images générées par DIFFUSSM sont plus robustes à la distorsion spatiale.
Le score FID de DIFFUSSM surpasse tous les modèles lors de l'utilisation d'un guidage sans classificateur et maintient un écart assez faible (0,01) par rapport à DiT. Notez que DIFFUSSM, entraîné avec une réduction de 30 % du total des Gflops, surpasse déjà DiT sans appliquer de guidage sans classificateur. U-ViT est une autre architecture basée sur Transformer, mais utilise une architecture basée sur UNet avec des connexions à long saut entre les blocs. U-ViT utilise moins de FLOP et fonctionne mieux avec une résolution de 256 × 256, mais ce n'est pas le cas dans l'ensemble de données 512 × 512. L'auteur compare principalement avec DiT Par souci d'équité, cette connexion à long saut n'est pas adoptée. L'auteur estime que l'idée d'adopter U-Vit peut être bénéfique à la fois pour DiT et DIFFUSSM.
Les auteurs effectuent en outre des comparaisons sur des références à plus haute résolution en utilisant des conseils sans classificateur. Les résultats de DIFFUSSM sont relativement solides et proches des modèles haute résolution de pointe, seulement inférieurs à DiT sur sFID, et atteignent des scores FID comparables. DIFFUSSM a été formé sur 302 millions d'images, a observé 40 % des images et a utilisé 25 % de Gflops en moins que DiT
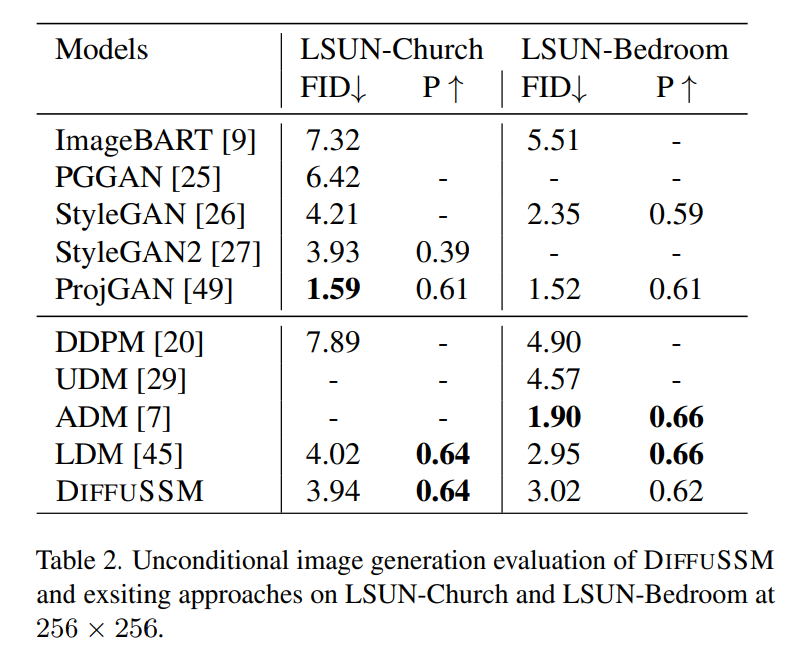
Génération d'images inconditionnelles
Basé sur l'estimation de l'auteur des capacités de génération d'images inconditionnelles du modèle. de la comparaison sont présentés dans le tableau 2. Les recherches de l'auteur ont révélé qu'avec un budget de formation comparable à celui du LDM, DIFFUSSM a obtenu des scores FID comparables (différences de -0,08 et 0,07). Ce résultat met en évidence l’applicabilité de DIFFUSSM sur différents benchmarks et différentes tâches. Semblable à LDM, cette méthode ne surpasse pas ADM sur la tâche LSUN-Bedrooms puisqu'elle n'utilise que 25 % du budget total de formation d'ADM. Pour cette tâche, le meilleur modèle GAN surpasse le modèle de diffusion dans la catégorie de modèle
Veuillez vous référer à l'article original pour plus de détails
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
