
 Périphériques technologiques
IA
Cet article résume les méthodes classiques et la comparaison des effets de l'amélioration et de la personnalisation des fonctionnalités dans l'estimation du CTR.
Périphériques technologiques
IA
Cet article résume les méthodes classiques et la comparaison des effets de l'amélioration et de la personnalisation des fonctionnalités dans l'estimation du CTR.
Cet article résume les méthodes classiques et la comparaison des effets de l'amélioration et de la personnalisation des fonctionnalités dans l'estimation du CTR.

Dans l'estimation du CTR, la méthode traditionnelle utilise l'intégration de fonctionnalités + MLP, dans lesquels les fonctionnalités sont très critiques. Cependant, pour les mêmes caractéristiques, la représentation est la même dans différents échantillons. Cette façon de saisir le modèle en aval limitera la capacité d'expression du modèle.
Afin de résoudre ce problème, une série de travaux connexes ont été proposés dans le domaine de l'estimation du CTR, appelés module d'amélioration des fonctionnalités. Le module d'amélioration des fonctionnalités corrige les résultats de sortie de la couche d'intégration en fonction de différents échantillons pour s'adapter à la représentation des caractéristiques de différents échantillons et améliorer la capacité d'expression du modèle.
Récemment, l'Université de Fudan et Microsoft Research Asia ont publié conjointement une revue des travaux d'amélioration des fonctionnalités, comparant les méthodes de mise en œuvre et les effets des différents modules d'amélioration des fonctionnalités. Présentons maintenant les méthodes de mise en œuvre de plusieurs modules d'amélioration des fonctionnalités, ainsi que les expériences comparatives associées menées dans cet article
 Titre de l'article : Résumé et évaluation complets des modules de raffinement des fonctionnalités pour la prédiction du CTR
Titre de l'article : Résumé et évaluation complets des modules de raffinement des fonctionnalités pour la prédiction du CTR
Adresse de téléchargement : https :// arxiv.org/pdf/2311.04625v1.pdf
1. Idée de modélisation d'amélioration des fonctionnalités
Le module d'amélioration des fonctionnalités est conçu pour améliorer la capacité d'expression de la couche d'intégration dans le modèle de prédiction CTR et réaliser une différenciation des représentations du mêmes caractéristiques sous différents échantillons. Le module d'amélioration des fonctionnalités peut être exprimé par la formule unifiée suivante, saisir l'intégration d'origine et, après avoir transmis une fonction, générer l'intégration personnalisée de cet exemple.
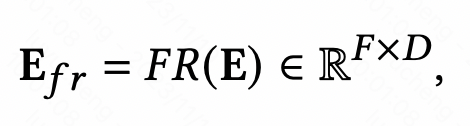 Images
Images
L'idée générale de cette méthode est qu'après avoir obtenu l'intégration initiale de chaque fonctionnalité, utilisez la représentation de l'échantillon lui-même pour transformer l'intégration de fonctionnalités afin d'obtenir l'intégration personnalisée de l'échantillon actuel. Nous présentons ici quelques méthodes classiques de modélisation de modules d’amélioration des fonctionnalités.
2. Méthode classique d'amélioration des fonctionnalités
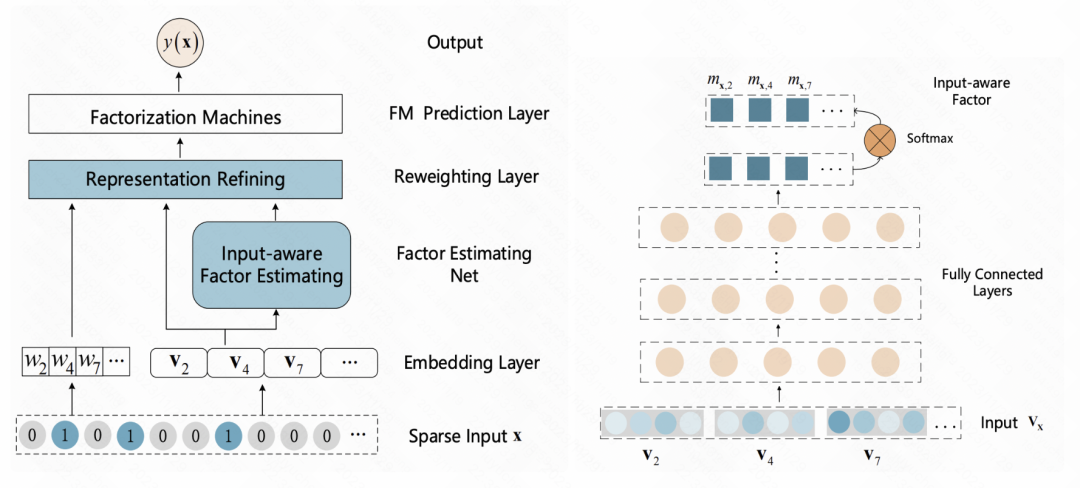
Une machine de factorisation sensible aux entrées pour la prédiction clairsemée (IJCAI 2019) Cet article ajoute une couche de repondération après la couche d'intégration et saisit l'intégration initiale de l'échantillon dans un MLP pour obtenir une représentation. de l'échantillon, normalisés à l'aide de softmax. Chaque élément après Softmax correspond à une fonctionnalité, représentant l'importance de cette fonctionnalité. Ce résultat softmax est multiplié par l'intégration initiale de chaque fonctionnalité correspondante pour obtenir une pondération d'intégration des fonctionnalités à la granularité de l'échantillon.
 Pictures
Pictures
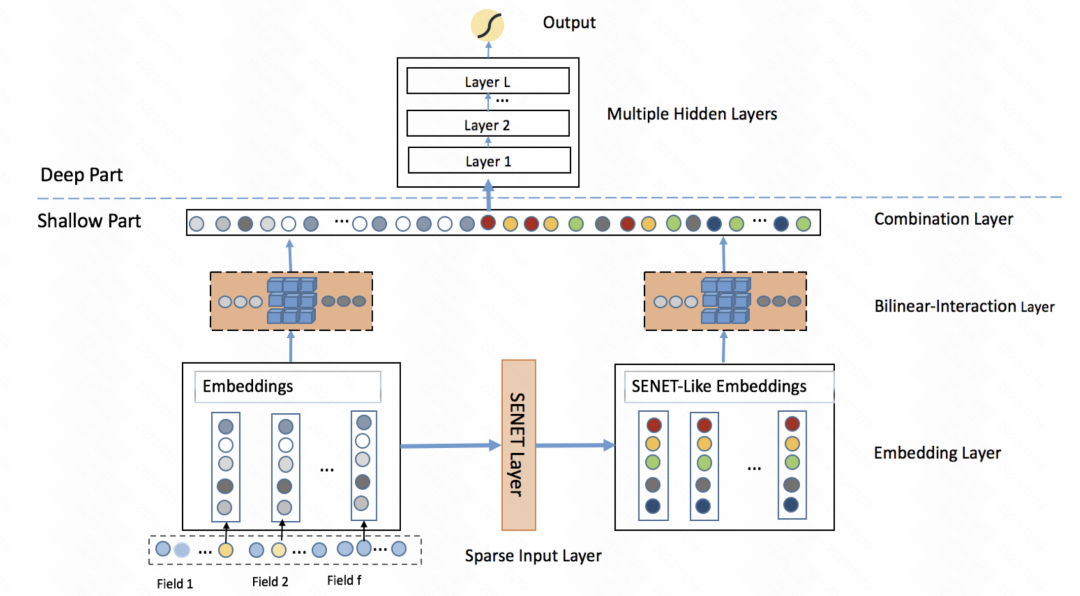
FiBiNET : un modèle de prédiction du taux de clics combinant l'importance des fonctionnalités et l'interaction des fonctionnalités de second ordre (RecSys 2019) adopte également une idée similaire. Le modèle apprend un poids personnalisé d'une caractéristique pour chaque échantillon. L'ensemble du processus est divisé en trois étapes : pressage, extraction et repondération. Lors de l'étape de compression, le vecteur d'intégration de chaque caractéristique est obtenu sous forme de scalaire statistique grâce à la méthode de pooling. Lors de l'étape d'extraction, ces scalaires sont entrés dans un perceptron multicouche (MLP) pour obtenir le poids de chaque caractéristique. Enfin, ces poids sont multipliés par le vecteur d'intégration de chaque caractéristique pour obtenir le résultat d'intégration pondéré, ce qui équivaut au filtrage de l'importance des caractéristiques au niveau de l'échantillon
 Image
Image
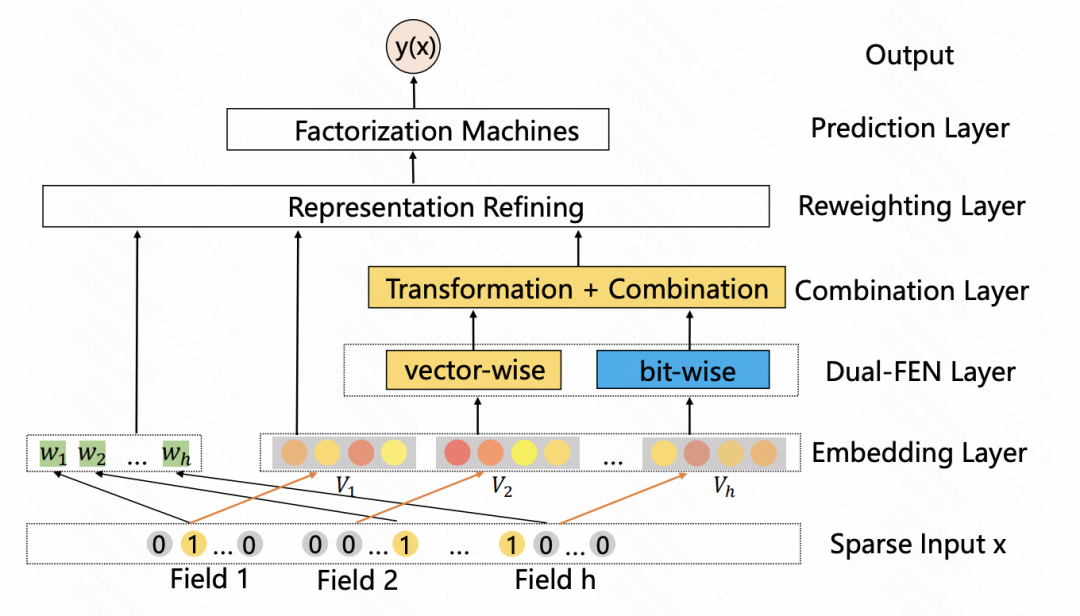
Une machine de factorisation à double entrée pour la prédiction du CTR ( IJCAI 2020) est similaire à l'article précédent, utilisant également l'auto-attention pour améliorer les fonctionnalités. Le tout est divisé en deux modules : vectoriel et bit-wise. Vector-wise traite l'intégration de chaque fonctionnalité comme un élément dans la séquence et l'entre dans le transformateur pour obtenir la représentation des fonctionnalités fusionnées ; la partie par bit utilise MLP multicouche pour mapper les fonctionnalités d'origine. Une fois les résultats d'entrée des deux parties ajoutés, le poids de chaque élément de fonctionnalité est obtenu et multiplié par chaque bit de la fonctionnalité d'origine correspondante pour obtenir la fonctionnalité améliorée.
 Image
Image
GateNet : Enhanced Gated Deep Network for Click-through Rate Prediction (2020) Utilise le vecteur d'intégration initial de chaque fonctionnalité pour générer son score de pondération de fonctionnalité indépendant via une fonction MLP et sigmoïde, tout en utilisant MLP pour combiner toutes les fonctionnalités sont mappées à des scores de pondération au niveau du bit, et les deux sont combinés pour pondérer les fonctionnalités d'entrée. En plus de la couche de fonctionnalités, dans la couche cachée de MLP, une méthode similaire est également utilisée pour pondérer l'entrée de chaque couche cachée
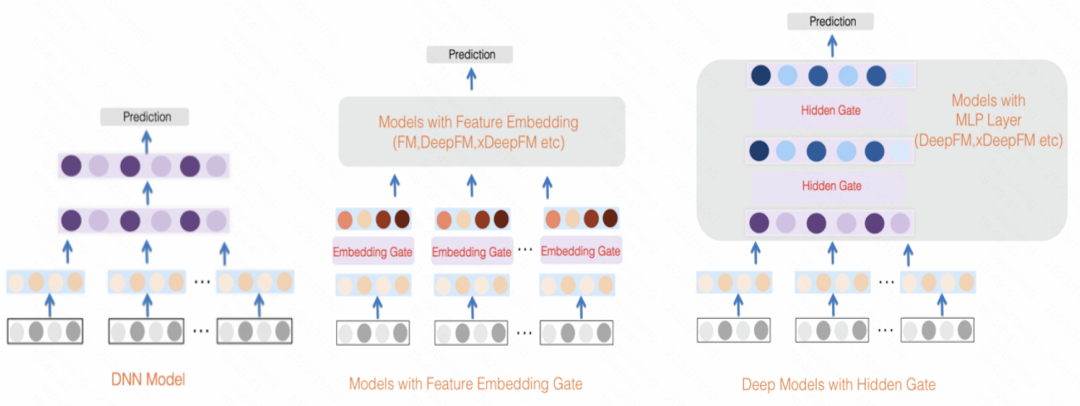 image
image
La prédiction interprétable du taux de clics via l'attention hiérarchique (WSDM 2020) utilise également l'auto-attention pour réaliser la conversion des fonctionnalités, mais ajoute la génération de fonctionnalités d'ordre élevé. L'auto-attention hiérarchique est utilisée ici.Chaque couche d'auto-attention prend comme entrée la sortie de la couche d'auto-attention précédente.Chaque couche ajoute une combinaison de caractéristiques de premier ordre pour obtenir une extraction hiérarchique de caractéristiques multi-ordres. Plus précisément, une fois que chaque couche a effectué une auto-attention, la nouvelle matrice de fonctionnalités générée est transmise via softmax pour obtenir le poids de chaque fonctionnalité. Les nouvelles fonctionnalités sont pondérées en fonction des poids des fonctionnalités d'origine, puis un produit scalaire est effectué. avec les caractéristiques originales pour obtenir une augmentation d'une caractéristique d'intersection des niveaux.
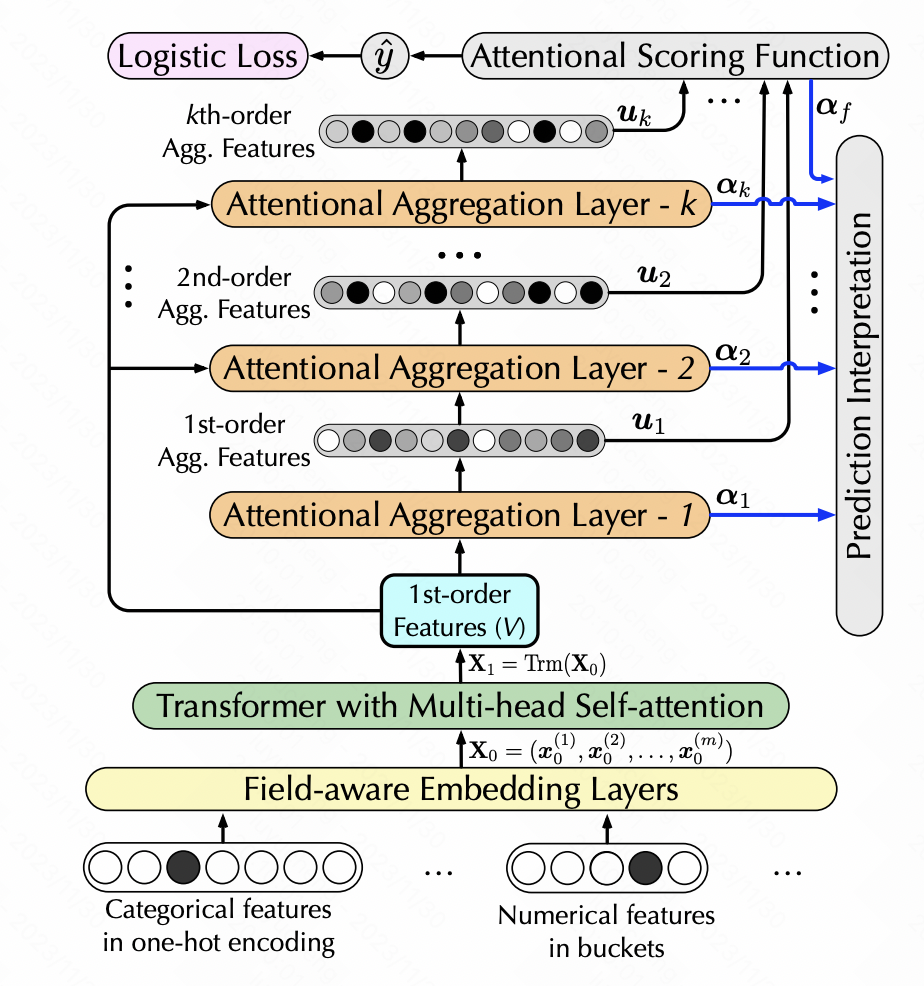 Pictures
Pictures
ContextNet : un cadre de prévision du taux de clics utilisant des informations contextuelles pour affiner l'intégration des fonctionnalités (2021) est également une approche similaire, utilisant un MLP pour mapper toutes les fonctionnalités dans une dimension de chaque taille d'intégration de fonctionnalités, par exemple Les fonctionnalités d'origine sont mises à l'échelle et des paramètres MLP personnalisés sont utilisés pour chaque fonctionnalité. De cette manière, chaque fonctionnalité est améliorée en utilisant d'autres fonctionnalités de l'échantillon comme bits supérieurs et inférieurs.
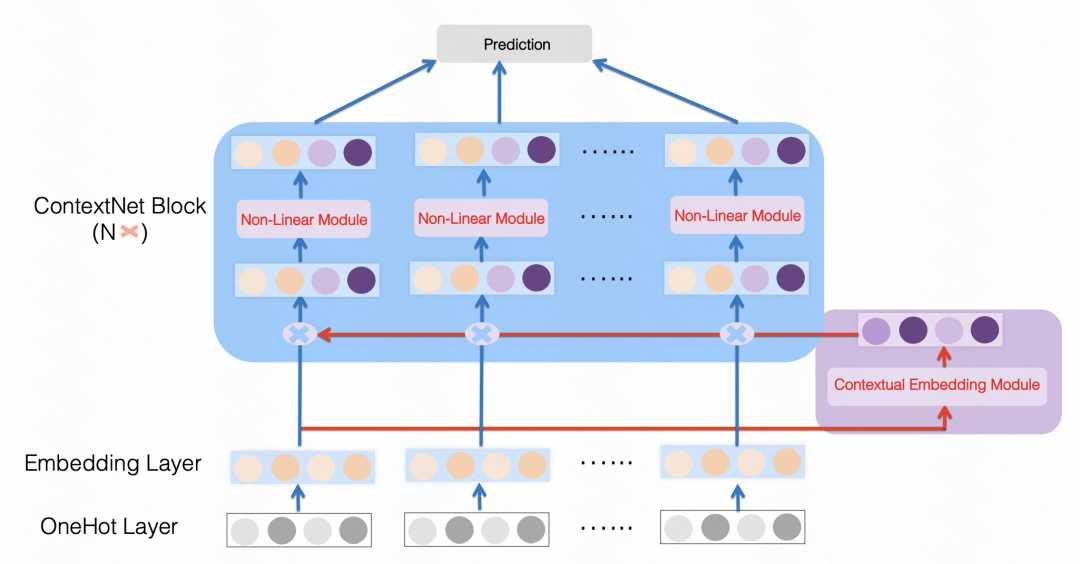 Images
Images
Amélioration de la prédiction du CTR avec l'apprentissage de la représentation des fonctionnalités contextuelle (SIGIR 2022) utilise l'auto-attention pour l'amélioration des fonctionnalités. Pour un ensemble de fonctionnalités d'entrée, le degré d'influence de chaque fonctionnalité sur d'autres fonctionnalités est différent. Grâce à l'auto-attention, l'auto-attention est effectuée sur l'intégration de chaque fonctionnalité pour obtenir une interaction d'informations entre les fonctionnalités au sein de l'échantillon. En plus de l'interaction entre les fonctionnalités, l'article utilise également MLP pour l'interaction des informations au niveau bit. La nouvelle intégration générée ci-dessus sera fusionnée avec l'intégration d'origine via un réseau de portes pour obtenir la représentation finale raffinée des fonctionnalités.
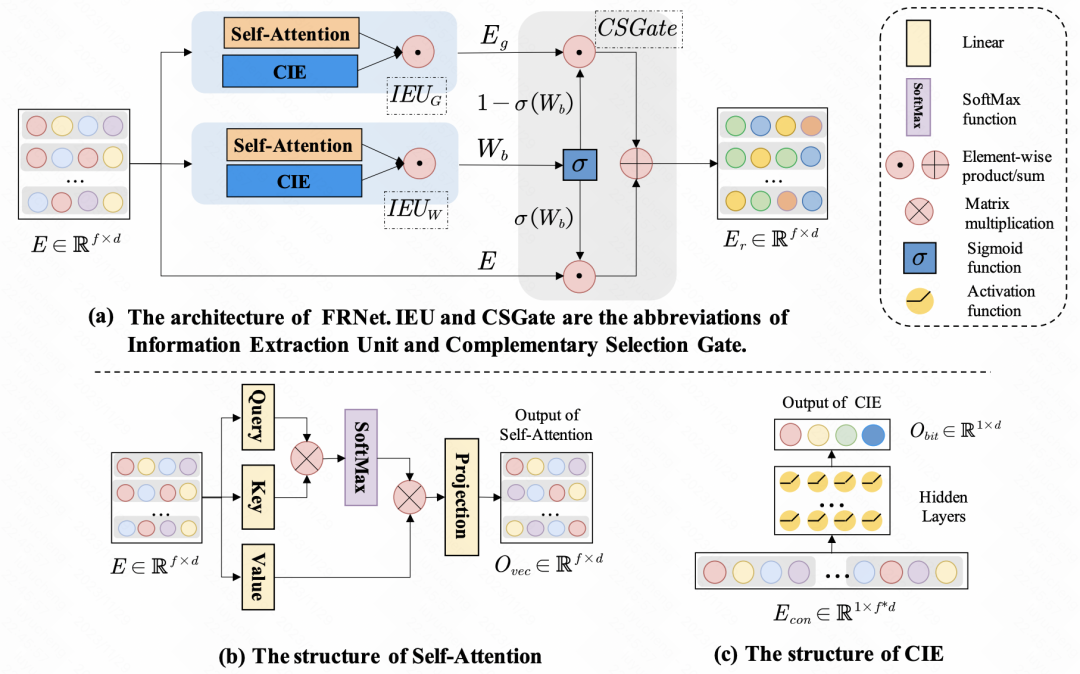 Photos
Photos
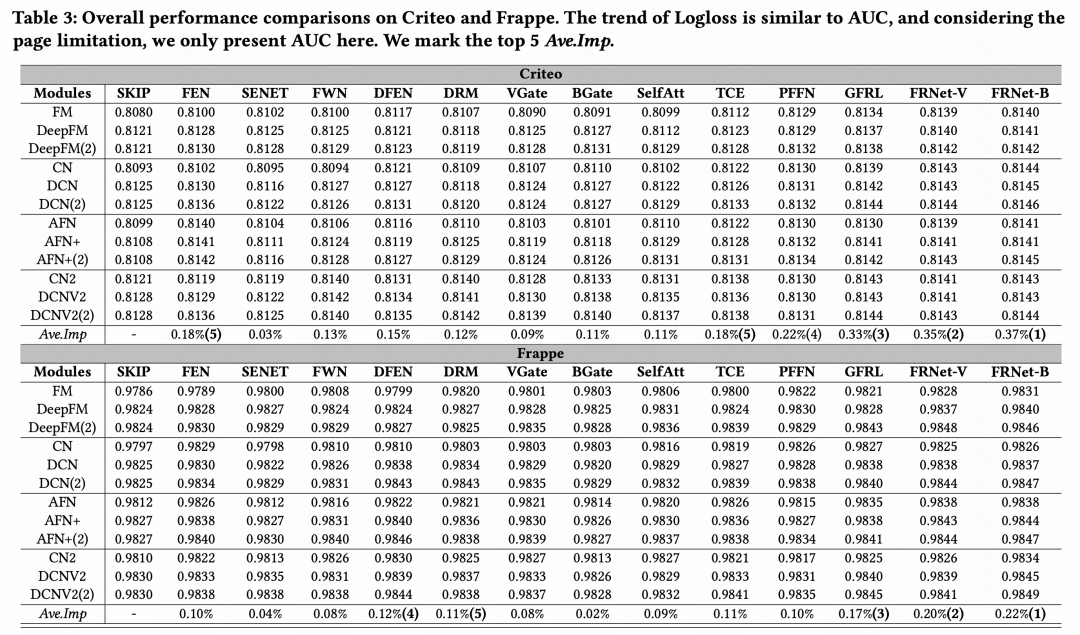
3. Résultats expérimentaux
Après avoir comparé les effets de diverses méthodes d'amélioration des fonctionnalités, nous sommes arrivés à la conclusion générale : parmi de nombreux modules d'amélioration des fonctionnalités, GFRL, FRNet-V et FRNetB sont les plus performants, et The l'effet est meilleur que les autres méthodes d'amélioration des fonctionnalités
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1657
1657
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

![Le module d'extension WLAN s'est arrêté [correctif]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) Le module d'extension WLAN s'est arrêté [correctif]
Feb 19, 2024 pm 02:18 PM
Le module d'extension WLAN s'est arrêté [correctif]
Feb 19, 2024 pm 02:18 PM
S'il y a un problème avec le module d'extension WLAN sur votre ordinateur Windows, cela peut entraîner une déconnexion d'Internet. Cette situation est souvent frustrante, mais heureusement, cet article propose quelques suggestions simples qui peuvent vous aider à résoudre ce problème et à rétablir le bon fonctionnement de votre connexion sans fil. Réparer le module d'extensibilité WLAN s'est arrêté Si le module d'extensibilité WLAN a cessé de fonctionner sur votre ordinateur Windows, suivez ces suggestions pour le réparer : Exécutez l'utilitaire de résolution des problèmes réseau et Internet pour désactiver et réactiver les connexions réseau sans fil Redémarrez le service de configuration automatique WLAN Modifier les options d'alimentation Modifier Paramètres d'alimentation avancés Réinstaller le pilote de la carte réseau Exécuter certaines commandes réseau Examinons-le maintenant en détail
 Le module d'extensibilité WLAN ne peut pas démarrer
Feb 19, 2024 pm 05:09 PM
Le module d'extensibilité WLAN ne peut pas démarrer
Feb 19, 2024 pm 05:09 PM
Cet article détaille les méthodes permettant de résoudre l'événement ID10000, qui indique que le module d'extension LAN sans fil ne peut pas démarrer. Cette erreur peut apparaître dans le journal des événements du PC Windows 11/10. Le module d'extensibilité WLAN est un composant de Windows qui permet aux fournisseurs de matériel indépendants (IHV) et aux fournisseurs de logiciels indépendants (ISV) de fournir aux utilisateurs des fonctionnalités de réseau sans fil personnalisées. Il étend les fonctionnalités des composants réseau Windows natifs en ajoutant la fonctionnalité par défaut de Windows. Le module d'extensibilité WLAN est démarré dans le cadre de l'initialisation lorsque le système d'exploitation charge les composants réseau. Si le module d'extension LAN sans fil rencontre un problème et ne peut pas démarrer, vous pouvez voir un message d'erreur dans le journal de l'Observateur d'événements.
 Python bibliothèques standard couramment utilisées et bibliothèques tierces module 2-sys
Apr 10, 2023 pm 02:56 PM
Python bibliothèques standard couramment utilisées et bibliothèques tierces module 2-sys
Apr 10, 2023 pm 02:56 PM
1. Introduction au module sys Le module os présenté précédemment est principalement destiné au système d'exploitation, tandis que le module sys de cet article est principalement destiné à l'interpréteur Python. Le module sys est un module fourni avec Python. C'est une interface permettant d'interagir avec l'interpréteur Python. Le module sys fournit de nombreuses fonctions et variables pour gérer différentes parties de l'environnement d'exécution Python. 2. Méthodes couramment utilisées du module sys Vous pouvez vérifier quelles méthodes sont incluses dans le module sys via la méthode dir() : import sys print(dir(sys))1.sys.argv-get les paramètres de ligne de commande sys. argv est utilisé pour implémenter la commande depuis l'extérieur du programme. Le programme reçoit des paramètres et il est capable d'obtenir la colonne des paramètres de la ligne de commande.
 Comment fonctionne l'importation de Python ?
May 15, 2023 pm 08:13 PM
Comment fonctionne l'importation de Python ?
May 15, 2023 pm 08:13 PM
Bonjour, je m'appelle somenzz, vous pouvez m'appeler frère Zheng. L'importation de Python est très intuitive, mais même ainsi, vous constaterez parfois que même si le package est là, nous rencontrerons toujours ModuleNotFoundError. Le chemin relatif est évidemment très correct, mais l'erreur ImportError:tentativerelativeimportwithnoknownparentpackage importe un module dans le même répertoire et. un différent. Les modules du répertoire sont complètement différents. Cet article vous aide à gérer facilement l'import en analysant certains problèmes souvent rencontrés lors de l'utilisation de l'import. Sur cette base, vous pouvez facilement créer des attributs.
 Programmation Python : explication détaillée des points clés de l'utilisation de tuples nommés
Apr 11, 2023 pm 09:22 PM
Programmation Python : explication détaillée des points clés de l'utilisation de tuples nommés
Apr 11, 2023 pm 09:22 PM
Préface Cet article continue de présenter le module de collection Python. Cette fois, il y introduit principalement les tuples nommés, c'est-à-dire l'utilisation de nommétuple. Sans plus tarder, commençons – n'oubliez pas d'aimer, de suivre et de transmettre ~ ^_^Création de tuples nommés La classe de tuple nommé nomméeTuples dans la collection Python donne un sens à chaque position dans le tuple et améliore la lisibilité du code sexuel et descriptif. Ils peuvent être utilisés partout où des tuples réguliers sont utilisés et ajoutent la possibilité d'accéder aux champs par nom plutôt que par index de position. Il provient des collections de modules intégrés Python. La syntaxe générale utilisée est : importer des collections XxNamedT
 Explication détaillée du fonctionnement d'Ansible
Feb 18, 2024 pm 05:40 PM
Explication détaillée du fonctionnement d'Ansible
Feb 18, 2024 pm 05:40 PM
Le principe de fonctionnement d'Ansible peut être compris à partir de la figure ci-dessus : l'extrémité de gestion prend en charge trois méthodes locales, ssh et zeromq pour se connecter à l'extrémité gérée. La valeur par défaut est d'utiliser une connexion basée sur ssh. Cette partie correspond au module de connexion. dans le diagramme d'architecture ci-dessus ; il peut être connecté par type d'application. La classification HostInventory (liste d'hôtes) est effectuée d'autres manières. Le nœud de gestion implémente les opérations correspondantes via divers modules. Un seul module et l'exécution par lots d'une seule commande peuvent être appelés. -hoc ; le nœud de gestion peut implémenter un ensemble de tâches multiples via des playbooks. Implémenter un type de fonctions, telles que l'installation et le déploiement de services Web, la sauvegarde par lots de serveurs de base de données, etc. Nous pouvons simplement comprendre les playbooks au fur et à mesure que le système passe
 Comment utiliser DateTime en Python
Apr 19, 2023 pm 11:55 PM
Comment utiliser DateTime en Python
Apr 19, 2023 pm 11:55 PM
Toutes les données reçoivent automatiquement un « DOB » (Date de naissance) au début. Par conséquent, il est inévitable de rencontrer des données de date et d’heure lors du traitement des données à un moment donné. Ce didacticiel vous fera découvrir le module datetime en Python et l'utilisation de certaines bibliothèques périphériques telles que pandas et pytz. En Python, tout ce qui concerne la date et l'heure est géré par le module datetime, qui divise le module en 5 classes différentes. Les classes sont simplement des types de données qui correspondent à des objets. La figure suivante résume les 5 classes datetime en Python ainsi que les attributs et exemples couramment utilisés. 3 extraits utiles 1. Convertir la chaîne au format datetime, peut-être en utilisant datet
 Cet article résume les méthodes classiques et la comparaison des effets de l'amélioration et de la personnalisation des fonctionnalités dans l'estimation du CTR.
Dec 15, 2023 am 09:23 AM
Cet article résume les méthodes classiques et la comparaison des effets de l'amélioration et de la personnalisation des fonctionnalités dans l'estimation du CTR.
Dec 15, 2023 am 09:23 AM
Dans l'estimation du CTR, la méthode traditionnelle utilise l'intégration de fonctionnalités + MLP, dans lesquels les fonctionnalités sont très critiques. Cependant, pour les mêmes caractéristiques, la représentation est la même dans différents échantillons. Cette façon de saisir le modèle en aval limitera la capacité d'expression du modèle. Afin de résoudre ce problème, une série de travaux connexes ont été proposés dans le domaine de l'estimation du CTR, appelés module d'amélioration des fonctionnalités. Le module d'amélioration des fonctionnalités corrige les résultats de sortie de la couche d'intégration en fonction de différents échantillons pour s'adapter à la représentation des caractéristiques de différents échantillons et améliorer la capacité d'expression du modèle. Récemment, l'Université de Fudan et Microsoft Research Asia ont publié conjointement une étude sur les travaux d'amélioration des fonctionnalités, comparant les méthodes de mise en œuvre et les effets de différents modules d'amélioration des fonctionnalités. Maintenant, introduisons un
