
 Périphériques technologiques
IA
Une compréhension plus approfondie du transformateur visuel, analyse du transformateur visuel
Périphériques technologiques
IA
Une compréhension plus approfondie du transformateur visuel, analyse du transformateur visuel
Une compréhension plus approfondie du transformateur visuel, analyse du transformateur visuel

Cet article est réimprimé avec l'autorisation du compte public Autonomous Driving Heart. Veuillez contacter la source lors de la réimpression
Écrire devant&&Compréhension personnelle de l'auteur
Actuellement, les modèles d'algorithmes basés sur la structure Transformer ont été largement utilisés dans Le domaine de la vision par ordinateur (CV) a eu un grand impact. Ils surpassent les précédents modèles d’algorithmes de réseaux neuronaux convolutifs (CNN) sur de nombreuses tâches de base de vision par ordinateur. Ce qui suit est le dernier classement de la liste LeaderBoard des différentes tâches de vision par ordinateur de base que j'ai trouvées Grâce à LeaderBoard, nous pouvons voir la domination du modèle d'algorithme Transformer dans diverses tâches de vision par ordinateur
- Tâche de classification d'images
Premier sur ImageNet LeaderBoard, il ressort de la liste que parmi les cinq premiers, chaque modèle utilise la structure Transformer, tandis que la structure CNN n'est que partiellement utilisée, ou combinée avec le Transformer.

LeaderBoard pour la tâche de classification d'images
- Tâche de détection de cible
Le suivant est LeaderBoard sur COCO test-dev. On peut voir dans la liste que plus de la moitié des cinq premiers sont basés sur DETR The. la structure de type algorithme est étendue.
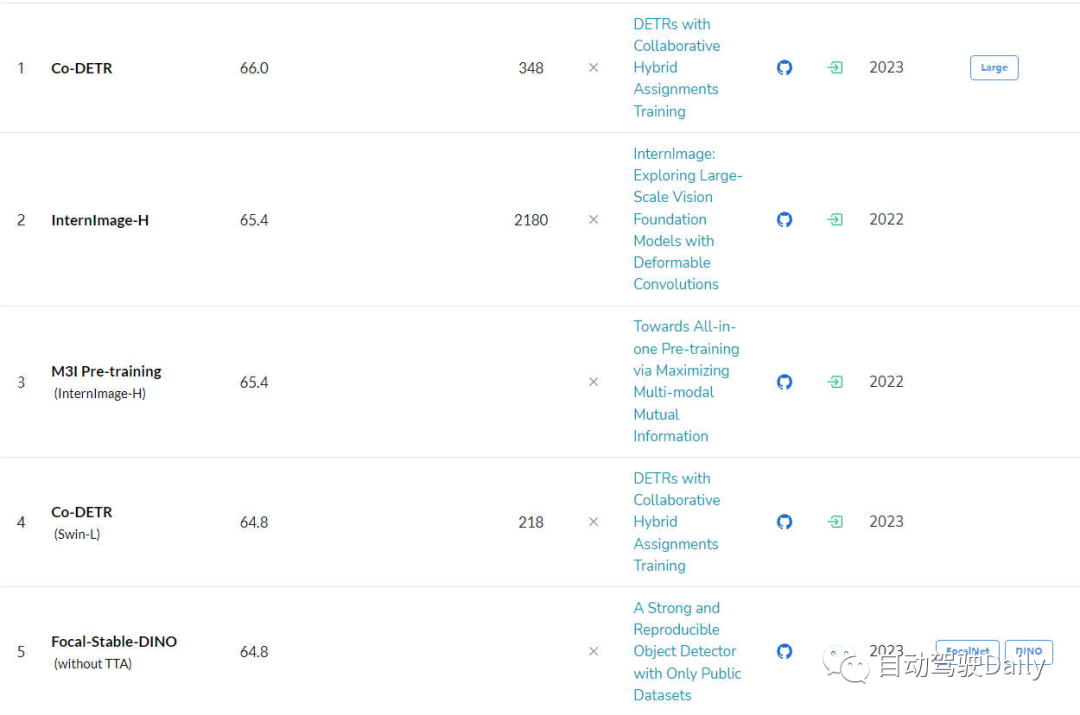 LeaderBoard pour la tâche de détection de cible
LeaderBoard pour la tâche de détection de cible
- Tâche de segmentation sémantique
Le dernier est LeaderBoard sur ADE20K val. On peut également voir dans la liste que parmi les premières de la liste, la structure Transformer occupe toujours l'actuelle. position. La force principale.
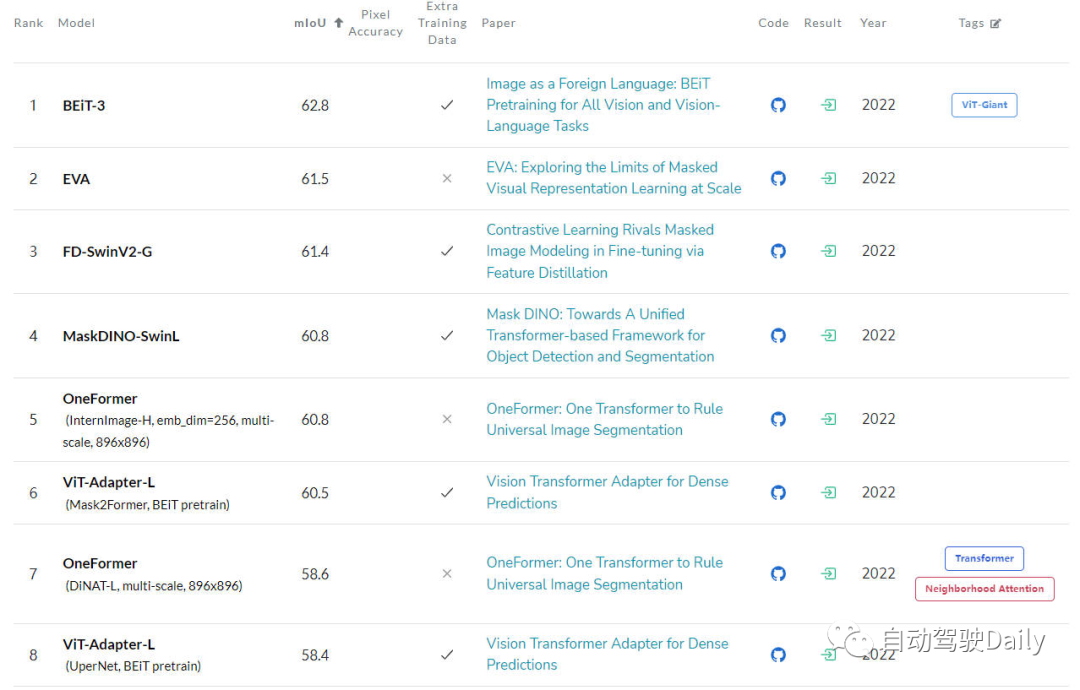 LeaderBoard pour les tâches de segmentation sémantique
LeaderBoard pour les tâches de segmentation sémantique
Bien que Transformer présente actuellement un grand potentiel de développement en Chine, la communauté actuelle de vision par ordinateur n'a pas pleinement compris le fonctionnement interne de Vision Transformer, ni sa prise de décision (résultats de prédiction de sortie)), donc le le besoin de son interprétabilité s’est progressivement fait sentir. Ce n'est qu'en comprenant comment ces modèles prennent des décisions que nous pourrons améliorer leurs performances et renforcer la confiance dans les systèmes d'intelligence artificielle
L'objectif principal de cet article est d'étudier différentes méthodes d'interprétabilité de Vision Transformer et sur la base des motivations de recherche de différents algorithmes, types de structures et les scénarios d'application sont classés pour former un article de synthèse
Analyse de Vision Transformer
Car comme mentionné tout à l'heure, la structure de Vision Transformer a obtenu de très bons résultats dans diverses tâches de vision par ordinateur de base. De nombreuses méthodes ont émergé dans la communauté de la vision par ordinateur pour améliorer son interprétabilité. Dans cet article, nous nous concentrons principalement sur les tâches de classification et sélectionnons les plus récentes et les plus récentes parmi cinq aspects : Méthodes d'attribution communes, Méthodes basées sur l'attention, Méthodes basées sur l'élagage, Méthodes intrinsèquement explicables, Autre Tâches Le travail classique est introduit. Voici la carte mentale qui apparaît dans l'article. Vous pouvez la lire plus en détail en fonction de ce qui vous intéresse ~
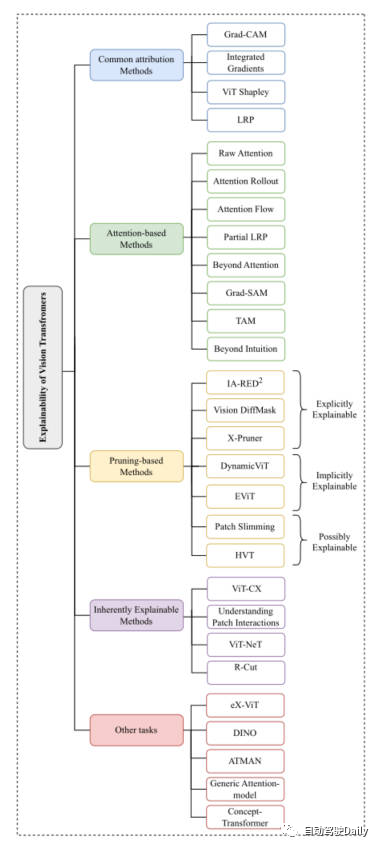
Carte mentale de cet article
Méthodes d'attribution courantes
Les explications basées sur les méthodes d'attribut commencent généralement. à partir du modèle Commençons par expliquer le processus par lequel les fonctionnalités d'entrée obtiennent progressivement le résultat de sortie final. Ce type de méthode est principalement utilisé pour mesurer la corrélation entre les résultats de prédiction du modèle et les caractéristiques d'entrée, telles que les algorithmes
Grad-CAMet Integrated Gradients sont directement appliqués aux algorithmes basés sur Visual Transformer. Certaines autres méthodes telles que SHAP et Layer-Wise Relevance Propagation (LRP) ont été utilisées pour explorer les architectures basées sur ViT. Cependant, en raison du coût de calcul très élevé de méthodes telles que SHAP, le récent algorithme ViT Shapely a été conçu pour s'adapter à la recherche d'applications liée au ViT. Méthodes basées sur l'attention
Vision Transformer a acquis de puissantes capacités d'extraction de fonctionnalités grâce à son mécanisme d'attention. Parmi les méthodes d’interprétabilité basées sur l’attention, la visualisation des résultats du poids d’attention est une méthode très efficace. Cet article présentera plusieurs techniques de visualisation
- Attention brute : Comme son nom l'indique, cette méthode consiste à visualiser la carte de poids d'attention obtenue à partir de la couche intermédiaire du modèle de réseau, afin d'analyser l'effet du modèle.
- Déploiement de l'attention : Cette technologie suit le transfert d'informations des jetons d'entrée vers les intégrations intermédiaires en élargissant les poids d'attention dans différentes couches du réseau.
- Attention Flow : Cette méthode traite la carte d'attention comme un réseau de flux et utilise l'algorithme de flux maximum pour calculer la valeur de flux maximale depuis l'intégration intermédiaire jusqu'au jeton d'entrée.
- partialLRP : Cette méthode est proposée pour visualiser le mécanisme d'attention multi-têtes dans Vision Transformer, tout en considérant également l'importance de chaque tête d'attention.
- Grad-SAM : Cette méthode est utilisée pour atténuer les limites liées au fait de s'appuyer uniquement sur la matrice d'attention d'origine pour expliquer les prédictions du modèle, incitant les chercheurs à utiliser des gradients dans les poids d'attention d'origine.
- Au-delà de l'intuition : Cette méthode est également une méthode d'explication de l'attention, comprenant deux étapes de perception de l'attention et de retour de raisonnement.
Enfin, voici un diagramme de visualisation de l'attention des différentes méthodes d'interprétabilité. Vous pouvez ressentir par vous-même la différence entre les différentes méthodes de visualisation.

Comparaison des cartes d'attention de différentes méthodes de visualisation
Méthodes basées sur l'élagage
L'élagage est une méthode très efficace qui est largement utilisée pour optimiser l'efficacité et la complexité de la structure du transformateur. La méthode d'élagage réduit le nombre de paramètres et la complexité de calcul du modèle en supprimant les informations redondantes ou inutiles. Bien que les algorithmes d’élagage se concentrent sur l’amélioration de l’efficacité de calcul du modèle, ce type d’algorithme peut toujours assurer l’interprétabilité du modèle.
Les méthodes d'élagage basées sur Vision-Transformer dans cet article peuvent être grossièrement divisées en trois catégories : explicitement explicable (explicitement explicable), implicitement explicable (implicitement explicable), éventuellement explicable (éventuellement explicable) expliquer).
-
Explicitement explicable
Parmi les méthodes basées sur l'élagage, il existe plusieurs types de méthodes qui peuvent fournir des modèles plus simples et plus explicables.
- IA-RED^2 : Le but de cette méthode est d'atteindre un équilibre optimal entre l'efficacité de calcul et l'interprétabilité du modèle d'algorithme. Et dans ce processus, la flexibilité du modèle d’algorithme ViT original est conservée.
- X-Pruner : Cette méthode est une méthode d'élagage des unités de saillance en créant un masque perceptuel interprétable qui mesure la contribution de chaque unité prévisible dans la prédiction d'une classe spécifique.
- Vision DiffMask : Cette méthode d'élagage comprend l'ajout d'un mécanisme de déclenchement à chaque couche ViT. Grâce au mécanisme de déclenchement, la sortie du modèle peut être maintenue tout en protégeant l'entrée. Au-delà de cela, le modèle algorithmique peut clairement déclencher un sous-ensemble des images restantes, permettant ainsi une meilleure compréhension des prédictions du modèle.
-
Implicitement explicable
Parmi les méthodes basées sur l'élagage, il existe également des méthodes classiques qui peuvent être divisées dans la catégorie des modèles d'explicabilité implicite. - Dynamic ViT : Cette méthode utilise un module de prédiction léger pour estimer l'importance de chaque jeton en fonction des caractéristiques actuelles. Ce module léger est ensuite ajouté à différentes couches de ViT pour élaguer les jetons redondants de manière hiérarchique. Plus important encore, cette méthode améliore l’interprétabilité en localisant progressivement les parties clés de l’image qui contribuent le plus à la classification.
- Efficient Vision Transformer (EViT) : L'idée principale de cette méthode est d'accélérer l'EViT en réorganisant les jetons. En calculant les scores d'attention, EViT conserve les jetons les plus pertinents tout en fusionnant les jetons les moins pertinents en jetons supplémentaires. Dans le même temps, afin d'évaluer l'interprétabilité d'EViT, l'auteur de l'article a visualisé le processus de reconnaissance de jetons sur plusieurs images d'entrée.
-
Peut-être explicable
Bien que ce type de méthode n'ait pas été conçu à l'origine pour améliorer l'interprétabilité de ViT, ce type de méthode offre un grand potentiel pour des recherches plus approfondies sur l'interprétabilité du modèle.
- Patch Minceur : Accélérez ViT en vous concentrant sur les correctifs redondants dans les images grâce à une approche descendante. L'algorithme conserve de manière sélective la capacité des correctifs clés à mettre en évidence des caractéristiques visuelles importantes, améliorant ainsi l'interprétabilité.
- Hierarchical Visual Transformer (HVT) : Cette méthode est introduite pour améliorer l'évolutivité et les performances de ViT. À mesure que la profondeur du modèle augmente, la longueur de la séquence diminue progressivement. De plus, en divisant les blocs ViT en plusieurs étapes et en appliquant des opérations de pooling à chaque étape, l'efficacité des calculs est considérablement améliorée. Compte tenu de la concentration progressive sur les composants les plus importants du modèle, il existe une opportunité d'explorer son impact potentiel sur l'amélioration de l'interprétabilité et de l'interprétabilité.
Méthodes intrinsèquement explicables
Parmi les différentes méthodes interprétables, il existe une classe de méthodes qui développent principalement des modèles algorithmiques capables de les expliquer intrinsèquement. Cependant, ces modèles ont souvent du mal à atteindre le même niveau de précision que les boîtes noires plus complexes. modèles. Par conséquent, un équilibre minutieux doit être considéré entre interprétabilité et performance. Ensuite, quelques œuvres classiques sont brièvement présentées.
- ViT-CX : Cette méthode est une méthode d'interprétation basée sur un masque personnalisée pour le modèle ViT. Cette approche repose sur l'intégration de correctifs et son impact sur les résultats du modèle, plutôt que de se concentrer sur eux. Cette méthode comprend deux étapes : la génération de masques et l'agrégation de masques, fournissant ainsi une carte de saillance plus significative.
- ViT-NeT : Cette méthode est un nouveau décodeur d'arbre neuronal qui décrit le processus de prise de décision à travers des structures arborescentes et des prototypes. Dans le même temps, l’algorithme permet également une interprétation visuelle des résultats.
- R-Cut : Cette méthode améliore l'interprétabilité de ViT grâce à la relation pondérée et coupée. Cette méthode comprend deux modules, à savoir les modules Relation Weighted Out et Cut. Le premier se concentre sur l’extraction de classes spécifiques d’informations de la couche intermédiaire, en mettant l’accent sur les caractéristiques pertinentes. Ce dernier effectue une décomposition fine des caractéristiques. En intégrant les deux modules, des cartes d'interprétabilité denses spécifiques à la classe peuvent être générées.
Autres tâches
L'architecture basée sur ViT doit encore être expliquée pour d'autres tâches de vision par ordinateur dans l'exploration. Certaines méthodes d'interprétabilité ont été proposées spécifiquement pour d'autres tâches, et les derniers travaux dans des domaines connexes seront présentés ci-dessous
- eX-ViT : Cet algorithme est un nouveau transformateur visuel interprétable basé sur une segmentation sémantique faiblement supervisée. De plus, afin d'améliorer l'interprétabilité, un module de perte orienté attribut est introduit, qui contient trois pertes : la perte orientée attribut au niveau mondial, la perte de discriminabilité des attributs au niveau local et la perte de diversité des attributs. Le premier utilise des cartes d’attention pour créer des caractéristiques interprétables, tandis que les deux derniers améliorent l’apprentissage des attributs.
- DINO : Cette méthode est une méthode simple auto-supervisée et une méthode d'autodistillation sans étiquettes. La carte d'attention finale apprise peut conserver efficacement les régions sémantiques de l'image, atteignant ainsi des objectifs interprétables.
- Generic Attention-model : Cette méthode est un modèle d'algorithme de prédiction basé sur l'architecture Transformer. La méthode est appliquée aux trois architectures les plus couramment utilisées, à savoir l’attention personnelle pure, l’attention personnelle combinée à une attention conjointe et l’attention codeur-décodeur. Pour tester l'interprétabilité du modèle, les auteurs ont utilisé une tâche de réponse visuelle aux questions, cependant, elle est également applicable à d'autres tâches CV telles que la détection d'objets et la segmentation d'images.
- ATMAN : Il s'agit d'une méthode de perturbation indépendante des modalités qui utilise un mécanisme d'attention pour générer une carte de corrélation de l'entrée par rapport à la prédiction de sortie. Cette approche tente de comprendre la prédiction des déformations grâce à des opérations d’attention efficaces en mémoire.
- Concept-Transformer : cet algorithme génère des explications sur les sorties du modèle en mettant en évidence les scores d'attention pour les concepts de haut niveau définis par l'utilisateur, garantissant ainsi la fiabilité et la fiabilité.
Future Outlook
Actuellement, les modèles d'algorithmes basés sur l'architecture Transformer ont obtenu des résultats exceptionnels dans diverses tâches de vision par ordinateur. Cependant, il y a actuellement un manque de recherche évidente sur la manière d'utiliser les méthodes d'interprétabilité pour promouvoir le débogage et l'amélioration des modèles, et améliorer l'équité et la fiabilité des modèles, en particulier dans les applications ViT.
Cet article vise à utiliser des tâches de classification d'images pour améliorer l'équité et la fiabilité. de modèles. Les modèles d'algorithme d'interprétabilité de Vision Transformer sont classés et organisés pour aider les lecteurs à mieux comprendre l'architecture de ces modèles. J'espère que cela sera utile à tout le monde

Ce qui doit être réécrit est : Lien original : https : // mp.weixin.qq.com/s/URkobeRNB8dEYzrECaC7tQ
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
