
 Périphériques technologiques
IA
QTNet : Nouvelle solution de fusion temporelle pour nuages de points, images et détecteurs multimodaux (NeurIPS 2023)
Périphériques technologiques
IA
QTNet : Nouvelle solution de fusion temporelle pour nuages de points, images et détecteurs multimodaux (NeurIPS 2023)
QTNet : Nouvelle solution de fusion temporelle pour nuages de points, images et détecteurs multimodaux (NeurIPS 2023)

Écrit auparavant et compréhension personnelle
La fusion de séries chronologiques est un moyen efficace d'améliorer la capacité de perception de la détection de cibles 3D de conduite autonome, mais la méthode actuelle présente des problèmes tels que le coût et les frais généraux lorsqu'elle est appliquée dans des scénarios de conduite autonome réels. Le dernier article de recherche « Fusion de synchronisation de mouvement explicite basée sur des requêtes pour la détection de cibles 3D » propose une nouvelle méthode de fusion de synchronisation dans NeurIPS 2023, qui prend des requêtes clairsemées comme objet de fusion de synchronisation et utilise des informations de mouvement explicites pour générer des matrices d'attention de synchronisation pour s'adapter à les caractéristiques des nuages de points à grande échelle. Cette méthode a été proposée par des chercheurs de l'Université des sciences et technologies de Huazhong et de Baidu, et s'appelle QTNet : une méthode de fusion temporelle pour la détection de cibles 3D basée sur une requête et un mouvement explicite. Des expériences ont prouvé que QTNet peut apporter des améliorations constantes des performances aux nuages de points, aux images et aux détecteurs multimodaux sans frais généraux

- Lien papier : https://openreview.net/pdf?id =gySmwdmVDF
- Code lien : https://github.com/AlmoonYsl/QTNet
Contexte du problème
Grâce à la continuité temporelle du monde réel, les informations dans la dimension temporelle peuvent rendre les informations de perception plus complètes, puis améliorer la précision et la robustesse de la détection de cible. Par exemple, les informations de synchronisation peuvent aider à résoudre le problème d'occlusion dans la détection de cible, fournir des informations sur l'état de mouvement et la vitesse de la cible, et fournir des informations sur la persistance et la cohérence de la cible. Par conséquent, la manière d’utiliser efficacement les informations temporelles est une question importante dans la perception de la conduite autonome. Les méthodes de fusion temporelle existantes sont principalement divisées en deux catégories. Un type est la fusion de séries chronologiques basée sur des fonctionnalités BEV denses (applicable à la fusion de séries chronologiques de nuages de points/images), et l'autre type est la fusion de séries chronologiques basée sur des fonctionnalités de proposition 3D (principalement destinée aux méthodes de fusion de séries chronologiques de nuages de points). Pour la fusion temporelle basée sur les caractéristiques BEV, puisque plus de 90 % des points sur BEV sont en arrière-plan, ce type de méthode ne prête pas plus d'attention aux objets de premier plan, ce qui entraîne une surcharge de calcul inutile et des performances sous-optimales. Pour l'algorithme de fusion de séries chronologiques basé sur la proposition 3D, il génère des fonctionnalités de proposition 3D grâce à un pooling RoI 3D fastidieux. Surtout lorsqu'il y a de nombreuses cibles et un grand nombre de nuages de points, la surcharge causée par le pooling RoI 3D est en fait très élevée. Il est souvent difficile de l’accepter dans les candidatures. De plus, les fonctionnalités de proposition 3D dépendent fortement de la qualité de la proposition, qui est souvent limitée dans les scènes complexes. Par conséquent, il est difficile pour les méthodes actuelles d’introduire efficacement une fusion temporelle afin d’améliorer les performances de détection de cibles 3D avec un surcoût extrêmement faible.
Comment réaliser une fusion temporelle efficace ?
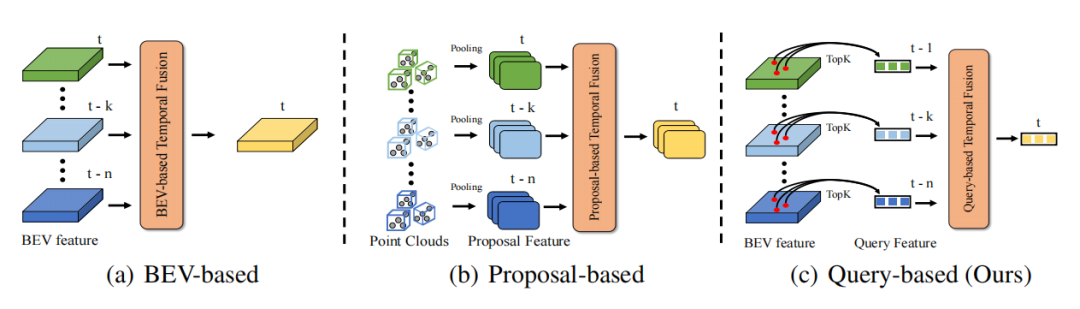
DETR est un très excellent paradigme de détection de cible. Sa conception de requêtes et ses idées de prédiction d'ensemble réalisent efficacement un paradigme de détection élégant sans aucun post-traitement. Dans DETR, chaque requête représente un objet et la requête est très clairsemée par rapport aux fonctionnalités denses (généralement, le nombre de requêtes est défini sur un nombre fixe relativement petit). Si Quey est utilisé comme objet de fusion temporelle, le problème de la surcharge de calcul tombera naturellement à un niveau inférieur. Par conséquent, le paradigme Query de DETR est un paradigme naturellement adapté à la fusion temporelle. La fusion temporelle nécessite la construction d'associations d'objets entre plusieurs images pour réaliser la synthèse d'informations de contexte temporel. Le principal problème est donc de savoir comment créer un pipeline de fusion de timing basé sur une requête et établir une corrélation entre la requête entre les deux trames.
- En raison du mouvement du véhicule autonome dans les scènes réelles, les nuages de points/images des deux images sont souvent mal alignés dans les systèmes de coordonnées, et dans les applications pratiques, il est impossible de réavancer toutes les images historiques dans l'image actuelle. via le réseau pour l'extraction des caractéristiques des nuages de points/images alignés. Par conséquent, cet article utilise Memory Bank pour stocker uniquement les fonctionnalités de requête obtenues à partir des images historiques et leurs résultats de détection correspondants afin d'éviter des calculs répétés.
- Étant donné que les nuages de points et les images sont très différents dans la description des caractéristiques cibles, il n'est pas possible de construire une méthode de fusion temporelle unifiée au niveau des caractéristiques. Cependant, dans un espace tridimensionnel, le nuage de points et la modalité d'image peuvent décrire la corrélation entre des images adjacentes via la relation géométrique entre les informations de position et de mouvement de la cible. Par conséquent, cet article utilise la position géométrique de l’objet et les informations de mouvement correspondantes pour guider la matrice d’attention de l’objet entre deux images.
Introduction à la méthode
L'idée principale de QTNet est d'utiliser la banque de mémoire pour stocker les fonctionnalités de requête obtenues dans des images historiques et leurs résultats de détection correspondants afin d'éviter la surcharge liée aux calculs répétés des images historiques. Entre deux images de Query, utilisez la matrice d'attention guidée par le mouvement pour la modélisation des relations
cadre global
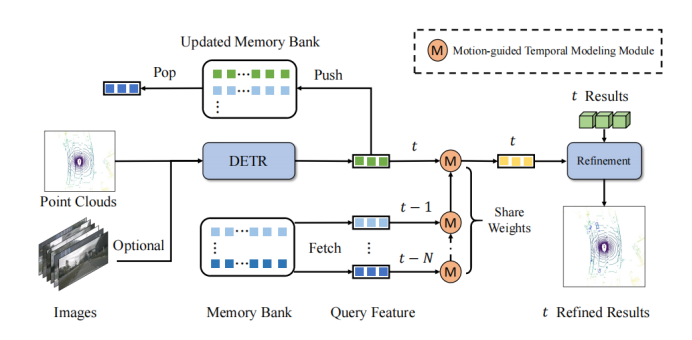
Comme le montre le schéma-cadre, QTNet comprend un détecteur d'objets 3D avec une structure DETR 3D (disponible pour LiDAR, caméra et multimodal), une banque de mémoire et un module de modélisation temporelle guidé par le mouvement (MTM) pour la fusion temporelle. QTNet obtient les fonctionnalités de requête et les résultats de détection de la trame correspondante via le détecteur de cible 3D de la structure DETR, et envoie les fonctionnalités de requête obtenues et les résultats de détection à la banque de mémoire dans une file d'attente premier entré, premier sorti (FIFO). Le nombre de banques de mémoire est défini sur le nombre d'images requises pour la fusion temporelle. Pour la fusion temporelle, QTNet lit les données de la banque de mémoire en commençant par le moment le plus éloigné et utilise le module MTM pour fusionner de manière itérative toutes les fonctionnalités de la banque de mémoire, de la trame à la trame pour améliorer les fonctionnalités de requête du courant. frame et affiner le résultat de détection correspondant à la trame actuelle en fonction de la fonctionnalité de requête améliorée.
Plus précisément, QTNet fusionne les fonctionnalités de requête des et frames et dans les frames, et obtient les fonctionnalités de requête améliorées des frames . Ensuite, QTNet fusionne les fonctionnalités de requête des cadres et . De cette façon, il est continuellement intégré au cadre par itération. Notez que le MTM utilisé ici du cadre au cadre partage tous les paramètres.
Module d'attention guidée par le mouvement
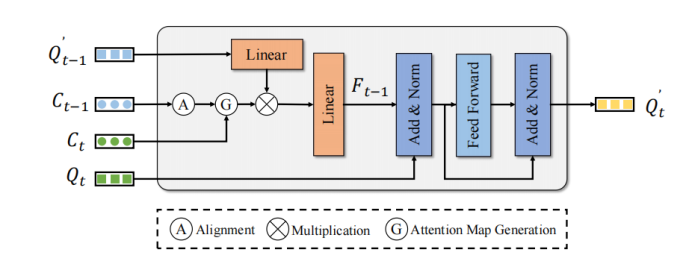
MTM utilise la position du point central de l'objet pour générer explicitement la matrice d'attention de Frame Query et Frame Query. Étant donné la matrice de pose de l'ego et , le point central de l'objet et la vitesse. Tout d'abord, MTM utilise la pose de l'ego et les informations de vitesse de la prédiction de l'objet pour déplacer l'objet de l'image précédente vers l'image suivante et aligner les systèmes de coordonnées des deux images :
Ensuite, il passe le point central de l'objet frame et le point central corrigé du cadre Construisez une matrice de coûts euclidienne. De plus, afin d'éviter d'éventuels faux appariements, cet article utilise la catégorie et le seuil de distance pour construire le masque d'attention :
La conversion de la matrice de coûts en matrice d'attention est le but ultime
La matrice d'attention est utilisée. Les fonctionnalités de requête améliorées du cadre sont utilisées pour agréger les fonctionnalités de synchronisation afin d'améliorer les fonctionnalités de requête du cadre :
Les fonctionnalités de requête améliorées finales du cadre sont raffiné via un simple FFN aux résultats de détection correspondants, pour obtenir l'effet d'améliorer les performances de détection.
Structure de fusion temporelle découplée
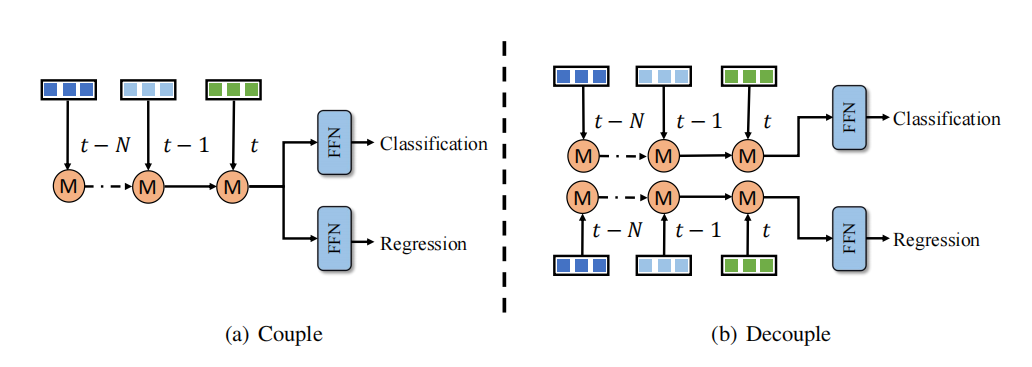
Il existe un problème de déséquilibre dans l'apprentissage de la classification et de la régression de la fusion temporelle. Une solution consiste à concevoir des branches de fusion temporelle pour la classification et la régression respectivement. Cependant, cette approche de découplage ajoute des coûts de calcul et une latence supplémentaires, ce qui est inacceptable pour la plupart des méthodes. En revanche, QTNet utilise une conception de fusion temporelle efficace, son coût et son délai de calcul sont négligeables et il fonctionne mieux que l'ensemble du réseau de détection 3D. Par conséquent, cet article adopte la méthode de découplage des branches de classification et de régression dans la fusion de séries chronologiques pour obtenir de meilleures performances de détection à un coût négligeable, comme le montre la figure
Résultats expérimentaux
QTNet au point Atteindre des points de croissance cohérents sur le cloud/ image/multi-modalité
Après vérification sur l'ensemble de données nuScenes, il a été constaté que QTNet a atteint 68,4 mAP et 72,2 NDS sans utiliser d'informations futures, de TTA et d'intégration de modèle. Comparé à MGTANet qui utilise des informations futures, QTNet fonctionne mieux que MGTANet dans le cas de la fusion temporelle à 3 images, améliorant respectivement 3,0 mAP et 1,0 NDS
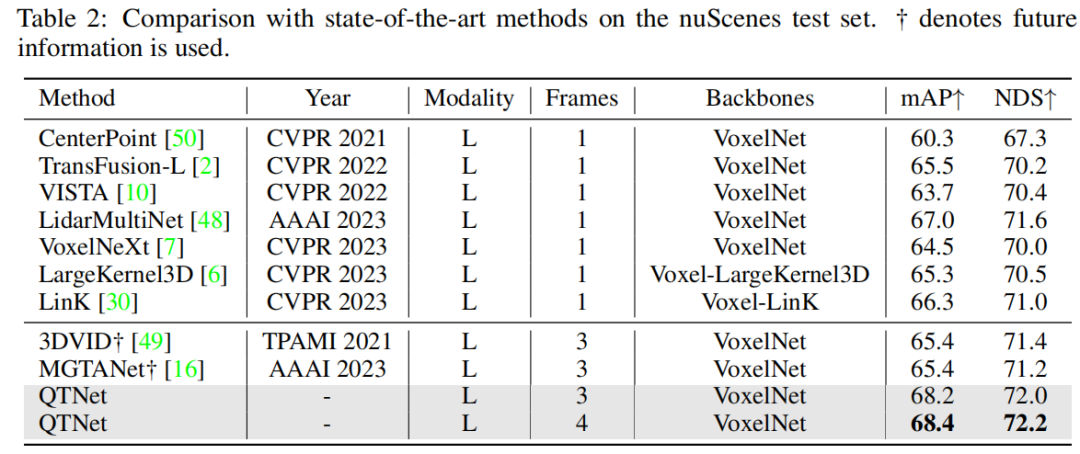
De plus, cet article étudie également la méthode multimodale et basée sur la vue en anneau a été vérifiée et les résultats expérimentaux sur l'ensemble de vérification nuScenes ont prouvé l'efficacité de QTNet dans différentes modalités.
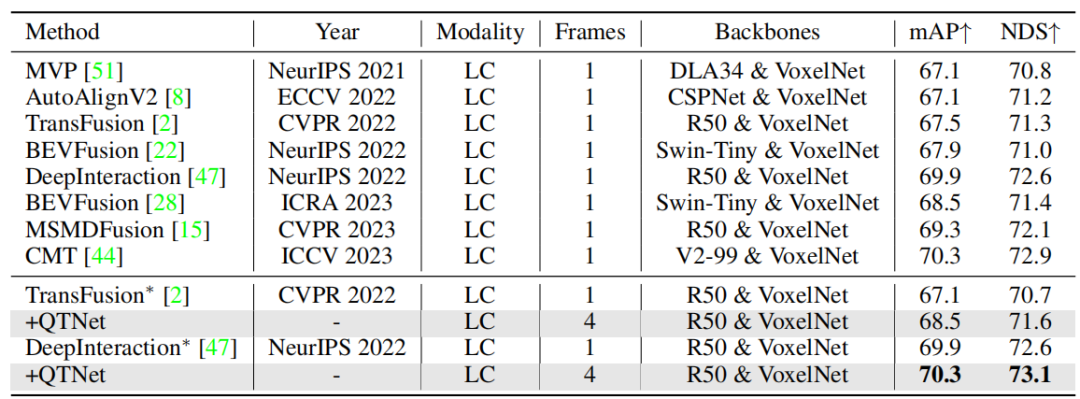

Pour les applications pratiques, les coûts liés à la fusion temporelle sont très importants. Cet article effectue des analyses et des expériences sur QTNet en termes de montant de calcul, de délai et de montant de paramètres. Les résultats montrent que par rapport à l'ensemble du réseau, la surcharge de calcul, les retards et les quantités de paramètres de QTNet causés par différentes lignes de base sont négligeables, en particulier la quantité de calcul n'utilise que 0,1 G FLOP (ligne de base LiDAR)
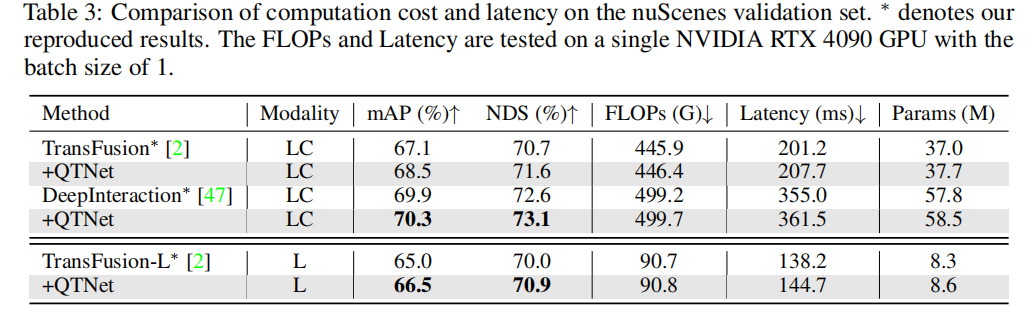
Comparaison de différentes fusions temporelles paradigmes
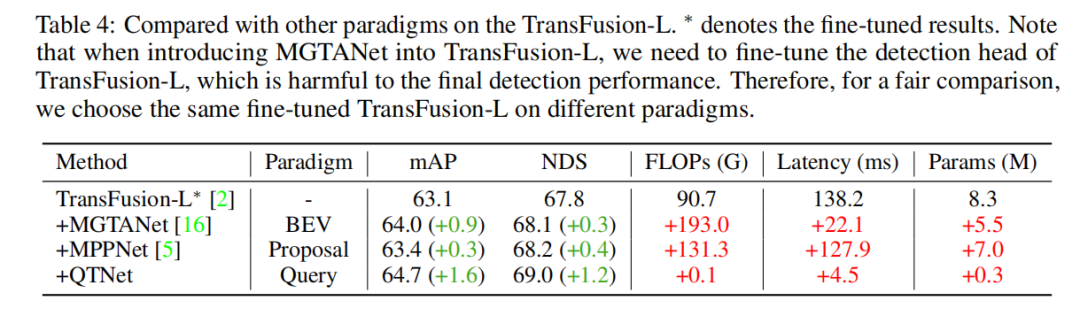
Afin de vérifier la supériorité du paradigme de fusion temporelle basée sur des requêtes, nous avons sélectionné différentes méthodes représentatives de fusion temporelle de pointe à des fins de comparaison. Grâce à des résultats expérimentaux, il a été constaté que l’algorithme de fusion temporelle basé sur le paradigme Query est plus efficace que ceux basés sur le paradigme BEV et Proposal. En utilisant seulement 0,1 G FLOP et 4,5 ms de surcharge, QTNet a montré de meilleures performances, tandis que la quantité globale de paramètres n'était que de 0,3 M
Expérience d'ablation
Cette étude était basée sur l'expérience d'ablation de base LiDAR de l'ensemble de validation nuScenes, via Fusion temporelle à 3 images. Les résultats expérimentaux montrent que la simple utilisation de Cross Attention pour modéliser les relations temporelles n’a aucun effet évident. Cependant, lors de l’utilisation de MTM, les performances de détection sont considérablement améliorées, ce qui illustre l’importance du guidage explicite du mouvement dans les nuages de points à grande échelle. De plus, grâce à des expériences d’ablation, il a également été constaté que la conception globale de QTNet est très légère et efficace. Lors de l'utilisation de 4 images de données pour la fusion temporelle, la quantité de calcul de QTNet n'est que de 0,24 G FLOP et le délai n'est que de 6,5 millisecondes
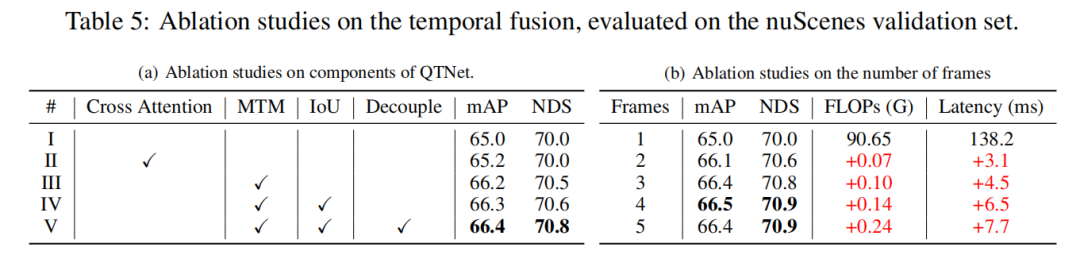
Visualisation de MTM
Afin d'explorer les raisons pour lesquelles MTM est meilleur que Cross Attention, cet article combine deux La matrice d'attention des objets entre les images est visualisée, où le même ID représente le même objet entre deux images. On peut constater que la matrice d'attention (b) générée par MTM est plus discriminante que la matrice d'attention (a) générée par Cross Attention, notamment la matrice d'attention entre petits objets. Cela montre que la matrice d'attention guidée par un mouvement explicite permet au modèle d'établir plus facilement l'association d'objets entre deux images grâce à la modélisation physique. Cet article n'explore que brièvement la question de l'établissement physique de corrélations temporelles dans la fusion temporelle. Il vaut toujours la peine d'explorer comment mieux construire des corrélations temporelles.
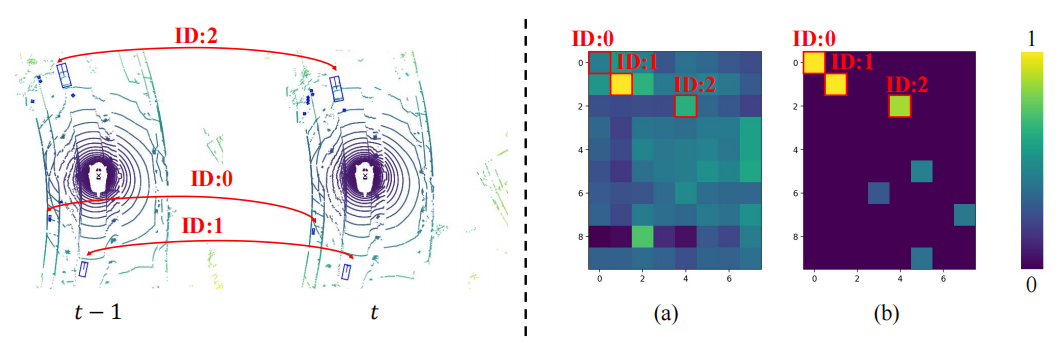
Visualisation des résultats de détection
Cet article utilise des séquences de scènes comme objet pour effectuer une analyse visuelle des résultats de détection. On peut constater que le petit objet dans le coin inférieur gauche s'éloigne rapidement du véhicule à partir du cadre , ce qui fait que la ligne de base manque la détection de l'objet dans le cadre . Cependant, QTNet peut toujours détecter le. objet dans le cadre , ce qui prouve que QTNet est capable de chronométrer l'efficacité de la fusion.
Résumé de cet article
Cet article propose une méthode de fusion temporelle basée sur des requêtes QTNet plus efficace pour la tâche actuelle de détection de cibles 3D. Son noyau principal comporte deux points : l'un consiste à utiliser une requête clairsemée comme objet de fusion temporelle et à stocker des informations historiques via une banque de mémoire pour éviter les calculs répétés ; l'autre consiste à utiliser une modélisation de mouvement explicite pour guider la génération de la matrice d'attention entre les requêtes temporelles ; , pour réaliser une modélisation des relations temporelles. Grâce à ces deux idées clés, QTNet peut mettre en œuvre efficacement une fusion temporelle qui peut être appliquée au LiDAR, à la caméra et à la multimodalité, et améliorer systématiquement les performances de détection de cibles 3D avec un surcoût négligeable.

Le contenu qui doit être réécrit est : Lien original : https://mp.weixin.qq.com/s/s9tkF_rAP2yUEkn6tp9eUQ
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Solution au i7-7700 impossible de passer à Windows 11
Dec 26, 2023 pm 06:52 PM
Solution au i7-7700 impossible de passer à Windows 11
Dec 26, 2023 pm 06:52 PM
Les performances du i77700 sont tout à fait suffisantes pour exécuter Win11, mais les utilisateurs constatent que leur i77700 ne peut pas être mis à niveau vers Win11. Cela est principalement dû aux restrictions imposées par Microsoft, ils peuvent donc l'installer tant qu'ils ignorent cette restriction. Le i77700 ne peut pas être mis à niveau vers win11 : 1. Parce que Microsoft limite la version du processeur. 2. Seules les versions Intel de huitième génération et supérieures peuvent directement passer à Win11. 3. En tant que 7ème génération, i77700 ne peut pas répondre aux besoins de mise à niveau de Win11. 4. Cependant, le i77700 est tout à fait capable d'utiliser Win11 en douceur en termes de performances. 5. Vous pouvez donc utiliser le système d'installation directe win11 de ce site. 6. Une fois le téléchargement terminé, cliquez avec le bouton droit sur le fichier et « chargez-le ». 7. Double-cliquez pour exécuter l'opération "Un clic
 En savoir plus sur les emojis 3D Fluent dans Microsoft Teams
Apr 24, 2023 pm 10:28 PM
En savoir plus sur les emojis 3D Fluent dans Microsoft Teams
Apr 24, 2023 pm 10:28 PM
N'oubliez pas, surtout si vous êtes un utilisateur de Teams, que Microsoft a ajouté un nouveau lot d'émojis 3DFluent à son application de visioconférence axée sur le travail. Après que Microsoft a annoncé des emojis 3D pour Teams et Windows l'année dernière, le processus a en fait permis de mettre à jour plus de 1 800 emojis existants pour la plate-forme. Cette grande idée et le lancement de la mise à jour des emoji 3DFluent pour les équipes ont été promus pour la première fois via un article de blog officiel. La dernière mise à jour de Teams apporte FluentEmojis à l'application. Microsoft affirme que les 1 800 emojis mis à jour seront disponibles chaque jour.
 Détection de chute, basée sur la reconnaissance de l'action humaine au point squelettique, une partie du code est complétée avec Chatgpt
Apr 12, 2023 am 08:19 AM
Détection de chute, basée sur la reconnaissance de l'action humaine au point squelettique, une partie du code est complétée avec Chatgpt
Apr 12, 2023 am 08:19 AM
Bonjour à tous. Aujourd'hui j'aimerais partager avec vous un projet de détection de chute, pour être précis, il s'agit de reconnaissance de mouvements humains basée sur des points squelettiques. Il est grossièrement divisé en trois étapes : la reconnaissance du corps humain, le code source du projet de classification des actions des points du squelette humain a été emballé, voir la fin de l'article pour savoir comment l'obtenir. 0. chatgpt Tout d'abord, nous devons obtenir le flux vidéo surveillé. Ce code est relativement fixe. Nous pouvons directement laisser chatgpt compléter le code écrit par chatgpt. Il n'y a aucun problème et peut être utilisé directement. Mais lorsqu'il s'agit de tâches commerciales ultérieures, comme l'utilisation de Mediapipe pour identifier les points du squelette humain, le code fourni par chatgpt est incorrect. Je pense que chatgpt peut être utilisé comme une boîte à outils indépendante de la logique métier. Vous pouvez essayer de le confier à c.
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Paint 3D sous Windows 11 : guide de téléchargement, d'installation et d'utilisation
Apr 26, 2023 am 11:28 AM
Paint 3D sous Windows 11 : guide de téléchargement, d'installation et d'utilisation
Apr 26, 2023 am 11:28 AM
Lorsque les rumeurs ont commencé à se répandre selon lesquelles le nouveau Windows 11 était en développement, chaque utilisateur de Microsoft était curieux de savoir à quoi ressemblerait le nouveau système d'exploitation et ce qu'il apporterait. Après de nombreuses spéculations, Windows 11 est là. Le système d'exploitation est livré avec une nouvelle conception et des modifications fonctionnelles. En plus de quelques ajouts, il s’accompagne de fonctionnalités obsolètes et supprimées. L'une des fonctionnalités qui n'existe pas dans Windows 11 est Paint3D. Bien qu'il propose toujours Paint classique, idéal pour les dessinateurs, les griffonneurs et les griffonneurs, il abandonne Paint3D, qui offre des fonctionnalités supplémentaires idéales pour les créateurs 3D. Si vous recherchez des fonctionnalités supplémentaires, nous recommandons Autodesk Maya comme le meilleur logiciel de conception 3D. comme
 Le dernier chef-d'œuvre du MIT : utiliser GPT-3.5 pour résoudre le problème de la détection des anomalies des séries chronologiques
Jun 08, 2024 pm 06:09 PM
Le dernier chef-d'œuvre du MIT : utiliser GPT-3.5 pour résoudre le problème de la détection des anomalies des séries chronologiques
Jun 08, 2024 pm 06:09 PM
Aujourd'hui, j'aimerais vous présenter un article publié par le MIT la semaine dernière, utilisant GPT-3.5-turbo pour résoudre le problème de la détection des anomalies des séries chronologiques et vérifiant dans un premier temps l'efficacité du LLM dans la détection des anomalies des séries chronologiques. Il n'y a pas de réglage fin dans l'ensemble du processus et GPT-3.5-turbo est utilisé directement pour la détection des anomalies. Le cœur de cet article est de savoir comment convertir des séries temporelles en entrées pouvant être reconnues par GPT-3.5-turbo et comment concevoir. des invites ou des pipelines pour laisser LLM résoudre la tâche de détection des anomalies. Permettez-moi de vous présenter une introduction détaillée à ce travail. Titre de l'article image : Largelangagemodelscanbezero-shotanomalydete
