
 Périphériques technologiques
IA
AAAI2024 : Far3D - Idée innovante pour atteindre directement la détection visuelle de cibles 3D à 150 m
Périphériques technologiques
IA
AAAI2024 : Far3D - Idée innovante pour atteindre directement la détection visuelle de cibles 3D à 150 m
AAAI2024 : Far3D - Idée innovante pour atteindre directement la détection visuelle de cibles 3D à 150 m

J'ai récemment lu une dernière recherche sur la perception visuelle pure de l'environnement sur Arxiv. Cette recherche est basée sur la série de méthodes PETR et se concentre sur la résolution du problème de perception visuelle pure de la détection de cibles à longue distance, étendant la plage de perception à 150 mètres. Les méthodes et les résultats de cet article ont une grande valeur de référence pour nous, j'ai donc essayé de l'interpréter
Titre original : Far3D : élargir l'horizon pour la détection d'objets 3D en vue surround
Lien de l'article : https://arxiv.org/abs /2308.09616
Affiliation de l'auteur : Institut de technologie de Pékin et technologie Megvii

Contexte de la tâche
La détection d'objets tridimensionnels joue un rôle important dans la compréhension de la scène tridimensionnelle de la conduite autonome, et son objectif est de précisément localiser et classer les objets autour du véhicule. Les méthodes pures de perception visuelle de l’environnement présentent les avantages d’un faible coût et d’une large applicabilité, et ont fait des progrès significatifs. Cependant, la plupart d'entre eux se concentrent sur la détection à courte portée (par exemple, la distance de détection des nuScenes est d'environ 50 mètres), et le champ de détection à longue portée est moins exploré. La détection d'objets distants est essentielle pour maintenir une distance de sécurité lors de la conduite réelle, en particulier à grande vitesse ou dans des conditions routières complexes.
Récemment, des progrès significatifs ont été réalisés dans la détection d'objets 3D à partir d'images à vue panoramique, qui peuvent être déployées à faible coût. Cependant, la plupart des études se concentrent principalement sur la détection à courte portée, et il existe moins d’études sur la détection à longue portée. L'extension directe des méthodes existantes pour couvrir de longues distances sera confrontée à des défis tels qu'un coût de calcul élevé et une convergence instable. Pour remédier à ces limitations, cet article propose un nouveau framework basé sur des requêtes clairsemées appelé Far3D.
Idée de thèse
Selon la représentation intermédiaire, les méthodes de détection par recherche existantes peuvent être grossièrement divisées en deux catégories : les méthodes basées sur la représentation BEV et les méthodes basées sur la représentation de requêtes clairsemées. La méthode basée sur la représentation BEV nécessite une très grande quantité de calculs en raison de la nécessité d'un calcul intensif des caractéristiques BEV, ce qui la rend difficile à étendre aux scénarios longue distance. La méthode basée sur une représentation de requête clairsemée apprendra la requête 3D globale à partir des données d'entraînement, la quantité de calcul est relativement faible et elle a une forte évolutivité. Cependant, elle présente également quelques faiblesses. Bien qu'elle puisse éviter la croissance carrée du nombre de requêtes, la requête fixe globale n'est pas facile à adapter aux scènes dynamiques, et les cibles sont souvent manquées dans la détection longue distance. ensemble de données, comparaison des performances 3D entre la détection et la détection 2D.
Dans la détection à longue portée, les méthodes basées sur une représentation clairsemée des requêtes présentent deux défis principaux. 
Le premier est la mauvaise performance de rappel. En raison de la distribution clairsemée des requêtes dans l’espace 3D, seul un petit nombre de requêtes positives correspondantes peuvent être générées sur de longues distances. Comme le montre la figure ci-dessus, le taux de rappel de la détection 3D est plus faible, tandis que le taux de rappel de la détection 2D existante est beaucoup plus élevé, laissant un net écart de performances entre les deux. Par conséquent, l’utilisation d’objets 2D de haute qualité pour améliorer les requêtes 3D est une méthode prometteuse, bénéfique pour obtenir un positionnement précis et une couverture complète des objets.
Deuxièmement, l'introduction directe des résultats de détection 2D pour aider à la détection 3D sera confrontée au problème de la propagation des erreurs. Comme le montre la figure ci-dessous, les deux sources principales sont 1) l'erreur de positionnement de l'objet due à une prédiction de profondeur inexacte 2) l'erreur de position 3D dans la transformation du tronc de tronc augmente avec la distance ; Ces requêtes bruyantes affecteront la stabilité de la formation et nécessiteront des méthodes de débruitage efficaces pour être optimisées. De plus, pendant la formation, le modèle montrera une tendance à surajuster aux objets proches densément peuplés tout en ignorant les objets distants peu distribués.
- Afin de traiter les problèmes mentionnés ci-dessus, cet article adopte le plan de conception suivant :
- En plus de la requête globale 3D apprise à partir de l'ensemble de données, une requête adaptative 3D générée à partir des résultats de détection 2D est également introduite. Plus précisément, le détecteur 2D et le réseau de prédiction de profondeur sont d'abord utilisés pour obtenir la boîte 2D et la profondeur correspondante, puis projetés dans l'espace 3D par transformation spatiale en tant qu'initialisation de la requête adaptative 3D.
- Afin de s'adapter aux différentes échelles d'objets à différentes distances, l'agrégation prenant en compte la perspective est conçue. Il permet aux requêtes 3D d’interagir avec des entités de différentes échelles, ce qui est avantageux pour capturer des objets à différentes distances. Par exemple, les objets distants nécessitent des fonctionnalités à grande résolution, tandis que les objets proches nécessitent des fonctionnalités différentes. Cette conception permet au modèle d'interagir de manière adaptative avec les fonctionnalités.
- Conception d'une stratégie appelée Débruitage 3D modulé par plage pour atténuer le problème de propagation des erreurs de requête et de convergence lente. Étant donné que les difficultés de régression des requêtes à différentes distances sont différentes, la requête bruyante est ajustée en fonction de la distance et de l'échelle de la boîte réelle. Entrez plusieurs ensembles de requêtes bruyantes proches de GT dans le décodeur pour reconstruire la boîte réelle 3D (pour les échantillons positifs) et éliminer respectivement les échantillons négatifs.
Principales contributions
- Cet article propose un nouveau cadre de détection basé sur des requêtes clairsemées, qui utilise un objet 2D de haute qualité avant de générer une requête adaptative 3D, élargissant ainsi la plage de perception de la détection 3D.
- Cet article conçoit un module d'agrégation prenant en compte la perspective, qui regroupe des caractéristiques visuelles à différentes échelles et perspectives, et une stratégie de débruitage 3D basée sur la distance cible pour résoudre les problèmes de propagation des erreurs de requête et de convergence du framework.
- Les résultats expérimentaux sur l'ensemble de données à longue portée Argoverse 2 montrent que Far3D surpasse les méthodes de recherche précédentes et surpasse plusieurs méthodes basées sur le lidar. Et sa généralité est vérifiée sur le jeu de données nuScenes.
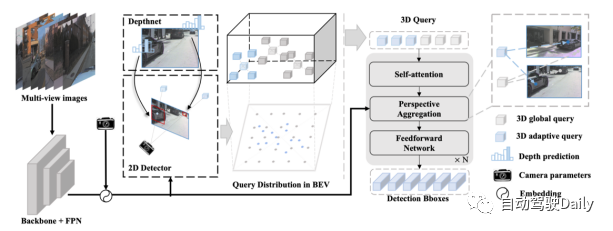
Conception du modèle
Aperçu du processus Far3D :
- Introduisez l'image surround dans le réseau fédérateur et la couche FPN, encodez les caractéristiques de l'image 2D et encodez-les avec les paramètres de la caméra.
- Utilise des détecteurs 2D et des réseaux de prédiction de profondeur pour générer des boîtes d'objets 2D fiables et leurs profondeurs correspondantes, qui sont ensuite projetées dans l'espace 3D grâce à des transformations de caméra.
- La requête adaptative 3D générée est combinée avec la requête globale 3D initiale et régressée de manière itérative par la couche de décodeur pour prédire la boîte d'objet 3D. De plus, le modèle peut implémenter une modélisation de séries chronologiques grâce à la propagation de requêtes à long terme.
Agrégation tenant compte de la perspective :
Afin d'introduire des fonctionnalités multi-échelles au modèle de détection à longue portée, cet article applique une attention déformable spatiale 3D. Il effectue d'abord un échantillonnage décalé à proximité de la position 3D correspondant à la requête, puis agrège les caractéristiques de l'image via une transformation de vue 3D-2D. L’avantage de cette méthode par rapport à l’attention globale dans la série PETR est que la complexité informatique peut être considérablement réduite. Plus précisément, pour le point de référence de chaque requête dans l'espace 3D, le modèle apprend M décalages d'échantillonnage autour de lui et projette ces points de décalage dans différentes fonctionnalités de vue 2D.
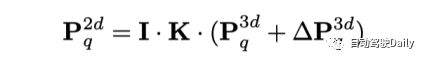
Par la suite, la requête 3D interagit avec les entités échantillonnées obtenues par projection. De cette manière, diverses caractéristiques de différentes perspectives et échelles seront rassemblées dans une requête tridimensionnelle en considérant leur importance relative.
Débruitage 3D modulé par plage :
Les requêtes 3D avec des distances différentes ont des difficultés de régression différentes, ce qui est différent des méthodes de débruitage 2D existantes (telles que DN-DETR, requêtes 2D qui sont généralement traitées de la même manière). La différence de difficulté vient de la densité de correspondance des requêtes et de la propagation des erreurs. D'une part, le degré de correspondance des requêtes correspondant aux objets distants est inférieur à celui des objets proches. D'un autre côté, lors de l'introduction d'a priori 2D dans une requête adaptative 3D, les petites erreurs dans les boîtes d'objets 2D seront amplifiées, sans compter que cet effet augmentera à mesure que la distance de l'objet augmente. Par conséquent, certaines requêtes proches de la case GT peuvent être considérées comme des requêtes positives, tandis que d’autres présentant des écarts évidents doivent être considérées comme des requêtes négatives. Cet article propose une méthode de débruitage 3D qui vise à optimiser ces échantillons positifs et à éliminer directement les échantillons négatifs.
Plus précisément, les auteurs construisent des requêtes bruyantes basées sur GT en ajoutant simultanément des groupes d'échantillons positifs et négatifs. Pour les deux types, un bruit aléatoire est appliqué en fonction de l’emplacement et de la taille de l’objet pour faciliter l’apprentissage du débruitage dans la perception à longue portée. Plus précisément, les échantillons positifs sont des points aléatoires dans la boîte 3D, tandis que les échantillons négatifs imposent un décalage plus important au GT, et la plage de décalage change avec la distance de l'objet. Cette méthode peut simuler des échantillons bruyants de candidats positifs et de faux positifs pendant la formation
Résultats expérimentaux
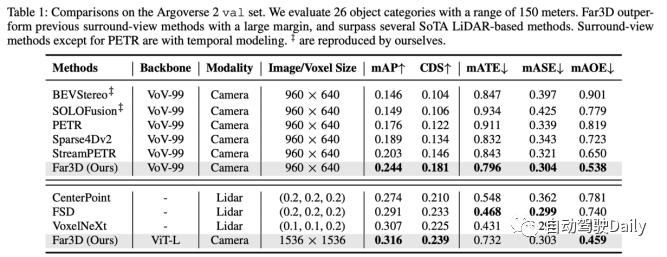
Far3D a atteint les performances les plus élevées sur Argoverse 2 avec une portée de détection de 150 m. Et une fois le modèle mis à l’échelle, il peut atteindre les performances de plusieurs méthodes basées sur Lidar, démontrant ainsi le potentiel des méthodes visuelles pures.
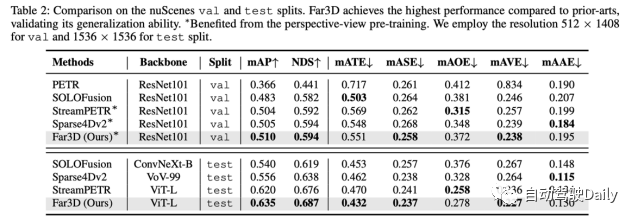
Afin de vérifier les performances de généralisation, l'auteur a également mené des expériences sur l'ensemble de données nuScenes, montrant qu'il atteignait les performances SoTA à la fois sur l'ensemble de validation et sur l'ensemble de test.
Après les expériences d'ablation, nous sommes arrivés à la conclusion suivante : la requête adaptative 3D, l'agrégation tenant compte de la perspective et le débruitage 3D ajusté en fonction de la plage ont chacun un certain gain

Réflexions sur le papier
Q : Quelle est la nouveauté de cet article ?
A : La principale nouveauté est de résoudre le problème de perception des scènes à longue distance. L'extension des méthodes existantes à des scénarios longue distance pose de nombreux problèmes, notamment les coûts de calcul et les difficultés de convergence. Les auteurs de cet article proposent un cadre efficace pour cette tâche. Même si les modules individuels peuvent sembler familiers, ils servent tous à la détection de cibles lointaines et ont des objectifs clairs.
Q : Par rapport à BevFormer v2, quelles sont les différences entre MV2D ?
A : MV2D s'appuie principalement sur l'ancrage 2D pour obtenir les caractéristiques correspondantes pour lier la 3D, mais il n'y a pas d'estimation explicite de la profondeur, donc l'incertitude sera relativement grande pour les objets distants, et il sera alors difficile de converger principalement avec BevFormer v2 ; résout l'écart de domaine entre le squelette 2D et la scène de tâche 3D. Généralement, le squelette pré-entraîné sur la tâche de reconnaissance 2D a une capacité insuffisante à détecter la scène 3D et n'explore pas les problèmes dans les tâches longue distance.
Q : Le timing peut-il être amélioré, comme la propagation des requêtes et la propagation des fonctionnalités ?
R : C'est faisable en théorie, mais le compromis performance-efficacité doit être pris en compte dans les applications pratiques.
Q : Y a-t-il des domaines qui nécessitent des améliorations ?
R : Les problèmes à longue traîne et les indicateurs d’évaluation à distance méritent d’être améliorés. Sur une cible de 26 classes comme Argoverse 2, les modèles ne fonctionnent pas bien sur les classes à longue traîne et réduisent finalement la précision moyenne, ce qui n'a pas encore été exploré. D’un autre côté, l’utilisation de métriques unifiées pour évaluer des objets distants et proches peut ne pas être appropriée, ce qui souligne la nécessité de critères d’évaluation dynamiques pratiques pouvant être adaptés à différents scénarios du monde réel.

Lien original : https://mp.weixin.qq.com/s/xxaaYQsjuWzMI7PnSmuaWg
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



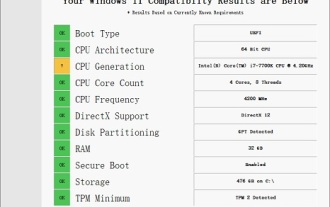 Solution au i7-7700 impossible de passer à Windows 11
Dec 26, 2023 pm 06:52 PM
Solution au i7-7700 impossible de passer à Windows 11
Dec 26, 2023 pm 06:52 PM
Les performances du i77700 sont tout à fait suffisantes pour exécuter Win11, mais les utilisateurs constatent que leur i77700 ne peut pas être mis à niveau vers Win11. Cela est principalement dû aux restrictions imposées par Microsoft, ils peuvent donc l'installer tant qu'ils ignorent cette restriction. Le i77700 ne peut pas être mis à niveau vers win11 : 1. Parce que Microsoft limite la version du processeur. 2. Seules les versions Intel de huitième génération et supérieures peuvent directement passer à Win11. 3. En tant que 7ème génération, i77700 ne peut pas répondre aux besoins de mise à niveau de Win11. 4. Cependant, le i77700 est tout à fait capable d'utiliser Win11 en douceur en termes de performances. 5. Vous pouvez donc utiliser le système d'installation directe win11 de ce site. 6. Une fois le téléchargement terminé, cliquez avec le bouton droit sur le fichier et « chargez-le ». 7. Double-cliquez pour exécuter l'opération "Un clic
 Détection de chute, basée sur la reconnaissance de l'action humaine au point squelettique, une partie du code est complétée avec Chatgpt
Apr 12, 2023 am 08:19 AM
Détection de chute, basée sur la reconnaissance de l'action humaine au point squelettique, une partie du code est complétée avec Chatgpt
Apr 12, 2023 am 08:19 AM
Bonjour à tous. Aujourd'hui j'aimerais partager avec vous un projet de détection de chute, pour être précis, il s'agit de reconnaissance de mouvements humains basée sur des points squelettiques. Il est grossièrement divisé en trois étapes : la reconnaissance du corps humain, le code source du projet de classification des actions des points du squelette humain a été emballé, voir la fin de l'article pour savoir comment l'obtenir. 0. chatgpt Tout d'abord, nous devons obtenir le flux vidéo surveillé. Ce code est relativement fixe. Nous pouvons directement laisser chatgpt compléter le code écrit par chatgpt. Il n'y a aucun problème et peut être utilisé directement. Mais lorsqu'il s'agit de tâches commerciales ultérieures, comme l'utilisation de Mediapipe pour identifier les points du squelette humain, le code fourni par chatgpt est incorrect. Je pense que chatgpt peut être utilisé comme une boîte à outils indépendante de la logique métier. Vous pouvez essayer de le confier à c.
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Le dernier chef-d'œuvre du MIT : utiliser GPT-3.5 pour résoudre le problème de la détection des anomalies des séries chronologiques
Jun 08, 2024 pm 06:09 PM
Le dernier chef-d'œuvre du MIT : utiliser GPT-3.5 pour résoudre le problème de la détection des anomalies des séries chronologiques
Jun 08, 2024 pm 06:09 PM
Aujourd'hui, j'aimerais vous présenter un article publié par le MIT la semaine dernière, utilisant GPT-3.5-turbo pour résoudre le problème de la détection des anomalies des séries chronologiques et vérifiant dans un premier temps l'efficacité du LLM dans la détection des anomalies des séries chronologiques. Il n'y a pas de réglage fin dans l'ensemble du processus et GPT-3.5-turbo est utilisé directement pour la détection des anomalies. Le cœur de cet article est de savoir comment convertir des séries temporelles en entrées pouvant être reconnues par GPT-3.5-turbo et comment concevoir. des invites ou des pipelines pour laisser LLM résoudre la tâche de détection des anomalies. Permettez-moi de vous présenter une introduction détaillée à ce travail. Titre de l'article image : Largelangagemodelscanbezero-shotanomalydete
 La première reconstruction purement visuelle et statique de la conduite autonome
Jun 02, 2024 pm 03:24 PM
La première reconstruction purement visuelle et statique de la conduite autonome
Jun 02, 2024 pm 03:24 PM
Une solution d'annotation purement visuelle utilise principalement la vision ainsi que certaines données du GPS, de l'IMU et des capteurs de vitesse de roue pour l'annotation dynamique. Bien entendu, pour les scénarios de production de masse, il n’est pas nécessaire qu’il s’agisse d’une vision pure. Certains véhicules produits en série seront équipés de capteurs comme le radar à semi-conducteurs (AT128). Si nous créons une boucle fermée de données dans la perspective d'une production de masse et utilisons tous ces capteurs, nous pouvons résoudre efficacement le problème de l'étiquetage des objets dynamiques. Mais notre plan ne prévoit pas de radar à semi-conducteurs. Par conséquent, nous présenterons cette solution d’étiquetage de production de masse la plus courante. Le cœur d’une solution d’annotation purement visuelle réside dans la reconstruction de pose de haute précision. Nous utilisons le schéma de reconstruction de pose de Structure from Motion (SFM) pour garantir la précision de la reconstruction. Mais passe
 Qu'est-ce que le NeRF ? La reconstruction 3D basée sur NeRF est-elle basée sur des voxels ?
Oct 16, 2023 am 11:33 AM
Qu'est-ce que le NeRF ? La reconstruction 3D basée sur NeRF est-elle basée sur des voxels ?
Oct 16, 2023 am 11:33 AM
1 Introduction Les champs de rayonnement neuronal (NeRF) constituent un paradigme relativement nouveau dans le domaine de l'apprentissage profond et de la vision par ordinateur. Cette technologie a été introduite dans l'article ECCV2020 « NeRF : Representing Scenes as Neural Radiation Fields for View Synthesis » (qui a remporté le prix du meilleur article) et est depuis devenue extrêmement populaire, avec près de 800 citations à ce jour [1 ]. Cette approche marque un changement radical dans la manière traditionnelle dont l’apprentissage automatique traite les données 3D. Représentation de la scène du champ de rayonnement neuronal et processus de rendu différenciable : compositer des images en échantillonnant des coordonnées 5D (position et direction de visualisation) le long des rayons de la caméra ; introduire ces positions dans un MLP pour produire des densités de couleur et volumétriques et composer ces valeurs à l'aide de techniques de rendu volumétrique ; ; la fonction de rendu est différentiable, elle peut donc être transmise
 Jetez un œil au passé et au présent de l'Occ et de la conduite autonome ! La première revue résume de manière exhaustive les trois thèmes majeurs de l'amélioration des fonctionnalités/déploiement en production de masse/annotation efficace.
May 08, 2024 am 11:40 AM
Jetez un œil au passé et au présent de l'Occ et de la conduite autonome ! La première revue résume de manière exhaustive les trois thèmes majeurs de l'amélioration des fonctionnalités/déploiement en production de masse/annotation efficace.
May 08, 2024 am 11:40 AM
Écrit ci-dessus et compréhension personnelle de l'auteur Ces dernières années, la conduite autonome a reçu une attention croissante en raison de son potentiel à réduire la charge du conducteur et à améliorer la sécurité de conduite. La prédiction d'occupation tridimensionnelle basée sur la vision est une tâche de perception émergente adaptée à une enquête rentable et complète sur la sécurité de la conduite autonome. Bien que de nombreuses études aient démontré la supériorité des outils de prédiction d’occupation 3D par rapport aux tâches de perception centrée sur les objets, il existe encore des revues dédiées à ce domaine en développement rapide. Cet article présente d'abord le contexte de la prédiction d'occupation 3D basée sur la vision et discute des défis rencontrés dans cette tâche. Ensuite, nous discutons de manière approfondie de l'état actuel et des tendances de développement des méthodes actuelles de prévision d'occupation 3D sous trois aspects : l'amélioration des fonctionnalités, la convivialité du déploiement et l'efficacité de l'étiquetage. enfin
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
