
 Périphériques technologiques
IA
Revue complète de Gemini : De la CMU à GPT 3.5 Turbo, Gemini Pro perd
Périphériques technologiques
IA
Revue complète de Gemini : De la CMU à GPT 3.5 Turbo, Gemini Pro perd
Revue complète de Gemini : De la CMU à GPT 3.5 Turbo, Gemini Pro perd

Combien pèse le Gémeaux de Google ? Comment se compare-t-il au modèle GPT d’OpenAI ? Ce document CMU a des résultats de mesure clairs
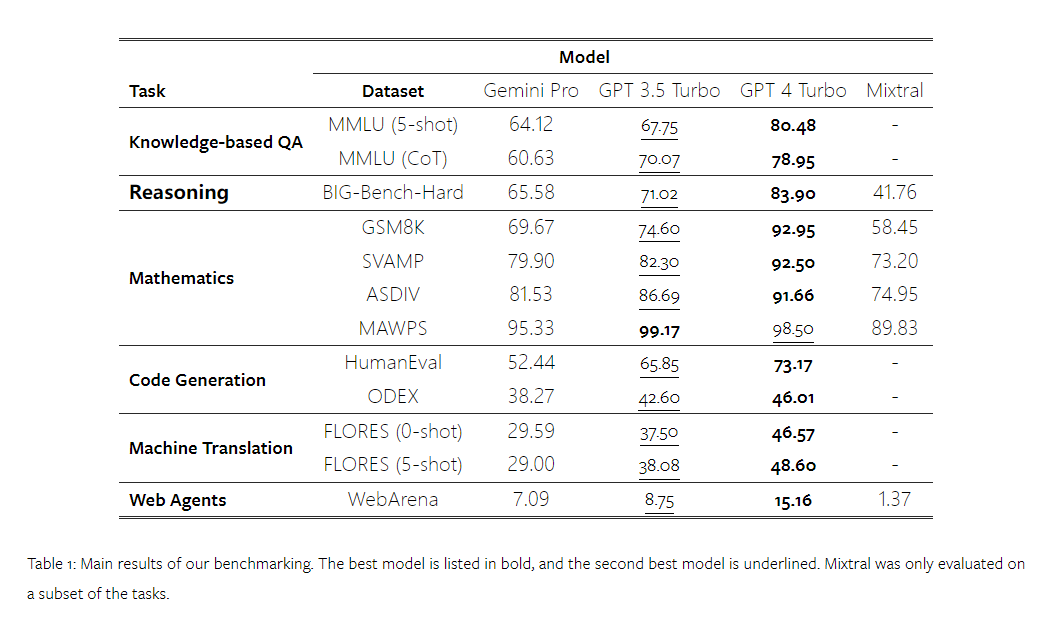

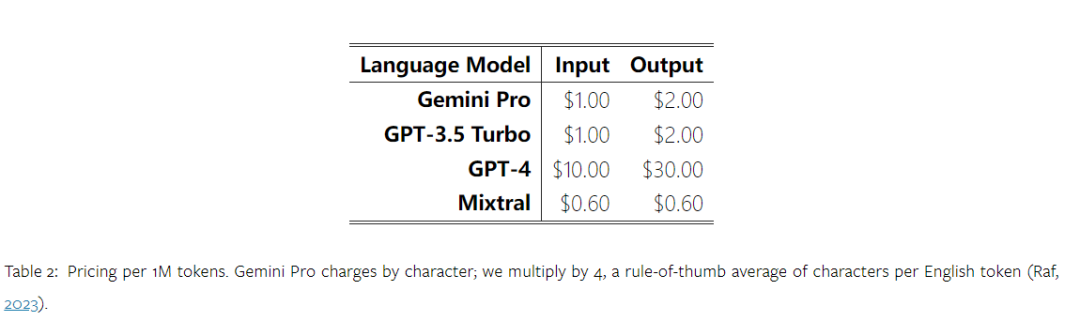
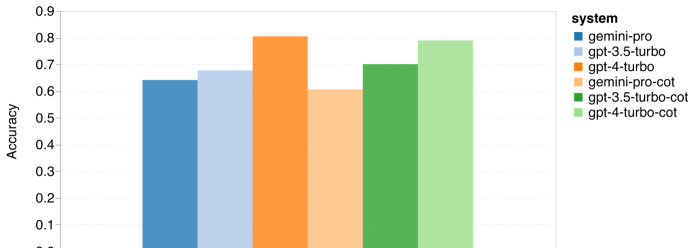
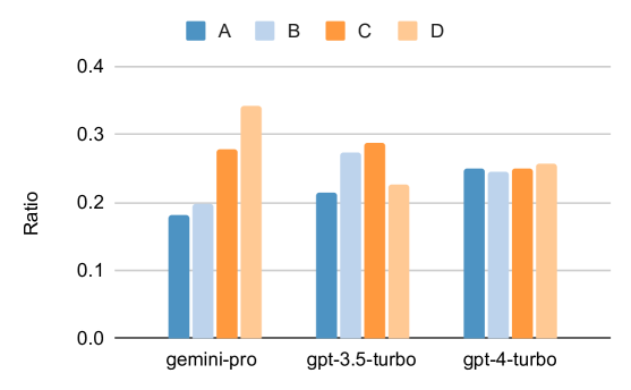
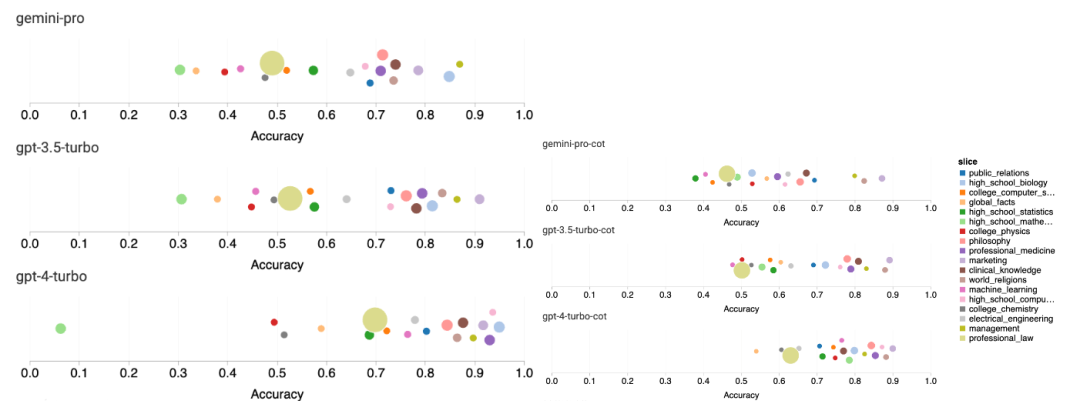
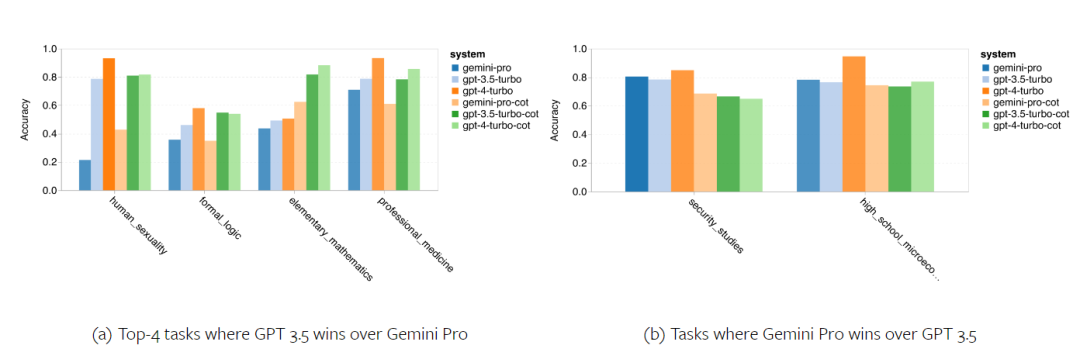
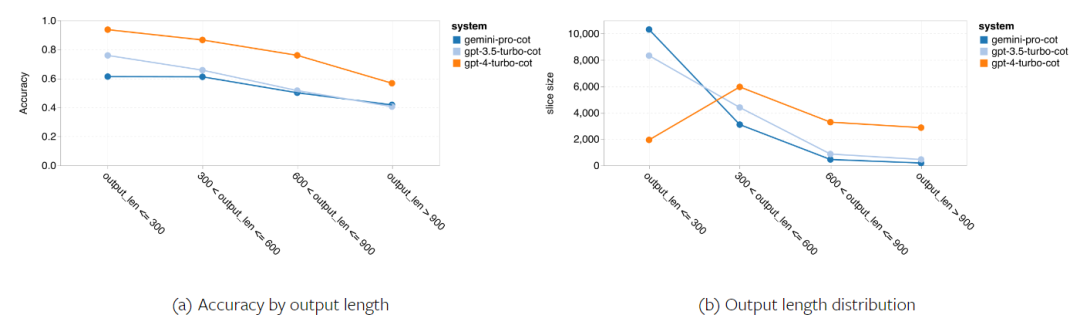
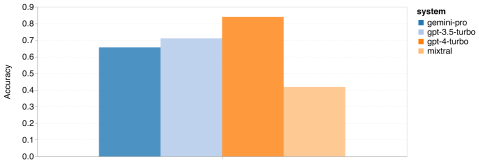
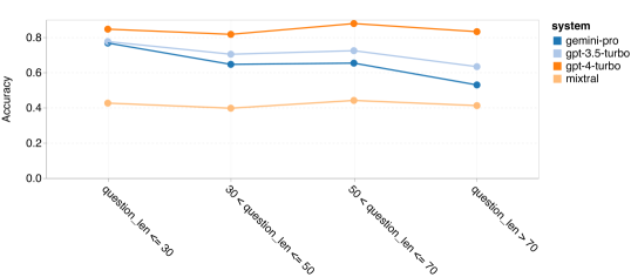
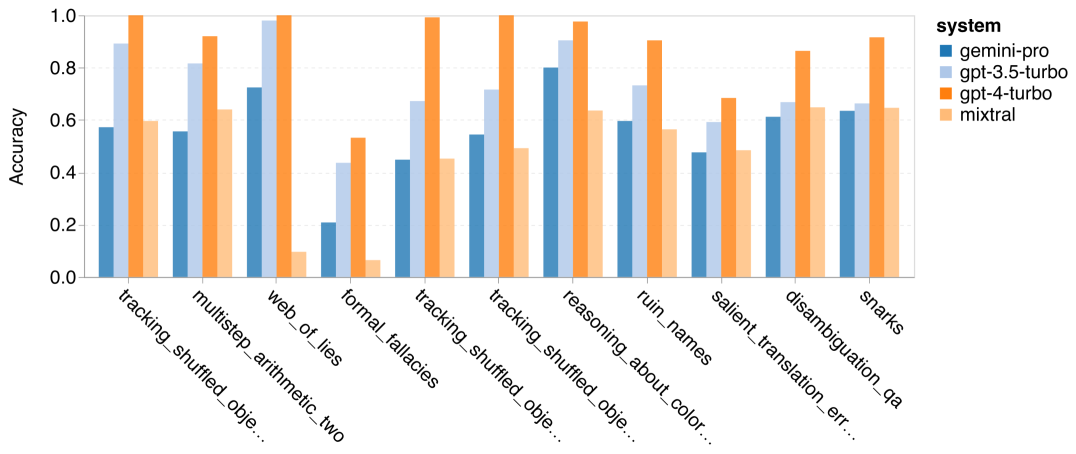
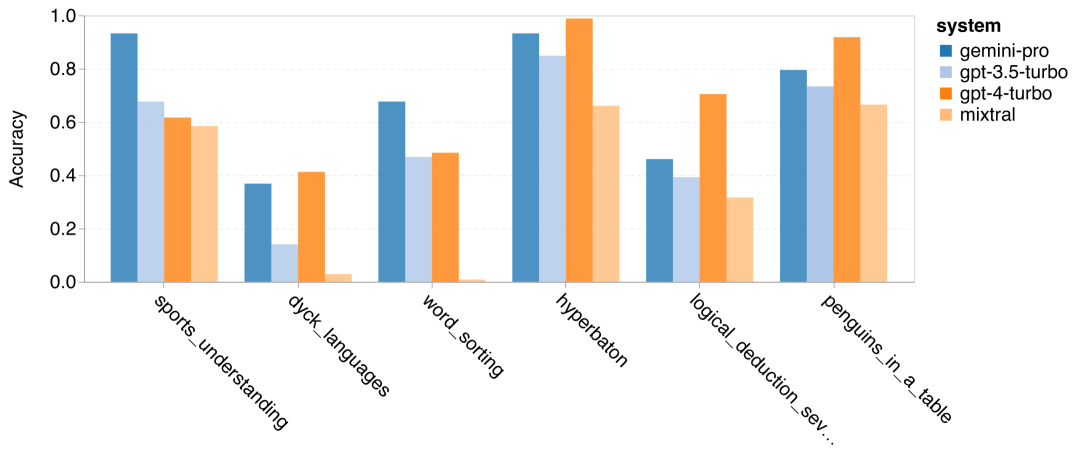
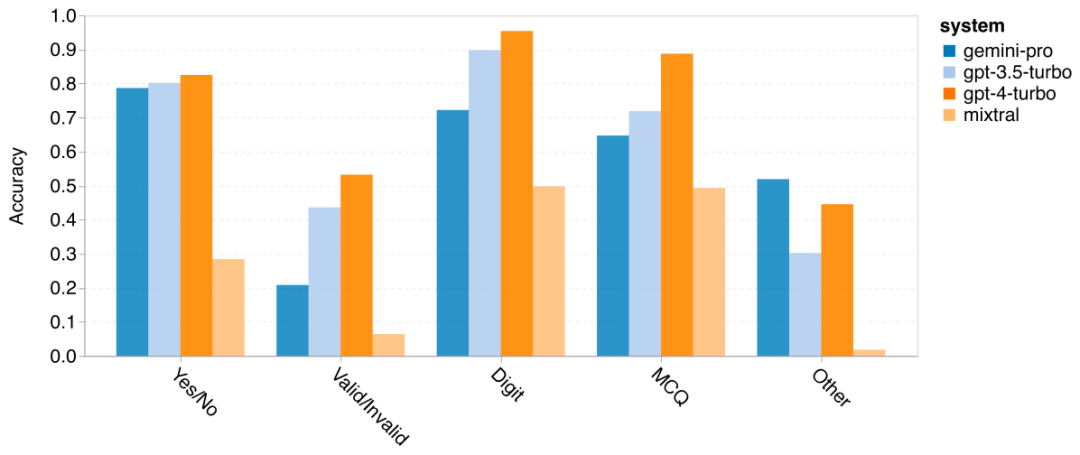
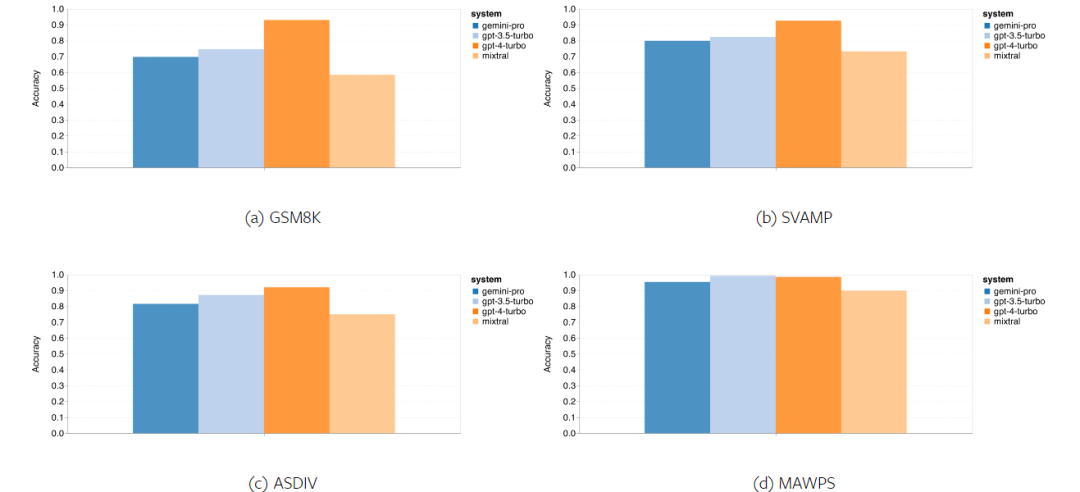
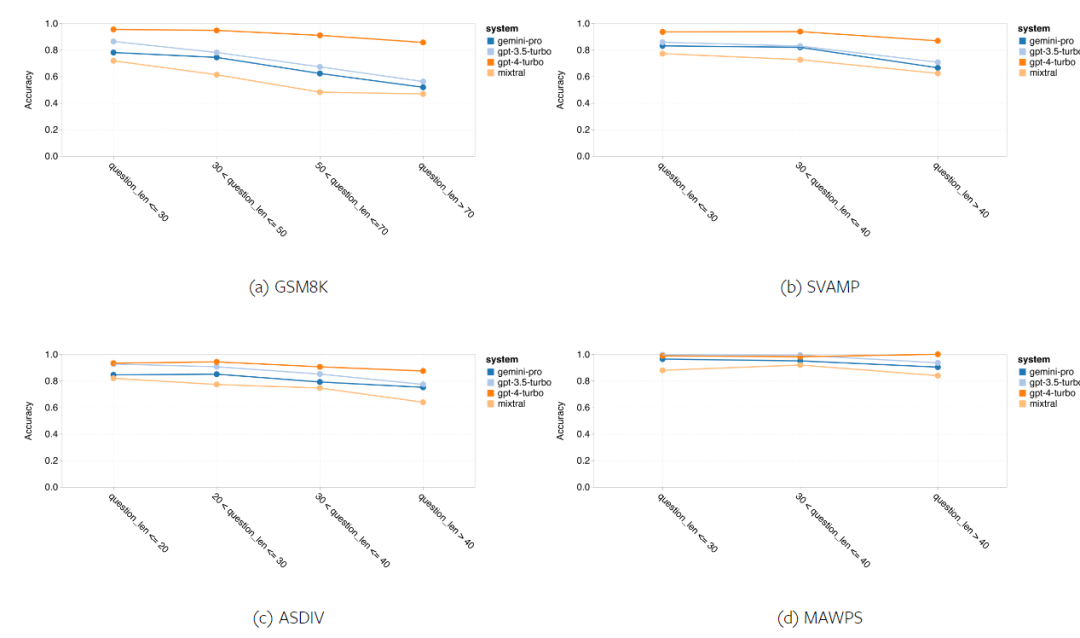
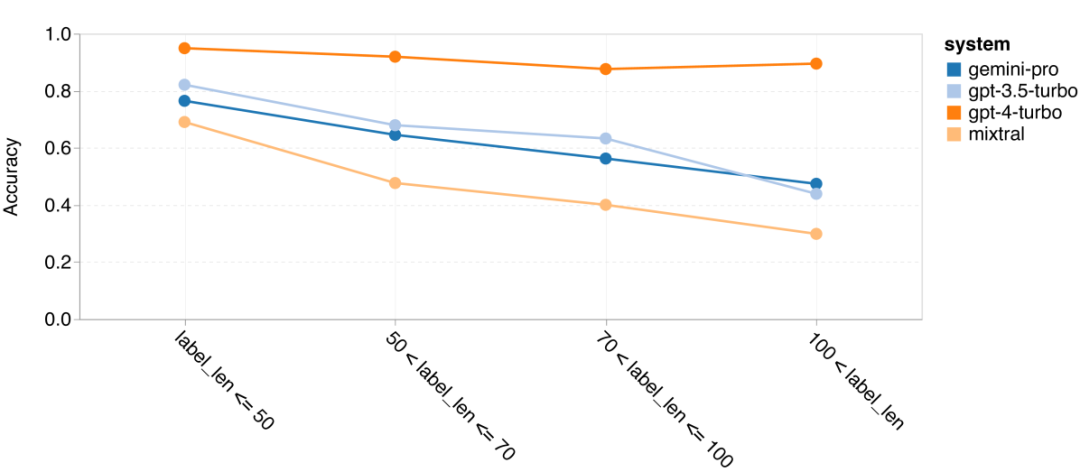
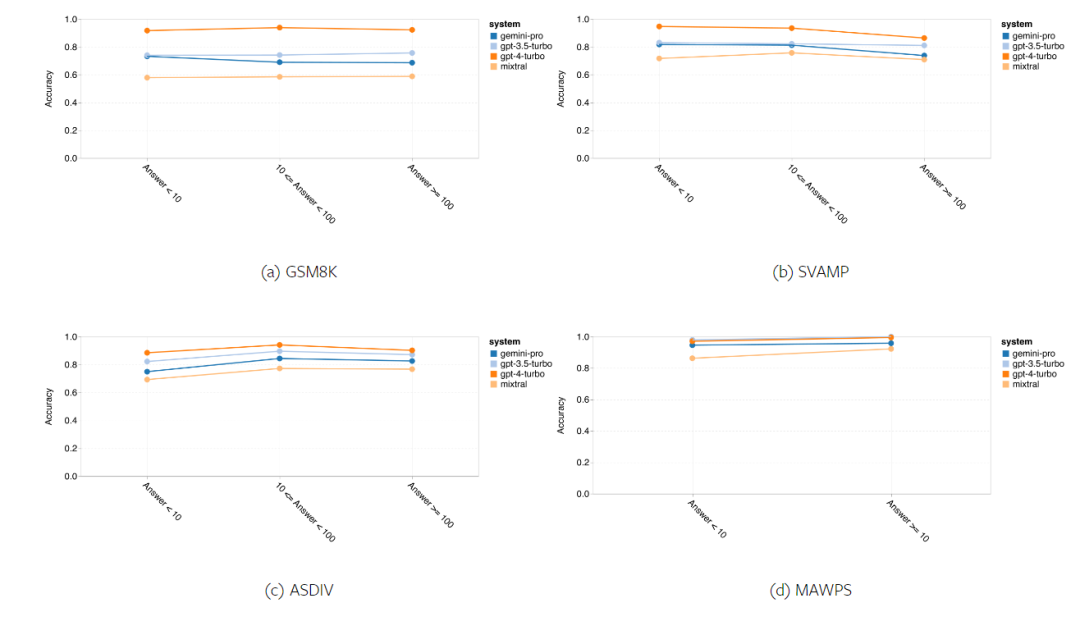
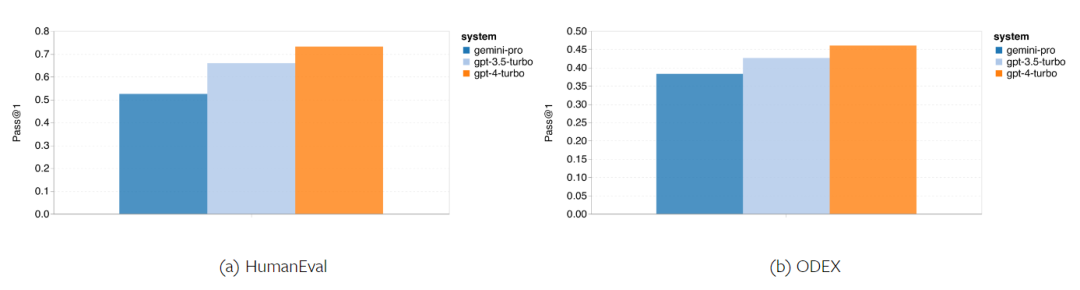
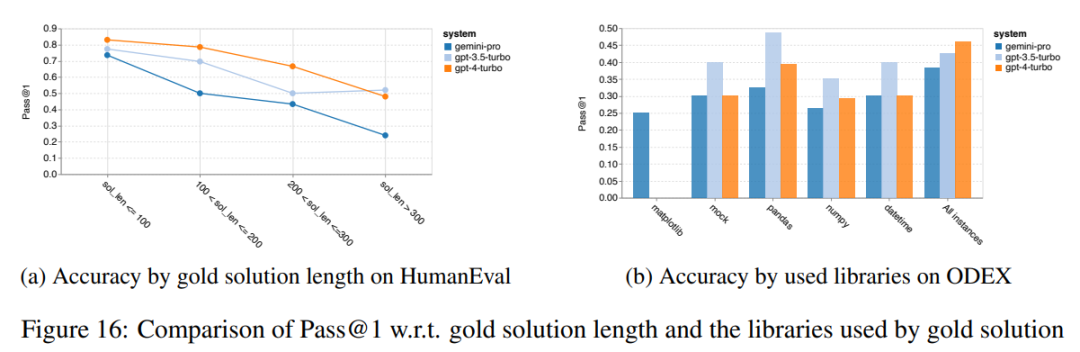
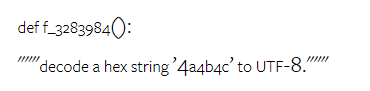
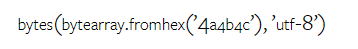
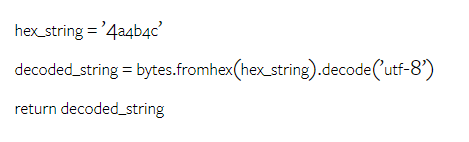


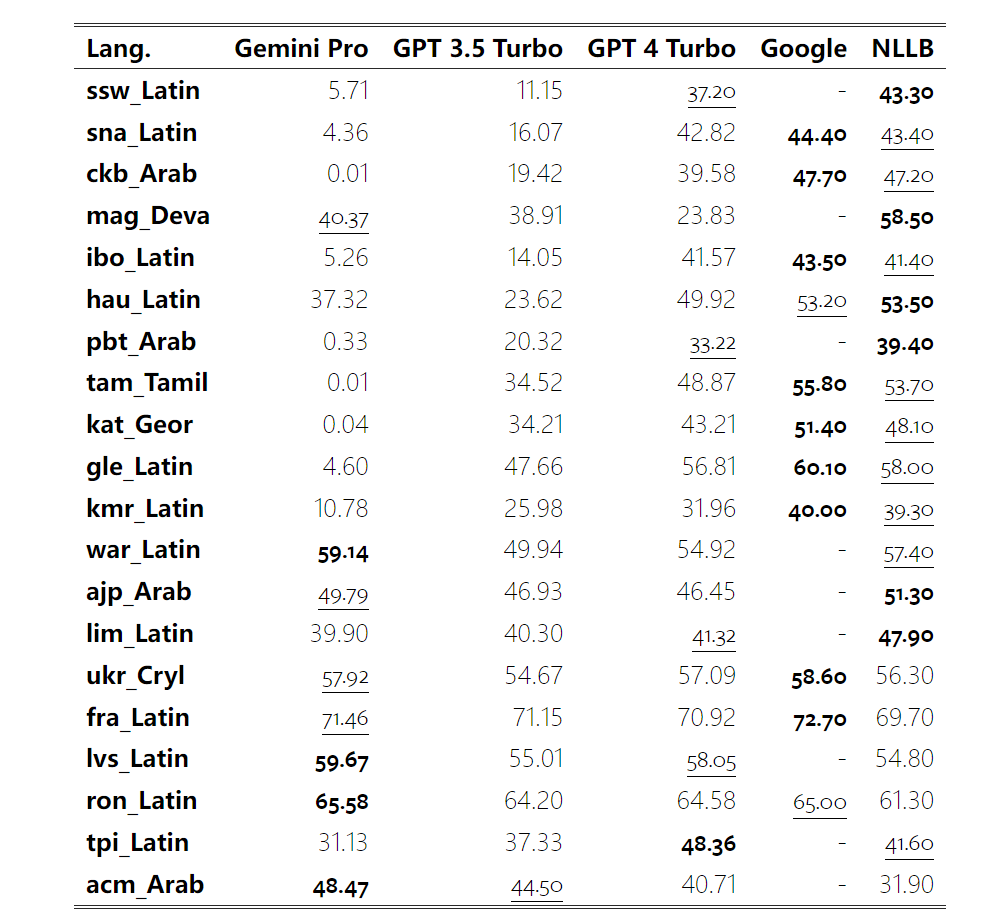
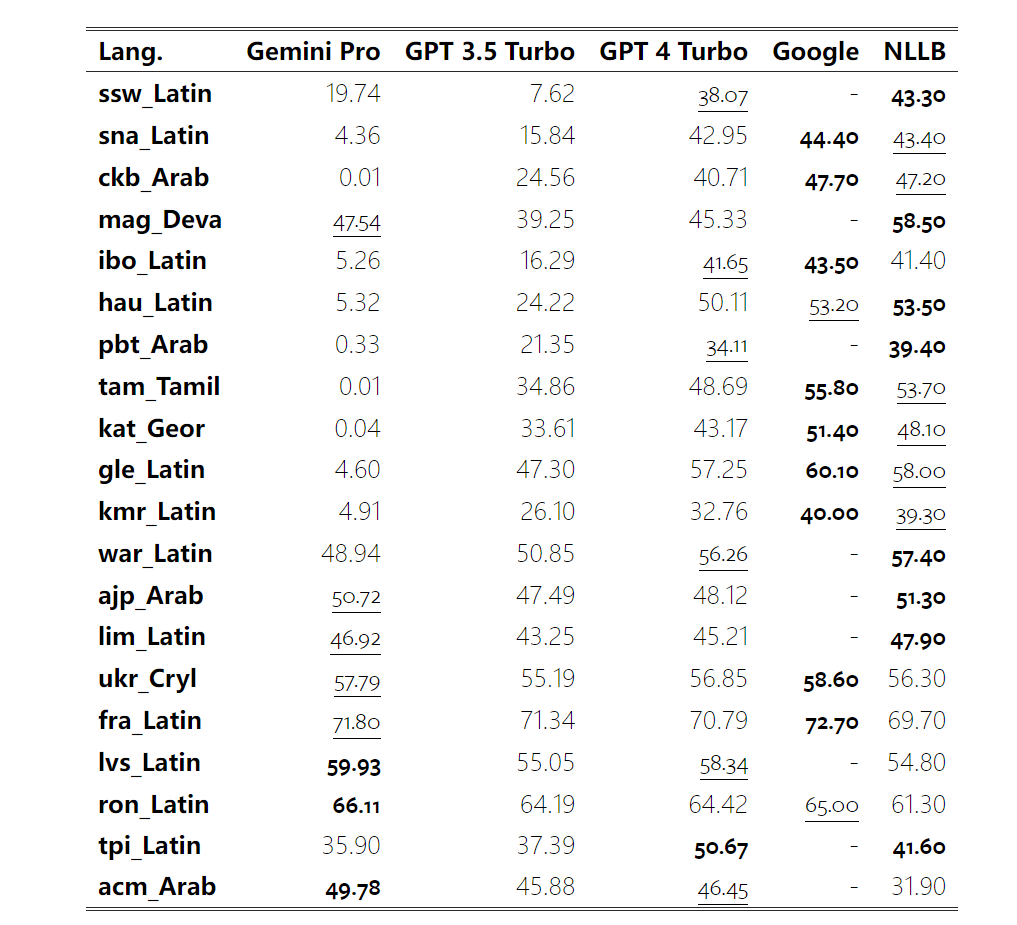
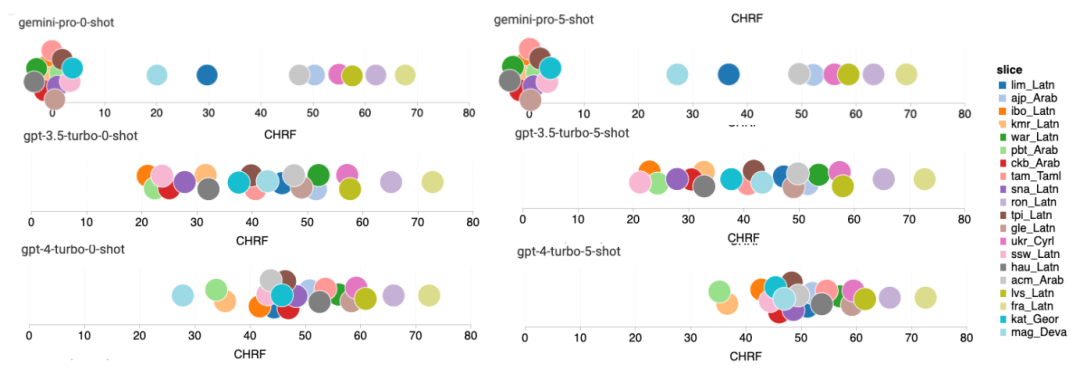
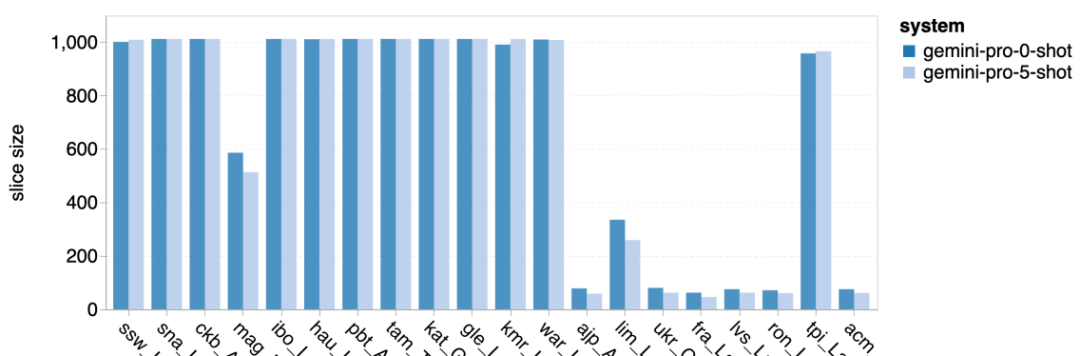
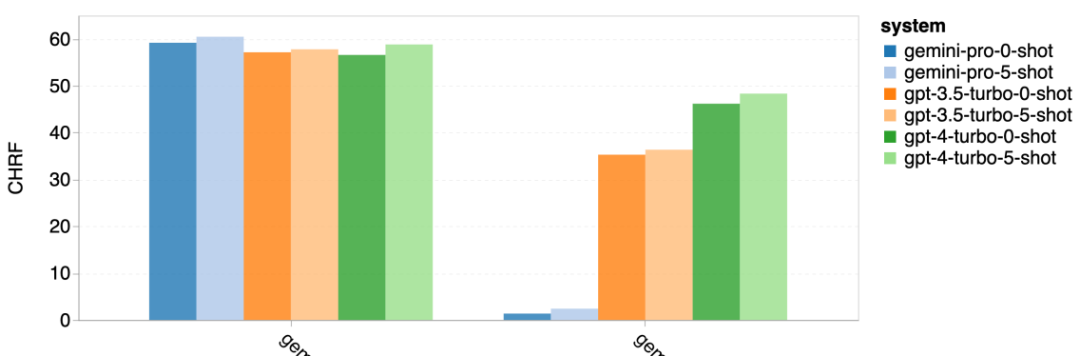
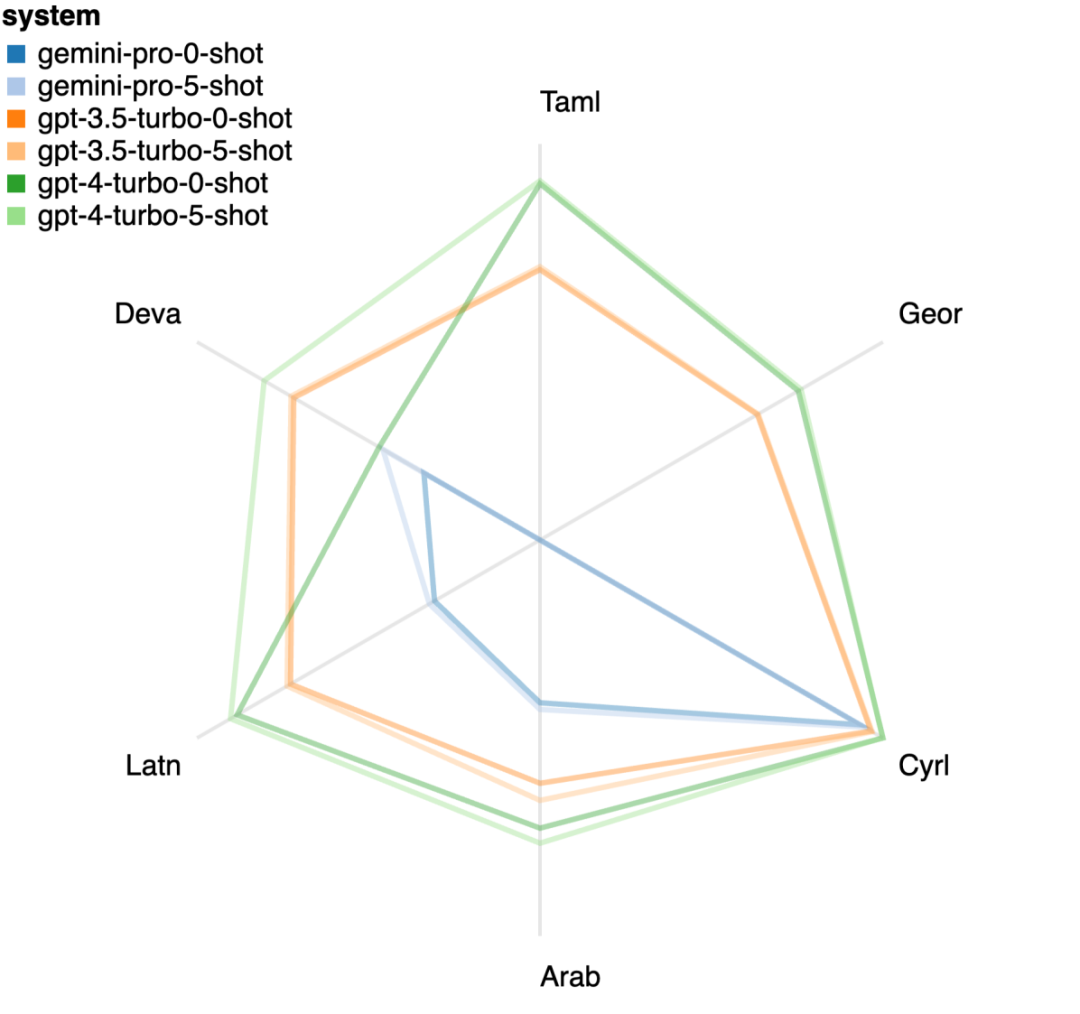
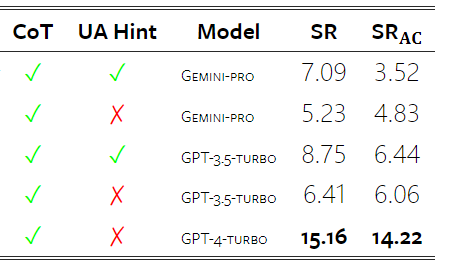
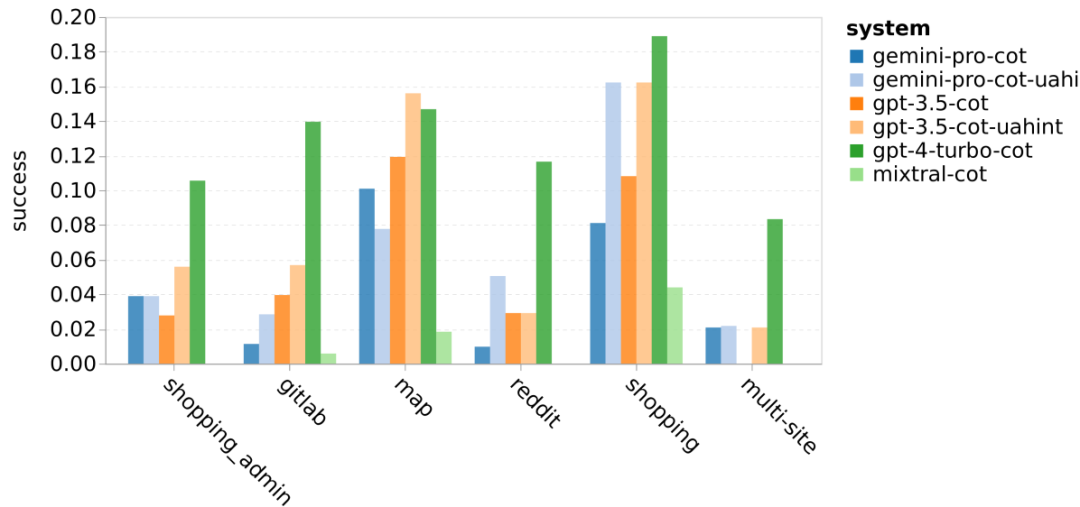
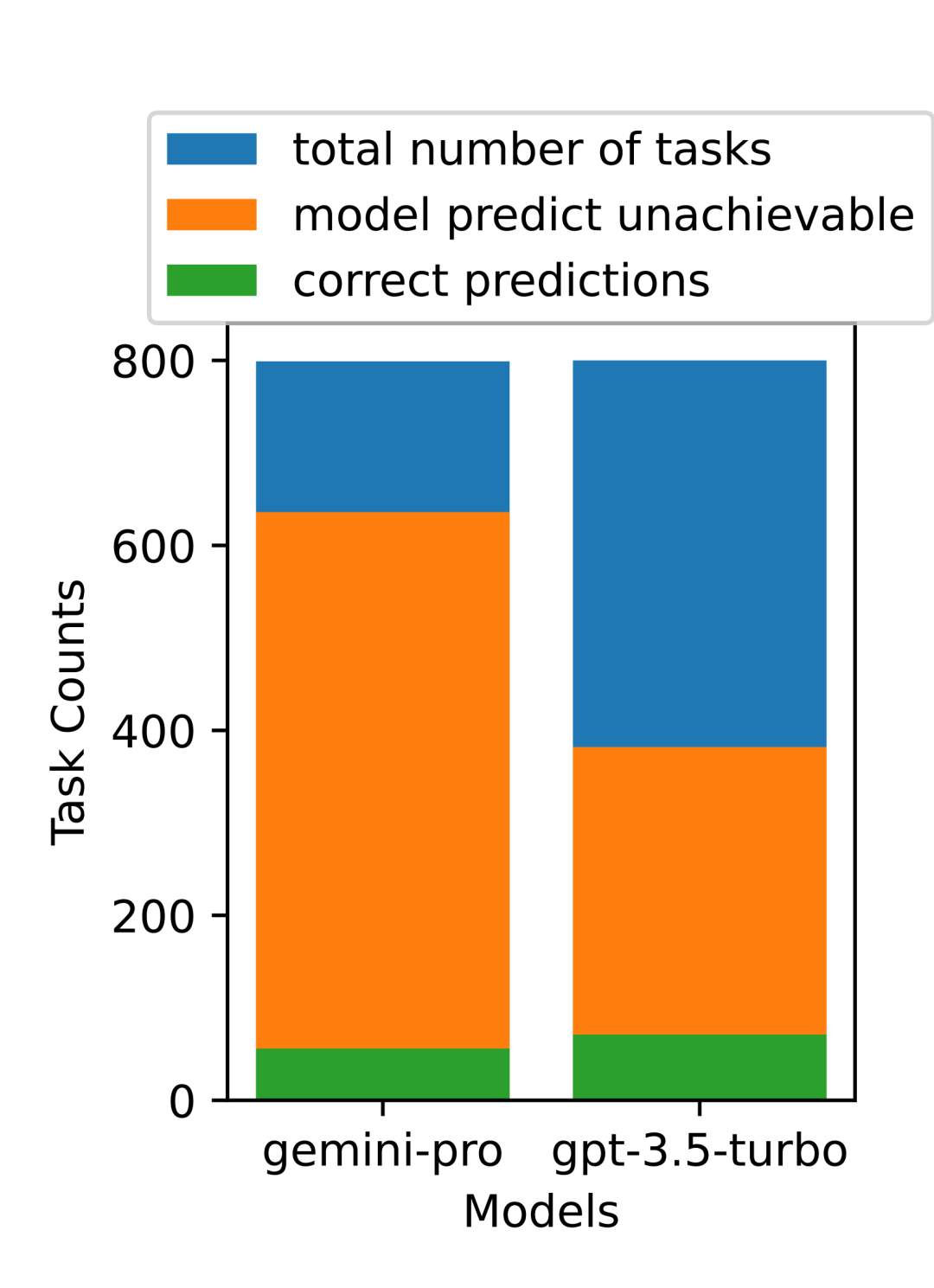
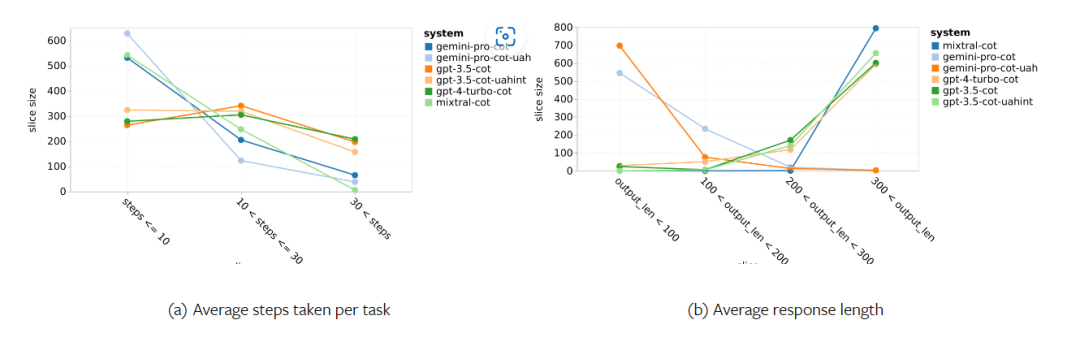
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle plate-forme d'échange de devises 2025 est meilleure? Les dernières recommandations des dix principales applications de trading de devises populaires
Mar 25, 2025 pm 06:18 PM
Quelle plate-forme d'échange de devises 2025 est meilleure? Les dernières recommandations des dix principales applications de trading de devises populaires
Mar 25, 2025 pm 06:18 PM
2025 Classement de plate-forme d'échange de devises: 1. Okx, 2. Binance, 3. Gate.io, 4. Coinbase, 5. Kraken, 6. Huobi Global, 7. Crypto.com, 8. Kucoin, 9. Gemini, 10. Bitstamp. Ces plateformes fonctionnent parfaitement dans les mesures de sécurité, les avis des utilisateurs et les performances du marché, et conviennent aux utilisateurs pour effectuer des transactions en devises numériques.
 Résumé des plateformes de trading de devises virtuelles sûres et faciles à utiliser en 2025
Mar 25, 2025 pm 06:15 PM
Résumé des plateformes de trading de devises virtuelles sûres et faciles à utiliser en 2025
Mar 25, 2025 pm 06:15 PM
Recommandé des plates-formes de négociation de devises virtuelles sûres et faciles à utiliser en 2025. Cet article résume dix plates-formes mondiales de trading de devises virtuelles mondiales, notamment Binance, Okx, Huobi, Gate.io, Coinbase, Kraken, Kucoin, Bitfinex, Crypto.com et Gemini. Ils présentent des avantages en termes de paires de négociation, de volume de transaction 24 heures sur 24, de sécurité, d'expérience utilisateur, etc. Par exemple, le trading de Binance est rapide, le trading à terme OKX est populaire, Coinbase convient aux débutants et Kraken est connu pour sa sécurité. Cependant, il convient de noter que les transactions en monnaie virtuelle sont extrêmement risquées et que les investissements devraient être prudents. Assurez-vous d'évaluer soigneusement votre propre style avant de sélectionner une plate-forme
 Quelle application de change de monnaie numérique est la meilleure en 2025?
Mar 25, 2025 pm 06:06 PM
Quelle application de change de monnaie numérique est la meilleure en 2025?
Mar 25, 2025 pm 06:06 PM
Classement des échanges d'applications de monnaie numérique sécurisés en 2025: 1. Okx, 2. Binance, 3. Gate.io, 4. Coinbase, 5. Kraken, 6. Huobi Global, 7. Crypto.com, 8. Kucoin, 9. Gemini, 10. Bitstamp. Ces plateformes fonctionnent parfaitement dans les mesures de sécurité, les avis des utilisateurs et les performances du marché, et conviennent aux utilisateurs pour effectuer des transactions en devises numériques.
 Le dernier résumé de la plate-forme de trading officielle Ethereum 2025
Mar 26, 2025 pm 04:45 PM
Le dernier résumé de la plate-forme de trading officielle Ethereum 2025
Mar 26, 2025 pm 04:45 PM
En 2025, le choix d'une plate-forme de trading Ethereum "formelle" signifie la sécurité, la conformité et la transparence. Les opérations agréées, la sécurité financière, les opérations transparentes, la LMA / KYC, la protection des données et le trading équitable sont essentiels. Des échanges conformes tels que Coinbase, Kraken et Gemini méritent d'être prêts à prêter attention. Binance et Ouli ont la possibilité de devenir des plateformes formelles en renforçant la conformité. Defi est une option, mais il y a des risques. Assurez-vous de prêter attention à la sécurité, à la conformité, aux dépenses, à la propagation des risques, à la sauvegarde des clés privées et à effectuer vos propres recherches.
 Top 10 de la sécurité mondiale et classement des échanges de devises virtuels faciles à utiliser 2025
Mar 21, 2025 pm 03:09 PM
Top 10 de la sécurité mondiale et classement des échanges de devises virtuels faciles à utiliser 2025
Mar 21, 2025 pm 03:09 PM
Top 10 plates-formes de trading de devises virtuelles: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Coinbase, 6. Huobi Global, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini, ces plates-formes sont très appréciées pour leur sécurité, leur fiabilité et leur expérience des utilisateurs, et sont idéaux pour les tradiers crypto-monnaie.
 Le dernier classement des dix premiers échanges de crypto-monnaie au monde en 2025
Mar 26, 2025 pm 05:09 PM
Le dernier classement des dix premiers échanges de crypto-monnaie au monde en 2025
Mar 26, 2025 pm 05:09 PM
Il est difficile de prédire le classement des échanges de crypto-monnaie en 2025 car le marché change rapidement. Ce qui est important n'est pas le classement spécifique, mais la compréhension des facteurs qui affectent le classement: la conformité réglementaire, l'investissement institutionnel, l'intégration de défi, l'expérience utilisateur, la sécurité et la mondialisation. Binance, Coinbase, Kraken et d'autres devraient entrer dans les dix premiers, mais des événements de cygne noir peuvent également se produire. Faites attention aux tendances du marché et aux tendances d'échange, ne croyez pas aveuglément aux classements et faites un bon travail de recherche avant d'investir.
 La dernière liste de classement du logiciel d'application de trading de devises numériques Crypto Crypto
Mar 21, 2025 pm 02:51 PM
La dernière liste de classement du logiciel d'application de trading de devises numériques Crypto Crypto
Mar 21, 2025 pm 02:51 PM
Crypto Digital Currency Trading App Ranking: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Coinbase, 6. Huobi Global, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini, ces plates-formes sont hautement appréciées pour leur sécurité, leur fiabilité et leur expérience des utilisateurs, et sont idéales pour le trafic de crypte.
 Top 10 des plates-formes de trading de devises numériques sûres et fiables en 2025
Mar 21, 2025 pm 03:21 PM
Top 10 des plates-formes de trading de devises numériques sûres et fiables en 2025
Mar 21, 2025 pm 03:21 PM
Top 10 des plates-formes de trading de devises numériques sûres et fiables en 2025: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Coinbase, 6. Huobi Global, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini, ces plates-formes sont hautement considérées pour leur sécurité, leur expérience de fiabilité et l'utilisateur, et sont idéales pour les échantillons de cryptocurvence.
