

使用SQL语句操作MYSQL字符编码_MySQL

-- 查看所有的字符编码
SHOW CHARACTER SET;
-- 查看创建数据库的指令并查看数据库使用的编码
show create database dbtest;
-- 查看数据库编码:
show variables like '%char%';
-- 设置character_set_server、set character_set_client和set character_set_results
set character_set_server = utf8; -- 服务器的默认字符集。使用这个语句可以修改成功,但重启服务后会失效。根本的办法是修改配置MYSQL文件MY.INI,character_set_server=utf8,配置到mysqld字段下。
set character_set_client = gbk; -- 来自客户端的语句的字符集。服务器使用character_set_client变量作为客户端发送的查询中使用的字符集。
set character_set_results = gbk; -- 用于向客户端返回查询结果的字符集。character_set_results变量指示服务器返回查询结果到客户端使用的字符集。包括结果数据,例如列值和结果元数据(如列名)。
-- 创建数据库时,设置数据库的编码方式
-- CHARACTER SET:指定数据库采用的字符集,utf8不能写成utf-8
-- COLLATE:指定数据库字符集的排序规则,utf8的默认排序规则为utf8_general_ci(通过show character set查看)
drop database if EXISTS dbtest;
create database dbtest CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 修改数据库编码
alter database dbtest CHARACTER SET GBK COLLATE gbk_chinese_ci;
alter database dbtest CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 创建表时,设置表、字段编码
use dbtest;
drop table if exists tbtest;
create table tbtest(
id int(10) auto_increment,
user_name varchar(60) CHARACTER SET GBK COLLATE gbk_chinese_ci,
email varchar(60),
PRIMARY key(id)
)CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 修改表编码
alter table tbtest character set utf8 COLLATE utf8_general_ci;
-- 修改字段编码
ALTER TABLE tbtest MODIFY email VARCHAR(60) CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 查看某字段使用的编码:
SELECT CHARSET(email) FROM tbtest;

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 11 techniques courantes d'encodage des caractéristiques de classification
Apr 12, 2023 pm 12:16 PM
11 techniques courantes d'encodage des caractéristiques de classification
Apr 12, 2023 pm 12:16 PM
Les algorithmes d'apprentissage automatique n'acceptent que les entrées numériques, donc si nous rencontrons des caractéristiques catégorielles, nous coderons les caractéristiques catégorielles. Cet article résume 11 méthodes courantes de codage de variables catégorielles. 1. ONE HOT ENCODING La méthode d’encodage la plus populaire et la plus couramment utilisée est One Hot Enoding. Une unique variable à n observations et d valeurs distinctes est convertie en d variables binaires à n observations, chaque variable binaire est identifiée par un bit (0, 1). Par exemple : l'implémentation la plus simple après l'encodage consiste à utiliser get_dummiesnew_df=pd.get_dummies(columns=[‘Sex’], data=df)2 de pandas,
 Utilisez la fonction Character.isDigit() de Java pour déterminer si un caractère est un nombre
Jul 27, 2023 am 09:32 AM
Utilisez la fonction Character.isDigit() de Java pour déterminer si un caractère est un nombre
Jul 27, 2023 am 09:32 AM
Utilisez la fonction Character.isDigit() de Java pour déterminer si un caractère est un caractère numérique. Les caractères sont représentés sous la forme de codes ASCII en interne dans l'ordinateur. Chaque caractère a un code ASCII correspondant. Parmi eux, les valeurs du code ASCII correspondant aux caractères numériques 0 à 9 sont respectivement 48 à 57. Pour déterminer si un caractère est un nombre, vous pouvez utiliser la méthode isDigit() fournie par la classe Character en Java. La méthode isDigit() est de la classe Character
 Comment taper des flèches dans Word
Apr 16, 2023 pm 11:37 PM
Comment taper des flèches dans Word
Apr 16, 2023 pm 11:37 PM
Comment utiliser la correction automatique pour saisir des flèches dans Word L'un des moyens les plus rapides de saisir des flèches dans Word consiste à utiliser les raccourcis de correction automatique prédéfinis. Si vous tapez une séquence spécifique de caractères, Word convertit automatiquement ces caractères en symboles fléchés. Vous pouvez dessiner de nombreux styles de flèches différents en utilisant cette méthode. Pour taper une flèche dans Word à l'aide de la correction automatique : Déplacez votre curseur vers l'emplacement du document où vous souhaitez que la flèche apparaisse. Tapez l'une des combinaisons de caractères suivantes : Si vous ne souhaitez pas que ce que vous tapez soit remplacé par un symbole de flèche, appuyez sur la touche Retour arrière de votre clavier pour
 Combien d'octets les caractères chinois codés en utf8 occupent-ils ?
Feb 21, 2023 am 11:40 AM
Combien d'octets les caractères chinois codés en utf8 occupent-ils ?
Feb 21, 2023 am 11:40 AM
Les caractères chinois codés en UTF8 occupent 3 octets. En codage UTF-8, un caractère chinois équivaut à trois octets et un signe de ponctuation chinois occupe trois octets, tandis qu'en codage Unicode, un caractère chinois (y compris le chinois traditionnel) équivaut à deux octets. UTF-8 utilise 1 à 4 octets pour coder chaque caractère. Un caractère US-ASCIl n'a besoin que de 1 octet pour coder. Le latin, le grec, le cyrillique, l'arménien et l'hébreu avec des signes diacritiques, l'arabe, le syriaque et d'autres lettres nécessitent 2 octets. codage.
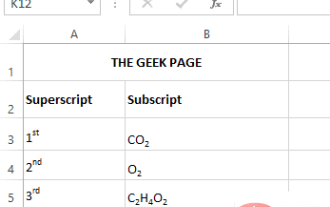 Comment appliquer les options de formatage en exposant et en indice dans Microsoft Excel
Apr 14, 2023 pm 12:07 PM
Comment appliquer les options de formatage en exposant et en indice dans Microsoft Excel
Apr 14, 2023 pm 12:07 PM
Un exposant est un ou plusieurs caractères, lettres ou chiffres, que vous devez définir légèrement au-dessus de la ligne normale de texte. Par exemple, si vous devez écrire 1er, la lettre st doit être légèrement plus haute que le caractère 1. De même, un indice est un groupe de caractères ou un caractère unique et doit être défini légèrement à un niveau inférieur au niveau de texte normal. Par exemple, lorsque vous écrivez une formule chimique, vous devez placer les nombres sous la ligne normale de caractères. Les captures d'écran suivantes montrent quelques exemples de formatage en exposant et en indice. Même si cela peut sembler une tâche ardue, appliquer le formatage en exposant et en indice à votre texte est en réalité assez simple. Dans cet article, nous expliquerons en quelques étapes simples comment formater facilement du texte en exposant ou en indice. J'espère que vous avez apprécié la lecture de cet article. Comment appliquer l'exposant dans Excel
 Comment saisir des caractères étendus, tels que le symbole du degré, sur iPhone et Mac ?
Apr 22, 2023 pm 02:01 PM
Comment saisir des caractères étendus, tels que le symbole du degré, sur iPhone et Mac ?
Apr 22, 2023 pm 02:01 PM
Votre clavier physique ou numérique offre un nombre limité d'options de caractères en surface. Cependant, il existe plusieurs façons d'accéder aux lettres accentuées, aux caractères spéciaux et bien plus encore sur iPhone, iPad et Mac. Le clavier iOS standard vous donne un accès rapide aux lettres majuscules et minuscules, aux chiffres standard, à la ponctuation et aux caractères. Bien sûr, il existe de nombreux autres personnages. Vous pouvez choisir entre des lettres avec des signes diacritiques et des points d'interrogation à l'envers. Vous êtes peut-être tombé sur un caractère spécial caché. Sinon, voici comment y accéder sur iPhone, iPad et Mac. Comment accéder aux caractères étendus sur iPhone et iPad Obtenir des caractères étendus sur votre iPhone ou iPad est très simple. Dans "Informations", "
 Knowledge graph : le partenaire idéal des grands modèles
Jan 29, 2024 am 09:21 AM
Knowledge graph : le partenaire idéal des grands modèles
Jan 29, 2024 am 09:21 AM
Les grands modèles linguistiques (LLM) ont la capacité de générer un texte fluide et cohérent, ouvrant de nouvelles perspectives dans des domaines tels que la conversation par intelligence artificielle et l'écriture créative. Cependant, le LLM présente également certaines limites clés. Premièrement, leurs connaissances se limitent aux modèles reconnus à partir des données de formation, sans une véritable compréhension du monde. Deuxièmement, les capacités de raisonnement sont limitées et ne peuvent pas faire de déductions logiques ni fusionner des faits provenant de plusieurs sources de données. Face à des questions plus complexes et ouvertes, les réponses de LLM peuvent devenir absurdes ou contradictoires, ce que l'on appelle des « illusions ». Par conséquent, bien que le LLM soit très utile à certains égards, il présente néanmoins certaines limites lorsqu’il s’agit de problèmes complexes et de situations du monde réel. Afin de combler ces lacunes, des systèmes de génération augmentée par récupération (RAG) ont vu le jour ces dernières années.
 Manière correcte d'afficher les caractères chinois dans matplotlib
Jan 13, 2024 am 11:03 AM
Manière correcte d'afficher les caractères chinois dans matplotlib
Jan 13, 2024 am 11:03 AM
Afficher correctement les caractères chinois dans matplotlib est un problème souvent rencontré par de nombreux utilisateurs chinois. Par défaut, matplotlib utilise des polices anglaises et ne peut pas afficher correctement les caractères chinois. Pour résoudre ce problème, nous devons définir la police chinoise correcte et l'appliquer à matplotlib. Vous trouverez ci-dessous quelques exemples de code spécifiques pour vous aider à afficher correctement les caractères chinois dans matplotlib. Tout d’abord, nous devons importer les bibliothèques requises : importmatplot
