
 Périphériques technologiques
IA
La vidéo peut être reconstruite en 14 secondes et les caractères peuvent être modifiés. Meta accélère la synthèse vidéo de 44 fois.
Périphériques technologiques
IA
La vidéo peut être reconstruite en 14 secondes et les caractères peuvent être modifiés. Meta accélère la synthèse vidéo de 44 fois.
La vidéo peut être reconstruite en 14 secondes et les caractères peuvent être modifiés. Meta accélère la synthèse vidéo de 44 fois.
Dec 27, 2023 pm 06:35 PMLe nouveau cadre de synthèse vidéo de Meta nous a apporté quelques surprises





Adresse de papier: https://arxiv.org/pdf/2312.13834.pdf project Homepage: https://fairy-video2video.github.io/

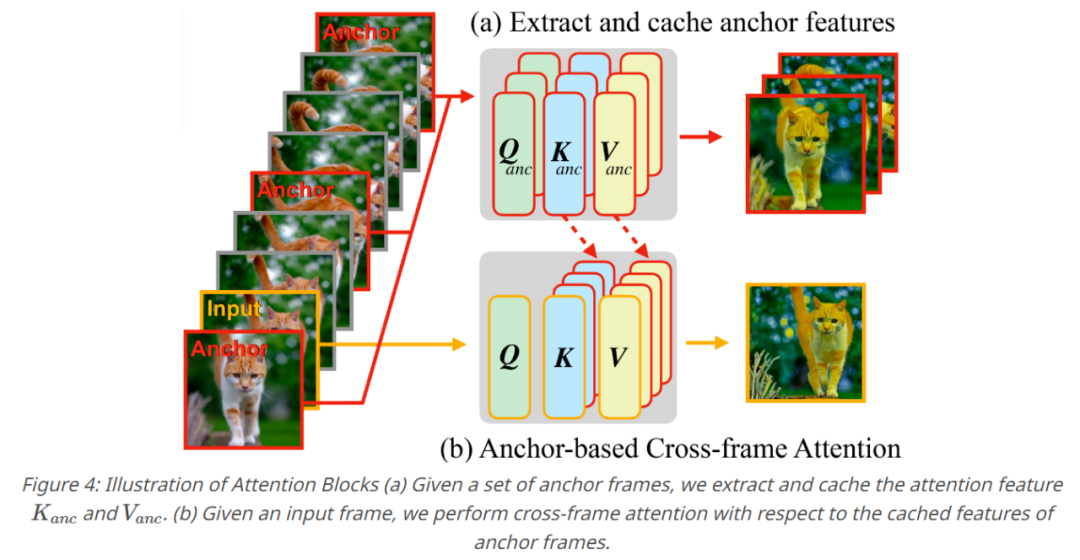





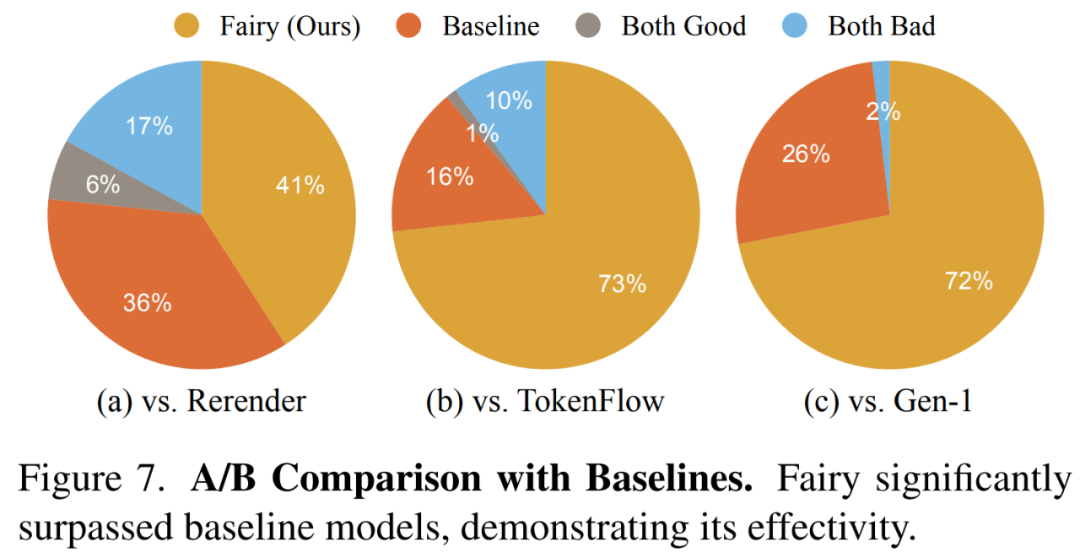

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Article chaud

Outils chauds Tags

Article chaud

Tags d'article chaud

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
 En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
 L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
 Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
Jul 23, 2024 pm 02:05 PM
Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
Jul 23, 2024 pm 02:05 PM
Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
 Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
 Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
 La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
