

Les fonctions d'activation jouent un rôle crucial dans l'apprentissage en profondeur. Elles peuvent introduire des caractéristiques non linéaires dans les réseaux neuronaux, permettant au réseau de mieux apprendre et simuler des relations entrées-sorties complexes. La sélection et l'utilisation correctes des fonctions d'activation ont un impact important sur les performances et l'effet d'entraînement des réseaux de neurones
Cet article présentera quatre fonctions d'activation couramment utilisées : Sigmoid, Tanh, ReLU et Softmax, depuis l'introduction, les scénarios d'utilisation, les avantages, inconvénients et solutions d'optimisation Explorez cinq dimensions pour vous fournir une compréhension complète des fonctions d'activation.

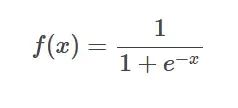 Formule de la fonction SIgmoïde
Formule de la fonction SIgmoïde
Introduction : La fonction sigmoïde est une fonction non linéaire couramment utilisée qui peut mapper n'importe quel nombre réel entre 0 et 1. Il est souvent utilisé pour convertir des valeurs prédites non normalisées en distributions de probabilité.
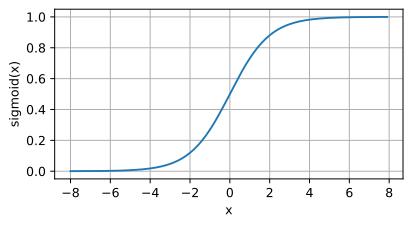 Image de la fonction SIgmoïde
Image de la fonction SIgmoïde
Scénario d'application :
Voici les avantages suivants :
Inconvénients : Lorsque la valeur d'entrée est très grande, le gradient peut devenir très petit, conduisant au problème de disparition du gradient.
Schéma d'optimisation :
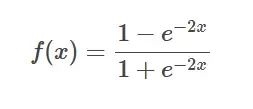 Formule de la fonction Tanh
Formule de la fonction Tanh
Introduction : La fonction Tanh est la version hyperbolique de la fonction sigmoïde, qui mappe n'importe quel nombre réel entre -1 et 1.
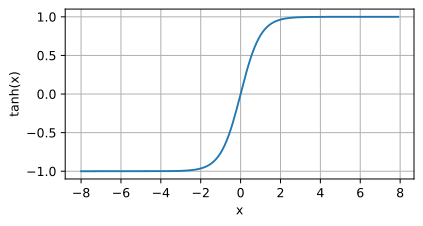 Image de la fonction Tanh
Image de la fonction Tanh
Scénario d'application : Lorsqu'une fonction plus raide que Sigmoïde est requise, ou dans certaines applications spécifiques qui nécessitent une sortie comprise entre -1 et 1.
Les avantages suivants sont les suivants : Elle offre une plage dynamique plus large et une courbe plus raide, ce qui peut accélérer la vitesse de convergence.
L'inconvénient de la fonction Tanh est que lorsque l'entrée est proche de ±1, sa dérivée se rapproche rapidement de 0. , provoquant la disparition du dégradé Problème
Solution d'optimisation :
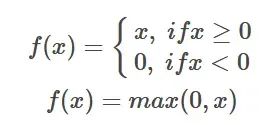 Formule de la fonction ReLU
Formule de la fonction ReLU
Introduction : La fonction d'activation ReLU est une fonction non linéaire simple, et son expression mathématique est f(x) = max( 0, x). Lorsque la valeur d'entrée est supérieure à 0, la fonction ReLU génère la valeur ; lorsque la valeur d'entrée est inférieure ou égale à 0, la fonction ReLU génère 0.
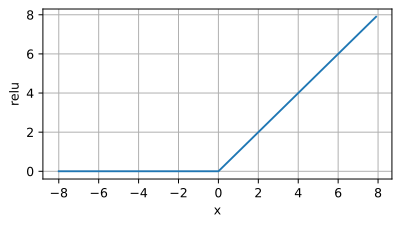 Image de la fonction ReLU
Image de la fonction ReLU
Scénario d'application : la fonction d'activation ReLU est largement utilisée dans les modèles d'apprentissage en profondeur, en particulier dans les réseaux de neurones convolutifs (CNN). Ses principaux avantages sont qu'il est simple à calculer, qu'il peut atténuer efficacement le problème de la disparition du gradient et qu'il peut accélérer la formation du modèle. Par conséquent, ReLU est souvent utilisé comme fonction d’activation préférée lors de la formation de réseaux neuronaux profonds.
Voici les avantages suivants :
Inconvénients :
Schéma d'optimisation :
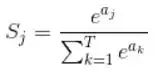 Formule de fonction Softmax
Formule de fonction Softmax
Introduction : Softmax est une fonction d'activation couramment utilisée, principalement utilisée dans les problèmes de multi-classification, qui peut convertir les neurones d'entrée en distribution de probabilité. Sa principale caractéristique est que la plage des valeurs de sortie est comprise entre 0 et 1 et que la somme de toutes les valeurs de sortie est 1.
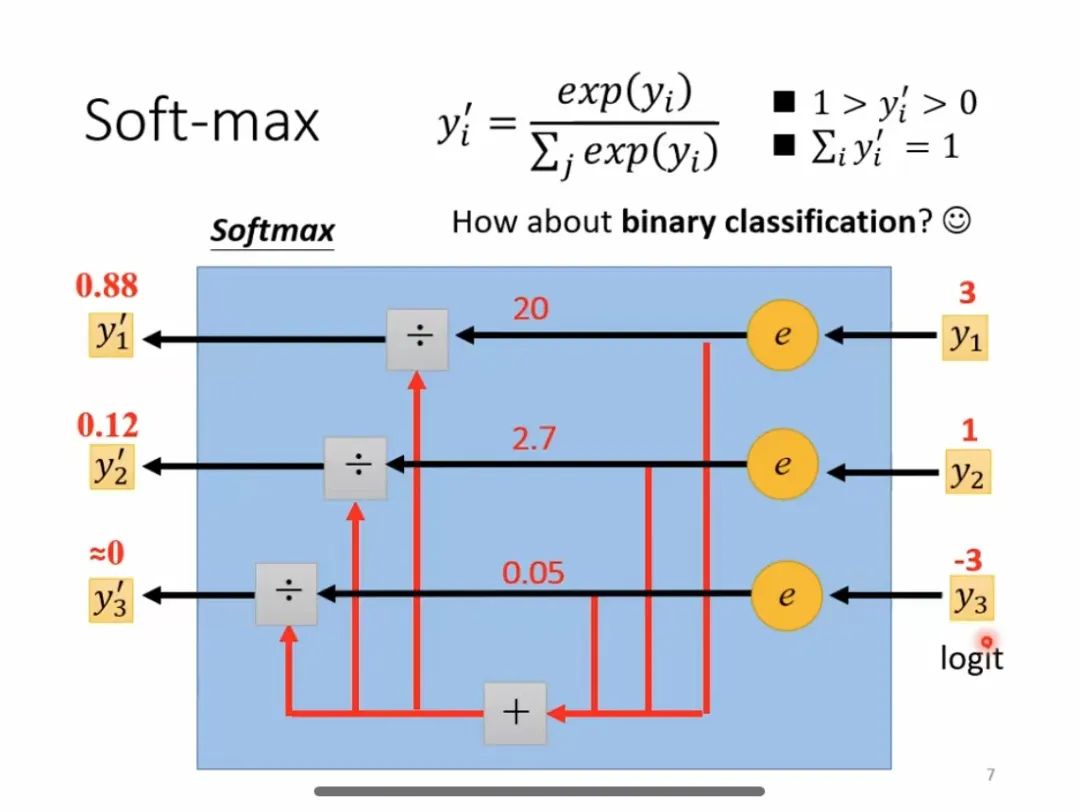 Processus de calcul Softmax
Processus de calcul Softmax
Scénario d'application :
Voici les avantages suivants : Dans les problèmes multi-classifications, une valeur de probabilité relative peut être fournie pour chaque catégorie afin de faciliter la prise de décision et la classification ultérieures.
Inconvénients : Il y aura des problèmes de disparition ou d'explosion de gradient.
Schéma d'optimisation :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Windows change le type de fichier
Windows change le type de fichier
 La différence entre passerelle et routeur
La différence entre passerelle et routeur
 Pourquoi swoole peut-il résider en mémoire ?
Pourquoi swoole peut-il résider en mémoire ?
 Que fait Python ?
Que fait Python ?
 Aucun service sur les données mobiles
Aucun service sur les données mobiles
 Quel format de fichier est csv ?
Quel format de fichier est csv ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



