

mysql高可用架构方案之二(keepalived+lvs+读写分离+负载均衡)_MySQL

mysql主从复制与lvs+keepalived实现负载高可用
目录
1、前言 4
2、原理 4
2.1、概要介绍 4
2.2、工作原理 4
2.3、实际作用 4
3方案 4
3.1、环境 4
3.2、架构图 5
3.3、设计原理 6
4、相关软件安装 6
4、配置mysql的主从 7
5、通过lvs+keepalived实现负载与热备,并实现读写分离 8
1、前言
最近研究了下高可用的东西,这里总结一下mysql主从复制读写分离度的高可用方案,可以提高服务器的使用效率,也可以提高提高维护效率。同时应用的效率也会有一定的提升,如果改造需要应用修改读取的ip地址与写入的ip地址,改造起来还算容易。
2、原理
2.1、概要介绍
如果将TCP/IP划分为5层,则Keepalived就是一个类似于3~5层交换机制的软件,具有3~5层交换功能,其主要作用是检测web服务器的状 态,如果某台web服务器故障,Keepalived将检测到并将其从系统中剔除,当该web服务器工作正常后Keepalived自动将其加入到服务器 群中,这些工作全部自动完成,而不需要人工干预,只需要人工修复故障的web服务器即可。
2.2、工作原理
Keepalived基于VRRP协议来实现高可用解决方案,利用其避免单点故障,通常这个解决方案中,至少有2台服务器运行Keepalived,即一 台为MASTER,另一台为BACKUP,但对外表现为一个虚拟IP,MASTER会发送特定消息给BACKUP,当BACKUP收不到该消息时,则认为 MASTER故障了,BACKUP会接管虚拟IP,继续提供服务,从而保证了高可用性,3层机理是发送ICMP数据包即PING给某台服务器,如果不痛,则认为其故障,并从服务器群中剔除。4层机理是检测TCP端口号状态来判断某台服务器是否故障,如果故障,则从服务器群中剔除。5层机理是根据用户的设定检查某个服务器应用程序是否正常运行,如果不正常,则从服务器群中剔除。3、
2.3、实际作用
Keepalived+lvs主要用作RealServer的健康检查,以及负载均衡设备MASTER和BACKUP之间failover的实现。
3方案
本案例先使用两台linux做双机MASTER-SLAVE高可用,实现都写分离,用于提高查询性能),采用MYSQL5.6.x的半同步实现数据复制和同步,使用keepalived来监控MYSQL和提供读写VIP浮动。Keepalived在这里主要用作RealServer的健康状态检查以及LoadBalance主机和BackUP主机之间failover的实现
任何一台主机宕机都不会影响对外提供服务(读写vip可以浮动),保持服务的高可用。
3.1、环境
主机A:192.168.150.171
主机B:192.168.150.172
W-VIP:192.168.150.173 (负责写入)
R-VIP:192.168.150.174 (负责读取)
Client:任意,只要能访问以上三个IP即可
3.2、架构图
具体架构图如下:
3.3、设计原理(异常情况)
1、 服务器A和B,通过mysql的slave进程是用binlog同步数据。
2、 通过keepalived启用两个虚IP:W-VIP/R-VIP,一个负责写入,一个负责读取,实现读写分离。
3、 A和B都存在时,W-VIP下将请求转发至主机A,R-VIP将请求转发给A和B,实现负载均衡。
4、 当主机A异常时,B接管服务,W-VIP/R-VIP此时漂到了主机B上,此时这两个虚IP下都是主机B,实现高可用
5、 当主机B异常时,R-VIP会将B踢出,其他不变
具体实现后的效果
正常状态
Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.150.173:3306 wrr persistent 60 -> 192.168.150.171:3306 Local 3 0 0 TCP 192.168.150.174:3306 wrr persistent 60 -> 192.168.150.172:3306 Route 3 0 0 -> 192.168.150.171:3306 Local 1 0 0
A故障后,B的状态
Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.150.173:3306 wrr persistent 60 -> 192.168.150.172:3306 Local 3 0 0 TCP 192.168.150.174:3306 wrr persistent 60 -> 192.168.150.172:3306 Local 3 0 0
架构图
4、相关软件安装
1、 mysql 可以根据需要进行安装,此处省略
2、 lvs+keepalived的安装
关联lvs与keepalived的ipvs所需的内核信息
ln -s /usr/src/kernels/2.6.18-194.el5-x86_64/ /usr/src/linux
安装lvs
下载:wget http://www.linuxvirtualserver.org/software/kernel-2.6/ipvsadm-1.24.tar.gz
tar -zxvf ipvsadm-1.24.tar.gz
cd tar -zxvf ipvsadm-1.24
make
make install
yum install ipv* 安装
验证
ipvsadm –v
ipvsadm v1.24 2003/06/07 (compiled with getopt_long and IPVS v1.2.0)说明安装成功
安装keepalived
tar –zxvf keepalived-1.2.12.tar.gz cd keepalived-1.2.12 ./configure --prefix=/usr/local/keepalived/ make make install ln -s /usr/local/keepalived/etc/keepalived /etc/ ln -s /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/rc.d/init.d/ ln -s /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/ ln -s /usr/local/keepalived/bin/genhash /bin/ ln -s /usr/local/keepalived/sbin/keepalived /sbin/
configure时注意Use IPVS Framework、IPVS sync daemon support 、Use VRRP Framework要返回yes,否则无法关联ipvs功能
4、配置mysql的主从
Master(210.171)的配置
vi /etc/my.cnf
添加如下内容:
server-id = 1 ##master ID binlog-do-db = ppl ##允许同步的库 binlog-ignore-db = mysql ##忽略同步的库,也就是不能同步的库 ##配置文件中还需开启log-bin,例如log-bin = mysql-bin mysql –uroot –p
以下内容在mysql中执行
mysql> grant replication slave on *.* to ‘repdb01’@’%’ identified by '123456'; mysql>create database db01; mysql>flush logs; mysql>show master status; mysql>use db01 mysql> create table test(name char);
返回一表格如下,记住File的内容,等下slave的配置中要用到
Slave的配置
vi /etc/my.cnf
添加如下内容:
server-id = 2 ##slave ID master-host = 192.168.150.171 ##指定master的地址 master-user = repdb01 ##同步所用的账号 master-password = 123456 ##同步所用的密码 master-port = 3306 ##master上mysql的端口 replicate-do-db = db01 ##要同步的库名 replicate-ignore-db = mysql ##忽略的库名 slave-skip-errors = 1062 ##当同步异常时,那些错误跳过,本例为1062错误 #log-slave-updates ##同步的同时,也记录自己的binlog日志,如果还有台slave是通过这台机器进行同步,那需要增加此项, #skip-slave-start ##启动时不自动开启slave进程 #read-only ##将库设为只读模式,只能从master同步,不能直接写入(避免自增键值冲突) mysql –uroot –p
以下内容在mysql中执行
mysql>create database db01; mysql>change master to master_log_file=’mysql-bin.000007’,master_log=106; mysql>slave start; mysql>show slave status \G
在返回值中查看,如果slave_IO_Runing与slave_SQL_Runing的值都为Yes说明同步成功
5、通过lvs+keepalived实现负载与热备,并实现读写分离
Master上的配置
vi /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id MySQL-HA
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 90
priority 100
advert_int 1
notify_master "/usr/local/mysql/bin/remove_slave.sh"
nopreempt
authentication {
auth_type PASS
auth_pass abcd1234
}
virtual_ipaddress {
192.168.150.173 label eth0:1
192.168.150.174 label eth0:2
}
}
virtual_server 192.168.150.173 3306 {
delay_loop 2
lb_algo wrr
lb_kind DR
persistence_timeout 60
protocol TCP
real_server 192.168.150.171 3306 {
weight 3
notify_down /usr/local/mysql/bin/mysql.sh
TCP_CHECK {
connect_timeout 10
nb_get_retry 3
delay_before_retry 3
connect_port 3306
}
}
}
virtual_server 192.168.150.174 3306 {
delay_loop 2
lb_algo wrr
lb_kind DR
persistence_timeout 60
protocol TCP
real_server 192.168.150.171 3306 {
weight 1
notify_down /usr/local/mysql/bin/mysql.sh
TCP_CHECK {
connect_timeout 10
nb_get_retry 3
delay_before_retry 3
connect_port 3306
}
}
real_server 192.168.150.172 3306 {
weight 3
TCP_CHECK {
connect_timeout 10
nb_get_retry 3
delay_before_retry 3
connect_port 3306
}
}
}
vi /usr/local/mysql/bin/remove_slave.sh
#!/bin/bash
user=root
password=123456
log=/root/mysqllog/remove_slave.log
#--------------------------------------------------------------------------------------
echo "`date`" >> $log
/usr/bin/mysql -u$user -p$password -e "set global read_only=OFF;reset master;stop slave;change master to master_host='localhost';" >> $log
/bin/sed -i 's#read-only#\#read-only#' /etc/my.cnf
chomd 755 /usr/local/mysql/bin/remove_slave.sh
vi /usr/local/mysql/bin/mysql.sh
#!/bin/bash
/etc/init.d/keepalived stop
Slave上的配置
vi /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id MySQL-HA
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 90
priority 99
advert_int 1
notify_master "/usr/local/mysql/bin/remove_slave.sh"
authentication {
auth_type PASS
auth_pass ppl.com
}
virtual_ipaddress {
192.168.150.173 label eth0:1
192.168.150.174 label eth0:2
}
}
virtual_server 192.168.150.173 3306 {
delay_loop 2
lb_algo wrr
lb_kind DR
persistence_timeout 60
protocol TCP
real_server 192.168.150.172 3306 {
weight 3
notify_down /usr/local/mysql/bin/mysql.sh
TCP_CHECK {
connect_timeout 10
nb_get_retry 3
delay_before_retry 3
connect_port 3306
}
}
}
virtual_server 192.168.150.174 3306 {
delay_loop 2
lb_algo wrr
lb_kind DR
persistence_timeout 60
protocol TCP
real_server 192.168.150.172 3306 {
weight 3
notify_down /usr/local/mysql/bin/mysql.sh
TCP_CHECK {
connect_timeout 10
nb_get_retry 3
delay_before_retry 3
connect_port 3306
}
}
# real_server 192.168.150.172 3306 {
# weight 3
# TCP_CHECK {
# connect_timeout 10
# nb_get_retry 3
# delay_before_retry 3
# connect_port 3306
# }
# }
}
vi /usr/local/mysql/bin/remove_slave.sh
#!/bin/bash
user=root
password=123456
log=/root/mysqllog/remove_slave.log
#--------------------------------------------------------------------------------------
echo "`date`" >> $log
/usr/bin/mysql -u$user -p$password -e "set global read_only=OFF;reset master;stop slave;change master to master_host='localhost';" >> $log
/bin/sed -i 's#read-only#\#read-only#' /etc/my.cnf
chomd 755 /usr/local/mysql/bin/remove_slave.sh
vi /usr/local/mysql/bin/mysql.sh
#!/bin/bash
/etc/init.d/keepalived stop
vi /usr/local/keepalived/bin/lvs-rs.sh
#!/bin/bash
WEB_VIP=192.168.150.174
. /etc/rc.d/init.d/functions
case "$1" in
start)
ifconfig lo:0 $WEB_VIP netmask 255.255.255.255 broadcast $WEB_VIP
/sbin/route add -host $WEB_VIP dev lo:0
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
sysctl -p >/dev/null 2>&1
echo "RealServer Start OK"
;;
stop)
ifconfig lo:0 down
route del $WEB_VIP >/dev/null 2>&1
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "0" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/all/arp_announce
echo "RealServer Stoped"
;;
status)
# Status of LVS-DR real server.
islothere=`/sbin/ifconfig lo:0 | grep $WEB_VIP`
isrothere=`netstat -rn | grep "lo:0" | grep $web_VIP`
if [ ! "$islothere" -o ! "isrothere" ];then
# Either the route or the lo:0 device
# not found.
echo "LVS-DR real server Stopped."
else
echo "LVS-DR Running."
fi
;;
*)
# Invalid entry.
echo "$0: Usage: $0 {start|status|stop}"
exit 1
;;
esac
exit 0
chmod 755 /usr/local/keepalived/bin/lvs-rs.sh
echo “/usr/local/keepalived/bin/lvs-rs.sh start” >>/etc/rc.localvi /etc/my.cnf
将这两个参数前边的 # 去掉,重启mysql
#skip-slave-start
#read-only
登陆mysql,手动将slave进程启动
mysql>slave start;
先启动master上的keepalived,正常后再启动slave上的。
启动后 主库可以查看ip a
[root@rac3 ~]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast qlen 1000 link/ether 00:50:56:95:06:1f brd ff:ff:ff:ff:ff:ff inet 192.168.150.171.171/24 brd 192.168.0.255 scope global eth0 inet 192.168.150.173/32 scope global eth0:1 inet 192.168.150.174/32 scope global eth0:2 inet6 fe80::250:56ff:fe95:61f/64 scope link valid_lft forever preferred_lft forever 3: sit0: <NOARP> mtu 1480 qdisc noop link/sit 0.0.0.0 brd 0.0.0.0 slave上查看 [root@rac1 keepalive]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet 192.168.150.174/32 brd 192.168.150.174 scope global lo:0 inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast qlen 1000 link/ether 00:50:56:95:5e:b4 brd ff:ff:ff:ff:ff:ff inet 192.168.150.188/24 brd 192.168.0.255 scope global eth0 inet 192.168.150.252/24 brd 192.168.0.255 scope global secondary eth0:1 inet 192.168.150.186/24 brd 192.168.0.255 scope global secondary eth0:4 inet6 fe80::250:56ff:fe95:5eb4/64 scope link valid_lft forever preferred_lft forever 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast qlen 1000 link/ether 00:50:56:95:11:ba brd ff:ff:ff:ff:ff:ff inet 10.10.10.188/24 brd 10.10.10.255 scope global eth1 inet 169.254.157.163/16 brd 169.254.255.255 scope global eth1:1 inet6 fe80::250:56ff:fe95:11ba/64 scope link valid_lft forever preferred_lft forever 4: sit0: <NOARP> mtu 1480 qdisc noop link/sit 0.0.0.0 brd 0.0.0.0
发现210.174 读的vip 在主备机上都可以看到
210.173 写入vip在主上才能看到
后续多台实验进行中,敬请等待

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Le concept d'apprentissage profond est né de la recherche sur les réseaux de neurones artificiels. Un perceptron multicouche contenant plusieurs couches cachées est une structure d'apprentissage profond. L'apprentissage profond combine des fonctionnalités de bas niveau pour former des représentations de haut niveau plus abstraites afin de caractériser des catégories ou des caractéristiques de données. Il est capable de découvrir des représentations de fonctionnalités distribuées de données. L'apprentissage profond est un type d'apprentissage automatique, et l'apprentissage automatique est le seul moyen d'atteindre l'intelligence artificielle. Alors, quelles sont les différences entre les différentes architectures de systèmes d’apprentissage profond ? 1. Réseau entièrement connecté (FCN) Un réseau entièrement connecté (FCN) se compose d'une série de couches entièrement connectées, chaque neurone de chaque couche étant connecté à chaque neurone d'une autre couche. Son principal avantage est qu'il est « indépendant de la structure », c'est-à-dire qu'aucune hypothèse particulière concernant l'entrée n'est requise. Bien que cette agnostique structurelle rende la
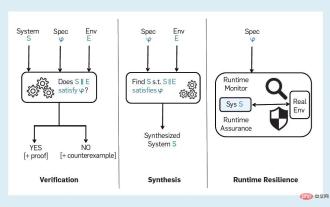 Vers une IA vérifiable : cinq défis des méthodes formelles
Apr 09, 2023 pm 02:01 PM
Vers une IA vérifiable : cinq défis des méthodes formelles
Apr 09, 2023 pm 02:01 PM
L'intelligence artificielle est un système informatique qui tente d'imiter l'intelligence humaine, y compris certaines fonctions humaines intuitivement liées à l'intelligence, telles que l'apprentissage, la résolution de problèmes, la pensée et l'action rationnelles. Interprété au sens large, le terme IA recouvre de nombreux domaines étroitement liés tels que l’apprentissage automatique. Les systèmes qui font largement appel à l’IA ont des impacts sociaux importants dans des domaines tels que la santé, les transports, la finance, les réseaux sociaux, le commerce électronique et l’éducation. Cet impact social croissant a également entraîné une série de risques et de préoccupations, notamment des erreurs dans les logiciels d’intelligence artificielle, des cyberattaques et la sécurité des systèmes d’intelligence artificielle. Par conséquent, la question de la vérification des systèmes d’IA, et le sujet plus large de l’IA digne de confiance, ont commencé à attirer l’attention de la communauté des chercheurs. « IA vérifiable » a été confirmée
 Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Il y a quelque temps, un tweet soulignant l'incohérence entre le schéma d'architecture du Transformer et le code de l'article de l'équipe Google Brain "AttentionIsAllYouNeed" a déclenché de nombreuses discussions. Certains pensent que la découverte de Sebastian était une erreur involontaire, mais elle est aussi surprenante. Après tout, compte tenu de la popularité du document Transformer, cette incohérence aurait dû être mentionnée mille fois. Sebastian Raschka a déclaré en réponse aux commentaires des internautes que le code « le plus original » était effectivement cohérent avec le schéma d'architecture, mais que la version du code soumise en 2017 a été modifiée, mais que le schéma d'architecture n'a pas été mis à jour en même temps. C’est aussi la cause profonde des discussions « incohérentes ».
 Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Les modèles d'apprentissage profond pour les tâches de vision (telles que la classification d'images) sont généralement formés de bout en bout avec des données provenant d'un seul domaine visuel (telles que des images naturelles ou des images générées par ordinateur). Généralement, une application qui effectue des tâches de vision pour plusieurs domaines doit créer plusieurs modèles pour chaque domaine distinct et les former indépendamment. Les données ne sont pas partagées entre différents domaines. Lors de l'inférence, chaque modèle gérera un domaine spécifique. Même s'ils sont orientés vers des domaines différents, certaines caractéristiques des premières couches entre ces modèles sont similaires, de sorte que la formation conjointe de ces modèles est plus efficace. Cela réduit la latence et la consommation d'énergie, ainsi que le coût de la mémoire lié au stockage de chaque paramètre du modèle. Cette approche est appelée apprentissage multidomaine (MDL). De plus, les modèles MDL peuvent également surpasser les modèles simples.
 Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA est basé sur l'architecture JPA et interagit avec la base de données via le mappage, l'ORM et la gestion des transactions. Son référentiel fournit des opérations CRUD et les requêtes dérivées simplifient l'accès à la base de données. De plus, il utilise le chargement paresseux pour récupérer les données uniquement lorsque cela est nécessaire, améliorant ainsi les performances.
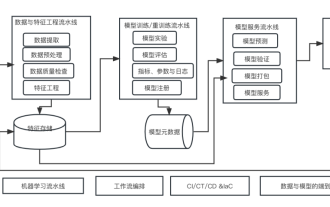 Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Nous vivons une ère d’autonomisation de l’IA, et l’apprentissage automatique est un moyen technique important pour y parvenir. Alors, existe-t-il une architecture universelle de système d’apprentissage automatique ? Dans le champ cognitif des programmeurs expérimentés, tout n'est rien, notamment pour l'architecture système. Cependant, il est possible de créer une architecture de système d'apprentissage automatique évolutive et fiable si elle est applicable à la plupart des systèmes ou cas d'utilisation basés sur l'apprentissage automatique. Du point de vue du cycle de vie du machine learning, cette architecture dite universelle couvre les étapes clés du machine learning, du développement de modèles de machine learning au déploiement de systèmes de formation et de systèmes de services dans des environnements de production. Nous pouvons essayer de décrire une telle architecture de système d’apprentissage automatique à partir des dimensions de 10 éléments. 1.
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
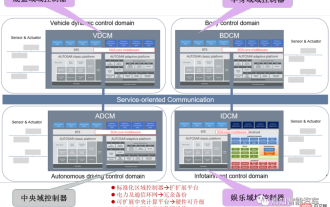 Conception d'architecture logicielle et méthodologie de découplage logiciel et matériel dans SOA
Apr 08, 2023 pm 11:21 PM
Conception d'architecture logicielle et méthodologie de découplage logiciel et matériel dans SOA
Apr 08, 2023 pm 11:21 PM
Pour la prochaine génération d'architecture électronique et électrique centralisée, l'utilisation d'une unité centrale de calcul centrale + zonale et d'une disposition de contrôleur régional est devenue une option incontournable pour divers OEM ou acteurs de niveau 1. Concernant l'architecture de l'unité centrale de calcul, il y en a trois. façons : séparation SOC, isolation matérielle, virtualisation logicielle. L'unité informatique centrale centralisée intégrera les fonctions commerciales de base des trois principaux domaines de la conduite autonome, du cockpit intelligent et du contrôle des véhicules. Le contrôleur régional standardisé a trois responsabilités principales : la distribution d'énergie, les services de données et la passerelle régionale. L’unité centrale de calcul intégrera donc un commutateur Ethernet haut débit. À mesure que le degré d'intégration de l'ensemble du véhicule devient de plus en plus élevé, de plus en plus de fonctions ECU seront lentement absorbées par le contrôleur régional. Et la plateforme
