

| Présentation | Récemment, j'ai effectué une synchronisation des journaux en temps réel. Avant de me connecter, j'ai effectué un seul test de stress de journal en ligne. Il n'y a eu aucun problème avec la file d'attente des messages, le client et la machine locale. attendez-vous à ce qu'après le téléchargement du deuxième journal, le problème soit survenu : | .
Une certaine machine au sommet du cluster a vu une charge énorme. Les machines du cluster ont la même configuration matérielle et le même logiciel déployé, mais cette machine a un problème de charge. On suppose initialement qu'il peut y avoir un problème matériel.
Dans le même temps, nous devons également découvrir le coupable de la charge anormale, puis trouver des solutions au niveau logiciel et matériel.

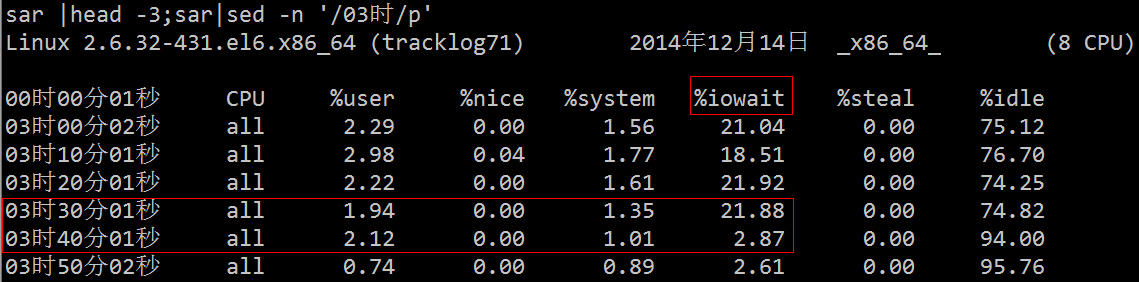
Vous pouvez voir d'en haut que la charge moyenne est élevée, %wa est élevée et %us est faible :
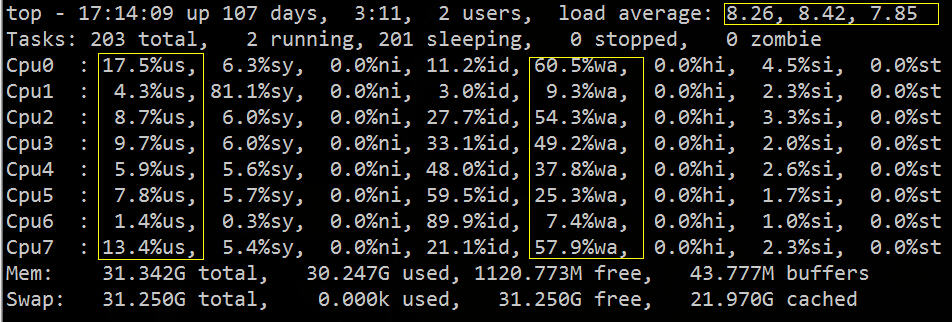
À partir de l'image ci-dessus, nous pouvons déduire grossièrement que IO a rencontré un goulot d'étranglement. Ensuite, nous pouvons utiliser les outils de diagnostic IO associés pour une vérification et un dépannage spécifiques.
Les méthodes de combinaison couramment utilisées sont les suivantes :
•Utilisez vmstat, sar, iostat pour détecter s'il s'agit d'un goulot d'étranglement du processeur
•Utilisez free et vmstat pour détecter s'il y a un goulot d'étranglement de mémoire
•Utilisez iostat et dmesg pour détecter s'il s'agit d'un goulot d'étranglement d'E/S disque
• Utilisez netstat pour détecter s'il existe un goulot d'étranglement de la bande passante du réseau.
La signification de la commande vmstat est d'afficher l'état de la mémoire virtuelle ("Virtual Memor Statics"), mais elle peut rendre compte de l'état de fonctionnement global du système tel que les processus, la mémoire, les E/S, etc.
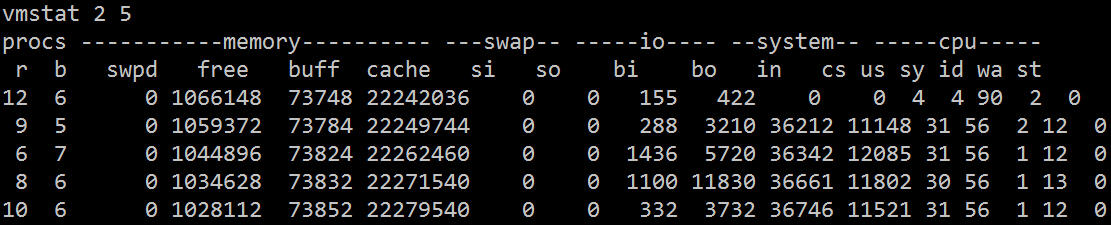
Ses champs associés sont décrits comme suit :
Procs
•r : nombre de processus dans la file d'attente d'exécution. Cette valeur peut également être utilisée pour déterminer si le processeur doit être augmenté. (long terme supérieur à 1)
•b : nombre de processus en attente d'E/S, c'est-à-dire le nombre de processus en état de veille non-interruptible, indiquant le nombre de tâches en cours d'exécution et en attente de ressources CPU. Lorsque cette valeur dépasse le nombre de processeurs, un goulot d'étranglement du processeur se produira
Mémoire
•swpd : utilisez la taille de la mémoire virtuelle. Si la valeur de swpd n'est pas 0, mais que les valeurs de SI et SO sont 0 pendant une longue période, cette situation n'affectera pas les performances du système.
•free : taille de mémoire physique libre.
•buff : La taille de la mémoire utilisée comme tampon.
• cache : La taille de la mémoire utilisée comme cache. Si la valeur du cache est grande, cela signifie qu'il y a de nombreux fichiers dans le cache. Si les fichiers fréquemment consultés peuvent être mis en cache, le bi IO lu du disque sera très petit.
Swap (zone d'échange)
•si : La taille écrite de la zone d'échange vers la mémoire par seconde, qui est transférée dans la mémoire depuis le disque.
•so : la taille de la mémoire écrite dans la zone de swap par seconde, transférée de la mémoire au disque.
Remarque : Lorsque la mémoire est suffisante, ces deux valeurs sont toutes deux 0. Si ces deux valeurs sont supérieures à 0 pendant une longue période, les performances du système seront affectées et les ressources du disque et du processeur seront affectées. être consommé. Certains amis pensent que la mémoire n'est pas suffisante lorsqu'ils voient que la mémoire libre (libre) est très petite ou proche de 0. Vous ne pouvez pas simplement regarder cela, mais aussi combiner si et ainsi s'il y a très peu de libre, il y a aussi très peu de si et donc (la plupart du temps c'est 0), alors ne vous inquiétez pas, les performances du système ne seront pas affectées pour le moment.
IO (entrée et sortie)
(La taille du bloc de la version Linux est désormais de 1 Ko)
•bi : Nombre de blocs lus par seconde
•bo : Nombre de blocs écrits par seconde
Remarque : lors de la lecture et de l'écriture de disques aléatoires, plus ces deux valeurs sont grandes (par exemple, dépasser 1 024 Ko), plus la valeur que vous pouvez voir est grande, vous pouvez voir que le processeur attend les E/S.
système
•in : nombre d'interruptions par seconde, y compris les interruptions d'horloge.
•cs : nombre de changements de contexte par seconde.
Remarque : plus les deux valeurs ci-dessus sont grandes, plus le temps CPU consommé par le noyau sera important.
CPU
(exprimé en pourcentage)
•us : Pourcentage du temps d'exécution du processus utilisateur (temps utilisateur). Lorsque notre valeur est relativement élevée, cela signifie que le processus utilisateur consomme beaucoup de temps CPU, mais si l'utilisation dépasse 50 % pendant une longue période, nous devrions alors envisager d'optimiser l'algorithme du programme ou de l'accélérer.
•sy : Pourcentage du temps d'exécution du processus système du noyau (heure système). Lorsque la valeur de sy est élevée, cela signifie que le noyau du système consomme beaucoup de ressources CPU. Ce n'est pas une performance anodine, et nous devons en vérifier la raison.
•wa : pourcentage du temps d'attente des IO. Lorsque la valeur de wa est élevée, cela signifie que l'attente d'E/S est importante. Cela peut être dû à un grand nombre d'accès aléatoires sur le disque, ou à un goulot d'étranglement (opération de blocage) sur le disque.
•id : pourcentage de temps d'inactivité
Comme le montre vmstat, la majeure partie du temps CPU est gaspillée en attendant les E/S, ce qui peut être dû à un grand nombre d'accès aléatoires au disque ou à une bande passante du disque supérieure à 1024 Ko, ce qui devrait indiquer un goulot d'étranglement des E/S.
2.2 iostatUtilisons un outil de diagnostic d'E/S de disque plus professionnel pour examiner les statistiques pertinentes.
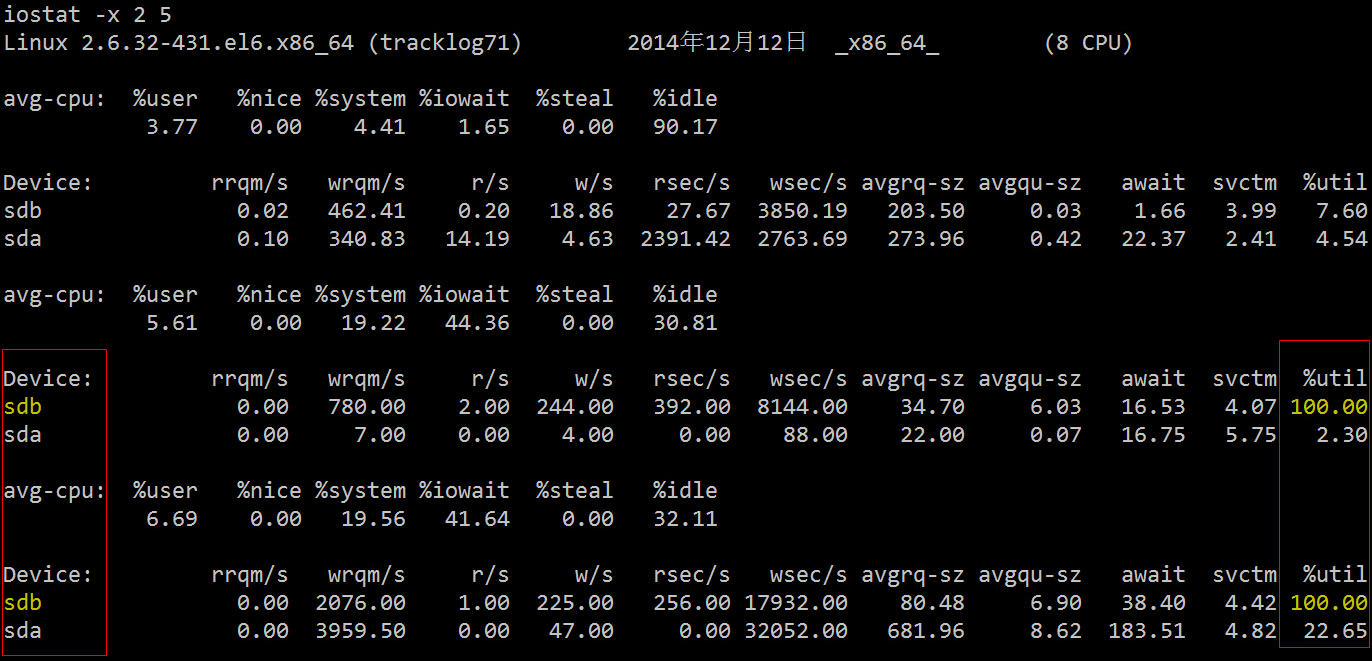
Ses champs associés sont décrits comme suit :
•rrqm/s : nombre d'opérations de lecture de fusion par seconde. C'est delta(rmerge)/s
•wrqm/s : nombre d'opérations d'écriture de fusion par seconde. C'est delta(wmerge)/s
•r/s : nombre de lectures effectuées à partir du périphérique d'E/S par seconde. C'est delta(rio)/s
•w/s : nombre d'écritures sur le périphérique d'E/S effectuées par seconde. C'est delta(wio)/s
•rsec/s : Nombre de secteurs lus par seconde. C'est delta(rsect)/s
•wsec/s : Nombre de secteurs écrits par seconde. C'est delta(wsect)/s
•rkB/s : K octets lus par seconde. Correspond à la moitié de rsect/s car la taille de chaque secteur est de 512 octets. (calcul des besoins)
•wkB/s : nombre de K octets écrits par seconde. est la moitié de wsect/s. (calcul des besoins)
•avgrq-sz : taille moyenne des données (secteurs) par opération d'E/S de périphérique. delta(rsect+wsect)/delta(rio+wio)
•avgqu-sz : longueur moyenne de la file d'attente d'E/S. C'est delta(aveq)/s/1000 (car l'unité de aveq est la milliseconde).
•wait : temps d'attente moyen (millisecondes) pour chaque opération d'E/S de périphérique. C'est delta(ruse+wuse)/delta(rio+wio)
•svctm : durée de service moyenne (millisecondes) par opération d'E/S de périphérique. C'est delta(use)/delta(rio+wio)
•%util : quel pourcentage de seconde est utilisé pour les opérations d'E/S, ou combien de secondes la file d'attente d'E/S est non vide. C'est delta(use)/s/1000 (car l'unité d'utilisation est la milliseconde)
Vous pouvez voir que le taux d'utilisation de la SDB sur les deux disques durs a atteint 100 % et qu'il existe un sérieux goulot d'étranglement d'E/S. L'étape suivante consiste à découvrir quel processus lit et écrit des données sur ce disque dur.
2.3 iotop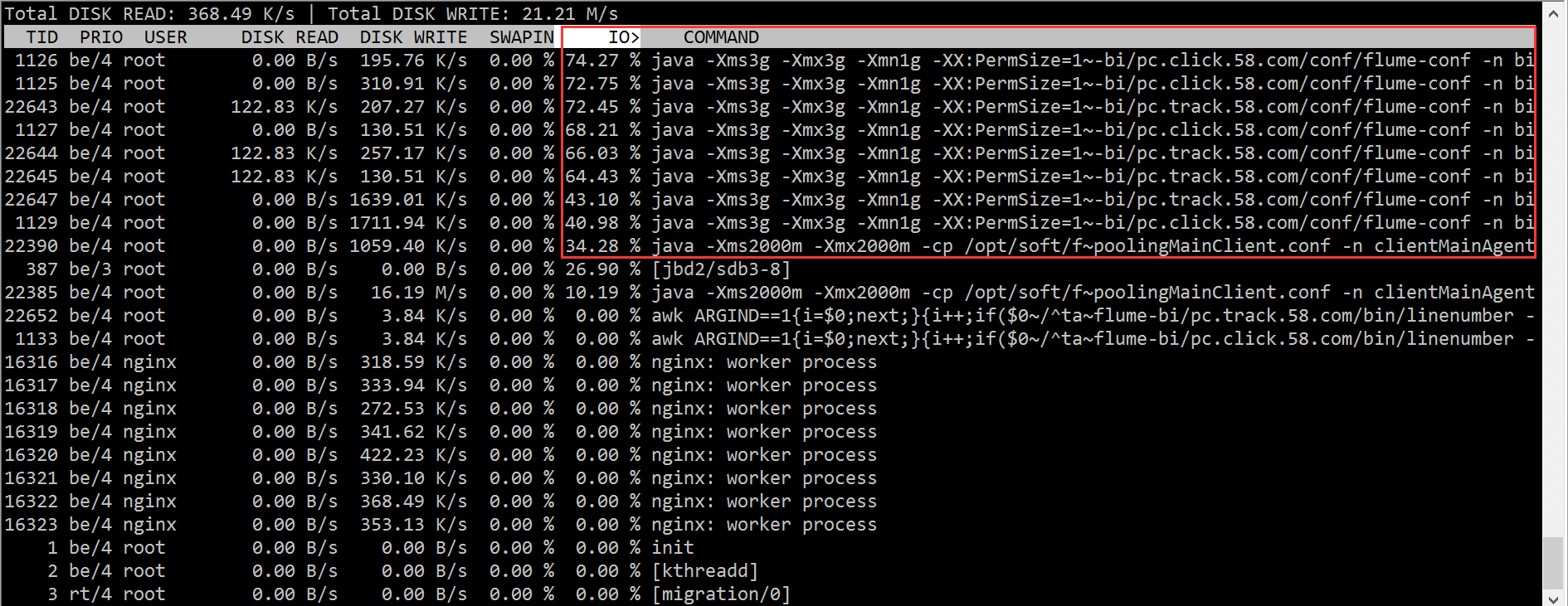
Selon les résultats d'iotop, nous avons rapidement localisé le problème avec le processus canal, qui a provoqué un grand nombre d'attentes d'E/S.
Mais comme je l'ai dit au début, les configurations des machines dans le cluster sont les mêmes, et les programmes déployés sont exactement les mêmes que ceux utilisés par rsync. Se pourrait-il que le disque dur soit cassé ?
Cela doit être vérifié par un étudiant en exploitation et maintenance. La conclusion finale est la suivante :
Sdb est un raid1 à double disque, la carte raid utilisée est "LSI Logic/Symbios Logic SAS1068E", et il n'y a pas de cache. La pression de près de 400 IOPS a atteint la limite matérielle. La carte raid utilisée par les autres machines est "LSI Logic / Symbios Logic MegaRAID SAS 1078", qui dispose d'un cache de 256 Mo et n'a pas atteint le goulot d'étranglement matériel. La solution est de remplacer la machine par une IOPS plus grande. Par exemple, nous avons finalement changé. à une machine avec PERC6 /i Machines avec cartes contrôleur RAID intégrées. Il convient de noter que les informations RAID sont stockées dans la carte RAID et dans le micrologiciel du disque. Les informations RAID sur le disque et le format des informations sur la carte RAID doivent correspondre. Sinon, la carte RAID ne peut pas les reconnaître et le disque doit l'être. formaté.
IOPS dépend essentiellement du disque lui-même, mais il existe de nombreuses façons d'améliorer les IOPS. L'ajout de cache matériel et l'utilisation de matrices RAID sont des méthodes courantes. S'il s'agit d'un scénario comme celui d'une base de données avec des IOPS élevées, il est désormais courant d'utiliser un SSD pour remplacer le disque dur mécanique traditionnel.
Mais comme mentionné précédemment, notre objectif, en partant à la fois des aspects logiciels et matériels, est de voir si nous pouvons trouver respectivement la solution la moins chère :
Maintenant que nous connaissons la raison matérielle, nous pouvons essayer de déplacer les opérations de lecture et d'écriture vers un autre disque, puis voir l'effet :
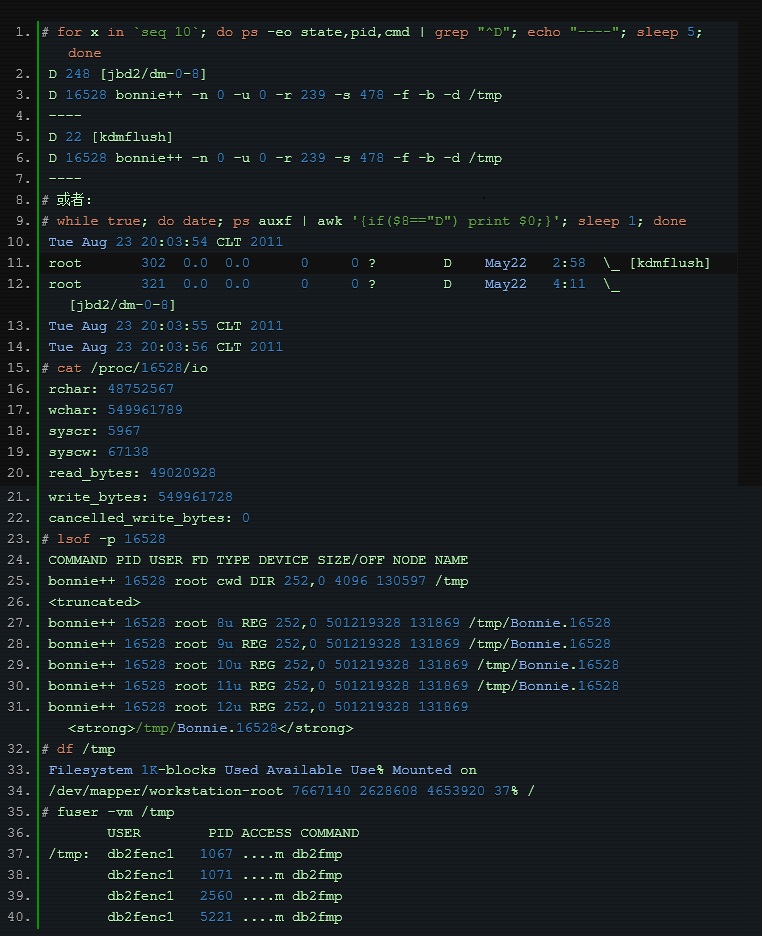
En fait, en plus d'utiliser les outils professionnels mentionnés ci-dessus pour localiser ce problème, nous pouvons directement utiliser l'état du processus pour trouver les processus pertinents.
Nous savons que le processus a les états suivants :
•D sommeil ininterrompu (généralement IO)
•R en cours d'exécution ou exécutable (dans la file d'attente d'exécution)
• S veille interrompue (en attente de la fin d'un événement)
•T arrêté, soit par un signal de contrôle de travail, soit parce qu'il est en cours de traçage.
•Paging W (non valide depuis le noyau 2.6.xx)
•X mort (ne devrait jamais être vu)
•Z processus défunt ("zombie"), terminé mais non récolté par son parent.
L'état de D est généralement ce qu'on appelle le "veille ininterrompue" provoqué par l'attente IO. Nous pouvons partir de ce point et ensuite localiser le problème étape par étape :
.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



