

Principes de base du contrôle des autorisations Linux

Cet article présente principalement les principes de base du contrôle des autorisations dans les systèmes Linux. 
Dans les systèmes Linux, toutes nos opérations sont essentiellement des processus accédant aux fichiers. Pour accéder aux fichiers, nous devons d'abord obtenir les autorisations d'accès correspondantes, et les autorisations d'accès sont obtenues via le modèle de sécurité du système Linux.
Pour le modèle de sécurité des systèmes Linux, nous devons connaître les deux points suivants :
- Le modèle de sécurité d'origine sur le système Linux s'appelle DAC, dont le nom complet est Discretionary Access Control, qui se traduit par contrôle d'accès discrétionnaire.
- Plus tard, un nouveau modèle de sécurité a été ajouté et conçu appelé MAC, dont le nom complet est Mandatory Access Control, qui se traduit par contrôle d'accès obligatoire.
Notez que MAC et DAC ne s'excluent pas mutuellement. DAC est le modèle de sécurité le plus basique et est généralement le mécanisme de contrôle d'accès le plus couramment utilisé que Linux doit avoir. MAC est un mécanisme de sécurité amélioré construit sur DAC et appartient aux modules facultatifs. Avant l'accès, les systèmes Linux effectuent généralement d'abord une vérification DAC. En cas d'échec, l'opération échoue directement ; si elle réussit la vérification DAC et que le système prend en charge le module MAC, il effectue ensuite une vérification des autorisations MAC.
Pour distinguer les deux, nous appelons le système Linux qui prend en charge MAC SELinux, ce qui signifie qu'il s'agit d'un système à sécurité renforcée pour Linux.
Ici, nous parlerons du modèle de sécurité DAC dans les systèmes Linux.
Modèle de sécurité DACLe contenu principal de DAC est le suivant : Sous Linux, un processus a théoriquement les mêmes autorisations que l'utilisateur qui l'exécute. Tout ce qui est impliqué est centré autour de ce noyau.
Contrôle des informations d'identification des utilisateurs et des groupesInformations sur l'utilisateur, le groupe et le mot de passe
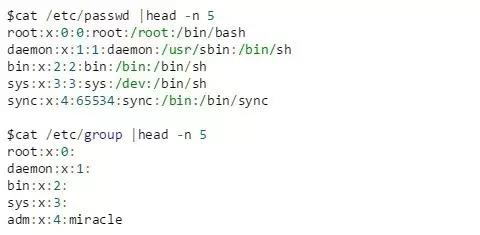
Enregistrez les informations sur les utilisateurs et les groupes via /etc/passwd et /etc/group, et enregistrez les mots de passe et leurs informations de modification via /etc/shadow, avec un enregistrement par ligne.
Les utilisateurs et les groupes sont représentés respectivement par UID et GID. Un utilisateur peut appartenir à plusieurs groupes en même temps. Par défaut, chaque utilisateur doit appartenir à un GID avec le même UID et le même nom.
Pour /etc/passwd, chaque champ d'enregistrement est le nom d'utilisateur : Mot de passe (crypté et enregistré dans /etc/shadow) : UID : GID (UID par défaut) : Commentaire de description : Répertoire personnel : Shell de connexion (le premier programme en cours d'exécution)
Pour /etc/group, les champs de chaque enregistrement sont : Nom du groupe : Mot de passe (généralement il n'y a pas de mot de passe de groupe) : GID : Liste des utilisateurs des membres du groupe (liste des UID des utilisateurs séparés par des virgules)
Pour /etc/shadow, les champs de chaque enregistrement sont : Nom de connexion : Mot de passe crypté : Heure de la dernière modification : Intervalle de temps minimum : Intervalle de temps maximum : Temps d'avertissement : Temps d'inactivité :
Exemple
Voici des exemples d'informations sur les utilisateurs et les groupes. Les informations de mot de passe dans /etc/shadow sont cryptées et stockées, aucun exemple n'est fourni.
Type de fichier
Les types de fichiers sous Linux sont les suivants :
- Les fichiers ordinaires, y compris les fichiers texte et les fichiers binaires, peuvent être créés au toucher ; Le fichier socket, utilisé pour la communication réseau, est généralement créé indirectement par l'application lors de l'exécution
- ; Le fichier pipe est un tube nommé, pas un tube sans nom, et peut être créé avec mkfifo ;
- Les fichiers de caractères et les fichiers de blocs sont tous deux des fichiers de périphérique et peuvent être créés avec mknod ;
- Le fichier de lien est un fichier de lien logiciel, pas un fichier de lien physique, et peut être créé avec ln.
Groupe de contrôle d'accès
Divisé en trois groupes pour le contrôle :
- l'utilisateur contient les autorisations définies pour le propriétaire du fichier
- group contient les autorisations définies pour le groupe de fichiers
- others inclut les autorisations définies pour les autres
Autorisations configurables
Les valeurs d'autorisation courantes (mais pas toutes) sont indiquées ci-dessous, notamment :
- r signifie autorisation de lecture.
- w signifie autorisation d'écriture.
- x est généralement destiné aux fichiers/répertoires exécutables, indiquant qu'il dispose d'autorisations d'exécution/de recherche.
- s concerne généralement les fichiers/répertoires exécutables, indiquant qu'il a l'autorisation d'accorder les autorisations au propriétaire du fichier. Seuls les groupes d'utilisateurs et de groupes peuvent définir cette autorisation.
- Généralement pour les répertoires, après avoir défini le sticky bit, les utilisateurs disposant d'autorisations ne peuvent écrire et supprimer que leurs propres fichiers, sinon ils peuvent écrire et supprimer tous les fichiers du répertoire. L'ancien système signifie également qu'une fois le fichier exécutable exécuté, le texte est copié dans la zone d'échange pour améliorer la vitesse.
Exemple
Vous pouvez vérifier son type de fichier et ses autorisations via ls -l, et modifier les autorisations via chmod.Par exemple,
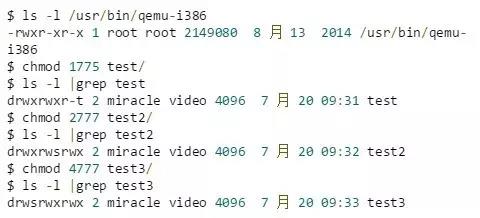
Dans la sortie, le premier caractère indique le type de fichier, y compris le fichier ordinaire (-), le fichier de répertoire (d), le ou les fichiers socket, le fichier pipe (p), le fichier de caractères (c) et le fichier de bloc (b). , fichier de lien (l); La partie -rwxr-xr-x à partir du deuxième caractère représente le bit d'autorisation du fichier, avec un total de 9 bits.
Pour le fichier /usr/bin/qemu-i386, la signification de ce contrôle d'autorisation est :
- Le rwx dans les bits 2 à 4 indique que le fichier est accessible par son propriétaire avec les autorisations r, w ou x.
- Le r-x aux positions 5 à 7 indique que le fichier est accessible aux utilisateurs du même groupe que le fichier avec les autorisations r ou x
- Le rx dans les bits 8 à 10 signifie que le fichier est accessible à d'autres utilisateurs inconnus avec les autorisations r ou x.
Autorisations définies pour test/, test2/, test3/ :
- Les autorisations r,w,x pour chaque groupe de contrôle d'autorisation sont représentées par un chiffre octal, par exemple : 755 représente rwxr-xr-x ;
- l'autorisation s,t sera affichée à la place de la position x ; pour définir l'autorisation s,t, vous devez ajouter un numéro avant que le groupe de contrôle d'autorisation octal correspondant utilisé pour contrôler l'autorisation r,w,x ne soit utilisé pour le groupe propriétaire ; contrôle, t est utilisé pour d’autres contrôles.
- Pour définir les propriétaires, ajoutez 4, pour définir les groupes, ajoutez 2 et pour définir l'autorisation des autres t, ajoutez 1 ; par exemple, lors de la définition de t pour test/plus tôt, utilisez 1775, ce qui signifie rwxrwxr-t .
Autorisations de processus
Pour les processus, les attributs suivants sont liés aux autorisations d'accès aux fichiers :
- ID utilisateur effectif : UID lié aux autorisations d'accès aux fichiers de processus (en abrégé euid).
- ID de groupe effectif : GID lié aux autorisations d'accès aux fichiers de processus (en abrégé egid).
- ID utilisateur réel : L'UID (en abrégé ruid) de l'utilisateur qui a créé le processus lors de la connexion au système.
- identifiant de groupe réel : le GID (en abrégé rgid) de l'utilisateur qui a créé le processus lors de la connexion au système.
- ID utilisateur défini enregistré : copié à partir de l'euid.
- ID de groupe enregistré : copié depuis egid.
Exemple
Nous pouvons utiliser ps et top pour sélectionner et afficher les processus avec euid et ruid. Ou utilisez top pour afficher l'euid et le ruid du processus
Exemple vu en haut :
Entrez d'abord en haut pour obtenir quelque chose comme ce qui suit
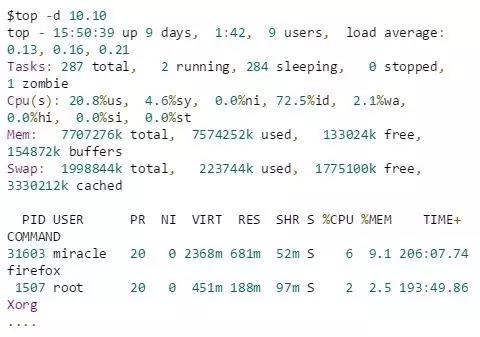
Ici, l'option -d est utilisée pour étendre la fréquence de rafraîchissement de top pour faciliter l'utilisation. Comme on peut le voir ici, seul le champ USER représente l'identifiant utilisateur effectif du processus correspondant.
Ouvrez les options d'affichage de la lecture de l'identifiant utilisateur :
a. Pendant que la commande top est en cours d'exécution, entrez f et vous verrez une ligne similaire à la suivante :
b. Entrez c pour activer le commutateur d'affichage du nom d'utilisateur réel.
c. Enfin, appuyez sur Retour pour revenir en haut et vous verrez l'option d'identification réelle de l'utilisateur. Entrez « o » à ce moment pour ajuster l'ordre des colonnes. Enfin, nous pouvons voir le résultat incluant « l'identifiant d'utilisateur effectif » et « l'identifiant d'utilisateur réel » comme suit :
Stratégie de contrôle des autorisations pour les fichiers d'accès aux processusRègles
Stratégie de contrôle approximatif des autorisations pour les fichiers d'accès aux processus
Pour un processus d'accès aux fichiers, la chose la plus importante est euid, donc ses attributs d'autorisation sont tous centrés sur euid.
- L'euid d'un processus prend généralement par défaut sa valeur ruid
- Si le bit d'autorisation exécutable du fichier exécutable est s, une fois que le processus a appelé exec dessus, son euid est défini sur l'identifiant utilisateur du fichier exécutable
- L'ID utilisateur défini enregistré du processus est copié à partir de euid.
- Lorsque l'euid du processus correspond à l'identifiant utilisateur du fichier, le processus ne dispose que des autorisations définies par le bit d'autorisation utilisateur du fichier
- Les règles de contrôle des autorisations de groupe egid sont similaires.
Modifier les attributs d'autorisation via l'exécution du fichier exécutable
Lors de l'appel d'un fichier exécutable via exec :
- La valeur du processus reste toujours inchangée ;
- l'ID utilisateur défini enregistré provient toujours de l'euid ; La valeur
- euid dépend de la définition ou non du bit set-user-ID du fichier.
Comme suit :
Modifier les attributs d'autorisation via l'appel système setuid(uid)
Lors de la modification des attributs d'autorisation via setuid(uid) :
- le superutilisateur peut modifier en douceur ruid, euid, l'ID utilisateur défini enregistré ;
- un utilisateur non privilégié ne peut modifier euid que lorsque uid et ruid sont égaux, sinon il ne peut pas être modifié.
Exemple
Quelques exemples particuliers supplémentaires :
set-user-id

Comme mentionné précédemment, la signification de cette sortie est que, pour le fichier /usr/bin/sudo,
- Les rws dans les bits 1 à 3 signifient que le fichier est accessible par son propriétaire avec les autorisations r, w ou s
- Le rx dans les bits 4 à 6 indique que le fichier est accessible aux utilisateurs du même groupe que le fichier avec les autorisations r ou x.
- Le rx dans les bits 7 à 9 indique que le fichier est accessible à d'autres utilisateurs inconnus avec les autorisations r ou x.
Après ce paramètre, le propriétaire dispose des autorisations de lecture, d'écriture et d'exécution, ce qui n'est pas différent. Mais pour les processus utilisateur ordinaires qui n’appartiennent pas au groupe racine, c’est très différent.
Lorsqu'un processus utilisateur ordinaire exécute la commande sudo, il obtient les autorisations d'exécution via le x dans les autres, puis utilise le s dans l'utilisateur pour disposer temporairement des autorisations du propriétaire (racine) du fichier exécutable sudo, c'est-à-dire des super autorisations .
C'est également pourquoi les utilisateurs ordinaires peuvent exécuter de nombreuses commandes avec des privilèges d'administrateur via la commande sudo.
installer le stick-bit

Après ce paramètre, tout le monde dispose d'autorisations de lecture, d'écriture et d'exécution pour le répertoire /tmp, ce qui n'est pas différent. Cependant, le sticky bit t est placé dans l'autre partie, et sa fonction est tout à fait différente.
Si le répertoire n'a pas le sticky bit défini, toute personne disposant d'autorisations d'écriture sur le répertoire peut supprimer tous les fichiers et sous-répertoires qu'il contient, même si elle n'est pas le propriétaire du fichier correspondant et n'a pas d'autorisation de lecture ou d'écriture après le répertoire ; sticky bit est défini, l'utilisateur peut Seuls les fichiers et sous-répertoires lui appartenant peuvent être écrits ou supprimés.
C'est pourquoi n'importe qui peut écrire des fichiers et des répertoires dans le répertoire /tmp, mais ne peut écrire et supprimer que les fichiers ou répertoires qui lui appartiennent.
Citer un fragment d'application du programme man pour décrire l'utilisation de set-user-id et du set-user-id enregistré
Le programme man peut être utilisé pour afficher les manuels d'aide en ligne. Le programme man peut être installé pour spécifier set-user-ID ou set-group-ID pour un utilisateur ou un groupe spécifié.
Le programme man peut lire ou écraser des fichiers à certains emplacements, ce qui est généralement configuré par un fichier de configuration (généralement /etc/man.config ou /etc/manpath.config) ou des options de ligne de commande.
Le programme man peut exécuter d'autres commandes pour traiter le fichier contenant la page de manuel affichée.
Pour éviter les erreurs de traitement, man bascule entre deux privilèges : les privilèges de l'utilisateur exécutant la commande man et les privilèges du propriétaire du programme man.
Le fil conducteur à comprendre : lorsque seul man est exécuté, les privilèges du processus sont les privilèges de l'utilisateur man. Lorsqu'un processus enfant est exécuté via man (comme une commande shell via !bash), l'utilisateur passe à l'utilisateur actuel et revient après l'exécution.
Le processus est le suivant :
- Supposons que le fichier programme man appartient à l'utilisateur man et que son bit set-user-ID soit activé. Lorsque nous l'exécutons, nous nous trouvons dans la situation suivante :
– ID utilisateur réel = notre UID utilisateur
– ID utilisateur effectif = UID utilisateur homme
– set-user-ID enregistré = man user UID - Le programme man accédera aux fichiers de configuration et aux pages de manuel requis. Ces fichiers appartiennent à l'utilisateur man, mais comme l'ID utilisateur effectif est man, l'accès aux fichiers est autorisé.
- Lorsque man exécute une commande pour nous, il appellera setuid(getuid())) (getuid() renvoie le véritable identifiant d'utilisateur).
Parce que nous ne sommes pas le processus superutilisateur, ce changement ne peut changer que l'ID utilisateur effectif. Nous aurons la situation suivante :
. Désormais, lorsque le processus man s'exécute, il utilise notre UID comme identifiant utilisateur effectif. Cela signifie que nous ne pouvons accéder qu'aux fichiers pour lesquels nous disposons de nos propres autorisations. Autrement dit, il peut exécuter en toute sécurité n’importe quel filtre en notre nom.
– ID utilisateur réel = notre UID utilisateur (ne sera pas modifié)
– ID utilisateur effectif = notre UID utilisateur
– set-user-ID enregistré = UID utilisateur de l'homme (ne sera pas modifié) - Lorsque le filtre est terminé, l'homme appellera setuid (euid).
Ici, euid est l'UID de l'utilisateur man. (Cet ID est enregistré par man appelant geteuid.) Cet appel est OK car le paramètre setuid est égal à l'ID set-user-ID enregistré. (C'est pourquoi nous avons besoin d'un set-user-ID enregistré. À ce stade, nous aurons la situation suivante :
). – ID utilisateur réel = notre UID utilisateur (ne sera pas modifié)
– ID utilisateur effectif = UID de l’homme
– set-user-ID enregistré = UID utilisateur de l'homme (ne sera pas modifié) - Puisque l'ID utilisateur effectif est man, le programme man peut désormais gérer ses propres fichiers.
En utilisant l'ID utilisateur défini de cette manière, nous pouvons utiliser des autorisations supplémentaires via l'ID utilisateur défini du fichier programme lorsque le processus démarre et se termine. Cependant, pendant cette période, nous opérions sous notre propre autorité. Si nous ne parvenons pas à revenir à l'ID utilisateur défini enregistré à la fin, nous pouvons conserver des autorisations supplémentaires pendant l'exécution.
Jetons un coup d'oeil à ce qui se passera si l'homme démarre une coquille :
- Le shell ici est démarré par l'homme à l'aide de fork et exec.
- Parce qu'à l'heure actuelle, l'ID utilisateur réel et l'ID utilisateur effectif sont tous deux nos UID utilisateur ordinaires (voir étape 3), le shell n'a donc aucune autre autorisation supplémentaire.
- Le shell démarré ne peut pas accéder à l'ID d'utilisateur (man) enregistré de man, car l'ID d'utilisateur enregistré du shell est copié à partir de l'ID d'utilisateur effectif par exec.
- Dans le processus enfant (shell) exécutant exec, tous les identifiants utilisateur sont nos identifiants utilisateur ordinaires.
En fait, la façon dont nous décrivons comment man utilise la fonction setuid n'est pas particulièrement correcte, car le programme peut définir l'ID utilisateur sur root À ce stade, setuid changera les trois uid en l'identifiant que vous avez défini, mais nous n'en avons besoin que. Définissez un identifiant utilisateur efficace.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
CentOS a été interrompu, les alternatives comprennent: 1. Rocky Linux (meilleure compatibilité); 2. Almalinux (compatible avec CentOS); 3. Serveur Ubuntu (configuration requise); 4. Red Hat Enterprise Linux (version commerciale, licence payante); 5. Oracle Linux (compatible avec Centos et Rhel). Lors de la migration, les considérations sont: la compatibilité, la disponibilité, le soutien, le coût et le soutien communautaire.
 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Une fois CentOS arrêté, les utilisateurs peuvent prendre les mesures suivantes pour y faire face: sélectionnez une distribution compatible: comme Almalinux, Rocky Linux et CentOS Stream. Migrez vers les distributions commerciales: telles que Red Hat Enterprise Linux, Oracle Linux. Passez à Centos 9 Stream: Rolling Distribution, fournissant les dernières technologies. Sélectionnez d'autres distributions Linux: comme Ubuntu, Debian. Évaluez d'autres options telles que les conteneurs, les machines virtuelles ou les plates-formes cloud.
 Que faire si l'image Docker échoue
Apr 15, 2025 am 11:21 AM
Que faire si l'image Docker échoue
Apr 15, 2025 am 11:21 AM
Dépannage des étapes pour la construction d'image Docker échouée: cochez la syntaxe Dockerfile et la version de dépendance. Vérifiez si le contexte de construction contient le code source et les dépendances requis. Affichez le journal de construction pour les détails d'erreur. Utilisez l'option - cibler pour créer une phase hiérarchique pour identifier les points de défaillance. Assurez-vous d'utiliser la dernière version de Docker Engine. Créez l'image avec --t [Image-Name]: Debug Mode pour déboguer le problème. Vérifiez l'espace disque et assurez-vous qu'il est suffisant. Désactivez SELINUX pour éviter les interférences avec le processus de construction. Demandez de l'aide aux plateformes communautaires, fournissez Dockerfiles et créez des descriptions de journaux pour des suggestions plus spécifiques.
 Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Vs Code Système Exigences: Système d'exploitation: Windows 10 et supérieur, MacOS 10.12 et supérieur, processeur de distribution Linux: minimum 1,6 GHz, recommandé 2,0 GHz et au-dessus de la mémoire: minimum 512 Mo, recommandée 4 Go et plus d'espace de stockage: Minimum 250 Mo, recommandée 1 Go et plus d'autres exigences: connexion du réseau stable, xorg / wayland (Linux) recommandé et recommandée et plus
