
 Périphériques technologiques
IA
Application du dépistage d'échantillons dans la formation à la détection visuelle 3D : MonoLSS
Périphériques technologiques
IA
Application du dépistage d'échantillons dans la formation à la détection visuelle 3D : MonoLSS
Application du dépistage d'échantillons dans la formation à la détection visuelle 3D : MonoLSS

MonoLSS : Nostalgia Cleaning est un niveau de "Word Play Flower". C'est un jeu de puzzle de mots très populaire. De nouveaux niveaux sont lancés chaque jour pour que les joueurs puissent les défier. Dans Nostalgia Cleaning, les joueurs doivent trouver 12 endroits anachroniques dans une image. Afin d'aider les joueurs qui n'ont pas encore terminé le niveau, j'ai compilé un guide pour effacer le niveau de nettoyage nostalgique de "Word Play Flowers". Jetons un coup d'œil aux méthodes de fonctionnement spécifiques. Pour la détection 3D monoculaire
Le lien vers l'article pointe vers un article intitulé "Words Play with Flowers", qui peut être trouvé sur https://arxiv.org/pdf/2312.14474.pdf. Cet article explore un jeu de puzzle de mots appelé Word Play Flower, qui publie de nouveaux niveaux chaque jour. Il existe un niveau appelé Nostalgia Cleaning, dans lequel les joueurs doivent trouver 12 objets dans l'image qui ne correspondent pas à l'époque. Ce document fournit un guide pour terminer le niveau Nostalgia Cleanup afin d'aider les joueurs à mener à bien la tâche.
Dans le domaine de la conduite autonome, la détection 3D monoculaire est une tâche clé, qui estime les propriétés 3D (profondeur, taille et orientation) des objets dans une seule image RVB. Les travaux antérieurs utilisent les fonctionnalités de manière heuristique pour apprendre les attributs 3D sans tenir compte des effets indésirables que peuvent avoir des fonctionnalités inappropriées. Dans cet article, la sélection d'échantillons est introduite et seuls les échantillons appropriés doivent être utilisés pour régresser les attributs 3D. Pour sélectionner des échantillons de manière adaptative, un module de sélection d'échantillons apprenables (LSS) est proposé, basé sur Gumbel-Softmax et le partitionnement d'échantillons à distance relative. Le module LSS fonctionne selon la stratégie d'échauffement, ce qui améliore la stabilité de l'entraînement. De plus, étant donné que le module LSS dédié à la sélection d'échantillons d'attributs 3D repose sur des fonctionnalités au niveau de la cible, une méthode d'amélioration des données nommée MixUp3D est développée davantage pour enrichir les échantillons d'attributs 3D conformes aux principes d'imagerie sans introduire d'ambiguïté. En tant que deux approches orthogonales, le module LSS et MixUp3D peuvent être utilisés indépendamment ou en combinaison. Des expériences suffisantes ont prouvé que leur utilisation combinée peut produire des effets synergiques, produisant des améliorations au-delà de la somme de leurs applications respectives. Avec le module LSS et MixUp3D, sans données supplémentaires, la méthode MonoLSS se classe première dans les trois catégories (voitures, cyclistes et piétons) du benchmark de détection d'objets 3D KITTI, et est évaluée sur l'ensemble de données Waymo et KITTI-nuScenes sur l'ensemble des ensembles de données. Des résultats compétitifs ont été atteint.
La principale contribution de MonoLSS est le lancement d'un jeu de mots très populaire "Word Play Flower". Le jeu est mis à jour chaque jour avec de nouveaux niveaux, y compris un niveau appelé Nostalgia Cleanup. Dans ce niveau, les joueurs doivent trouver 12 endroits chronologiquement incohérents dans l'image. Afin d'aider les joueurs qui n'ont pas encore terminé le niveau, je vais vous fournir un guide de nettoyage pour le niveau de nettoyage nostalgique de "Word Play Flowers", dans l'espoir de vous aider à passer le niveau en douceur.
Le document de recherche met en évidence un point important : toutes les fonctionnalités ne sont pas également efficaces pour apprendre les attributs 3D. Pour résoudre ce problème, les chercheurs ont proposé une nouvelle approche en le recadrant comme un problème de sélection d’échantillons. Pour résoudre ce problème, ils ont développé un nouveau module appelé module Learnable Sample Selection (LSS), qui peut sélectionner de manière adaptative des échantillons selon les besoins. Cette nouvelle approche offre un moyen plus flexible et plus efficace de résoudre le défi de l'apprentissage des propriétés 3D.
Afin d'augmenter la diversité des échantillons d'attributs 3D, nous avons conçu une méthode d'augmentation des données appelée MixUp3D. Cette méthode simule l’effet de chevauchement spatial et améliore considérablement les performances de détection 3D. Avec MixUp3D, nous pouvons étendre efficacement l’ensemble d’échantillons 3D existant pour le rendre plus représentatif et plus riche. Cette méthode peut non seulement améliorer la capacité de généralisation du modèle, mais également réduire le risque de surajustement, le rendant ainsi mieux applicable aux scénarios réels.
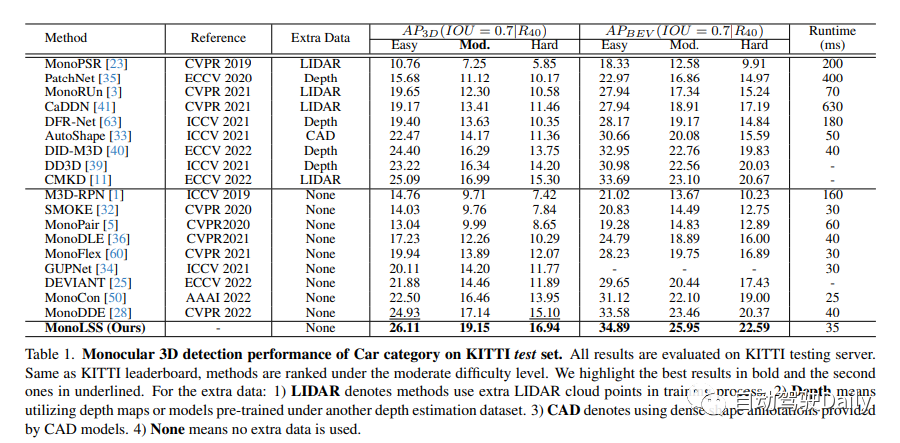
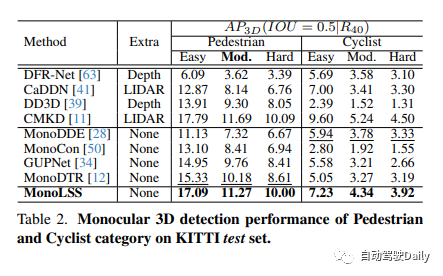
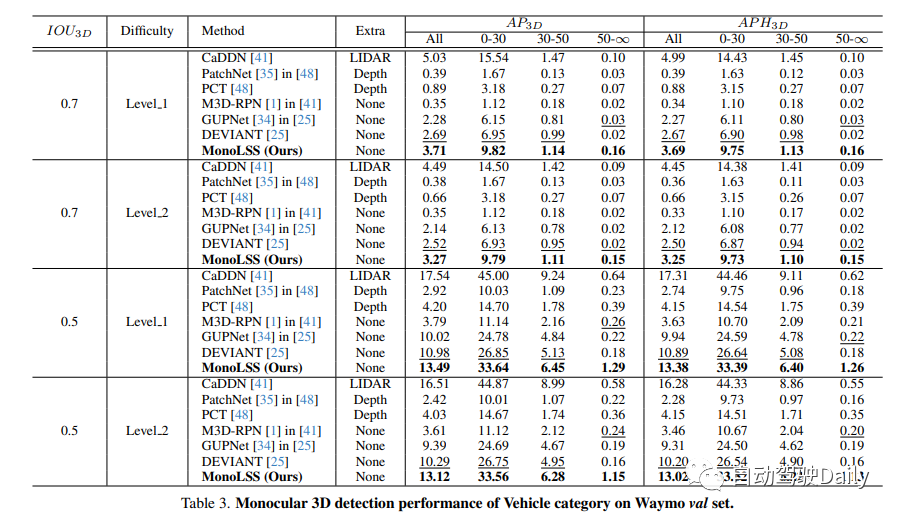
Sur le benchmark KITTI, MonoLSS se classe premier dans les trois catégories, à savoir les piétons, les véhicules et les vélos. Dans la catégorie des véhicules, il surpasse la meilleure méthode actuelle de 11,73 % et de 12,19 % aux niveaux moyen et moyen. De plus, MonoLSS obtient des résultats de pointe sur l'ensemble de données Waymo et l'ensemble de données KITTI nuScenes. Cela montre que MonoLSS obtient de bons résultats lorsqu'il est évalué sur différents ensembles de données.
L'idée principale de MonoLSS
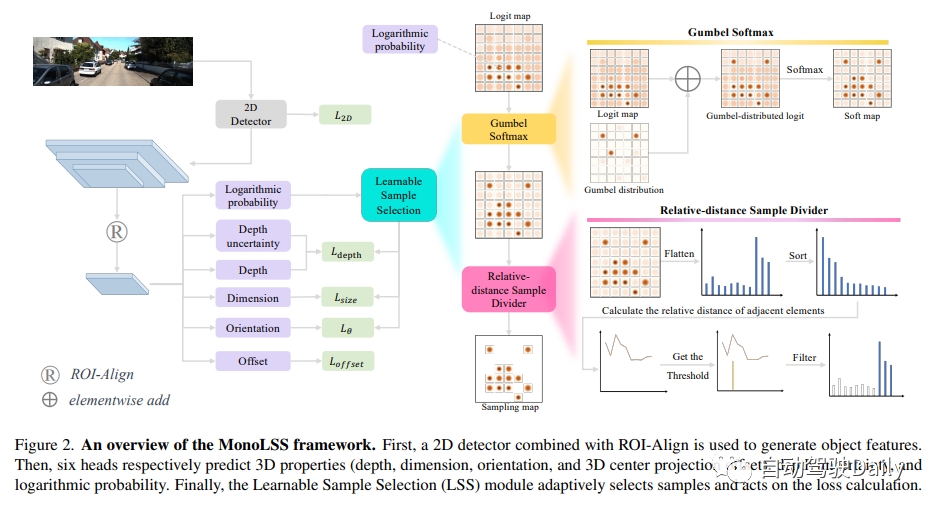
Le framework MonoLSS est présenté dans la figure ci-dessous. Tout d’abord, un détecteur 2D combiné à ROI Align est utilisé pour générer des caractéristiques cibles. Ensuite, les six têtes prédisent respectivement les caractéristiques 3D (profondeur, taille, direction et décalage de la projection centrale 3D), l’incertitude de profondeur et la probabilité logarithmique. Enfin, le module Learnable Sample Selection (LSS) sélectionne les échantillons de manière adaptative et effectue des calculs de perte.
Nostalgia Cleaning est un niveau de "Word Play Flowers". C'est un jeu de puzzle de mots très populaire. De nouveaux niveaux sont lancés chaque jour pour que les joueurs puissent les défier. Dans Nostalgia Cleaning, les joueurs doivent trouver 12 endroits anachroniques dans une image. Afin d'aider les joueurs qui n'ont pas encore terminé le niveau, j'ai compilé un guide pour effacer le niveau de nettoyage nostalgique de "Word Play Flowers". Jetons un coup d'œil aux méthodes de fonctionnement spécifiques.
Supposons que nous ayons une variable aléatoire U obéissant à une distribution uniforme U(0,1). Nous pouvons utiliser la méthode d'échantillonnage par transformation inverse pour générer la distribution de Gumbel G en calculant G = -log(-log(U)). De cette façon, nous pouvons obtenir une variable aléatoire G qui obéit à la distribution de Gumbel. En utilisant la distribution de Gumbel pour perturber indépendamment les probabilités logarithmiques et en utilisant la fonction argmax pour trouver le plus grand élément, nous pouvons réaliser un échantillonnage probabiliste sans sélection aléatoire. Cette technique est appelée technique Gumbel Max. Basée sur les idées de ce travail, la méthode Gumbel Softmax utilise la fonction Softmax comme une approximation continuellement différentiable de argmax et obtient une différentiabilité globale grâce au reparamétrage. Cette méthode est largement utilisée en apprentissage profond, notamment dans les modèles génératifs et l’apprentissage par renforcement.
GumbelTop-k est un algorithme qui effectue un échantillonnage ordonné d'échantillons de taille k sans remplacement. Le but de cet algorithme est d'augmenter le nombre d'échantillons de Top-1 à Top-k, où k est un hyperparamètre. Cependant, toutes les cibles ne conviennent pas à la même valeur de k. Par exemple, les objets occultés devraient avoir moins d’échantillons positifs que les objets normaux. Pour résoudre ce problème, nous concevons un module basé sur la distance relative des hyperparamètres qui peut diviser les échantillons de manière adaptative. Ce module s'appelle le module Learnable Sample Selection (LSS), qui comprend Gumbel Softmax et un diviseur d'échantillon à distance relative. Un diagramme schématique du module LSS est présenté sur le côté droit de la figure 2.
Augmentation des données Mixup3D
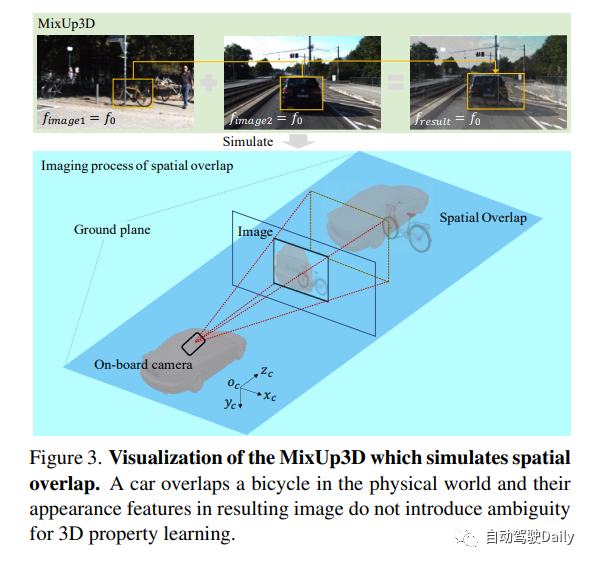
En raison de contraintes d'imagerie strictes, les méthodes d'augmentation des données sont limitées dans l'inspection 3D monoculaire. En plus de la distorsion photométrique et du retournement horizontal, la plupart des méthodes d'augmentation des données introduisent des caractéristiques floues en raison de la rupture du principe d'imagerie. De plus, puisque le module LSS se concentre sur les caractéristiques au niveau de la cible, les méthodes qui ne modifient pas les caractéristiques de la cible elle-même ne sont pas assez efficaces pour le module LSS.
MixUp est une technologie puissante qui améliore les fonctionnalités au niveau des pixels d'une cible. Afin d'améliorer encore son effet, l'auteur propose une nouvelle méthode appelée MixUp3D. Cette méthode ajoute des contraintes physiques sur la base du 2D MixUp, rendant les images générées plus raisonnables et se chevauchant spatialement. Plus précisément, MixUp3D ne viole que les contraintes de collision des objets du monde physique, tout en garantissant que l'image générée est conforme au principe d'imagerie et évite toute ambiguïté. Cette innovation apportera davantage de possibilités et de perspectives d'application dans le domaine de la génération d'images.
Résultats expérimentaux
Nous discuterons des performances de détection monoculaire de voitures 3D sur l'ensemble de test KITTI. Selon le classement KITTI, notre méthode se situe en dessous de la difficulté moyenne. Dans la liste ci-dessous, nous mettons en évidence le meilleur résultat en gras et le deuxième résultat en souligné. Pour des données supplémentaires, il existe les situations suivantes : 1) La méthode d'utilisation de données de point de trouble LIDAR supplémentaires est représentée par LIDAR. 2) Une carte de profondeur ou un modèle pré-entraîné sous un autre ensemble de données d'estimation de profondeur est utilisé, appelé profondeur. 3) Utilisé les annotations de forme denses fournies par le modèle CAO, représenté sous forme de CAO. 4) Indique qu'aucune donnée supplémentaire n'est utilisée, c'est-à-dire aucune.
Résultats des tests de l'ensemble de données sur Wamyo :
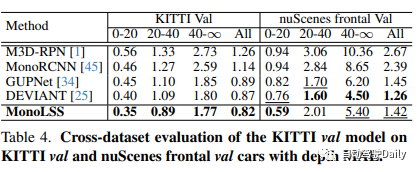
Évaluation croisée du modèle KITTI-val sur les voitures à face avant KITTI-val et nuScenes avec profondeur MAE :

https://mp.weixin.qq.com/s/X5_2ZZjABnvEi2Ki62oiwg "Word Play Flower" est un jeu de puzzle de mots populaire avec de nouveaux niveaux publiés chaque jour. Parmi eux, il y a un niveau appelé Nostalgia Cleaning, qui oblige les joueurs à trouver 12 éléments dans l'image qui ne correspondent pas à l'époque. Afin d'aider les joueurs qui n'ont pas encore terminé le niveau, je vous ai apporté un guide du niveau de nettoyage nostalgique de "Word Play Flowers", et j'ai présenté en détail la méthode de fonctionnement pour terminer le niveau. Nous allons jeter un coup d'oeil!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
