
 Tutoriel système
Linux
Réseaux de neurones préférés pour l'application aux données de séries chronologiques
Tutoriel système
Linux
Réseaux de neurones préférés pour l'application aux données de séries chronologiques
Réseaux de neurones préférés pour l'application aux données de séries chronologiques

| Présentation | Cet article présente brièvement le processus de développement du réseau neuronal récurrent RNN et analyse l'algorithme de descente de gradient, la rétropropagation et le processus LSTM. |
Avec le développement de la science et de la technologie et l'amélioration substantielle des capacités informatiques du matériel, l'intelligence artificielle est soudainement apparue aux yeux des gens après des décennies de travail en coulisses. L’épine dorsale de l’intelligence artificielle repose sur le support du Big Data, du matériel haute performance et d’excellents algorithmes. En 2016, l’apprentissage profond est devenu un mot brûlant dans les recherches Google. Avec la victoire d’AlphaGo sur le champion du monde de Go dans la bataille homme-machine au cours des deux dernières années, les gens ont le sentiment qu’ils ne peuvent plus résister aux progrès rapides de l’IA. En 2017, l'IA a fait des percées et des produits connexes sont également apparus dans la vie des gens, comme les robots intelligents, les voitures sans conducteur et la recherche vocale. Récemment, la Conférence mondiale sur l'intelligence s'est tenue avec succès à Tianjin. Lors de la conférence, de nombreux experts de l'industrie et entrepreneurs ont exprimé leur point de vue sur l'avenir. On peut comprendre que la plupart des entreprises technologiques et des instituts de recherche sont très optimistes quant aux perspectives de l'intelligence artificielle. Par exemple, Baidu le fera. Toute sa richesse repose sur l'intelligence artificielle, peu importe s'il devient célèbre ou échoue après tout, tant qu'il ne gagne rien. Pourquoi l’apprentissage profond a-t-il soudainement un tel impact et un tel engouement ? En effet, la technologie change la vie et de nombreuses professions pourraient être lentement remplacées par l’intelligence artificielle à l’avenir. Tout le monde parle d’intelligence artificielle et de deep learning. Même Yann LeCun ressent la popularité de l’intelligence artificielle en Chine
!
Pour en revenir au sujet, derrière l'intelligence artificielle se cachent le big data, d'excellents algorithmes et un support matériel doté de puissantes capacités informatiques. Par exemple, NVIDIA se classe au premier rang des cinquante entreprises les plus intelligentes au monde grâce à ses solides capacités de recherche et de développement de matériel et à sa prise en charge des cadres d'apprentissage profond. De plus, il existe de nombreux excellents algorithmes d'apprentissage en profondeur, et un nouvel algorithme apparaîtra de temps en temps, ce qui est vraiment éblouissant. Mais la plupart d’entre eux sont améliorés sur la base d’algorithmes classiques, tels que les réseaux de neurones convolutifs (CNN), les réseaux de croyances profondes (DBN), les réseaux de neurones récurrents (RNN), etc.
Cet article présentera le réseau classique Recurrent Neural Network (RNN), qui est également le réseau préféré pour les données de séries chronologiques. Lorsqu’il s’agit de certaines tâches séquentielles d’apprentissage automatique, RNN peut atteindre une très grande précision avec laquelle aucun autre algorithme ne peut rivaliser. En effet, les réseaux de neurones traditionnels n'ont qu'une mémoire à court terme, tandis que le RNN présente l'avantage d'une mémoire à court terme limitée. Cependant, le réseau RNN de première génération n’a pas attiré beaucoup d’attention, car les chercheurs ont souffert de graves problèmes de disparition de gradient lors de l’utilisation d’algorithmes de rétropropagation et de descente de gradient, ce qui a entravé le développement des RNN pendant des décennies. Enfin, une avancée majeure s’est produite à la fin des années 1990, conduisant à une nouvelle génération de RNN plus précis. Près de deux décennies après avoir tiré parti de cette avancée, les développeurs ont perfectionné et optimisé une nouvelle génération de RNN, jusqu'à ce que des applications comme Google Voice Search et Apple Siri commencent à usurper ses processus clés. Aujourd’hui, les réseaux RNN sont répandus dans tous les domaines de recherche et contribuent à déclencher une renaissance de l’intelligence artificielle.
Réseaux de neurones liés au passé (RNN)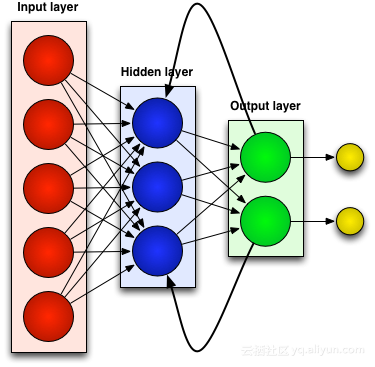
La plupart des réseaux de neurones artificiels, tels que les réseaux de neurones à rétroaction, ne se souviennent pas de l'entrée qu'ils viennent de recevoir. Par exemple, si un réseau neuronal à action directe reçoit le caractère « WISDOM », au moment où il atteint le caractère « D », il a oublié qu'il vient de lire le caractère « S », ce qui constitue un gros problème. Peu importe à quel point vous entraînez le réseau, il est toujours difficile de deviner le prochain caractère le plus probable, « O ». Cela en fait un candidat assez inutile pour certaines tâches, comme la reconnaissance vocale, où la qualité de la reconnaissance bénéficie largement de la capacité à prédire le caractère suivant. Les réseaux RNN, en revanche, mémorisent les entrées précédentes, mais à un niveau très sophistiqué.
Nous entrons à nouveau dans "WISDOM" et l'appliquons à un réseau récurrent. L'unité ou neurone artificiel du réseau RNN lorsqu'elle reçoit "D" a également pour entrée le caractère "S" qu'elle a reçu précédemment. En d’autres termes, il utilise les événements passés combinés aux événements présents comme entrée pour prédire ce qui va se passer ensuite, ce qui lui confère l’avantage d’une mémoire à court terme limitée. Lors de l'entraînement, avec suffisamment de contexte, on peut deviner que le caractère suivant est le plus susceptible d'être "O".
Ajuster et réajusterComme tous les réseaux de neurones artificiels, les unités RNN attribuent une matrice de poids à leurs multiples entrées. Ces poids représentent la proportion de chaque entrée dans la couche réseau ; puis une fonction est appliquée à ces poids pour déterminer une seule sortie. est appelée fonction de perte (fonction de coût) et limite l'erreur entre la sortie réelle et la sortie cible. Cependant, les RNN attribuent non seulement des pondérations aux entrées actuelles, mais également aux entrées des moments passés. Ensuite, les poids attribués à l'entrée actuelle et aux entrées passées sont ajustés dynamiquement en minimisant la fonction de perte. Ce processus implique deux concepts clés : la descente de gradient et la rétropropagation (BPTT).
Descente de DégradéL'un des algorithmes les plus connus de l'apprentissage automatique est l'algorithme de descente de gradient. Son principal avantage est qu’il évite considérablement la « malédiction de la dimensionnalité ». Qu'est-ce que la « malédiction de la dimensionnalité » ? Cela signifie que dans les problèmes de calcul impliquant des vecteurs, à mesure que le nombre de dimensions augmente, la quantité de calcul augmentera de façon exponentielle. Ce problème touche de nombreux systèmes de réseaux neuronaux car trop de variables doivent être calculées pour atteindre la fonction de perte minimale. Cependant, les algorithmes de descente de gradient brisent la malédiction de la dimensionnalité en amplifiant les erreurs multidimensionnelles ou les minima locaux de la fonction de coût. Cela aide le système à ajuster les valeurs de poids attribuées aux unités individuelles afin que le réseau devienne plus précis.
Rétropropagation dans le tempsRNN entraîne ses unités en affinant ses poids grâce à l'inférence rétrospective. En termes simples, sur la base de l'erreur entre la production totale calculée par l'unité et la sortie cible, une régression couche par couche inverse est effectuée à partir de l'extrémité de sortie finale du réseau et la dérivée partielle de la fonction de perte est utilisée pour ajuster le poids de chaque unité. Il s’agit du célèbre algorithme BP. Pour plus d’informations sur l’algorithme BP, vous pouvez lire les précédents blogs connexes de ce blogueur. Le réseau RNN utilise une version similaire appelée rétropropagation dans le temps (BPTT). Cette version étend le processus de réglage pour inclure les poids responsables de la mémoire de chaque unité correspondant à la valeur d'entrée à l'instant précédent (T-1).
Ouais : problème de dégradé en voie de disparition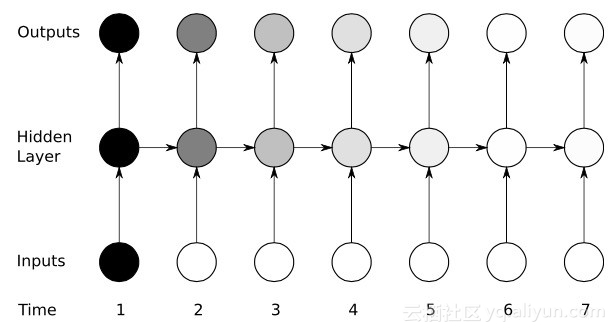
Bien qu'ils aient connu un certain succès initial grâce aux algorithmes de descente de gradient et au BPTT, de nombreux réseaux de neurones artificiels (y compris les réseaux RNN de première génération) ont finalement souffert d'un sérieux revers : le problème de disparition du gradient. Quel est le problème du gradient de disparition ? L’idée de base est en fait très simple. Examinons d’abord le concept de gradient, en considérant le gradient comme une pente. Dans le contexte de l'entraînement de réseaux neuronaux profonds, des valeurs de gradient plus grandes représentent des pentes plus raides, et plus le système peut glisser rapidement jusqu'à la ligne d'arrivée et terminer l'entraînement. Mais c’est là que les chercheurs ont eu des ennuis : un entraînement rapide était impossible lorsque la pente était trop plate. Ceci est particulièrement critique pour la première couche d'un réseau profond, car si la valeur de gradient de la première couche est nulle, cela signifie qu'il n'y a pas de direction d'ajustement et que les valeurs de poids pertinentes ne peuvent pas être ajustées pour minimiser la fonction de perte. Le phénomène est appelé « élimination ». À mesure que le gradient devient de plus en plus petit, le temps d'entraînement deviendra de plus en plus long, semblable au mouvement linéaire en physique, la balle continuera à se déplacer sur une surface lisse.
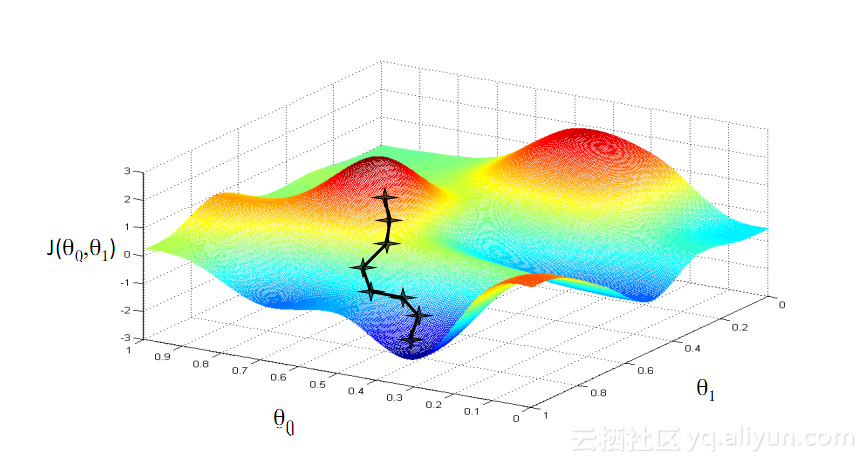
À la fin des années 1990, une avancée majeure a résolu le problème du gradient de disparition mentionné ci-dessus, provoquant un deuxième essor de la recherche sur le développement des réseaux RNN. L'idée centrale de cette grande avancée est l'introduction de la mémoire unitaire à long terme et à court terme (LSTM).
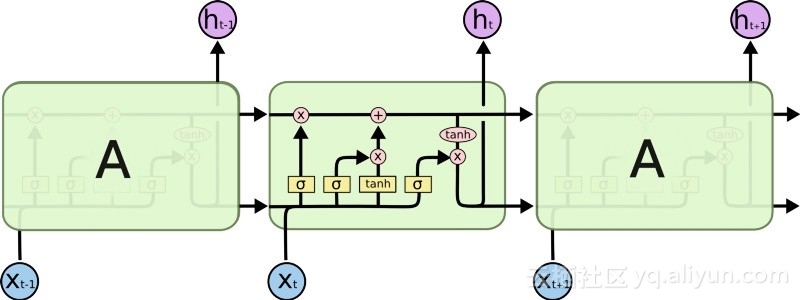
L'introduction du LSTM a créé un monde différent dans le domaine de l'IA. Cela est dû au fait que ces nouvelles unités ou neurones artificiels (comme les unités de mémoire à court terme standard de RNN) mémorisent leurs entrées dès le départ. Cependant, contrairement aux cellules RNN standard, les LSTM peuvent être montés sur leurs mémoires, qui ont des propriétés de lecture/écriture similaires aux registres de mémoire des ordinateurs classiques. De plus, les LSTM sont analogiques et non numériques, ce qui rend leurs fonctionnalités distinctes. Autrement dit, leurs courbes sont continues et l'on retrouve la raideur de leurs pentes. Par conséquent, LSTM est particulièrement adapté au calcul partiel impliqué dans la rétropropagation et la descente de gradient.
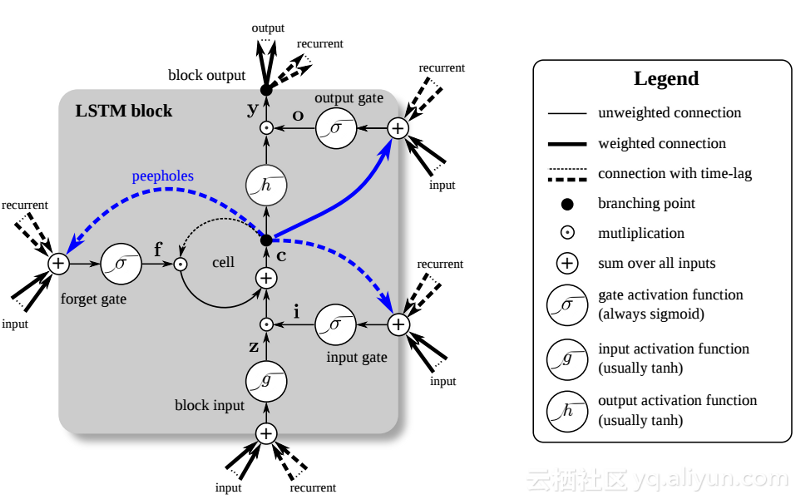
En résumé, LSTM peut non seulement ajuster ses poids, mais également conserver, supprimer, transformer et contrôler les entrées et sorties de ses données stockées en fonction du gradient d'entraînement. Plus important encore, LSTM peut conserver des informations d'erreur importantes pendant une longue période, de sorte que la pente soit relativement raide et que le temps de formation du réseau soit donc relativement court. Cela résout le problème de la disparition des gradients et améliore considérablement la précision des réseaux RNN actuels basés sur LSTM. Grâce aux améliorations significatives de l'architecture RNN, Google, Apple et de nombreuses autres entreprises avancées utilisent désormais RNN pour alimenter les applications au cœur de leurs activités.
RésuméLes réseaux de neurones récurrents (RNN) peuvent mémoriser leurs entrées précédentes, ce qui leur confère de plus grands avantages que les autres réseaux de neurones artificiels lorsqu'il s'agit de tâches continues et sensibles au contexte telles que la reconnaissance vocale.
Concernant l'histoire du développement des réseaux RNN : La première génération de RNN a atteint la capacité de corriger les erreurs grâce à des algorithmes de rétropropagation et de descente de gradient. Cependant, le problème du gradient de disparition a empêché le développement du RNN ; ce n'est qu'en 1997 qu'une avancée majeure a été réalisée après l'introduction d'une architecture basée sur LSTM.
La nouvelle méthode transforme efficacement chaque unité du réseau RNN en un ordinateur analogique, améliorant ainsi considérablement la précision du réseau.
Informations sur l'auteur
Jason Roell : ingénieur logiciel passionné par l'apprentissage profond et son application aux technologies transformatrices.
Linkedin : http://www.linkedin.com/in/jason-roell-47830817/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Entrée de la version Web Deepseek Entrée du site officiel Deepseek
Feb 19, 2025 pm 04:54 PM
Entrée de la version Web Deepseek Entrée du site officiel Deepseek
Feb 19, 2025 pm 04:54 PM
Deepseek est un puissant outil de recherche et d'analyse intelligent qui fournit deux méthodes d'accès: la version Web et le site officiel. La version Web est pratique et efficace et peut être utilisée sans installation; Que ce soit des individus ou des utilisateurs d'entreprise, ils peuvent facilement obtenir et analyser des données massives via Deepseek pour améliorer l'efficacité du travail, aider la prise de décision et promouvoir l'innovation.
 Comment installer Deepseek
Feb 19, 2025 pm 05:48 PM
Comment installer Deepseek
Feb 19, 2025 pm 05:48 PM
Il existe de nombreuses façons d'installer Deepseek, notamment: Compiler à partir de Source (pour les développeurs expérimentés) en utilisant des packages précompilés (pour les utilisateurs de Windows) à l'aide de conteneurs Docker (pour le plus pratique, pas besoin de s'inquiéter de la compatibilité), quelle que soit la méthode que vous choisissez, veuillez lire Les documents officiels documentent soigneusement et les préparent pleinement à éviter des problèmes inutiles.
 Le package d'installation OUYI OKX est directement inclus
Feb 21, 2025 pm 08:00 PM
Le package d'installation OUYI OKX est directement inclus
Feb 21, 2025 pm 08:00 PM
OUYI OKX, le premier échange mondial d'actifs numériques, a maintenant lancé un package d'installation officiel pour offrir une expérience de trading sûre et pratique. Le package d'installation OKX de OUYI n'a pas besoin d'être accessible via un navigateur. Le processus d'installation est simple et facile à comprendre.
 Obtenez le package d'installation Gate.io gratuitement
Feb 21, 2025 pm 08:21 PM
Obtenez le package d'installation Gate.io gratuitement
Feb 21, 2025 pm 08:21 PM
Gate.io est un échange de crypto-monnaie populaire que les utilisateurs peuvent utiliser en téléchargeant son package d'installation et en l'installant sur leurs appareils. Les étapes pour obtenir le package d'installation sont les suivantes: Visitez le site officiel de Gate.io, cliquez sur "Télécharger", sélectionnez le système d'exploitation correspondant (Windows, Mac ou Linux) et téléchargez le package d'installation sur votre ordinateur. Il est recommandé de désactiver temporairement les logiciels antivirus ou le pare-feu pendant l'installation pour assurer une installation fluide. Une fois terminé, l'utilisateur doit créer un compte Gate.io pour commencer à l'utiliser.
 Installation officielle du site officiel de Bitget (Guide du débutant 2025)
Feb 21, 2025 pm 08:42 PM
Installation officielle du site officiel de Bitget (Guide du débutant 2025)
Feb 21, 2025 pm 08:42 PM
Bitget est un échange de crypto-monnaie qui fournit une variété de services de trading, notamment le trading au comptant, le trading de contrats et les dérivés. Fondée en 2018, l'échange est basée à Singapour et s'engage à fournir aux utilisateurs une plate-forme de trading sûre et fiable. Bitget propose une variété de paires de trading, notamment BTC / USDT, ETH / USDT et XRP / USDT. De plus, l'échange a une réputation de sécurité et de liquidité et offre une variété de fonctionnalités telles que les types de commandes premium, le trading à effet de levier et le support client 24/7.
 OUYI Exchange Télécharger le portail officiel
Feb 21, 2025 pm 07:51 PM
OUYI Exchange Télécharger le portail officiel
Feb 21, 2025 pm 07:51 PM
Ouyi, également connu sous le nom d'OKX, est une plate-forme de trading de crypto-monnaie de pointe. L'article fournit un portail de téléchargement pour le package d'installation officiel d'Ouyi, qui facilite les utilisateurs pour installer le client Ouyi sur différents appareils. Ce package d'installation prend en charge les systèmes Windows, Mac, Android et iOS. Une fois l'installation terminée, les utilisateurs peuvent s'inscrire ou se connecter au compte OUYI, commencer à négocier des crypto-monnaies et profiter d'autres services fournis par la plate-forme.
 Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Solution aux problèmes d'autorisation Lors de la visualisation de la version Python dans Linux Terminal Lorsque vous essayez d'afficher la version Python dans Linux Terminal, entrez Python ...
 Comment définir automatiquement les autorisations d'UnixSocket après le redémarrage du système?
Mar 31, 2025 pm 11:54 PM
Comment définir automatiquement les autorisations d'UnixSocket après le redémarrage du système?
Mar 31, 2025 pm 11:54 PM
Comment définir automatiquement les autorisations d'UnixSocket après le redémarrage du système. Chaque fois que le système redémarre, nous devons exécuter la commande suivante pour modifier les autorisations d'UnixSocket: sudo ...
