

La sauvegarde est avant tout. Aujourd'hui, nous résumerons plusieurs méthodes de sauvegarde et étapes de récupération couramment utilisées.
1.mysqldumpDans le travail quotidien, nous utilisons la commande mysqldump pour créer un fichier de dump au format SQL pour sauvegarder la base de données. Ou nous pouvons exporter les données et effectuer des opérations telles que la migration des données et la configuration principale et secondaire. mysqldump est un outil de sauvegarde logique qui copie les définitions d'objets de base de données d'origine et les données de table pour produire un ensemble d'instructions SQL exécutables. Par défaut, des instructions d'insertion sont générées et une sortie avec d'autres délimiteurs ou fichiers au format XML peut également être générée.
shell> mysqldump [arguments] > file_name
Jetons un bref aperçu de l'utilisation quotidienne :
Sauvegardez toutes les bases de données :
shell> mysqldump –all-databases > dump.sql (不包含INFORMATION_SCHEMA,performance_schema,sys,如果想要导出的话还要结合–skip-lock-tables和–database一起用)
Sauvegardez la base de données spécifiée :
shell> mysqldump –databases db1 db2 db3 > dump.sql
Lorsque nous ne sauvegardons qu'une seule donnée, nous pouvons omettre –databases et l'écrire directement : mysqldump test > dump.sql Cependant, il existe quelques différences subtiles si elle n'est pas ajoutée, la sortie de vidage de la base de données n'inclut pas la création de la base de données et. utilisez des instructions, afin qu'il puisse importer directement dans une base de données avec un autre nom sans ajouter ce paramètre.
Bien sûr, nous pouvons également sauvegarder uniquement une certaine table :
mysqldump –user [username] –password=[password] [database name] [table “” not found /]<br> table_name.sql
Après avoir compris quelques usages simples, concentrons-nous sur quelques paramètres :
Nous venons de dire que la table sera verrouillée lors de l'utilisation de mysqldump. Examinons en détail son mécanisme de verrouillage.
Nous ouvrons deux fenêtres et exécutons mysqldump -uroot -pxxxxx –master-data=2 –databases dbname > /tmp/dbnamedate +%F.sql dans la première. Connectez-vous ensuite dans la deuxième fenêtre et utilisez le processus show. La commande peut voir que la session de vidage en cours est en cours d'exécution.

SELECT /!40001 SQL_NO_CACHE / * FROM table_name; Vous pouvez voir que ce SQL interroge les données en mode no_cache.
Ensuite, nous avons exécuté select sur la même table et avons constaté qu'elle était bloquée. Le curseur ne revient jamais.

Généralement, lorsqu'on rencontre ce genre de fichier, on se demande s'il est verrouillé ? Pour vérifier, vérifions les informations de verrouillage et constatons que le processus de vidage est réellement verrouillé.

Généralement, lorsqu'on rencontre ce genre de fichier, on se demande s'il est verrouillé ? Pour vérifier, vérifions les informations de verrouillage et constatons que le processus de vidage est réellement verrouillé.

Ouvrons le general_log spécifique et jetons un œil aux opérations à ce moment-là :
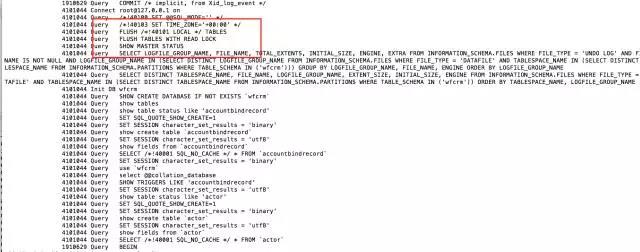
4101044 Query FLUSH /!40101 LOCAL / TABLES 4101044 Query FLUSH TABLES WITH READ LOCK
(Fermez toutes les tables ouvertes et ajoutez un verrou en lecture à toutes les tables de la base de données jusqu'à ce que le déverrouillage des tables soit explicitement exécuté. Cette opération est souvent utilisée lors de la sauvegarde des données.)
4101044 Query SHOW MASTER STATUS
(C'est parce que j'ai utilisé –master-data=2)
La montre sera donc verrouillée à ce moment-là.
Si je n'ajoute pas le paramètre –master-data (mysqldump -uroot -pxx –databases db > /tmp/dbnamedate +%F.sql), mysql affichera LOCK TABLES table_name1 READ,LOCK pour chaque table à sauvegarder. TABLES table_name2 READ, et il n'y aura aucun blocage de lecture.
Existe-t-il une méthode non verrouillable ? En fait, il existe. Il s'agit d'utiliser –single-transaction pour mettre l'opération de sauvegarde dans une transaction.
Processus de sauvegarde Mysqldump avec le paramètre –single-transaction :
S'il s'agit de MySQL version 5.6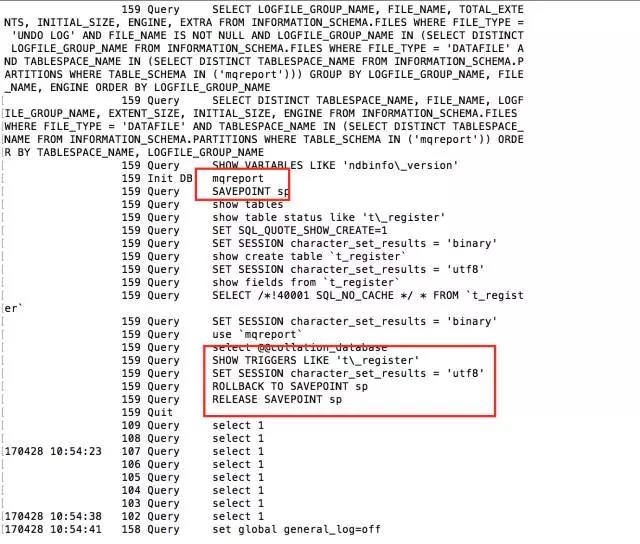
Entre les sauvegardes, FLUSH TABLES WITH READ LOCK, puis définissez le niveau de transaction SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ, puis démarrez une transaction START TRANSACTION pour la sauvegarde. À ce stade, le processus de sauvegarde est très intéressant. Il crée d'abord un point de sauvegarde. , puis sauvegardez les tables de la base de données dans l'ordre. Une fois la sauvegarde terminée, elle est restaurée au point de sauvegarde précédent pour garantir la cohérence des données.
如果是5.7版本的MySQL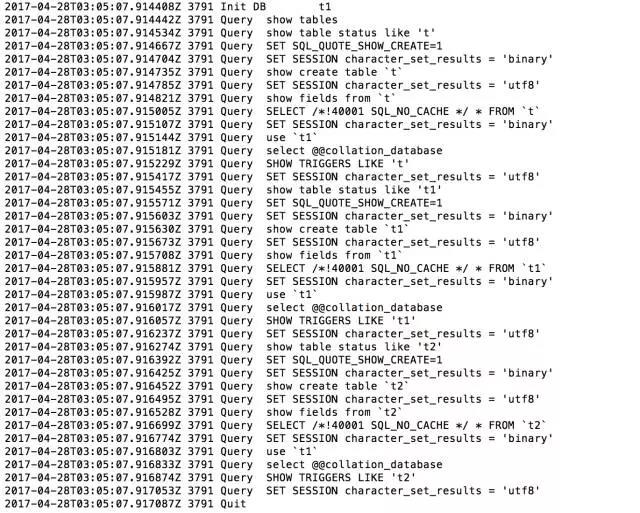
备份前的操作相同,只是没有了savepoint。
不过不管是哪个版本,只有InnoDB表是在一个一致性的状态。其它的任何MyISAM表或内存表是没有用的。 mysqldump的优势是可以查看或者编辑十分方便,它也可以灵活性的恢复之前的数据。它也不关心底层的存储引擎,既适用于支持事务的,也适用于不支持事务的表。不过它不能作为一个快速备份大量的数据或可伸缩的解决方案。如果数据库过大,即使备份步骤需要的时间不算太久,但有可能恢复数据的速度也会非常慢,因为它涉及的SQL语句插入磁盘I/O,创建索引等等。 对于大规模的备份和恢复,更合适的做法是物理备份,复制其原始格式的数据文件,可以快速恢复:如果你的表主要是InnoDB表,或者如果你有一个InnoDB和MyISAM表,可以考虑使用MySQL的mysqlbackup命令备份。
恢复操作:先看一下当前的数据:
dbadmin@test 11:10:34>select * from t; +——-+ | id | +——-+ | 1 | +——-+ 1 row in set (0.00 sec)
备份;
mysqldump -uroot -proot@1234 –master-data=1 test >test.sql
模拟增量操作
dbadmin@test 11:15:17>insert into t values (2); Query OK, 1 row affected (0.00 sec) dbadmin@test 11:15:36>select * from t; +——+ | id | +——+ | 1 | | 2 | +——+ 2 rows in set (0.00 sec)
模拟误操作:
dbadmin@test 11:15:41>truncate table t; Query OK, 0 rows affected (0.01 sec) dbadmin@test 11:16:14>select * from t; Empty set (0.00 sec)
模拟恢复操作:
step 1:找到误操作的log position
dbadmin@test 11:20:57>show master logs; dbadmin@(none) 11:21:37>show binlog events in ‘mysql-bin.000004’;
查看可以看到是444。
step 2:恢复到备份
dbadmin@test 11:16:25>source test.sql dbadmin@test 11:17:26>select from t; +——-+ | id | +——-+ | 1 | +——-+ 1 row in set (0.00 sec)
step 3: 因为我们在备份的时候使用了master-data的参数,所以可以直接看到备份时候的最后位置,然后应用中间的log。查看可以看到是187。
我们使用mysqlbinlog得到这一段时间的操作,其实我们也可以用这个工具得到操作后使用sed进行undo的操作。
mysqlbinlog –start-position=187 –stop-position=444 mysql-bin.000004 > increment.sql dbadmin@test 11:44:37>source /u01/my3307/log/increment.sql dbadmin@test 11:44:50>select from t; +——+ | id | +——+ | 1 | | 2 | +——+
至此数据恢复。
二、mysqlbackupmysqlbackup是Oracle公司提供的针对企业的备份软件,全名叫做MySQL Enterprise Backup,是一个收费的软件。
我们简单来看一下这个工具的使用。
查看所有的帮助:
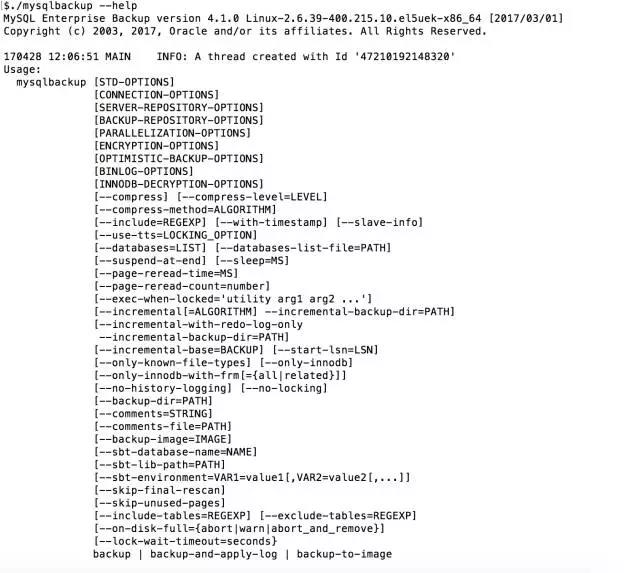
我这里只是截取了一小部分,这个帮助很长,参数很多,功能很全,是oracle官方主推的备份方式。
全量备份
mysqlbackup –user=root –password=ucjmh –databases=’t1′ –encrypt-password=1 –with-timestamp –backup-dir=/u01/backup/ backup
解释一下参数:
backup 是备份的方式, 一共有如下几种方式,我会在一个恢复案例里把常用的几个都用到。
Backup operations: backup, backup-and-apply-log, backup-to-image Update operations: apply-log, apply-incremental-backup Restore operations: copy-back, copy-back-and-apply-log Validation operation: validate Single-file backup operations: image-to-backup-dir, backup-dir-to-image, list-image, extract
其实,在大多数情况下,单个文件备份,使用backup-to-image命令创建,性能优于backup。buckup这个命令只执行一个完整的备份过程的初始阶段。需要通过再次运行mysqlbackup运用apply-log 命令,使备份一致。
mysqlbackup –user=root –password=ucjmh –databases=’t1′ –encrypt-password=1 –with-timestamp –backup-dir=/u01/backup/2017-04-28_12-49-35/ apply-log
当然你可以直接用backup-and-apply-log 不过这个时候的备份将不能用于增量了。
增量备份:
mysqlbackup –user=root –password=ucjmh –databases=’t1′ –encrypt-password=1 –with-timestamp –backup-dir=/u01/backup/ –incremental –incremental-base=dir:/u01/backup/2017-04-28_12-49-35 –incremental-backup-dir=/u01/backup/incremental backup
这个是基于上次的备份做的备份,当然也可以基于某一个log position之后做。
–incremental:代表增量备份;
–incremental-base:上次全备的目录;
–incremental-backup-dir:增量备份的保存的目录
大致梳理一下操作步骤,来了解一下恢复的原理:首先检测并应用全备事务日志文件(这里是因为我备份的时候用的是backup而不是backup-and-apply-log),然后基于全备去应用增量的log。这个时候如果有多次增量备份也可以(基于LSN点向后应用)。 所有的都应用完成之后就是一个可以直接cp的数据库了。
个人感觉这个工具比xtrabackup好用,但是xtrabackup是开源的,所以市场占有量才会大,才会更有名,更多人用吧。
三、mysqlhotcopymysqlhotcopy使用lock tables、flush tables和cp或scp来快速备份数据库.它是备份数据库或单个表最快的途径,完全属于物理备份,但只能用于备份MyISAM存储引擎和ARCHIVE引擎,并且是一个服务器命令,只能运行在数据库目录所在的机器上.与mysqldump备份不同,mysqldump属于逻辑备份,备份时是执行的sql语句.使用mysqlhotcopy命令前需要要安装相应的软件依赖包. 因为这个功能很弱,我们只简单的介绍一个怎么用:
备份一个库
mysqlhotcopy db_name [/path/to/new_directory]
备份一张表
mysqlhotcopy db_name./table_name/ /path/to/new_directory
更详细的使用可以使用perldoc mysqlhotcopy查看。
四、xtrabackup/innobackupexPercona XtraBackup是一款基于MySQL的热备份的开源实用程序,它可以备份5.1到5.7版本上InnoDB,XtraDB,MyISAM存储引擎的表, Xtrabackup有两个主要的工具:xtrabackup、innobackupex 。
(1)xtrabackup只能备份InnoDB和XtraDB两种数据表,而不能备份MyISAM数据表
(2)innobackupex则封装了xtrabackup,是一个脚本封装,所以能同时备份处理innodb和myisam,但在处理myisam时需要加一个读锁。
首先我们先来简单的了解一下xtrabackup是怎么工作的。xtrabackup基于innodb的crash-recovery(实例恢复)功能,先copy innodb的物理文件(这个时候数据的一致性是无法满足的),然后进行基于redo log进行恢复,达到数据的一致性。
我们还是简单来看一下日常工作中具体的使用:
全备:
xtrabackup –backup –target-dir=/data/backup/base
可以先看到
在备份过程中,可以看到很多输出显示数据文件被复制,以及日志文件线程反复扫描日志文件和复制。
同样的,它也输出了当前的binlog filename和position,如果有gtid(同样也会输出) 可以用于搭建主从。最后一行一定会是你的lsn被copy的信息。 这是因为每次启动备份,都会记录170429 12:54:10 >> log scanned up to (1676085)),然后开始拷贝文件,一般来讲数据库越大拷贝文件是要花费越长的时间,所以说这期间一般情况都会有新的操作,所以说所有文件也可能记录的并不是一个时间点的数据, 为了解决数据这个问题,XtraBackup 就会启动一个后台进程来每秒1次的观测mysql的事务日志,直到备份结束。而且把事务日志中的改变记录下来。我们知道事物日志是会重用的(redo log),所以这个进程会把redolog写到自己的日志文件xtrabackup_log,这个后台监控进程会记录所有的事务日志的改变,用于保证数据一致性所。
增量备份:
当我们做过全量备份以后会在目录下产生xtrabackup_checkpoints的文件 这里面记录了lsn和备份方式,我们可以基于这次的全量做增量的备份。
$cat xtrabackup_checkpoints backup_type = full-backuped from_lsn = 0 to_lsn = 1676085 last_lsn = 1676085 compact = 0 recover_binlog_info = 0 xtrabackup –backup –target-dir=/data/backup/inc1 –incremental-basedir=/data/backup/base
这个时候xtrabackup也是去打开了xtrabackup_checkpoints文件进行上一次备份的信息查看。这个时候去查看增量备份的xtrabackup_checkpoints也记录了这些信息。
$cat xtrabackup_checkpoints backup_type = incremental from_lsn = 1676085 to_lsn = 1676085 last_lsn = 1676085 compact = 0 recover_binlog_info = 0
这也意味着你可以在增量的备份上继续增量的备份。
同样的,xtrabackup也支持压缩(–compress)、加密(–encrypt)、并行(–parallel)等操作,但是和mysqlbackup不同的是这个没有同时的备份binlog,而mysqlbackup是备份了binlog的。
我们来模拟一个恢复的过程深入的了解一下原理。
查看当前数据:
dbadmin@test 03:04:33>select from t; +——-+ | id | +——-+ | 1 | +——-+ 1 row in set (0.00 sec)
全量备份
$xtrabackup –backup –target-dir=/data/backup/base
模拟增量数据
dbadmin@test 03:07:16>select from t; +——-+ | id | +——-+ | 1 | | 2 | +——-+ 2 rows in set (0.00 sec)
进行增量备份:
$xtrabackup –backup –target-dir=/data/backup/inc1 –incremental-basedir=/data/backup/base
模拟无备份操作:
dbadmin@test 03:09:42>select * from t; +——-+ | id | +——-+ | 1 | | 2 | | 3 | +——-+ 3 rows in set (0.00 sec) 模拟误操作:
dbadmin@test 03:09:45>truncate table t; Query OK, 0 rows affected (0.00 sec)
模拟恢复操作:
step 1:找到误操作的log position
dbadmin@test 03:10:19>show master logs; dbadmin@test 03:10:47>show binlog events in ‘mysql-bin.000001’; 1333
我们需要分别对全量、增量备份各做一次prepare操作。
增量
如果我们使用它自带的还原命令的时候就要先把data目录给清空。不然就会报如下的错误
$innobackupex –copy-back /data/backup/base/ 170429 15:37:19 innobackupex: Starting the copy-back operation IMPORTANT: Please check that the copy-back run completes successfully. At the end of a successful copy-back run innobackupex prints “completed OK!”. innobackupex version 2.4.6 based on MySQL server 5.7.13 Linux (x86_64) (revision id: 8ec05b7) Original data directory /u01/my3307/data is not empty!
当然我们大多数据时候是不会在原来的实例上做操作的,都会把相应的备份在奇他的实例上进行恢复,然后再导出导入到误操作的实例。这里我们直接清掉目录,然后再次运行,查看恢复后的数据:
dbadmin@test 03:41:56>select * from t; +——-+ | id | +——-+ | 1 | | 2 | +——-+ 2 rows in set (0.00 sec)
同样的被恢复的目录里会多出来两个文件,一个是xtrabackup_binlog_pos_innodb,一个是xtrabackup_info。在这两个文件中都可以看到你最后的log,pos。在info里还可以看到lsn。我们基于这个pos再进行binlog的重演,恢复在binlog没有被备份的数据。
1076 $mysqlbinlog mysql-bin.000001 –start-position=1076 –stop-position=1333 -vv >increment.sql dbadmin@test 03:51:25>source /u01/my3307/log/increment.sql dbadmin@test 03:51:34>select * from t; +——-+ | id | +——-+ | 1 | | 2 | | 3 | +——-+ 3 rows in set (0.00 sec)
至此数据恢复完成。
五、直接复制整个数据库目录MySQL还有一种非常简单的备份方法,就是将MySQL中的数据库文件直接复制出来。这是最简单,速度最快的方法。 不过在此之前,要先将服务器停止,这样才可以保证在复制期间数据库的数据不会发生变化。如果在复制数据库的过程中还有数据写入,就会造成数据不一致。这种情况在开发环境可以,但是在生产环境中很难允许备份服务器。
注意:这种方法不适用于InnoDB存储引擎的表,而对于MyISAM存储引擎的表很方便。同时,还原时MySQL的版本最好相同。 只所以提这一点是因为当有停机窗口时,搭建主从的时候,这个往往是最快的。
一般生产环境的备份都会用percona-xtrabackup或者mysqlbackup,结合自己的情况,选择合适的备份策略,适时拿出来验证备份的有效性。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



