
 Périphériques technologiques
IA
'Minecraft' se transforme en une ville IA et les habitants des PNJ jouent comme de vraies personnes
Périphériques technologiques
IA
'Minecraft' se transforme en une ville IA et les habitants des PNJ jouent comme de vraies personnes
'Minecraft' se transforme en une ville IA et les habitants des PNJ jouent comme de vraies personnes

Veuillez noter que cet homme carré fronça les sourcils, réfléchissant à l'identité des « invités non invités » devant lui.

Il s'est avéré qu'elle se trouvait dans une situation dangereuse. Après avoir réalisé cela, elle a rapidement commencé une recherche mentale pour trouver une stratégie pour résoudre le problème.
Finalement, elle a décidé de fuir les lieux dans un premier temps, puis de demander de l'aide le plus rapidement possible et d'agir immédiatement.

En même temps, la personne d'en face pense aussi la même chose qu'elle...

Il y a une telle scène dans "Minecraft", où tous les personnages sont contrôlés par l'intelligence artificielle.
Chacun d'eux a un cadre identitaire unique. Par exemple, la fille mentionnée précédemment est une coursière de 17 ans mais intelligente et courageuse.

Ils ont la capacité de se souvenir et de penser, et vivent comme des humains dans cette petite ville située dans "Minecraft".
Ce qui les motive, c'est un tout nouveau cadre de jeu de rôle d'IA basé sur le langage LARP conçu pour le monde ouvert.
LA fait référence ici à Language Agent, et LARP est l'abréviation de Live Action Role Playing, qui est un jeu de mots.
En plus d'avoir une complexité cognitive plus élevée que les cadres d'agents traditionnels, le LARP réduit également l'écart entre les agents et les jeux en monde ouvert——
Ces jeux n'ont souvent pas de "normes de passage" spécifiques permettant aux joueurs de librement explorez-le, alors que les agents de jeu traditionnels sont souvent utilisés pour atteindre des objectifs spécifiques.
De plus, l'objectif du GN est de mettre en valeur la simulation et de rendre le comportement de l'agent plus proche de l'humain Pour cela, les chercheurs ont même introduit un mécanisme d'oubli.
Alors, comment le LARP est-il mis en œuvre ? Venez le découvrir bientôt.
Agent de contrôle collaboratif multi-modules
La structure du LARP est modulaire, incluant spécifiquement la cognition, la personnalité, la mémoire, la prise de décision et d'autres composants.
Parmi eux, le module de mémoire est composé de trois parties : la mémoire à long terme, la mémoire de travail (à court terme) et le système de traitement de la mémoire.
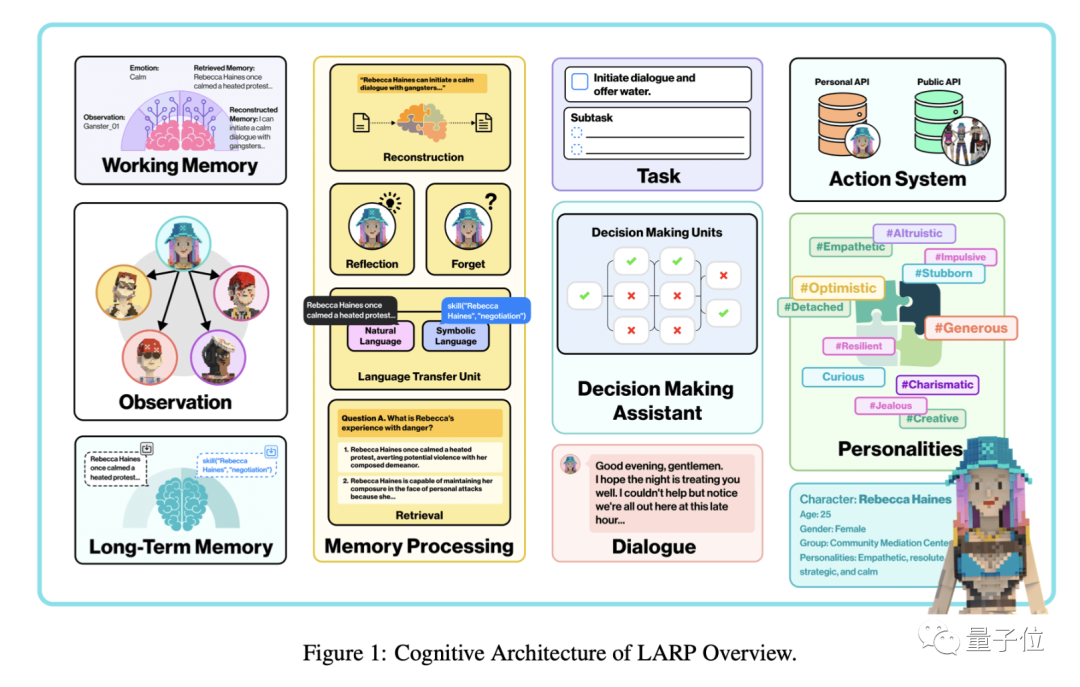
Au cours du processus, l'environnement et d'autres informations observées par le personnage seront saisis dans le module de traitement de la mémoire sous forme de langage naturel. Après conversion du codage et combinés avec la mémoire à long terme extraite, une mémoire de travail sera créée. être formé ;
Ensuite, la mémoire de travail sera introduite dans le module de prise de décision, qui produit finalement un contenu de prise de décision ou de dialogue.
Une caractéristique du module de prise de décision est qu'il décomposera un grand objectif en sous-tâches et utilisera le modèle de langage pour déterminer l'ordre d'exécution des sous-tâches.
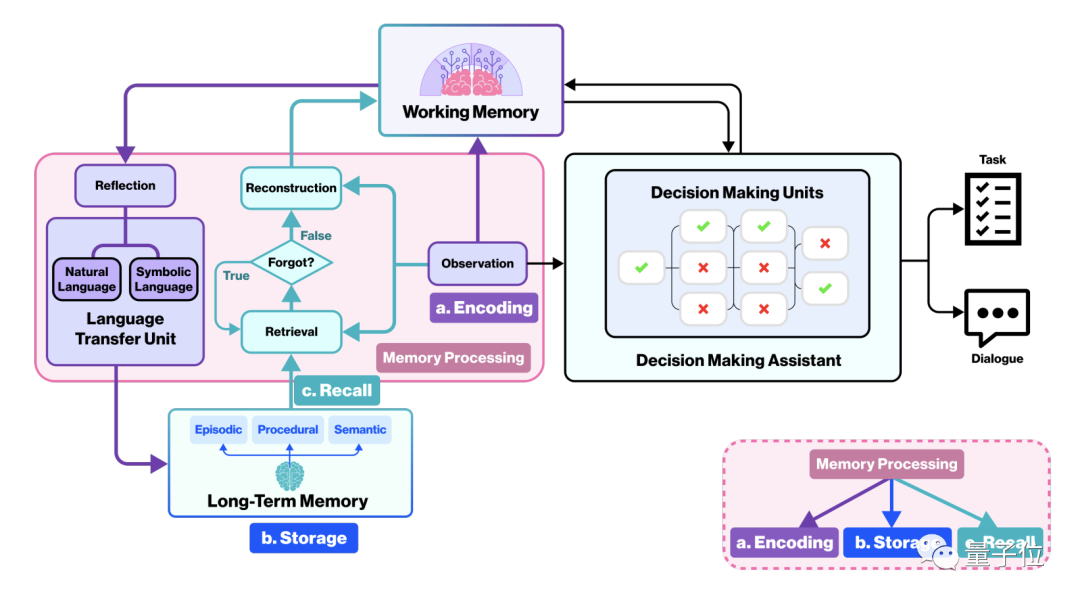
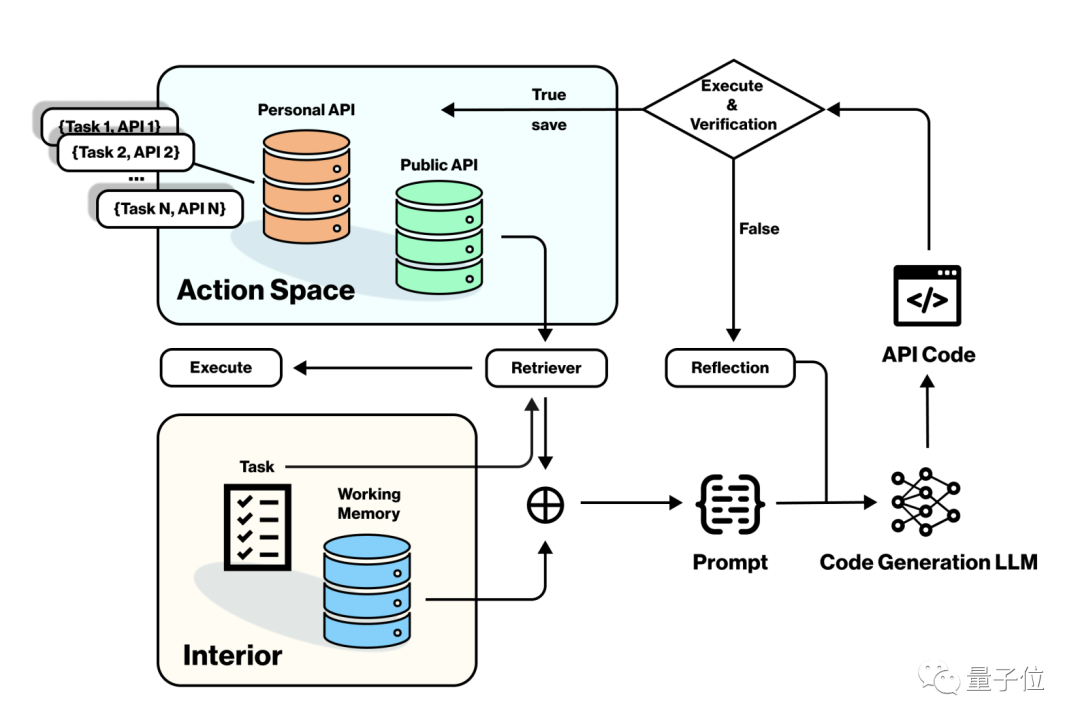
Les décisions prises par le modèle seront exécutées en appelant l'API via le module d'interaction avec l'environnement. Si nécessaire, le module de backtracking sera également appelé pour la reconstruction du code
Après une exécution réussie, les nouvelles compétences du personnage seront mises à jour. stocké et devient une nouvelle mémoire à long terme.
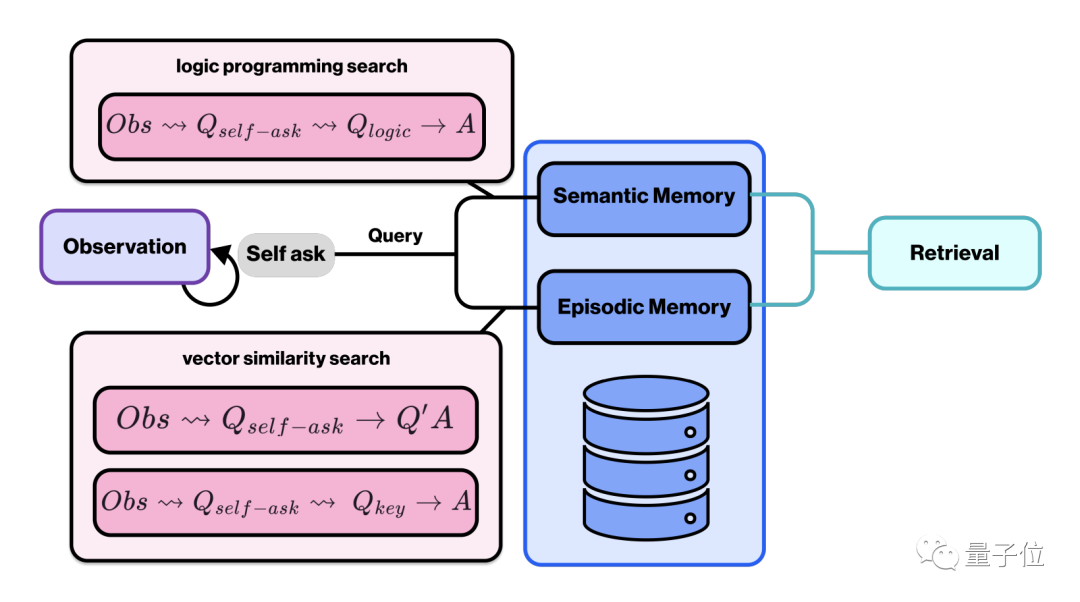
Dans le processus de récupération de la mémoire à long terme, les personnages se poseront des questions basées sur le contenu observé et interrogeront les trois dimensions des énoncés logiques, de la similarité des vecteurs et de la similarité des phrases pour extraire des réponses.
L'énoncé logique est utilisé pour interroger la mémoire sémantique, et les deux derniers sont utilisés pour interroger la mémoire épisodique.
La mémoire sémantique correspond à des concepts généraux et à des connaissances factuelles sur le monde, y compris les règles du jeu et les visions du monde associées ; la mémoire épisodique correspond à des événements spécifiques du jeu, liés à des scènes et des expériences spécifiques.
Le contenu du premier est relativement fixe, tandis que le second continuera à s'accumuler en fonction de l'expérience de l'Agent.
Afin de faire en sorte que l'agent contrôlé par le GN ressemble davantage à une personne réelle, l'équipe de recherche a également délibérément introduit un mécanisme d'oubli qui évolue au fil du temps.
Lorsque le paramètre d'atténuation σ dépasse un certain seuil, la récupération de la mémoire échouera, simulant ainsi le processus d'oubli. La méthode de calcul de σ est définie sur la base des lois de la psychologie :
σ = αλN (1 + βt) - ψ
. λ représente l'importance de la mémoire, N représente le nombre de récupérations, t représente le temps écoulé depuis la dernière récupération, ψ est le taux d'oubli du personnage, α et β sont des paramètres d'échelle
Cette formule a été proposée par le psychologue Wayne Wickelgren et est a Un ajout à la courbe d'oubli d'Ebbinghaus.
En termes de création de personnages, les chercheurs ont pré-entraîné des modèles de base sur des ensembles de données qui reflètent différentes personnalités, et ont utilisé des ensembles de données d'instructions spécialement construits pour un réglage fin supervisé.
Dans le même temps, l'équipe a également conçu plusieurs ensembles de données pour les différentes capacités des personnages et formé un modèle d'adaptation de bas rang, qui a été intégré dynamiquement au modèle de base pour guider le module de prise de décision afin de générer du contenu adapté. la personnalité.
Parallèlement, des modules de vérification des actions et d'identification des conflits sont également mis en place dans LARP pour garantir que le contenu généré par le modèle pour l'agent est contraint par les données de l'environnement de jeu et les spécifications des connaissances préalables.

Actuellement, la page GitHub de LARP a été créée, mais elle est encore en position courte et le code n'a pas encore été publié.
Avec l'approfondissement de la recherche sur de grands modèles, les expériences d'intelligence par agents et par essaims sont désormais devenues l'une des directions les plus populaires de la recherche sur l'IA.
Par exemple, la Stanford AI Town, devenue populaire l'année dernière, et la « AI Game Company » et « AI Werewolf » lancées par l'Université Tsinghua ont toutes permis aux gens de constater les avantages de la collaboration multi-agents.
Pour plus d'informations sur les agents intelligents, le « Top Ten Frontier Technology Reports in 2023 » lancé par le Qubit Think Tank comporte également une introduction détaillée.
Adresse papier : https://arxiv.org/abs/2312.17653
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 Surveillez les gouttelettes MySQL et MariaDB avec Exportateur de Prometheus Mysql
Apr 08, 2025 pm 02:42 PM
Surveillez les gouttelettes MySQL et MariaDB avec Exportateur de Prometheus Mysql
Apr 08, 2025 pm 02:42 PM
Une surveillance efficace des bases de données MySQL et MARIADB est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Prometheus Mysql Exportateur est un outil puissant qui fournit des informations détaillées sur les mesures de base de données qui sont essentielles pour la gestion et le dépannage proactifs.
