

| Présentation | Les conteneurs révolutionnent l'ensemble du cycle de vie des logiciels : depuis les premières expériences techniques et preuves de concept, en passant par le développement, les tests, le déploiement et le support. |
Vous voulez essayer MongoDB sur votre ordinateur portable ? Exécutez simplement une commande et vous obtiendrez un bac à sable léger et autonome. Vous pouvez supprimer toutes les traces de ce que vous avez fait lorsque vous avez terminé.
Vous souhaitez utiliser la même copie de pile d'applications dans plusieurs environnements ? Créez vos propres images de conteneurs et laissez vos équipes de développement, de test, d'exploitation et de support utiliser le même clone d'environnement.
Les conteneurs révolutionnent l'ensemble du cycle de vie des logiciels : depuis les premières expériences techniques et preuves de concept, en passant par le développement, les tests, le déploiement et le support.
Les outils d'orchestration sont utilisés pour gérer la création, la mise à niveau de plusieurs conteneurs et les rendre hautement disponibles. L'orchestration contrôle également la façon dont les conteneurs sont connectés pour créer des applications complexes à partir de plusieurs conteneurs de microservices.
Des fonctionnalités riches, des outils simples et des API puissantes font des conteneurs et des capacités d'orchestration le premier choix des équipes DevOps à intégrer dans les workflows d'intégration continue (CI) et de livraison continue (CD).
Cet article explore les défis supplémentaires rencontrés lors de l'exécution et de l'orchestration de MongoDB dans des conteneurs et explique comment les surmonter.
Notes sur MongoDBIl y a quelques considérations supplémentaires pour exécuter MongoDB avec des conteneurs et une orchestration :
Les nœuds de base de données MongoDB sont avec état. Si un conteneur tombe en panne et est replanifié, les données sont perdues (elles peuvent être récupérées à partir d'autres nœuds du jeu de réplicas, mais cela prend du temps), ce qui n'est pas souhaitable. Pour résoudre ce problème, vous pouvez utiliser des fonctionnalités telles que l'abstraction de volume dans Kubernetes pour mapper le répertoire de données temporaire MongoDB dans le conteneur vers un emplacement persistant afin que les données survivent aux pannes du conteneur et aux processus de replanification.
Les nœuds de base de données MongoDB dans un jeu de réplicas doivent pouvoir communiquer entre eux, y compris après une replanification. Tous les nœuds d'un jeu de réplicas doivent connaître les adresses de tous leurs pairs, mais lorsqu'un conteneur est replanifié, il peut redémarrer avec une adresse IP différente. Par exemple, tous les conteneurs d'un pod Kubernetes partagent une adresse IP, et lorsqu'un pod est réorchestré, l'adresse IP change. Avec Kubernetes, cela est géré en associant un service Kubernetes à chaque nœud MongoDB, qui fournit un « nom d'hôte » utilisant le service DNS Kubernetes pour maintenir le service inchangé lors des réorchestrations.
Une fois que chaque nœud MongoDB individuel est en cours d'exécution (chacun dans son propre conteneur), le jeu de réplicas doit être initialisé et chaque nœud y est ajouté. Cela peut nécessiter un traitement supplémentaire en dehors de l'outil d'orchestration. Plus précisément, vous devez utiliser un nœud MongoDB dans le jeu de réplicas cible pour exécuter les commandes rs.initiate et rs.add.
Si un cadre d'orchestration fournissait une réorchestration automatisée des conteneurs (tels que Kubernetes), cela augmenterait la résilience de MongoDB, car les membres du jeu de réplicas défaillants pourraient être automatiquement recréés, rétablissant ainsi les niveaux de redondance complets sans intervention humaine.
Il convient de noter que même si la structure d'orchestration peut surveiller l'état du conteneur, il est peu probable qu'elle surveille l'application exécutée à l'intérieur du conteneur ou qu'elle sauvegarde ses données. Cela signifie qu'il est important d'utiliser une solution puissante de surveillance et de sauvegarde comme MongoDB Cloud Manager incluse dans MongoDB Enterprise Advanced et MongoDB Professional. Pensez à créer votre propre image contenant votre version MongoDB préférée et MongoDB Automation Agent.
Comme mentionné dans la section précédente, les bases de données distribuées (telles que MongoDB) nécessitent un peu d'attention lorsqu'elles sont déployées à l'aide de frameworks d'orchestration (tels que Kubernetes). Cette section décrira en détail comment y parvenir.
Nous commençons par créer l'intégralité du jeu de réplicas MongoDB dans un seul cluster Kubernetes (généralement au sein d'un centre de données, qui n'offre évidemment pas de géoredondance). En pratique, il est rarement nécessaire d’effectuer des modifications pour s’exécuter sur plusieurs clusters, et ces étapes sont décrites plus loin.
Chaque membre du jeu de réplicas fonctionnera comme son propre pod et fournira un service avec une adresse IP et un port exposés. Cette adresse IP « fixe » est importante car les applications externes et les autres membres du jeu de réplicas peuvent compter sur elle pour rester inchangée en cas de replanification d'un pod.
L'image ci-dessous illustre l'un des pods et les contrôleurs et services de réplication associés.
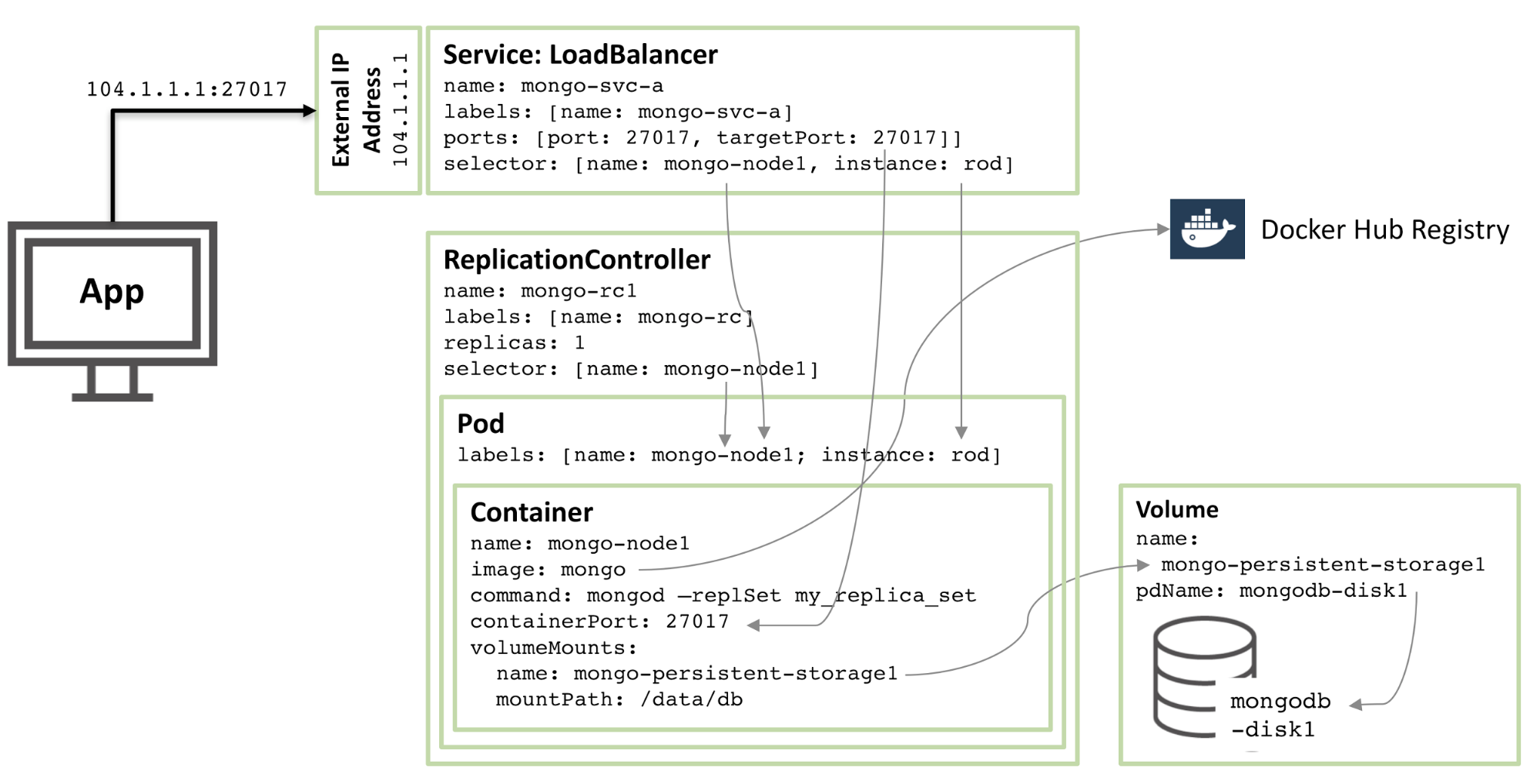
Figure 1 : Membres du jeu de réplicas MongoDB configurés en tant que pods Kubernetes et exposés en tant que services
Figure 1 : membres du jeu de réplicas MongoDB configurés en tant que pods Kubernetes et exposés en tant que services
Une introduction étape par étape aux ressources décrites dans cette configuration :
À partir du noyau, il existe un conteneur appelé mongo-node1. mongo-node1 contient une image nommée mongo, qui est une image de conteneur MongoDB accessible au public et hébergée sur Docker Hub. Le conteneur expose le port 27107 dans le cluster.
La fonctionnalité de volume de données de Kubernetes est utilisée pour mapper le répertoire /data/db du connecteur à un stockage persistant nommé mongo-persistent-storage1, qui à son tour est mappé à un disque nommé mongodb-disk1 créé dans Google Cloud . C'est ici que MongoDB stocke ses données afin qu'elles persistent après la réorchestration du conteneur.
Le conteneur est conservé dans un pod avec une étiquette nommée mongo-node et un exemple (arbitraire) nommé rod .
Configurez le contrôleur de réplication mongo-node1 pour garantir qu'une seule instance du pod mongo-node1 est toujours en cours d'exécution.
Le service d'équilibrage de charge nommé mongo-svc-a ouvre une adresse IP et un port 27017 au monde extérieur, qui sont mappés sur le même numéro de port du conteneur. Le service utilise des sélecteurs pour faire correspondre les étiquettes des pods afin de déterminer le pod correct. L'adresse IP externe et le port seront utilisés pour la communication entre les applications et les membres du jeu de réplicas. Chaque conteneur possède également une adresse IP locale, mais lorsque le conteneur est déplacé ou redémarré, ces adresses IP changent et ne sont donc pas utilisées pour le jeu de réplicas.
Le diagramme suivant montre la configuration du deuxième membre du jeu de réplicas.
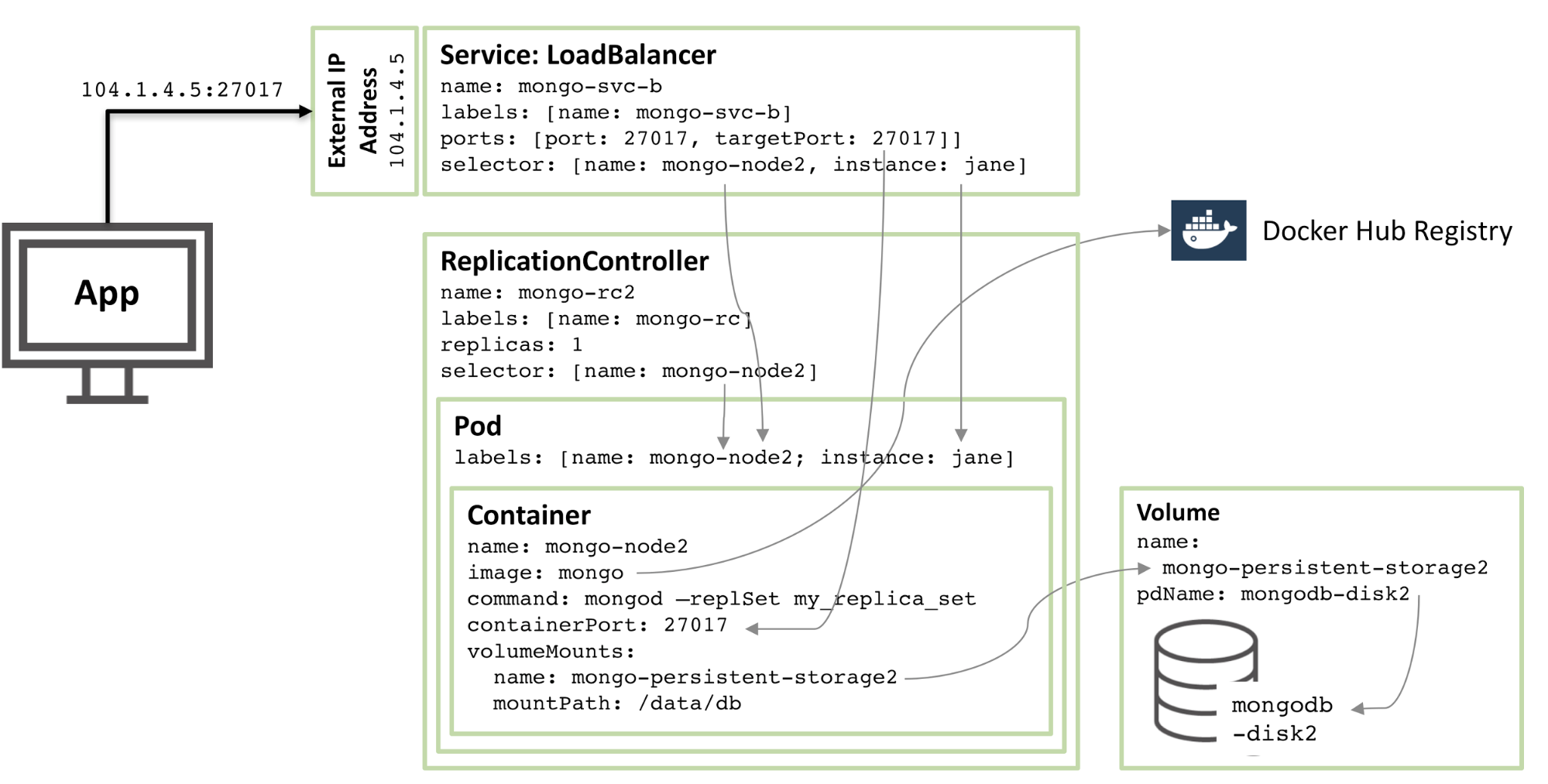
Figure 2 : Deuxième membre du jeu de réplicas MongoDB configuré en tant que pod Kubernetes
Figure 2 : Deuxième membre du jeu de réplicas MongoDB configuré en tant que pod Kubernetes
90% de la configuration est la même, seulement ces changements :
Les noms de disque et de volume doivent être uniques, donc mongodb-disk2 et mongo-persistent-storage2 sont utilisés
Le Pod se voit attribuer une étiquette d'instance : jane et un nom : mongo-node2 afin que le nouveau service puisse être distingué du rod Pod illustré dans la figure 1 à l'aide de sélecteurs.
Le contrôleur de copie s'appelle mongo-rc2
Le service s'appelle mongo-svc-b et reçoit une adresse IP externe unique (dans ce cas, Kubernetes a attribué 104.1.4.5)
La configuration du troisième membre de réplique suit le même modèle, et l'image ci-dessous montre l'ensemble de répliques complet :
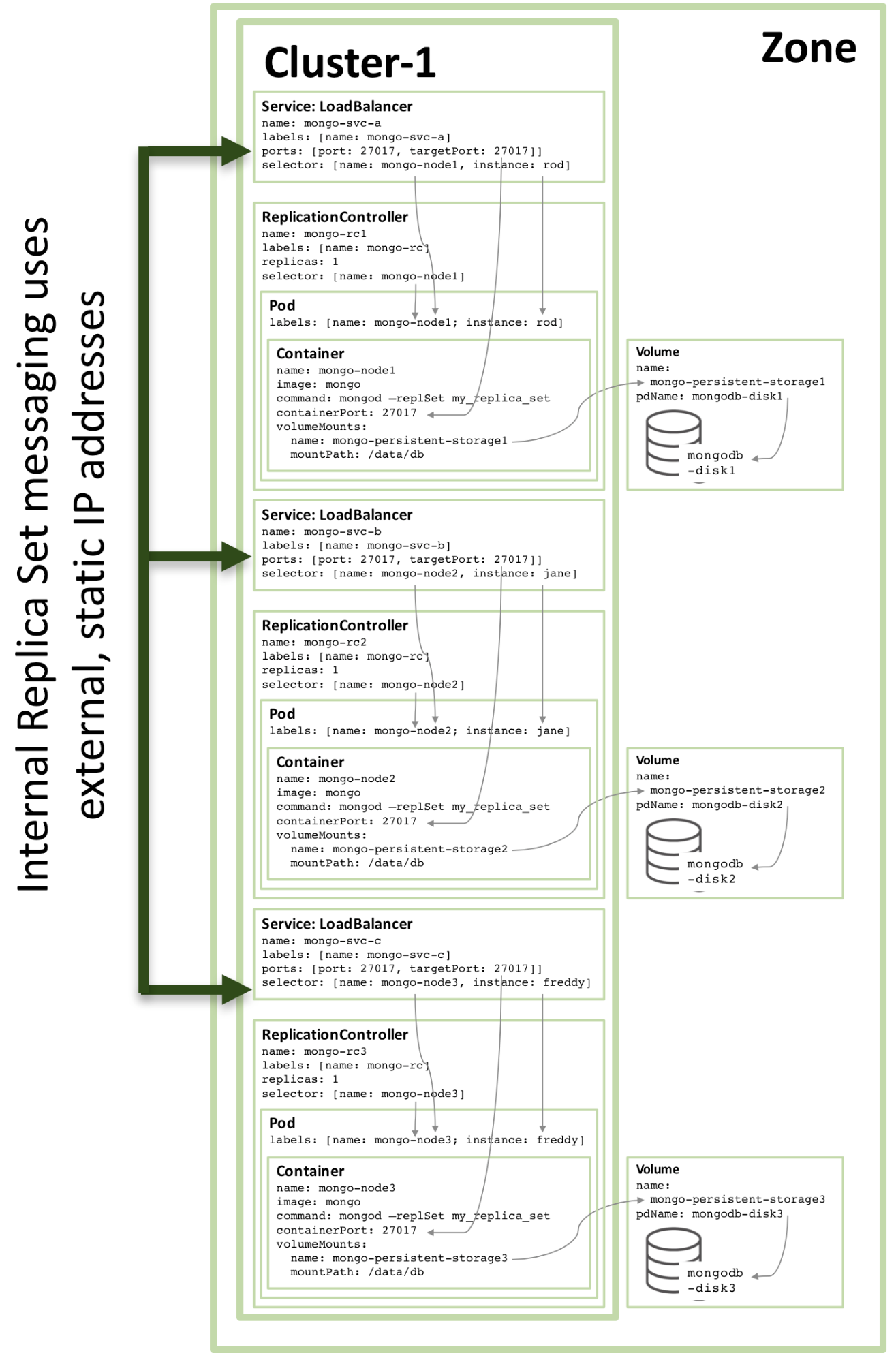
Figure 3 : Membre du jeu de réplicas complet configuré en tant que service Kubernetes
Figure 3 : membre du jeu de réplicas complet configuré en tant que service Kubernetes
Notez que même lors de l'exécution de la configuration présentée dans la figure 3 sur un cluster Kubernetes de trois nœuds ou plus, Kubernetes peut (et le fait souvent) orchestrer deux ou plusieurs membres du jeu de réplicas MongoDB sur le même hôte. En effet, Kubernetes traite les trois pods comme appartenant à trois services distincts.
Pour ajouter de la redondance au sein de la zone, un service headless supplémentaire peut être créé. Le nouveau service ne fournit aucune fonctionnalité au monde extérieur (il n'aura même pas d'adresse IP), mais il permet à Kubernetes de notifier trois pods MongoDB pour former un service, donc Kubernetes essaiera de les orchestrer sur différents nœuds.
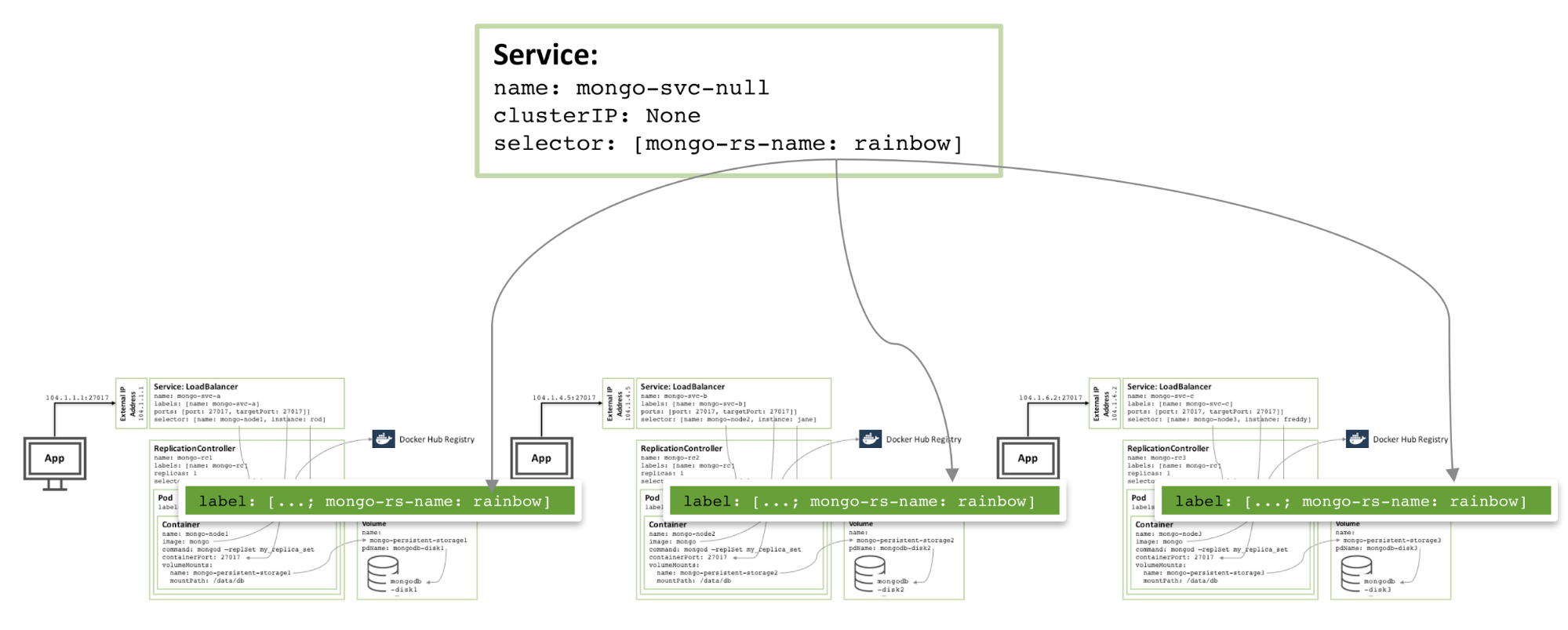
Figure 4 : Services sans tête qui évitent les membres du même jeu de réplicas MongoDB
Figure 4 : Services sans tête qui évitent les membres du même jeu de réplicas MongoDB
Les fichiers de configuration et les commandes requis pour configurer et lancer un jeu de réplicas MongoDB peuvent être trouvés dans le livre blanc Enabling Microservices: Elucidating Containers and Orchestration. En particulier, certaines des étapes spéciales décrites dans cet article sont nécessaires pour combiner trois instances MongoDB en un jeu de réplicas fonctionnel et robuste.
Le jeu de réplicas créé ci-dessus est risqué car tout s'exécute dans le même cluster GCE et donc dans la même zone de disponibilité. Si un événement majeur met une zone de disponibilité hors ligne, le jeu de réplicas MongoDB sera indisponible. Si une redondance géographique est requise, les trois pods doivent s'exécuter dans trois zones de disponibilité ou régions différentes.
Étonnamment, très peu de modifications ont été nécessaires pour créer des jeux de réplicas similaires répartis entre trois régions (nécessitant trois clusters). Chaque cluster nécessite son propre fichier YAML Kubernetes qui définit les pods, les contrôleurs de réplication et les services pour un seul membre de ce jeu de réplicas. Il suffit ensuite de créer un cluster, un stockage persistant et des nœuds MongoDB pour chaque région.
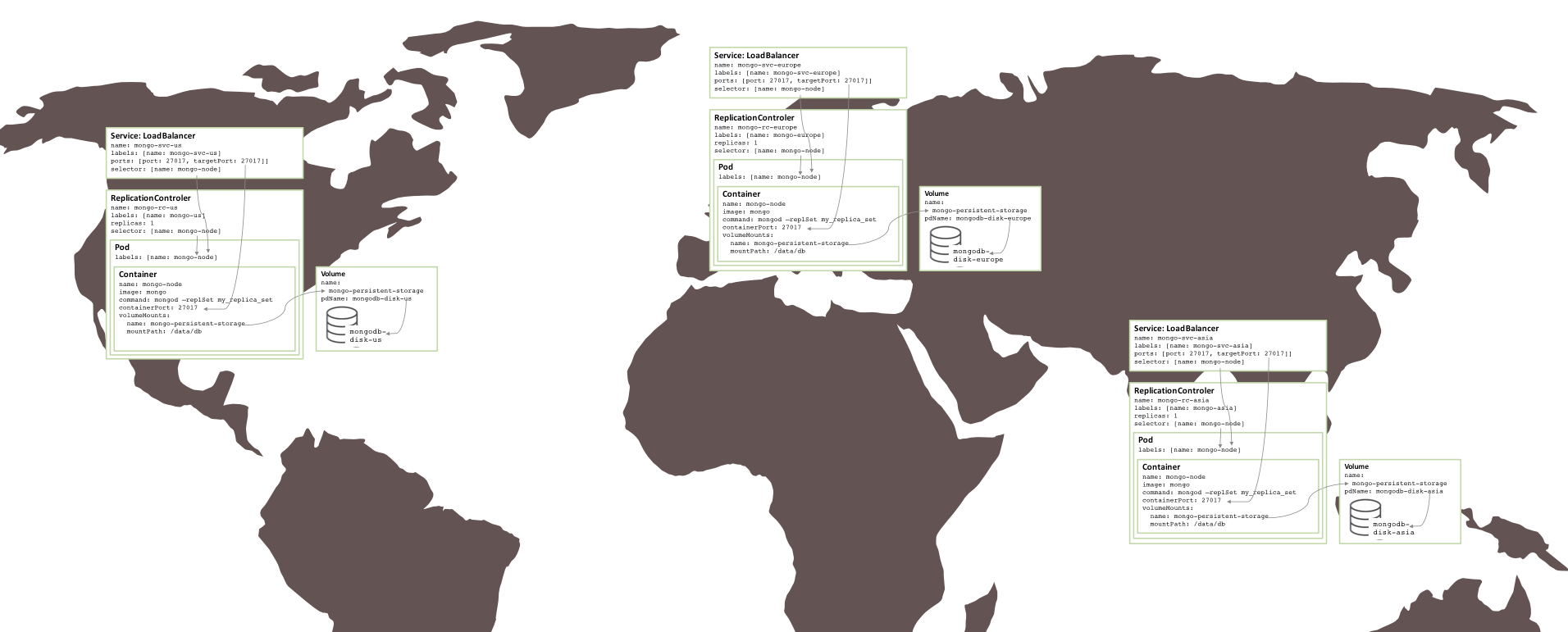
Figure 5 : Ensemble de réplicas exécuté sur plusieurs zones de disponibilité
Figure 5 : Ensemble de réplicas exécuté sur plusieurs zones de disponibilité
Prochaine étape
Pour en savoir plus sur les conteneurs et l'orchestration (les technologies impliquées et les avantages commerciaux qu'elles offrent), lisez le livre blanc Enabling Microservices: Containers and Orchestration Explained. Ce document fournit des instructions complètes pour obtenir le jeu de réplicas décrit dans cet article et l'exécuter sur Docker et Kubernetes dans Google Container Engine.
À propos de l'auteur :
Andrew est le directeur général du marketing produit chez MongoDB. Il a rejoint MongoDB l'été dernier après avoir travaillé chez Oracle, où il a passé plus de six ans dans la gestion de produits en se concentrant sur la haute disponibilité. Il peut être contacté à @andrewmorgan ou en commentant sur son blog (clusterdb.com).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



