

Les modèles linguistiques à grande échelle (LLM) ont fait d'énormes progrès tant dans le monde universitaire que dans l'industrie. Mais la formation et le déploiement du LLM sont très coûteux et nécessitent beaucoup de ressources informatiques et de mémoire. Les chercheurs ont donc développé de nombreux cadres et méthodes open source pour accélérer la pré-formation, le réglage fin et l'inférence du LLM. Cependant, les performances d'exécution des différentes piles matérielles et logicielles peuvent varier considérablement, ce qui rend difficile le choix de la meilleure configuration.
Récemment, un nouvel article intitulé « Dissection des performances d'exécution de la formation, du réglage fin et de l'inférence de grands modèles linguistiques » analyse en détail la formation LLM, le réglage fin et les performances d'exécution de l'inférence.

Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/pdf/2311.03687.pdf
Plus précisément, cette recherche a d'abord été réalisée sur trois 8-GPU à différentes échelles (7B , 13B et 70B) LLM a effectué un test de performance complet sans changer la signification originale de la pré-formation, du réglage fin et du service. Les tests ont porté sur des plates-formes avec et sans technologies d'optimisation individuelles, notamment ZeRO, Quantize, Recalculate et FlashAttention. L'étude fournit ensuite une analyse détaillée du temps d'exécution des sous-modules des opérateurs de calcul et de communication dans LLM
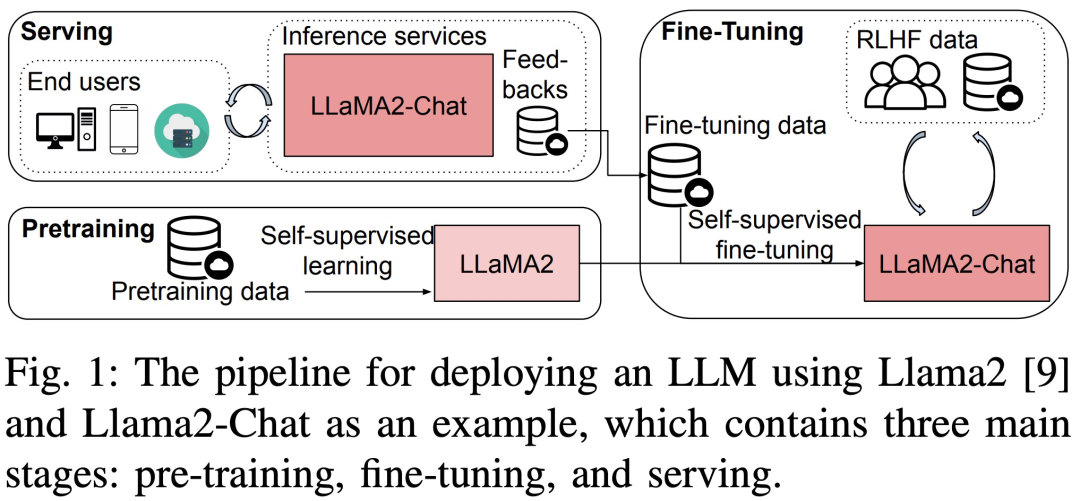
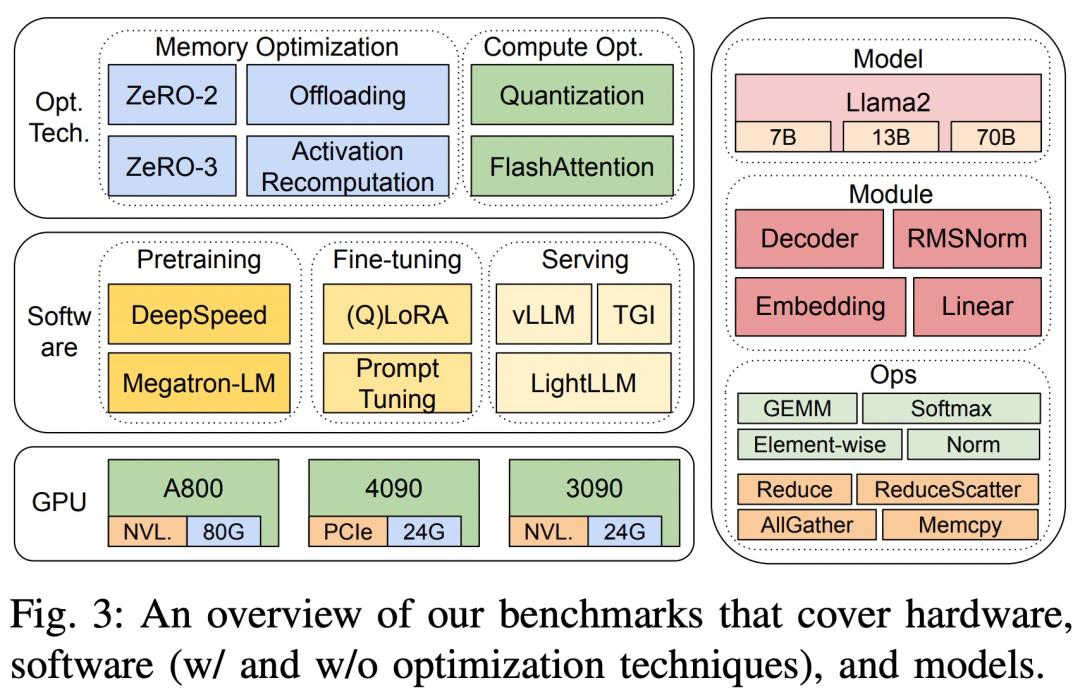
Les références de l'étude adoptent une approche descendante, couvrant Llama2 en trois étapes de bout en bout. Les performances temporelles pas à pas, les performances temporelles au niveau du module et les performances temporelles de l'opérateur sur une plate-forme matérielle à 8 GPU sont présentées dans la figure 3.
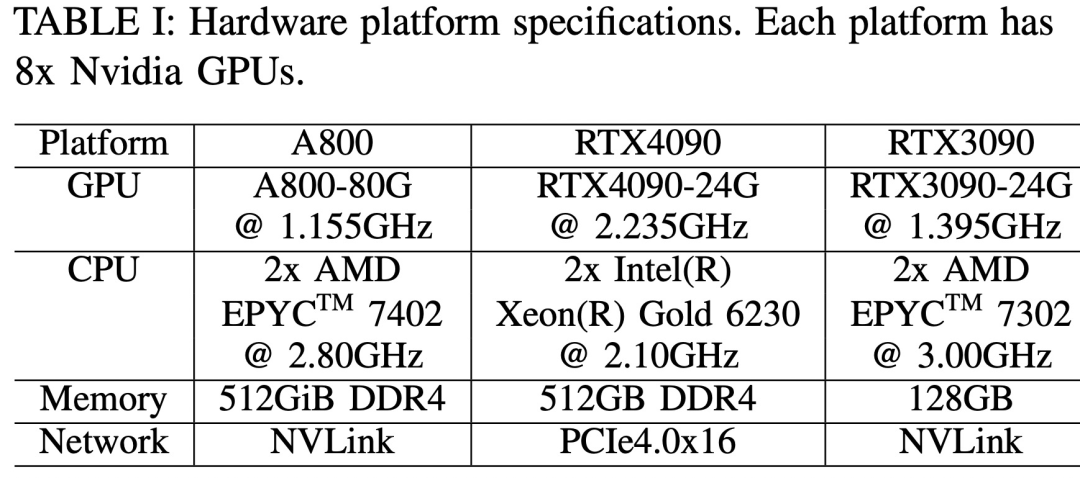
Les trois plates-formes matérielles sont RTX4090, RTX3090 et A800. Les spécifications spécifiques sont présentées dans le tableau 1 ci-dessous.
Côté logiciel, l'étude a comparé les temps de pas de bout en bout de DeepSpeed et Megatron-LM en termes de pré-entraînement et de réglage fin. Pour évaluer les techniques d'optimisation, l'étude a utilisé DeepSpeed pour activer les optimisations suivantes une par une : ZeRO-2, ZeRO-3, déchargement, recalcul d'activation, quantification et FlashAttention pour mesurer les améliorations de performances et les réductions de temps et de consommation de mémoire.
En termes de services LLM, il existe trois systèmes hautement optimisés, vLLM, LightLLM et TGI, et cette étude compare leurs performances (latence et débit) sur trois plateformes de tests.
Afin de garantir l'exactitude et la reproductibilité des résultats, cette étude a calculé la longueur moyenne des instructions, des entrées et des sorties de l'ensemble de données commun LLM alpaga, soit 350 jetons par échantillon, et des chaînes générées aléatoirement pour atteindre Longueur de séquence de 350.
Dans le service d'inférence, afin d'utiliser de manière globale les ressources informatiques et d'évaluer la robustesse et l'efficacité du framework, toutes les requêtes sont planifiées en mode rafale. L'ensemble de données expérimentales se compose de 1 000 phrases synthétiques, chaque phrase contient 512 jetons d'entrée. Cette étude maintient toujours le paramètre « longueur maximale du jeton généré » dans toutes les expériences sur la même plate-forme GPU afin de garantir la cohérence et la comparabilité des résultats.
Pas besoin de changer le sens original, pleine performance
Cette étude utilise des indicateurs tels que le pré-entraînement, le réglage fin et l'inférence du temps de pas, le débit et la consommation de mémoire des modèles Llama2 de différents tailles (7B, 13B et 70B), pour mesurer toutes les performances sur trois plates-formes de test sans changer la signification originale. Trois systèmes de service d'inférence largement utilisés : TGI, vLLM et LightLLM sont également évalués, en se concentrant sur des mesures telles que la latence, le débit et la consommation de mémoire.
Performance au niveau du module
LLM se compose généralement d'une série de modules (ou couches) qui peuvent avoir des caractéristiques informatiques et de communication uniques. Par exemple, les modules clés qui composent le modèle Llama2 sont Embedding, LlamaDecoderLayer, Linear, SiLUActivation et LlamaRMSNorm.
Au cours de la session d'expérimentation de pré-entraînement, les chercheurs ont d'abord analysé les performances de pré-entraînement (temps d'itération ou débit, consommation de mémoire) de modèles de différentes tailles (7B, 13B et 70B) sur trois tests Des micro-benchmarks aux niveaux des modules et des opérations ont ensuite été réalisés.
Pas besoin de changer le sens original, des performances complètes
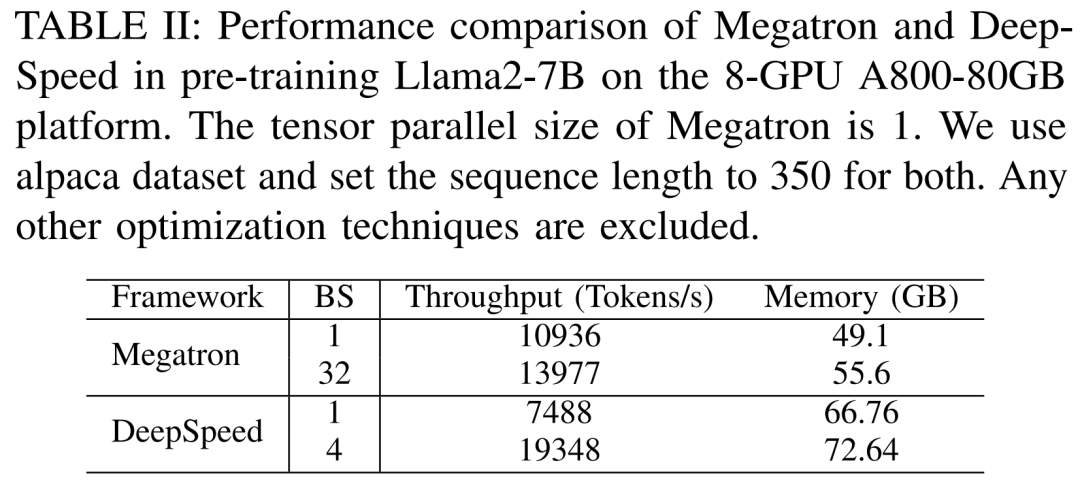
Les chercheurs ont d'abord mené des expériences pour comparer les performances de Megatron-LM et DeepSpeed, qui n'ont pas été utilisés lors du pré-entraînement de Llama2-7B sur le serveur A800-80GB. Toute technologie d'optimisation de la mémoire (telle que ZeRO).
Ils ont utilisé une longueur de séquence de 350 et ont fourni deux ensembles de tailles de lots pour Megatron-LM et DeepSpeed, de 1 à la taille de lot maximale. Les résultats sont présentés dans le tableau II ci-dessous, comparés au débit d'entraînement (jetons/seconde) et à la mémoire GPU grand public (en Go).
Les résultats montrent que lorsque la taille du lot est de 1, Megatron-LM est légèrement plus rapide que DeepSpeed. Cependant, DeepSpeed est la vitesse d'entraînement la plus rapide lorsque la taille du lot atteint son maximum. Lorsque les tailles de lots sont les mêmes, DeepSpeed consomme plus de mémoire GPU que le Megatron-LM basé sur un tenseur parallèle. Même avec des lots de petite taille, les deux systèmes consommaient des quantités importantes de mémoire GPU, provoquant un débordement de mémoire sur les serveurs GPU RTX4090 ou RTX3090.
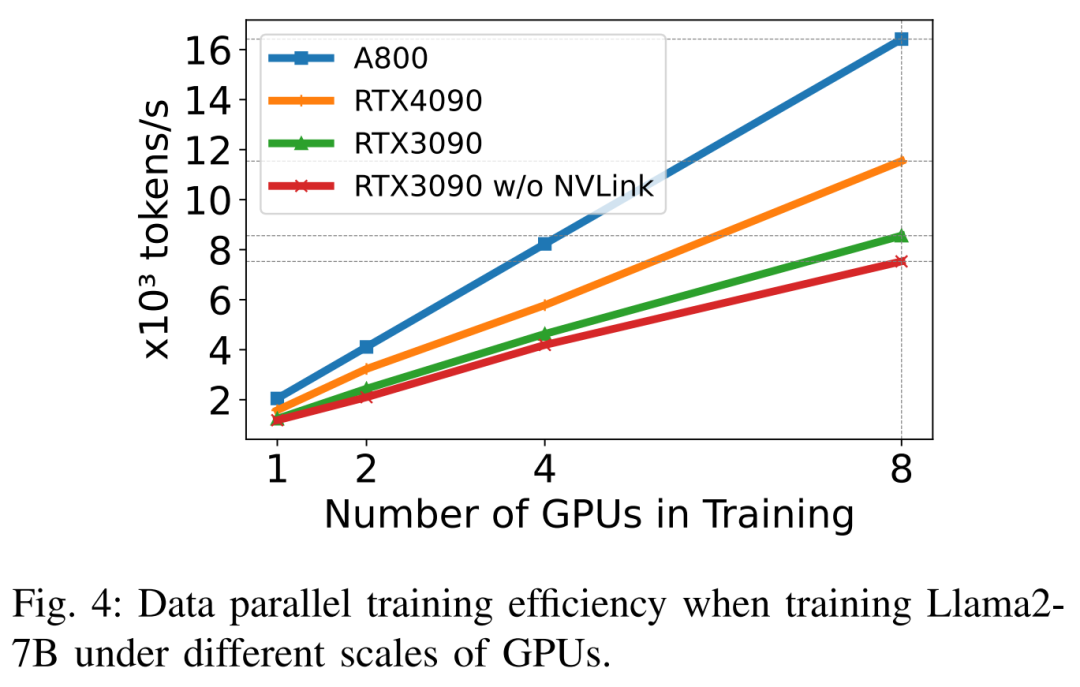
Lors de la formation de Llama2-7B (longueur de séquence 350, taille de lot 2), les chercheurs ont utilisé DeepSpeed avec quantification pour étudier l'efficacité de la mise à l'échelle sur différentes plates-formes matérielles. Les résultats sont présentés dans la figure 4 ci-dessous. L'A800 évolue de manière presque linéaire, et l'efficacité de mise à l'échelle des RTX4090 et RTX3090 est légèrement inférieure, à 90,8 % et 85,9 % respectivement. Sur la plateforme RTX3090, les connexions NVLink sont 10 % plus efficaces que sans NVLink.
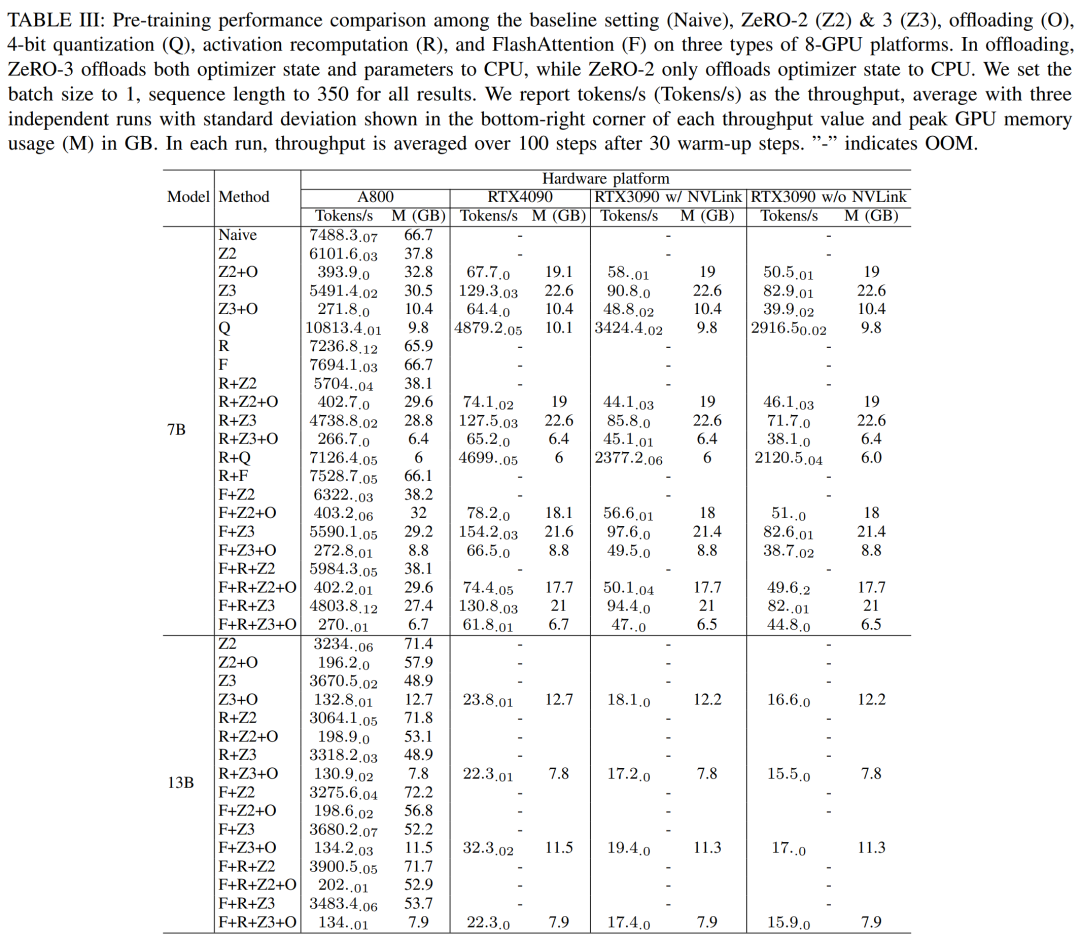
Les chercheurs utilisent DeepSpeed pour évaluer les performances d'entraînement sous différentes méthodes de mémoire et de calcul efficaces. Par souci d'équité, toutes les évaluations sont définies sur une longueur de séquence de 350, une taille de lot de 1 et un poids de modèle chargé par défaut de bf16.
Pour les ZeRO-2 et ZeRO-3 dotés de capacités de déchargement, ils déchargent respectivement l'état de l'optimiseur et l'état de l'optimiseur + le modèle vers la RAM du processeur. Pour la quantification, ils ont utilisé une configuration 4 bits avec double quantification. Les performances du RTX3090 lorsque NVLink est désactivé (c'est-à-dire que toutes les données sont transférées via le bus PCIe) sont également signalées. Les résultats sont présentés dans le tableau III ci-dessous.
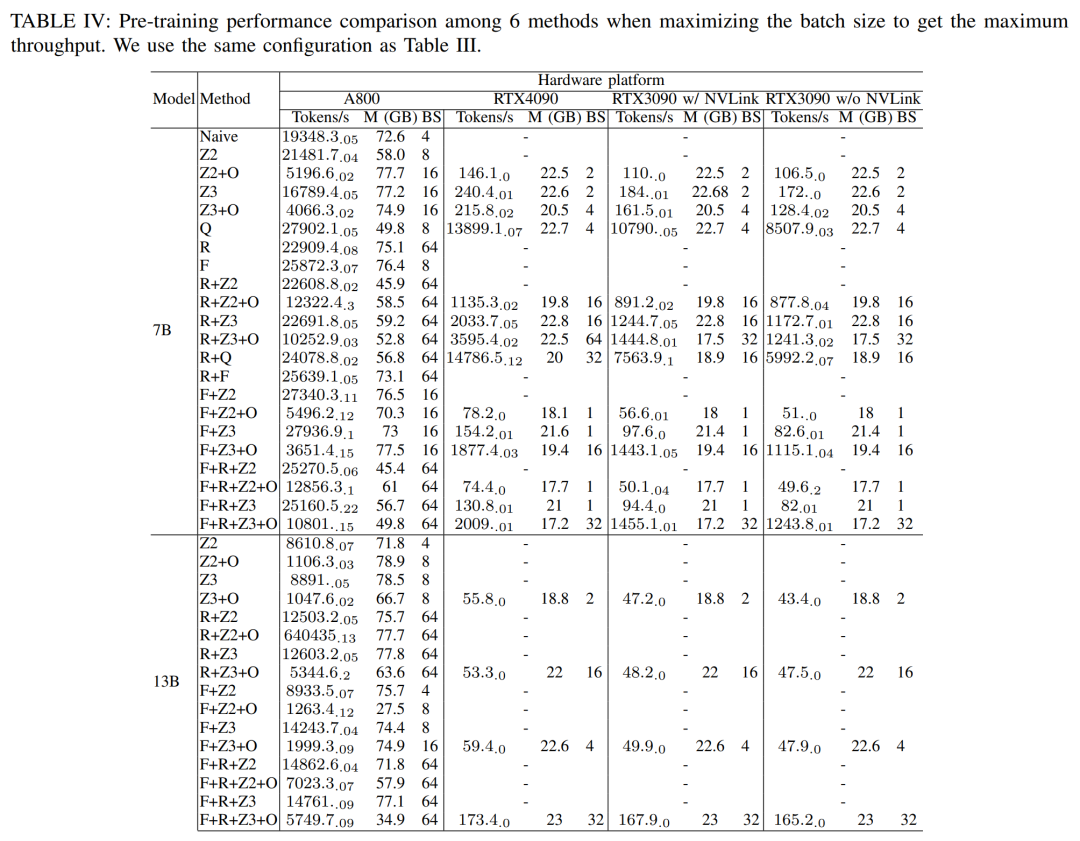
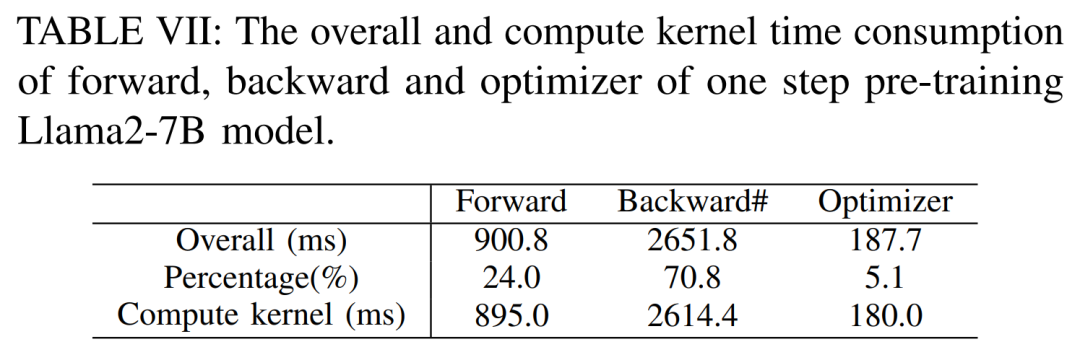
Pour obtenir un débit maximal, les chercheurs ont ensuite utilisé la puissance de calcul de différents serveurs GPU en maximisant la taille des lots de chaque méthode. Les résultats sont présentés dans le tableau IV, montrant qu'augmenter la taille du lot peut facilement améliorer le processus de formation. Par conséquent, les serveurs GPU dotés d'une bande passante élevée et d'une grande mémoire sont plus adaptés à l'entraînement de précision mixte à paramètres complets que les serveurs GPU grand public. Coût global et en temps de calcul de l'entraînement avant, arrière et de l'optimiseur du modèle Llama2-7B. Pour la phase arrière, étant donné que le temps total inclut le temps sans chevauchement, le temps de calcul du cœur est beaucoup plus petit que celui de la phase avant et de l'optimiseur. Si le temps sans chevauchement est supprimé de la phase arrière, la valeur devient 94,8.
Besoin de recalculer et de réévaluer l'impact de FlashAttention
Les techniques permettant d'accélérer la pré-formation peuvent être grossièrement divisées en deux catégories : économiser de la mémoire, augmenter la taille des lots et accélérer le calcul noyaux. Comme le montre la figure 5 ci-dessous, le GPU passe 5 à 10 % de son temps inactif pendant les phases d'avancement, de retour et d'optimisation.
Les chercheurs pensaient que ce temps d'inactivité était dû à des lots plus petits, ils ont donc testé toutes les techniques avec les plus grandes tailles de lots disponibles. Enfin, ils ont adopté le recalcul pour augmenter la taille du lot et utilisé FlashAttention pour accélérer le calcul de l'analyse de base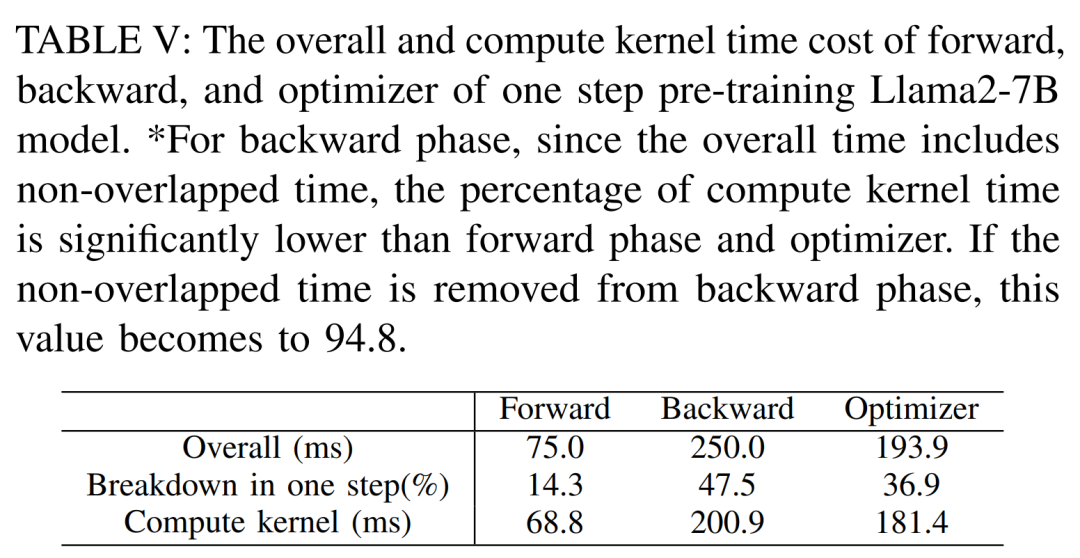
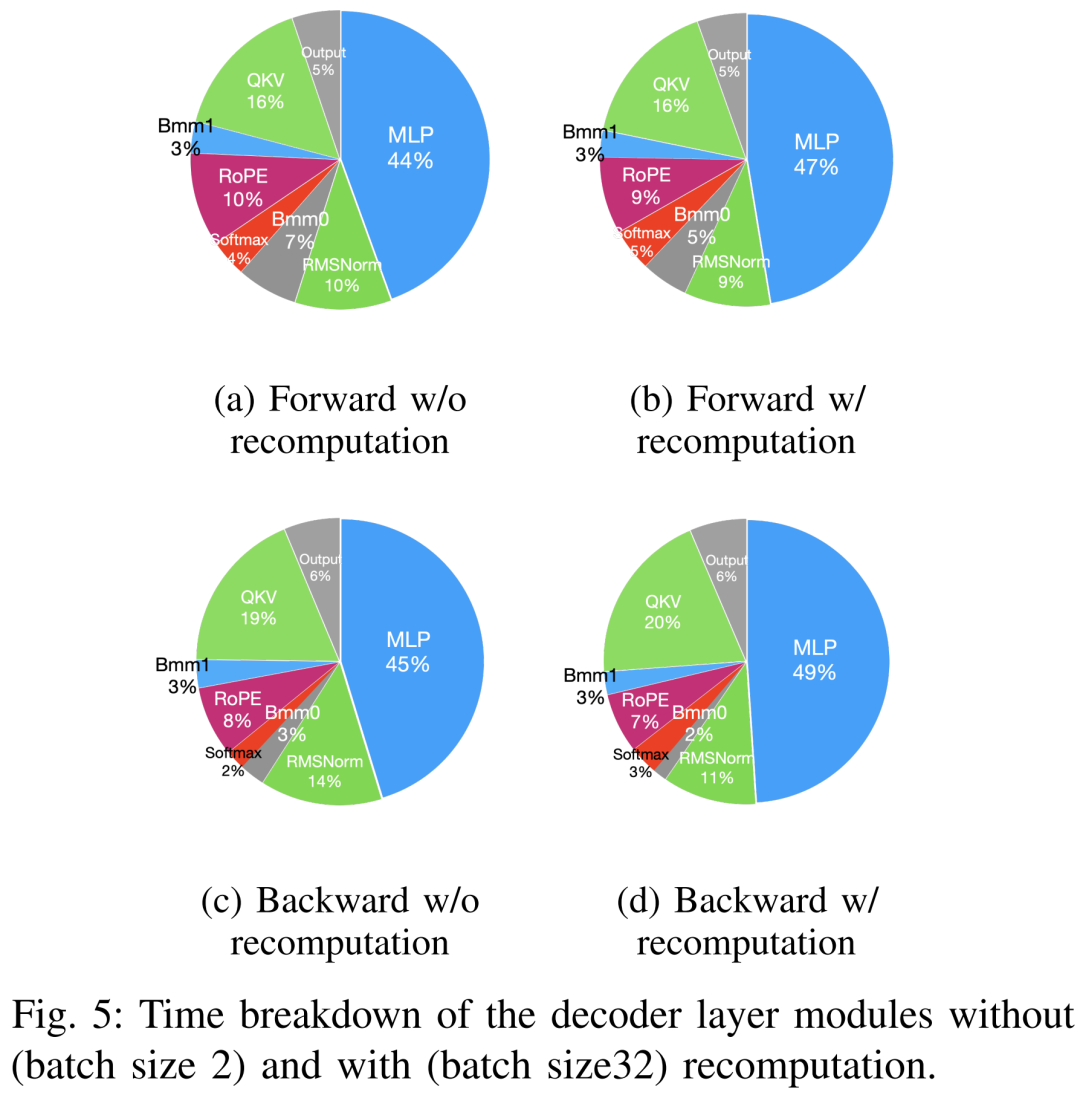
Comme le montre le tableau VII ci-dessous, à mesure que la taille du lot augmente, les temps de phase avant et arrière augmentent considérablement, ne laissant pratiquement aucun temps d'inactivité du GPU.
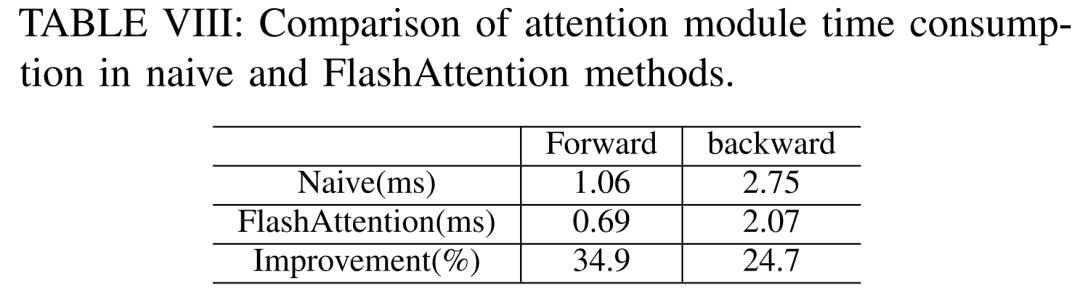
Selon le tableau VIII ci-dessous, FlashAttention peut accélérer les modules d'attention avant et arrière de 34,9 % et 24,7 % respectivement
Dans le processus de réglage fin , les chercheurs La méthode de réglage fin efficace des paramètres (PEFT) est principalement discutée pour démontrer les performances de réglage fin de LoRA et QLoRA sous différentes tailles de modèles et paramètres matériels. Utilisez une longueur de séquence de 350, une taille de lot de 1 et chargez les poids du modèle dans bf16 par défaut.
Selon les résultats du tableau IX ci-dessous, la tendance des performances après le réglage fin de Llama2-13B à l'aide de LoRA et QLoRA est cohérente avec celle de Llama2-7B. Par rapport à Llama2-7B, le débit du Llama2-13B affiné a chuté d'environ 30 %
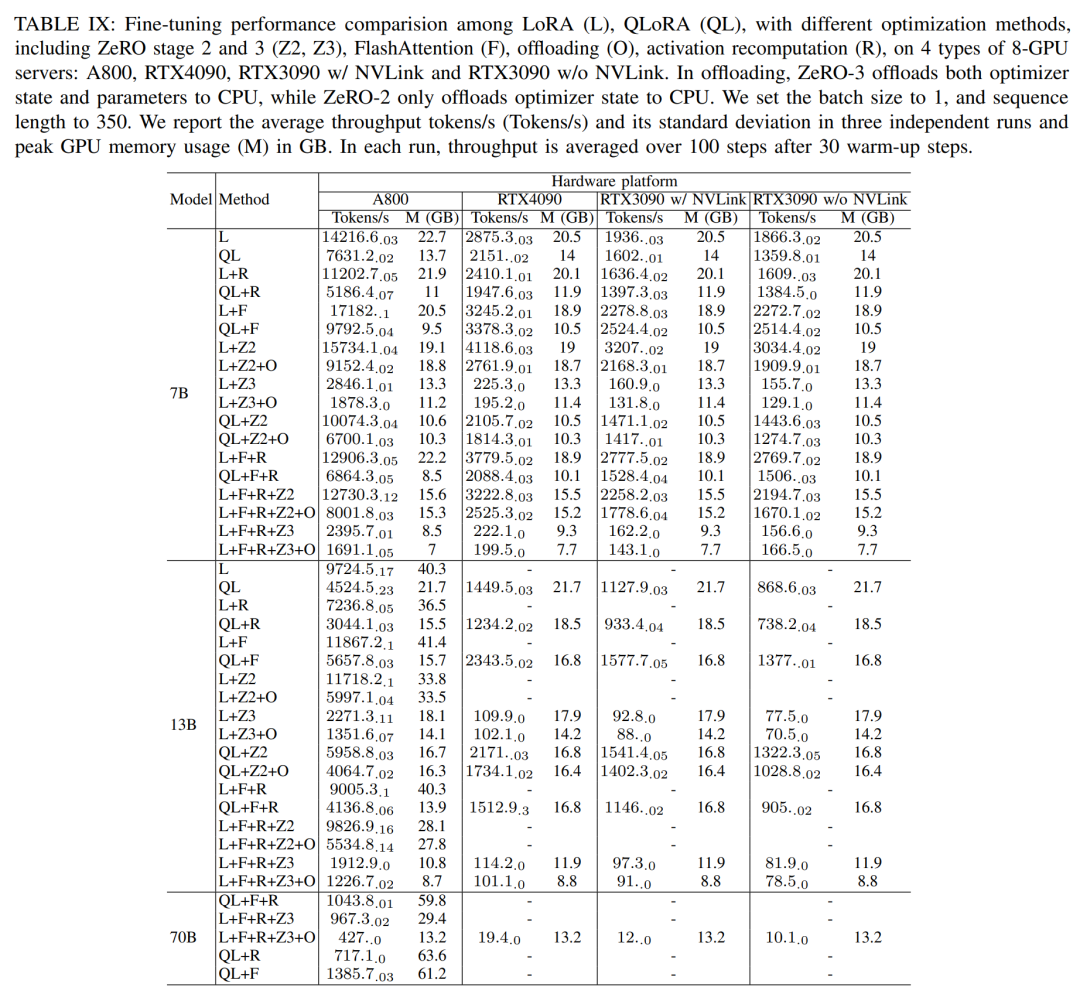
Cependant, lorsque toutes les techniques d'optimisation sont combinées, même le RTX4090 et le RTX3090 peuvent affiner le Llama2-70B pour atteindre 200 jetons/sec débit total.
Pas besoin de changer le sens original, performances complètes
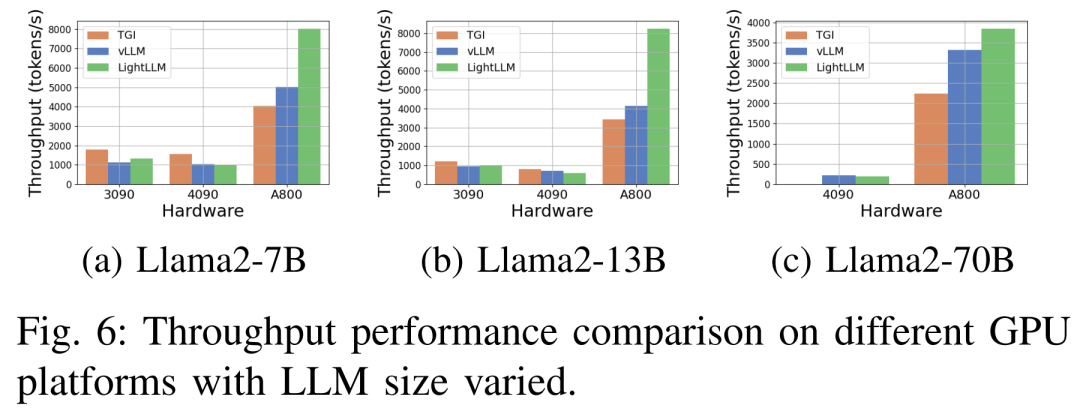
La figure 6 ci-dessous montre une analyse complète du débit sous diverses plates-formes matérielles et cadres d'inférence, qui omet Llama2-70B données d’inférence associées. Parmi eux, le framework TGI a démontré un excellent débit, notamment sur les GPU dotés de 24 Go de mémoire tels que les RTX3090 et RTX4090. De plus, LightLLM surpasse considérablement TGI et vLLM sur la plate-forme GPU A800, avec un débit presque doublé.
Ces résultats expérimentaux montrent que le cadre d'inférence TGI a d'excellentes performances sur la plate-forme GPU de 24 Go de mémoire, tandis que le cadre d'inférence LightLLM présente le débit le plus élevé sur la plate-forme GPU A800 de 80 Go. Cette découverte suggère que LightLLM est optimisé spécifiquement pour la série A800/A100 de GPU hautes performances.
Les performances de latence sous différentes plates-formes matérielles et cadres d'inférence sont présentées dans les figures 7, 8, 9 et 10
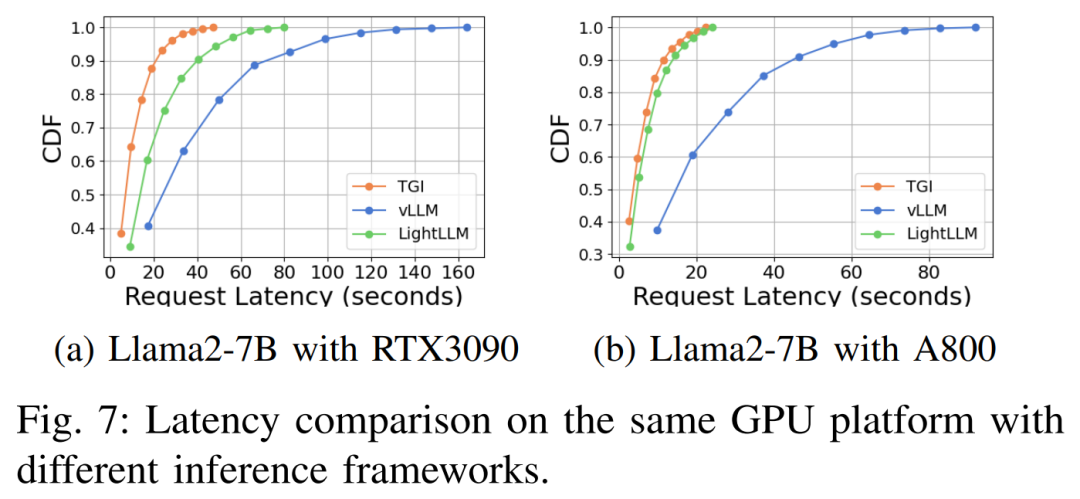
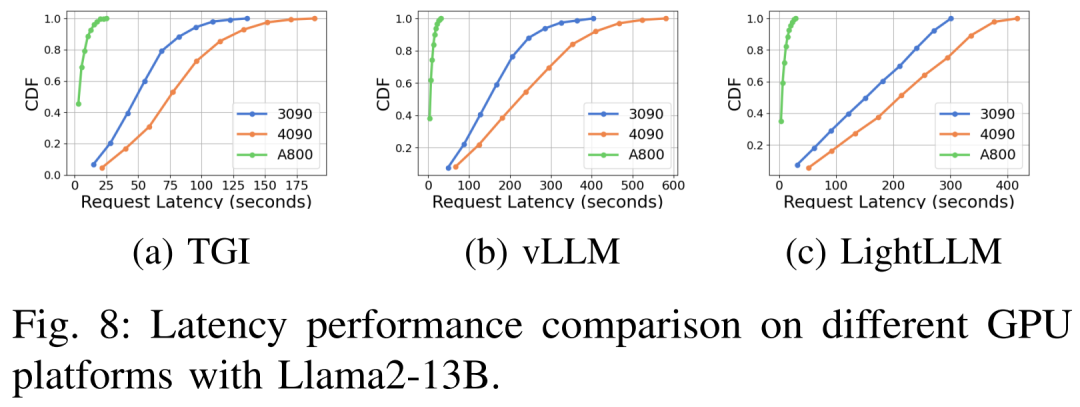
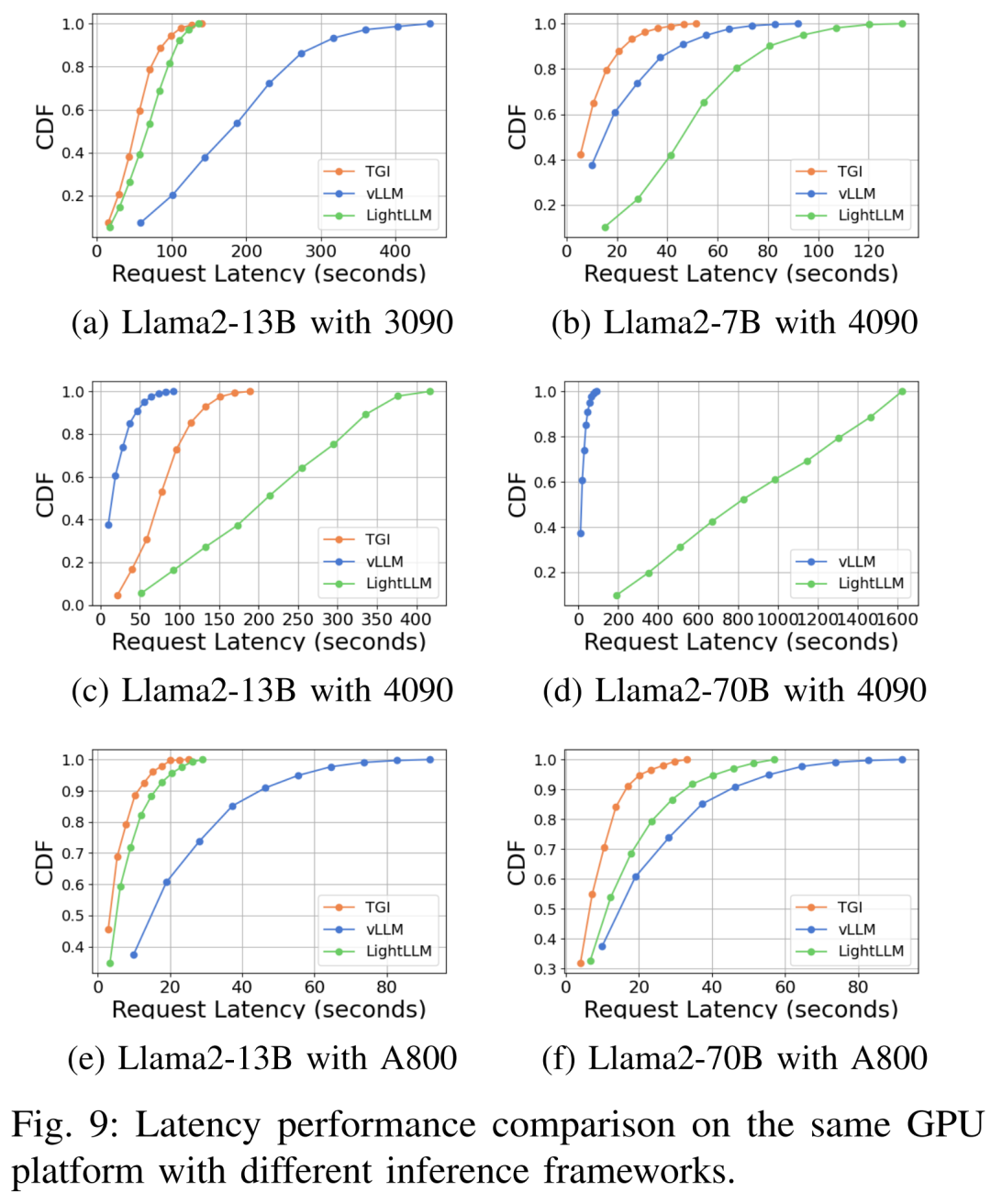
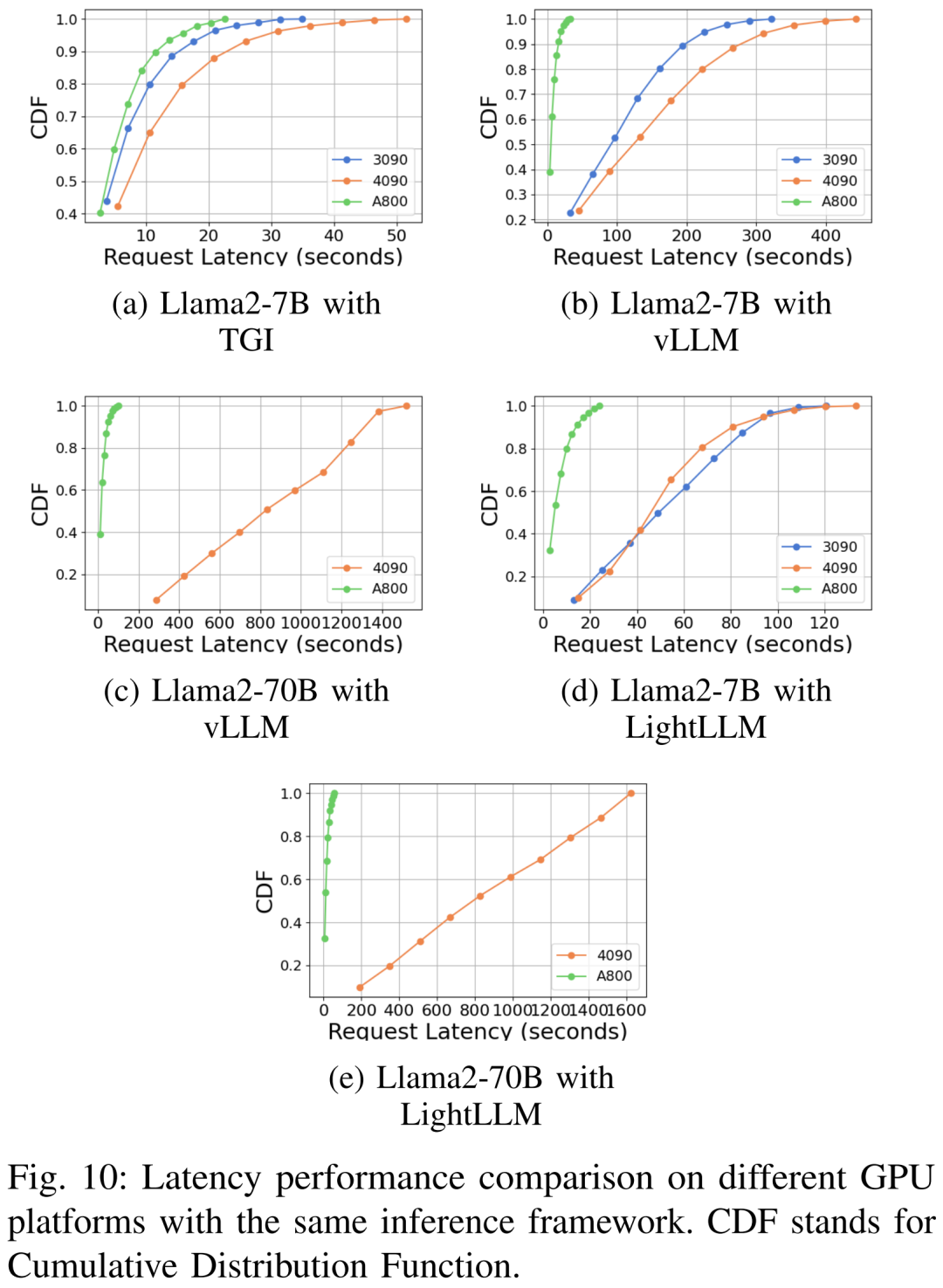
Complet Comme indiqué ci-dessus, la plateforme A800 est nettement meilleure que les deux plateformes grand public RTX4090 et RTX3090 en termes de débit et de latence. Et parmi les deux plates-formes grand public, le RTX3090 présente un léger avantage par rapport au RTX4090. Les trois frameworks d'inférence TGI, vLLM et LightLLM ne montrent aucune différence substantielle en termes de débit lorsqu'ils sont exécutés sur des plates-formes grand public. En comparaison, TGI surpasse systématiquement les deux autres en termes de latence. Sur la plateforme GPU A800, LightLLM est plus performant en termes de débit et sa latence est également très proche du framework TGI.
Veuillez vous référer au texte original pour plus de résultats expérimentaux
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 La différence entre la liaison bidirectionnelle vue2 et vue3
La différence entre la liaison bidirectionnelle vue2 et vue3
 Il existe plusieurs façons de positionner la position CSS
Il existe plusieurs façons de positionner la position CSS
 Quelle est la différence entre une machine de démonstration et une vraie machine ?
Quelle est la différence entre une machine de démonstration et une vraie machine ?
 Quels sont les logiciels de sauvegarde de données ?
Quels sont les logiciels de sauvegarde de données ?
 Quels problèmes le bouillonnement d'événements js peut-il résoudre ?
Quels problèmes le bouillonnement d'événements js peut-il résoudre ?
 convertir l'utilisation de la commande
convertir l'utilisation de la commande
 Comment définir le statut hors ligne sur Douyin
Comment définir le statut hors ligne sur Douyin
 Comment résoudre les erreurs de paramètres de disque
Comment résoudre les erreurs de paramètres de disque








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



