
 Périphériques technologiques
IA
Une étude complète des techniques d'atténuation des hallucinations dans l'apprentissage automatique à grande échelle
Périphériques technologiques
IA
Une étude complète des techniques d'atténuation des hallucinations dans l'apprentissage automatique à grande échelle
Une étude complète des techniques d'atténuation des hallucinations dans l'apprentissage automatique à grande échelle

Les grands modèles linguistiques (LLM) sont des réseaux de neurones profonds avec de grandes quantités de paramètres et de données, capables d'accomplir diverses tâches dans le domaine du traitement du langage naturel (NLP), telles que la compréhension et la génération de textes. Ces dernières années, avec l'amélioration de la puissance de calcul et de l'échelle des données, les LLM ont fait des progrès remarquables, comme GPT-4, BART, T5, etc., démontrant de fortes capacités de généralisation et de créativité.
Les LLM ont également de sérieux problèmes. Lors de la génération de texte, il est facile de produire un contenu qui n'est pas cohérent avec les faits réels ou les entrées de l'utilisateur, c'est-à-dire des hallucinations. Ce phénomène réduira non seulement les performances du système, mais affectera également les attentes et la confiance des utilisateurs, et entraînera même certains risques de sécurité et d'éthique. Par conséquent, comment détecter et atténuer les hallucinations dans les LLM est devenu un sujet important et urgent dans le domaine actuel de la PNL.
Le 1er janvier, plusieurs scientifiques de l'Université islamique des sciences et technologies du Bangladesh, de l'Institut d'intelligence artificielle de l'Université de Caroline du Sud aux États-Unis, de l'Université de Stanford aux États-Unis et du Département d'intelligence artificielle d'Amazon à aux États-Unis, SM Towhidul Islam Tonmoy, SM Mehedi Zaman et Vinija Jain, Anku Rani, Vipula Rawte, Aman Chadha et Amitava Das ont publié un article intitulé « A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models », qui vise à introduire et classer les techniques d'atténuation des hallucinations dans les grands modèles de langage (LLM).

Ils ont d'abord présenté la définition, les causes et les effets des hallucinations, ainsi que les méthodes d'évaluation. Ils proposent ensuite un système de classification détaillé qui divise les techniques d'atténuation des hallucinations en quatre catégories principales : basées sur des ensembles de données, basées sur des tâches, basées sur des commentaires et basées sur la récupération. Au sein de chaque catégorie, ils subdivisent en outre différentes sous-catégories et illustrent certaines méthodes représentatives.
Les auteurs analysent également les avantages, les inconvénients, les défis et les limites de ces technologies, ainsi que les orientations de recherche futures. Ils ont souligné que la technologie actuelle présente encore certains problèmes, tels qu'un manque de généralité, d'interprétabilité, d'évolutivité et de robustesse. Ils ont suggéré que les recherches futures devraient se concentrer sur les aspects suivants : développer des méthodes de détection et de quantification des hallucinations plus efficaces, tirer parti des informations multimodales et des connaissances de bon sens, concevoir des cadres d'atténuation des hallucinations plus flexibles et personnalisables et prendre en compte la participation et les commentaires humains.
1. Système de classification des hallucinations dans les LLM
Afin de mieux comprendre et décrire le problème des hallucinations dans les LLM, ils ont proposé un système de classification basé sur la source, le type, le degré et l'impact des hallucinations, comme le montre Figure 1 Afficher. Ils pensent que ce système peut couvrir tous les aspects des hallucinations dans les LLM, aider à analyser les causes et les caractéristiques des hallucinations et à évaluer la gravité et les méfaits des hallucinations.
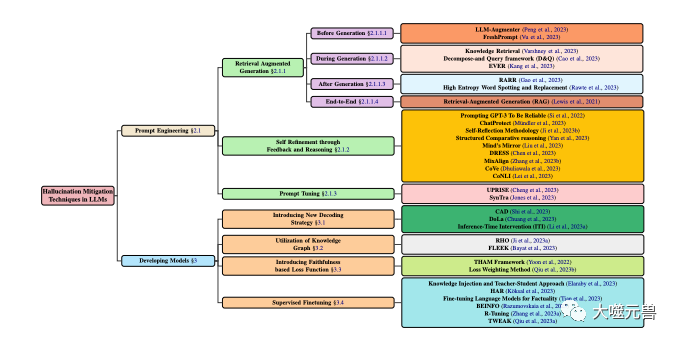 Figure 1
Figure 1
Classification des techniques d'atténuation des hallucinations en LLM, en se concentrant sur les méthodes populaires impliquant le développement de modèles et les techniques d'incitation. Le développement du modèle est divisé en diverses méthodes, notamment de nouvelles stratégies de décodage, l'optimisation basée sur des graphes de connaissances, l'ajout de nouveaux composants de fonction de perte et un réglage fin supervisé. Parallèlement, l'ingénierie des signaux peut inclure des méthodes basées sur l'amélioration de la récupération, des stratégies basées sur le feedback ou des ajustements des signaux.
La source des hallucinations
La source des hallucinations est la cause profonde des hallucinations dans les LLM, qui peuvent être résumées dans les trois catégories suivantes :
Connaissances paramétriques : les LLM apprennent grâce à une formation à grande échelle en la phase de pré-formation Connaissances implicites apprises à partir de textes non étiquetés, telles que la grammaire, la sémantique, le bon sens, etc. Ces connaissances sont généralement stockées dans les paramètres des LLM et peuvent être invoquées via des fonctions d'activation et des mécanismes d'attention. La connaissance paramétrique est la base des LLM, mais elle peut aussi être source d'illusions car elle peut contenir des informations inexactes, obsolètes ou biaisées, ou entrer en conflit avec des informations saisies par l'utilisateur.
Connaissances non paramétriques : connaissances explicites que les LLM obtiennent à partir de données annotées externes pendant la phase de mise au point ou de génération, telles que des faits, des preuves, des citations, etc. Ces connaissances existent généralement sous forme structurée ou non structurée et sont accessibles via des mécanismes de récupération ou de mémoire. Les connaissances non paramétriques sont complémentaires des LLM, mais peuvent également être source d'illusions, car elles peuvent contenir du bruit, des données erronées ou incomplètes, ou être incohérentes avec les connaissances paramétriques des LLM.
Stratégie de génération : fait référence à certaines technologies ou méthodes utilisées par les LLM lors de la génération de texte, telles que les algorithmes de décodage, les codes de contrôle, les invites, etc. Ces stratégies sont des outils pour les LLM, mais elles peuvent également être une source d'illusions, car elles peuvent amener les LLM à trop s'appuyer sur ou à ignorer certaines connaissances, ou à introduire des biais ou du bruit dans le processus de génération.
Types d'hallucinations
Les types d'hallucinations font référence aux manifestations spécifiques des hallucinations générées par les LLM, qui peuvent être divisées en quatre catégories suivantes :
Hallucination grammaticale : fait référence aux erreurs grammaticales dans le texte généré par les LLM. Ou des irrégularités, telles que des fautes d’orthographe, des erreurs de ponctuation, des erreurs d’ordre des mots, des erreurs de temps, une incohérence sujet-verbe, etc. Cette illusion est généralement causée par une compréhension incomplète des règles du langage par les LLM ou par un surajustement à des données bruitées.
Hallucination sémantique : fait référence aux erreurs sémantiques ou au caractère déraisonnable du texte généré par les LLM, telles que les erreurs de signification de mot, les erreurs de référence, les erreurs logiques, les ambiguïtés, les contradictions, etc. Cette illusion est souvent causée par une compréhension inadéquate du sens du langage par les LLM ou par un traitement insuffisant de données complexes.
Hallucination des connaissances : fait référence au fait que le texte généré par les LLM contient des erreurs ou des incohérences dans les connaissances, telles que des erreurs factuelles, des erreurs de preuves, des erreurs de citation, des incohérences avec la saisie ou le contexte, etc. Cette illusion est généralement causée par une acquisition incorrecte ou une utilisation inappropriée des connaissances par les LLM.
Creative Hallucination : fait référence au texte généré par les LLM qui comporte des erreurs créatives ou des aspects inappropriés, tels que des erreurs de style, des erreurs émotionnelles, des points de vue erronés, une incompatibilité avec des tâches ou des objectifs, etc. Cette illusion est souvent causée par le contrôle déraisonnable des LLM sur la création ou par une évaluation inadéquate.
Degré d'hallucinations
Le degré d'hallucinations fait référence à la quantité et à la qualité des hallucinations générées par les LLM, qui peuvent être divisées en trois catégories suivantes :
Hallucination légère : les hallucinations sont moins nombreuses et plus légères, n'affecte pas la lisibilité et l'intelligibilité globales du texte et ne porte pas atteinte au message principal et à l'objectif du texte. Par exemple, les LLM génèrent des erreurs grammaticales mineures, ou des ambiguïtés sémantiques, ou des erreurs de connaissances détaillées, ou des différences subtiles et créatives.
Hallucination modérée : Il existe des hallucinations nombreuses et lourdes, qui affectent une partie de la lisibilité et de l'intelligibilité du texte, et endommagent également les informations secondaires et le but du texte. Habituellement, les LLM génèrent de grosses erreurs grammaticales ou une certaine irrationalité sémantique.
Hallucination sévère : Les hallucinations sont très nombreuses et très lourdes, affectant la lisibilité et l'intelligibilité globale du texte, et détruisant également le message principal et le but du texte.
L'impact des hallucinations
L'impact des hallucinations fait référence aux conséquences potentielles des hallucinations générées par les LLM sur les utilisateurs et les systèmes, qui peuvent être divisées en trois catégories suivantes :
Hallucination inoffensive : Hallucination inoffensive : effets sur les utilisateurs et les systèmes Il n'a provoqué aucun effet négatif, et peut même avoir des effets positifs, comme l'augmentation du plaisir, de la créativité, de la diversité, etc. Par exemple, les LLM génèrent du contenu qui n'est pas lié à la tâche ou à l'objectif, ou du contenu cohérent avec les préférences ou les attentes de l'utilisateur, ou du contenu cohérent avec l'humeur ou l'attitude de l'utilisateur, ou du contenu utile pour le contenu de la communication ou de l'interaction de l'utilisateur.
Hallucination nuisible : elle a des impacts négatifs sur les utilisateurs et les systèmes, tels qu'une réduction de l'efficacité, de la précision, de la crédibilité, de la satisfaction, etc. Par exemple, les LLM génèrent du contenu incompatible avec les tâches ou les objectifs, ou du contenu incompatible avec les préférences ou les attentes de l'utilisateur, ou du contenu incompatible avec l'humeur ou l'attitude de l'utilisateur, ou du contenu qui entrave la communication de l'utilisateur. ou interaction.
Hallucination dangereuse : elle a un impact négatif grave sur les utilisateurs et le système, comme provoquer des malentendus, des conflits, des différends, des blessures, etc. Par exemple, les LLM génèrent du contenu contraire aux faits ou aux preuves, ou du contenu contraire à la moralité ou à la loi, ou du contenu contraire aux droits de l'homme ou à la dignité, ou encore du contenu qui menace la sécurité ou la santé.
2. Analyse des causes des hallucinations dans les LLM
Afin de mieux résoudre le problème des hallucinations dans les LLM, nous devons procéder à une analyse approfondie des causes des hallucinations. Selon les sources d'hallucinations mentionnées ci-dessus, l'auteur divise les causes des hallucinations en trois catégories suivantes :
Connaissance des paramètres insuffisante ou excessive : dans la phase de pré-formation, les LLM utilisent généralement une grande quantité de texte non étiqueté pour apprendre les règles et les connaissances du langage, formant ainsi des connaissances sur les paramètres. Cependant, ce type de connaissances peut présenter certains problèmes, tels qu'incomplètes, inexactes, non mises à jour, incohérentes, non pertinentes, etc., ce qui entraîne l'incapacité des LLM à comprendre et à utiliser pleinement les informations saisies lors de la génération de texte, ou l'incapacité de les utiliser correctement. distinguer et sélectionner les informations de sortie, produisant ainsi des hallucinations. D'un autre côté, la connaissance des paramètres peut être trop riche ou puissante, ce qui amène les LLM à s'appuyer ou à préférer excessivement leurs propres connaissances lors de la génération de texte, tout en ignorant ou en entrant en conflit avec les informations d'entrée, créant ainsi des hallucinations.
Manque ou erreur de connaissances non paramétriques : Dans la phase de mise au point ou de génération, les LLM utilisent généralement des données annotées externes pour obtenir ou compléter des connaissances linguistiques, formant ainsi des connaissances non paramétriques. Ce type de connaissances peut présenter certains problèmes, tels que la rareté, le bruit, les erreurs, le caractère incomplet, l'incohérence, la non-pertinence, etc., ce qui entraîne l'incapacité des LLM à récupérer et à fusionner efficacement les informations saisies lors de la génération du texte, ou à vérifier et corriger avec précision les informations saisies. informations, produisant ainsi des hallucinations. Les connaissances non paramétriques peuvent également être trop complexes ou diversifiées, ce qui rend difficile pour les LLM d'équilibrer et de coordonner différentes sources d'informations lors de la génération de texte, ou de s'adapter et de répondre à différentes exigences de tâches, créant ainsi des illusions.
Stratégie de génération inappropriée ou insuffisante : lorsque les LLM génèrent du texte, ils utilisent généralement certaines techniques ou méthodes pour contrôler ou optimiser le processus de génération et les résultats, formant ainsi une stratégie de génération. Ces stratégies peuvent présenter certains problèmes, tels qu'inappropriées, insuffisantes, instables, inexplicables, peu fiables, etc., entraînant l'incapacité des LLM à réguler et guider efficacement la direction et la qualité de la génération lors de la génération de texte, ou l'incapacité de découvrir et de corriger cela en temps opportun a généré des erreurs, créant ainsi des hallucinations. La stratégie de génération peut également être trop complexe ou changeante, ce qui rend difficile pour les LLM de maintenir et d'assurer la cohérence et la fiabilité de la génération lors de la génération de texte, ou il est difficile d'évaluer et de donner un retour sur les effets de la génération, créant ainsi des hallucinations.
3. Méthodes de détection et critères d'évaluation des hallucinations dans les LLM
Afin de mieux résoudre le problème des hallucinations dans les LLM, nous devons détecter et évaluer efficacement les hallucinations générées par les LLM. Selon les types d'hallucinations proposés ci-dessus, l'auteur divise les méthodes de détection des hallucinations dans les quatre catégories suivantes :
Méthodes de détection des hallucinations grammaticales : utiliser certains outils ou règles de vérification grammaticale pour identifier et corriger les erreurs grammaticales dans le texte généré par les LLM. Ou irrégulier. Par exemple, certains outils ou règles tels que la vérification de l'orthographe, la vérification de la ponctuation, la vérification de l'ordre des mots, la vérification du temps, la vérification de l'accord sujet-verbe, etc. peuvent être utilisés pour détecter et corriger les illusions grammaticales dans les textes générés par les LLM.
Méthode de détection des hallucinations sémantiques : Utilisez certains outils ou modèles d'analyse sémantique pour comprendre et évaluer les erreurs sémantiques ou l'irrationalité dans le texte généré par les LLM. Par exemple, certains outils ou modèles tels que l'analyse du sens des mots, la résolution de références, le raisonnement logique, l'élimination des ambiguïtés et la détection des contradictions peuvent être utilisés pour détecter et corriger les illusions sémantiques dans les textes générés par les LLM.
Méthode de détection de l'illusion de connaissances : utilisez des outils ou des modèles de récupération ou de vérification des connaissances pour obtenir et comparer les erreurs de connaissances ou les incohérences dans les textes générés par les LLM. Par exemple, certains outils ou modèles tels que les graphiques de connaissances, les moteurs de recherche, la vérification des faits, la vérification des preuves, la vérification des citations, etc. peuvent être utilisés pour détecter et corriger les illusions de connaissances dans les textes générés par les LLM.
Méthode de détection de l'illusion de création : utilisez des outils ou des modèles d'évaluation ou de rétroaction de création pour détecter et évaluer les erreurs de création ou le caractère inapproprié du texte généré par les LLM. Par exemple, certains outils ou modèles tels que l'analyse de style, l'analyse des sentiments, l'évaluation de la création, l'analyse des opinions, l'analyse des objectifs, etc. peuvent être utilisés pour détecter et corriger les illusions de création dans les textes générés par les LLM.
Selon le degré et l'impact de l'hallucination mentionné ci-dessus, nous pouvons diviser les critères d'évaluation de l'hallucination en quatre catégories suivantes :
Exactitude grammaticale : fait référence à la question de savoir si le texte généré par les LLM est grammaticalement cohérent avec le règles et habitudes du langage, telles que l’orthographe, la ponctuation, l’ordre des mots, le temps, l’accord sujet-verbe, etc. Cette norme peut être évaluée grâce à certains outils ou méthodes de vérification grammaticale automatique ou manuelle, tels que BLEU, ROUGE, BERTScore, etc.
Raisonnabilité sémantique : fait référence à la question de savoir si le texte généré par les LLM est sémantiquement cohérent avec le sens et la logique de la langue, comme le sens du mot, la référence, la logique, l'ambiguïté, la contradiction, etc. Cette norme peut être évaluée via certains outils ou méthodes d'analyse sémantique automatiques ou manuelles, tels que METEOR, MoverScore, BERTScore, etc.
Cohérence des connaissances : indique si le texte généré par les LLM est intellectuellement cohérent avec des faits ou des preuves réels, ou s'il est cohérent avec des informations saisies ou contextuelles, telles que des faits, des preuves, des références, des correspondances, etc. Cette norme peut être évaluée au moyen de certains outils ou méthodes automatiques ou manuels de récupération ou de vérification des connaissances, tels que FEVER, FactCC, BARTScore, etc.
Adéquation créative : indique si le texte généré par les LLM répond de manière créative aux exigences de la tâche ou de l'objectif, ou est cohérent avec les préférences ou les attentes de l'utilisateur, ou est en harmonie avec les émotions ou les attitudes de l'utilisateur, ou est cohérent avec les émotions ou les attitudes de l'utilisateur. Si la communication ou l'interaction de l'utilisateur est utile, comme le style, l'émotion, les opinions, les objectifs, etc. Cette norme peut être évaluée au moyen d'outils ou de méthodes d'évaluation ou de feedback de création automatique ou manuelle, tels que BLEURT, BARTScore, SARI, etc.
4. Méthodes pour atténuer les hallucinations dans les LLM
Afin de mieux résoudre le problème des hallucinations dans les LLM, nous devons atténuer et réduire efficacement les hallucinations générées par les LLM. Selon différents niveaux et angles, l'auteur divise les méthodes de soulagement des hallucinations dans les catégories suivantes :
Raffinement post-génération
Le raffinement post-génération consiste à modifier le texte après que les LLM ont généré le texte. Effectuer quelques vérifications et corrections. pour éliminer ou réduire l'illusion. L’avantage de ce type de méthode est qu’elle ne nécessite pas de recyclage ou de réglage des LLM et peut être directement appliquée à n’importe quel LLM. Les inconvénients de ce type d’approche sont que l’illusion peut ne pas être complètement éliminée, ou de nouvelles illusions peuvent être introduites, ou encore une partie de l’information ou de la créativité du texte original peut être perdue. Les représentants de ce type de méthode sont :
RARR (Refinement with Attribution and Retrieved References) : (Chrysostomou et Aletras, 2021) ont proposé une méthode de raffinement basée sur l'attribution et la récupération pour améliorer le texte généré par les LLM Fidelity. Un modèle d'attribution est utilisé pour identifier si chaque mot du texte généré par les LLM provient des informations d'entrée, de la connaissance des paramètres des LLM ou de la stratégie de génération des LLM. Utilisez un modèle de récupération pour récupérer certains textes de référence liés aux informations d'entrée à partir de sources de connaissances externes. Enfin, un modèle de raffinement est utilisé pour modifier le texte généré par les LLM en fonction des résultats d'attribution et des résultats de récupération afin d'améliorer sa cohérence et sa crédibilité avec les informations d'entrée.
Repérage et remplacement de mots à haute entropie (HEWSR) : (Zhang et al., 2021) ont proposé une méthode de raffinement basée sur l'entropie pour réduire les hallucinations dans le texte généré par les LLM. Premièrement, un modèle de calcul d'entropie est utilisé pour identifier les mots à haute entropie dans les textes générés par les LLM, c'est-à-dire les mots présentant une plus grande incertitude lors de leur génération. Ensuite, un modèle de remplacement est utilisé pour sélectionner un mot plus approprié à partir des informations d'entrée ou d'une source de connaissances externe afin de remplacer le mot à haute entropie. Enfin, un modèle de lissage est utilisé pour apporter quelques ajustements au texte remplacé afin de maintenir sa cohérence grammaticale et sémantique.
ChatProtect (Chat Protection with Self-Contradiction Detection) : (Wang et al., 2021) a proposé une méthode raffinée basée sur la détection d'auto-contradiction pour améliorer la sécurité des conversations de chat générées par les LLM. Premièrement, un modèle de détection de contradictions est utilisé pour identifier les auto-contradictions dans le dialogue généré par les LLM, c'est-à-dire les contenus qui entrent en conflit avec le contenu du dialogue précédent. Un modèle de remplacement est ensuite utilisé pour remplacer la réponse auto-contradictoire par une réponse plus appropriée parmi certaines réponses sûres prédéfinies. Enfin, un modèle d'évaluation est utilisé pour attribuer des notes au dialogue remplacé afin de mesurer sa sécurité et sa fluidité.
Auto-amélioration avec feedback et raisonnement
L'auto-amélioration avec feedback et raisonnement consiste à faire quelques évaluations et ajustements au texte dans le processus de génération de texte par les LLM pour éliminer ou réduire les hallucinations. L’avantage de ce type de méthode est qu’elle permet de surveiller et de corriger les hallucinations en temps réel, et d’améliorer les capacités d’auto-apprentissage et d’autorégulation des LLM. L’inconvénient de ce type d’approche est qu’elle peut nécessiter une formation supplémentaire ou un ajustement des LLM, ou qu’elle peut nécessiter des informations ou des ressources externes. Les représentants de ce type de méthode sont :
Méthodologie d'auto-réflexion (SRM) : (Iyer et al., 2021) a proposé une méthode parfaite basée sur l'auto-feedback pour améliorer la fiabilité des questions et réponses médicales générées par les LLM. La méthode utilise d'abord un modèle génératif pour générer une réponse initiale basée sur la question d'entrée et le contexte. Un modèle de rétroaction est ensuite utilisé pour générer une question de rétroaction basée sur la question d'entrée et le contexte, qui est utilisée pour détecter des hallucinations potentielles dans la réponse initiale. Utilisez ensuite un modèle de réponse pour générer une réponse basée sur la question de feedback afin de vérifier l'exactitude de la réponse initiale. Enfin, un modèle de correction est utilisé pour corriger la réponse initiale en fonction des résultats de la réponse afin d'améliorer sa fiabilité et sa précision.
Raisonnement comparatif structuré (SC) : (Yan et al., 2021) ont proposé une méthode de raisonnement basée sur une comparaison structurée pour améliorer la cohérence des prédictions de préférences de texte générées par les LLM. Cette méthode utilise un modèle génératif pour générer une comparaison structurée basée sur les paires de textes d'entrée, c'est-à-dire comparer et évaluer les paires de textes sous différents aspects. Utilisez un modèle d'inférence pour générer une prédiction de préférence de texte basée sur des comparaisons structurées, c'est-à-dire quelle paire de textes est préférée. Utilisez un modèle d'évaluation pour évaluer les comparaisons générées par rapport aux résultats prédits afin d'améliorer leur cohérence et leur crédibilité.
Think While Effectively Articulated Knowledge (TWEAK) : (Qiu et al., 2021a) propose une méthode d'inférence basée sur la vérification d'hypothèses pour améliorer la fidélité des connaissances générées par les LLM au texte. Cette méthode utilise un modèle génératif pour générer un texte initial basé sur les connaissances saisies. Utilisez ensuite un modèle d'hypothèse pour générer des hypothèses basées sur le texte initial, c'est-à-dire prédire le futur texte du texte sous différents aspects. Utilisez ensuite un modèle de vérification pour vérifier l’exactitude de chaque hypothèse en fonction des connaissances d’entrée. Enfin, un modèle d'ajustement est utilisé pour ajuster le texte initial en fonction des résultats de la vérification afin d'améliorer sa cohérence et sa crédibilité avec les connaissances d'entrée.
Nouvelle stratégie de décodage
La nouvelle stratégie de décodage consiste à apporter des modifications ou des optimisations à la distribution de probabilité du texte dans le processus de génération de texte par LLM afin d'éliminer ou de réduire les illusions. L’avantage de ce type de méthode est qu’elle peut affecter directement les résultats générés et améliorer la flexibilité et l’efficacité des LLM. L’inconvénient de ce type d’approche est qu’elle peut nécessiter une formation supplémentaire ou un ajustement des LLM, ou qu’elle peut nécessiter des informations ou des ressources externes. Les représentants de ce type de méthode sont :
Context-Aware Decoding (CAD) : (Shi et al., 2021) ont proposé une stratégie de décodage basée sur le contraste pour réduire les conflits de connaissances dans les textes générés par les LLM. Cette stratégie utilise un modèle contrastif pour calculer la différence dans la distribution de probabilité de la sortie des LLM lors de l'utilisation et de la non-utilisation des informations d'entrée. Ensuite, un modèle d'amplification est utilisé pour amplifier cette différence, de sorte que la probabilité d'une sortie cohérente avec les informations d'entrée soit plus élevée et que la probabilité d'une sortie en conflit avec les informations d'entrée soit plus faible. Enfin, un modèle génératif est utilisé pour générer du texte basé sur la distribution de probabilité amplifiée afin d'améliorer sa cohérence et sa crédibilité avec les informations d'entrée.
Décodage par couches contrastées (DoLa) : (Chuang et al., 2021) ont proposé une stratégie de décodage basée sur le contraste des couches pour réduire les illusions de connaissances dans les textes générés par les LLM. Premièrement, un modèle de sélection de couches est utilisé pour sélectionner certaines couches des LLM comme couches de connaissances, c'est-à-dire les couches qui contiennent le plus de connaissances factuelles. Un modèle de contraste de couches est ensuite utilisé pour calculer la différence logarithmique entre la couche de connaissances et les autres couches de l'espace du vocabulaire. Enfin, un modèle génératif est utilisé pour générer un texte basé sur la distribution de probabilité après comparaison de couches afin d'améliorer sa cohérence et sa crédibilité avec les connaissances factuelles.
Utilisation des graphiques de connaissances
L'utilisation des graphiques de connaissances consiste à utiliser des graphiques de connaissances structurés pour fournir ou compléter certaines connaissances liées aux informations d'entrée dans le processus de génération de texte des LLM, afin d'éliminer ou de réduire les hallucinations. L'avantage de ce type de méthode est qu'elle permet d'acquérir et d'intégrer efficacement des connaissances externes, et d'améliorer la couverture et la cohérence des connaissances des LLM. L'inconvénient de ce type d'approche est qu'une formation supplémentaire ou un réglage des LLM peuvent être nécessaires, ou que des graphiques de connaissances de haute qualité peuvent être nécessaires. Les représentants de ce type de méthode incluent :
RHO (Representation of linkedentities and relation predicates from a Knowledge Graph) : (Ji et al., 2021a) a proposé une méthode de représentation basée sur un knowledge graphe pour améliorer le dialogue généré par les LLM. Fidélité des réponses. Premièrement, un modèle de récupération de connaissances est utilisé pour récupérer certains sous-graphiques liés à la conversation d'entrée à partir d'un graphe de connaissances, c'est-à-dire un graphe contenant certaines entités et relations. Ensuite, un modèle de codage des connaissances est utilisé pour coder les entités et les relations dans le sous-graphe afin d'obtenir leurs représentations vectorielles. Ensuite, un modèle de fusion de connaissances est utilisé pour fusionner la représentation vectorielle des connaissances dans la représentation vectorielle du dialogue afin d'obtenir une représentation de dialogue améliorée. Enfin, un modèle de génération de connaissances est utilisé pour générer une réponse de dialogue fidèle basée sur la représentation de dialogue améliorée.
FLEEK (FactuaL Error détection and correction with Evidence Retrieved from external Knowledge) : (Bayat et al., 2021) a proposé une méthode de vérification et de correction basée sur des graphes de connaissances pour améliorer la factualité du texte généré par les LLM. La méthode utilise d'abord un modèle de reconnaissance des faits pour identifier les faits potentiellement vérifiables dans le texte généré par les LLM, c'est-à-dire les faits pour lesquels des preuves peuvent être trouvées dans le graphe de connaissances. Un modèle de génération de questions est ensuite utilisé pour générer une question pour chaque fait afin d'interroger le graphe de connaissances. Utilisez ensuite un modèle de récupération de connaissances pour récupérer des preuves liées au problème à partir du graphe de connaissances. Enfin, un modèle de vérification et de correction des faits est utilisé pour vérifier et corriger les faits dans le texte généré par les LLM sur la base de preuves afin d'améliorer sa factualité et son exactitude.
Fonction de perte basée sur la fidélité
La fonction de perte basée sur la fidélité consiste à utiliser une certaine mesure entre le texte généré et les informations d'entrée ou les étiquettes réelles pendant la formation ou le réglage fin des LLM. Une mesure de cohérence dans le cadre de une fonction de perte pour éliminer ou réduire les illusions. L'avantage de ce type de méthode est qu'elle peut affecter directement l'optimisation des paramètres des LLM et améliorer la fidélité et la précision des LLM. L'inconvénient de ce type d'approche est qu'une formation supplémentaire ou un réglage des LLM peuvent être nécessaires, ou que des données annotées de haute qualité peuvent être nécessaires. Les représentants de ce type de méthode comprennent :
Text Hallucination Mitigating (THAM) Framework : (Yoon et al., 2022) ont proposé une fonction de perte basée sur la théorie de l'information pour réduire les hallucinations dans les conversations vidéo générées par les LLM. Tout d’abord, un modèle de langage de dialogue est utilisé pour calculer la distribution de probabilité du dialogue. Un modèle de langage d'hallucination est ensuite utilisé pour calculer la distribution de probabilité des hallucinations, c'est-à-dire la distribution de probabilité des informations qui ne peuvent pas être obtenues à partir de la vidéo d'entrée. Ensuite, un modèle d'information mutuelle est utilisé pour calculer l'information mutuelle entre le dialogue et l'illusion, c'est-à-dire l'information mutuelle sur le degré d'illusion contenu dans le dialogue. Enfin, un modèle d'entropie croisée est utilisé pour calculer l'entropie croisée du dialogue et l'étiquette réelle, c'est-à-dire la précision du dialogue. Le but de cette fonction de perte est de minimiser la somme des informations mutuelles et de l’entropie croisée, réduisant ainsi les illusions et les erreurs dans le dialogue.
Correction d'erreurs factuelles avec des preuves extraites de connaissances externes (FECK) : (Ji et al., 2021b) ont proposé une fonction de perte basée sur des preuves de connaissances pour améliorer la factualité des textes générés par les LLM. Premièrement, un modèle de récupération de connaissances est utilisé pour récupérer certains sous-graphes liés au texte d'entrée à partir d'un graphe de connaissances, c'est-à-dire un graphe contenant certaines entités et relations. Ensuite, un modèle de codage des connaissances est utilisé pour coder les entités et les relations dans le sous-graphe afin d'obtenir leurs représentations vectorielles. Ensuite, un modèle d'alignement des connaissances est utilisé pour aligner les entités et les relations dans le texte généré par les LLM avec les entités et les relations dans le graphe de connaissances afin d'obtenir leur degré de correspondance. Enfin, la fonction de perte utilise un modèle de perte de connaissances pour calculer la distance entre les entités et relations dans le texte généré par les LLM et les entités et relations dans le graphe de connaissances, c'est-à-dire l'écart par rapport au fait. Le but de cette fonction de perte est de minimiser la perte de connaissances, améliorant ainsi la factualité et l'exactitude du texte généré par les LLM.
Prompt Tuning
Le réglage rapide est le processus d'utilisation d'un texte ou de symboles spécifiques dans le cadre de l'entrée pour contrôler ou guider le comportement de génération des LLM afin d'éliminer ou de réduire les hallucinations. L'avantage de ce type de méthode est qu'elle peut ajuster et guider efficacement la connaissance des paramètres des LLM, et peut améliorer l'adaptabilité et la flexibilité des LLM. L’inconvénient de ce type d’approche est qu’elle peut nécessiter une formation supplémentaire ou un réglage des LLM, ou encore des invites de haute qualité. Les représentants de ce type de méthode incluent :
UPRISE (Universal Prompt-based Refinement for Improving Semantic Equivalence) : (Chen et al., 2021) ont proposé une méthode de réglage fin basée sur des invites universelles pour améliorer la sémantique du texte généré. par l'équivalence des LLM. Premièrement, un modèle de génération d'invite est utilisé pour générer une invite générale basée sur le texte d'entrée, c'est-à-dire du texte ou des symboles utilisés pour guider les LLM afin de générer un texte sémantiquement équivalent. Ensuite, un modèle de réglage fin des indices est utilisé pour affiner les paramètres des LLM en fonction du texte d'entrée et des indices, ce qui le rend plus enclin à générer un texte sémantiquement équivalent au texte d'entrée. Enfin, la méthode utilise un modèle de génération d'indices pour générer un texte sémantiquement équivalent basé sur les paramètres de LLM affinés.
SynTra (Synthetic Task for Hallucination Mitigation in Abstractive Summarization) : (Wang et al., 2021) a proposé une méthode de réglage fin basée sur des tâches synthétiques pour réduire les hallucinations dans les résumés générés par les LLM. Premièrement, un modèle de génération de tâches synthétiques est utilisé pour générer une tâche synthétique basée sur le texte saisi, c'est-à-dire un problème de détection d'hallucinations dans les résumés. Un modèle synthétique de réglage fin des tâches est ensuite utilisé pour affiner les paramètres des LLM en fonction du texte saisi et de la tâche, ce qui le rend plus enclin à générer des résumés cohérents avec le texte saisi. Enfin, un modèle de génération de tâches synthétiques est utilisé pour générer un résumé cohérent basé sur les paramètres des LLM affinés.
5. Défis et limites des hallucinations dans les LLM
Bien que la technologie de soulagement des hallucinations dans les LLM ait fait certains progrès, il reste encore certains défis et limites qui nécessitent des recherches et une exploration plus approfondies. Voici quelques-uns des principaux défis et limites :
Définition et mesure des hallucinations : Sans une définition et une mesure unifiées et claires, différentes études peuvent utiliser différentes normes et mesures pour juger et évaluer le texte généré par les hallucinations des LLM. Cela conduit à des résultats incohérents et incomparables, et affecte également la compréhension et la résolution des problèmes d'hallucinations dans les LLM. Par conséquent, il est nécessaire d’établir une définition et une mesure communes et fiables des hallucinations afin de faciliter une détection et une évaluation efficaces des hallucinations dans les LLM.
Données et ressources sur les hallucinations : Il existe un manque de données et de ressources de haute qualité et à grande échelle pour soutenir la recherche et le développement sur les hallucinations dans les LLM. Par exemple, il y a un manque de certains ensembles de données contenant des annotations sur les hallucinations pour former et tester les méthodes de détection et d'atténuation des hallucinations dans les LLM ; il y a un manque de sources de connaissances contenant des faits et des preuves réels pour fournir et vérifier les connaissances contenues dans les textes générés par les LLM ; ; il manque certains ensembles de données contenant des hallucinations. Une plate-forme de commentaires et d'avis des utilisateurs pour collecter et analyser l'impact des hallucinations dans le texte généré par les LLM. Par conséquent, des données et des ressources de haute qualité et à grande échelle doivent être construites pour faciliter une recherche et un développement efficaces sur les hallucinations dans les LLM.
Causes et mécanismes des hallucinations : Il n'existe pas d'analyse approfondie et complète des causes et des mécanismes pour révéler et expliquer pourquoi les LLM produisent des hallucinations, et comment les hallucinations se forment et se propagent dans les LLM. Par exemple, on ne sait pas clairement comment les connaissances paramétriques, les connaissances non paramétriques et les stratégies génératives dans les LLM s’influencent et interagissent les unes avec les autres, et comment elles conduisent à des illusions de différents types, degrés et effets. Par conséquent, une analyse approfondie et complète des causes et des mécanismes est nécessaire pour faciliter une prévention et un contrôle efficaces des hallucinations dans les LLM.
Solution et optimisation des hallucinations : Il n'existe pas de solution parfaite et universelle ni de solution d'optimisation pour éliminer ou réduire les hallucinations dans le texte généré par les LLM, ainsi que pour améliorer la qualité et l'effet du texte généré par les LLM. Par exemple, on ne sait pas clairement comment améliorer la fidélité et la précision des LLM sans perdre leur capacité de généralisation et leur créativité. Par conséquent, certaines solutions complètes et universelles et solutions d'optimisation doivent être conçues pour améliorer la qualité et l'effet du texte généré par les LLM.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1369
1369
 52
52

 Pourquoi les grands modèles linguistiques utilisent-ils SwiGLU comme fonction d'activation ?
Apr 08, 2024 pm 09:31 PM
Pourquoi les grands modèles linguistiques utilisent-ils SwiGLU comme fonction d'activation ?
Apr 08, 2024 pm 09:31 PM
Si vous avez prêté attention à l'architecture des grands modèles de langage, vous avez peut-être vu le terme « SwiGLU » dans les derniers modèles et documents de recherche. SwiGLU peut être considéré comme la fonction d'activation la plus couramment utilisée dans les grands modèles de langage. Nous la présenterons en détail dans cet article. SwiGLU est en fait une fonction d'activation proposée par Google en 2020, qui combine les caractéristiques de SWISH et de GLU. Le nom chinois complet de SwiGLU est « unité linéaire à porte bidirectionnelle ». Il optimise et combine deux fonctions d'activation, SWISH et GLU, pour améliorer la capacité d'expression non linéaire du modèle. SWISH est une fonction d'activation très courante et largement utilisée dans les grands modèles de langage, tandis que GLU a montré de bonnes performances dans les tâches de traitement du langage naturel.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Visualisez l'espace vectoriel FAISS et ajustez les paramètres RAG pour améliorer la précision des résultats
Mar 01, 2024 pm 09:16 PM
Visualisez l'espace vectoriel FAISS et ajustez les paramètres RAG pour améliorer la précision des résultats
Mar 01, 2024 pm 09:16 PM
À mesure que les performances des modèles de langage open source à grande échelle continuent de s'améliorer, les performances d'écriture et d'analyse du code, des recommandations, du résumé de texte et des paires questions-réponses (QA) se sont toutes améliorées. Mais lorsqu'il s'agit d'assurance qualité, le LLM ne répond souvent pas aux problèmes liés aux données non traitées, et de nombreux documents internes sont conservés au sein de l'entreprise pour garantir la conformité, les secrets commerciaux ou la confidentialité. Lorsque ces documents sont interrogés, LLM peut halluciner et produire un contenu non pertinent, fabriqué ou incohérent. Une technique possible pour relever ce défi est la génération augmentée de récupération (RAG). Cela implique le processus d'amélioration des réponses en référençant des bases de connaissances faisant autorité au-delà de la source de données de formation pour améliorer la qualité et la précision de la génération. Le système RAG comprend un système de récupération permettant de récupérer des fragments de documents pertinents du corpus
 Guide du débutant sur le traitement du langage naturel en PHP
Jun 11, 2023 pm 06:30 PM
Guide du débutant sur le traitement du langage naturel en PHP
Jun 11, 2023 pm 06:30 PM
Avec le développement de la technologie de l’intelligence artificielle, le traitement du langage naturel (NLP) est devenu une technologie très importante. La PNL peut nous aider à mieux comprendre et analyser le langage humain pour réaliser certaines tâches automatisées, telles que le service client intelligent, l'analyse des sentiments, la traduction automatique, etc. Dans cet article, nous aborderons les bases et les outils du traitement du langage naturel à l'aide de PHP. Qu'est-ce que le traitement du langage naturel ? Le traitement du langage naturel est une méthode qui utilise la technologie de l'intelligence artificielle pour traiter
 Optimisation du LLM à l'aide de la technologie SPIN pour la formation de mise au point du jeu personnel
Jan 25, 2024 pm 12:21 PM
Optimisation du LLM à l'aide de la technologie SPIN pour la formation de mise au point du jeu personnel
Jan 25, 2024 pm 12:21 PM
2024 est une année de développement rapide pour les grands modèles de langage (LLM). Dans la formation du LLM, les méthodes d'alignement sont un moyen technique important, notamment le réglage fin supervisé (SFT) et l'apprentissage par renforcement avec rétroaction humaine qui s'appuie sur les préférences humaines (RLHF). Ces méthodes ont joué un rôle crucial dans le développement du LLM, mais les méthodes d’alignement nécessitent une grande quantité de données annotées manuellement. Face à ce défi, la mise au point est devenue un domaine de recherche dynamique, les chercheurs travaillant activement au développement de méthodes permettant d’exploiter efficacement les données humaines. Par conséquent, le développement de méthodes d’alignement favorisera de nouvelles percées dans la technologie LLM. L'Université de Californie a récemment mené une étude introduisant une nouvelle technologie appelée SPIN (SelfPlayfInetuNing). S
 Utiliser des graphiques de connaissances pour améliorer les capacités des modèles RAG et atténuer les fausses impressions des grands modèles
Jan 14, 2024 pm 06:30 PM
Utiliser des graphiques de connaissances pour améliorer les capacités des modèles RAG et atténuer les fausses impressions des grands modèles
Jan 14, 2024 pm 06:30 PM
Les hallucinations sont un problème courant lorsque l'on travaille avec de grands modèles de langage (LLM). Bien que LLM puisse générer un texte fluide et cohérent, les informations qu'il génère sont souvent inexactes ou incohérentes. Afin d'éviter les hallucinations du LLM, des sources de connaissances externes, telles que des bases de données ou des graphiques de connaissances, peuvent être utilisées pour fournir des informations factuelles. De cette manière, LLM peut s’appuyer sur ces sources de données fiables, ce qui permet d’obtenir un contenu textuel plus précis et plus fiable. Base de données vectorielles et base de données vectorielles Knowledge Graph Une base de données vectorielles est un ensemble de vecteurs de grande dimension qui représentent des entités ou des concepts. Ils peuvent être utilisés pour mesurer la similarité ou la corrélation entre différentes entités ou concepts, calculées à travers leurs représentations vectorielles. Une base de données vectorielles peut vous indiquer, sur la base de la distance vectorielle, que « Paris » et « France » sont plus proches que « Paris » et
 Technologie et applications de reconnaissance d'entités nommées et d'extraction de relations dans le traitement du langage naturel basé sur Java
Jun 18, 2023 am 09:43 AM
Technologie et applications de reconnaissance d'entités nommées et d'extraction de relations dans le traitement du langage naturel basé sur Java
Jun 18, 2023 am 09:43 AM
Avec l'avènement de l'ère Internet, une grande quantité d'informations textuelles a envahi notre champ de vision, suivie par les besoins croissants des gens en matière de traitement et d'analyse de l'information. Dans le même temps, l’ère d’Internet a également entraîné le développement rapide de la technologie de traitement du langage naturel, permettant aux utilisateurs de mieux obtenir des informations précieuses à partir de textes. Parmi eux, la technologie de reconnaissance d’entités nommées et d’extraction de relations constitue l’une des orientations de recherche importantes dans le domaine des applications de traitement du langage naturel. 1. Technologie de reconnaissance d'entités nommées Les entités nommées font référence à des personnes, des lieux, des organisations, du temps, de la monnaie, des connaissances encyclopédiques, des termes de mesure et des professions.
 Explication détaillée de GQA, le mécanisme d'attention couramment utilisé dans les grands modèles, et l'implémentation du code Pytorch
Apr 03, 2024 pm 05:40 PM
Explication détaillée de GQA, le mécanisme d'attention couramment utilisé dans les grands modèles, et l'implémentation du code Pytorch
Apr 03, 2024 pm 05:40 PM
Grouped Query Attention (GroupedQueryAttention) est une méthode d'attention multi-requêtes dans les grands modèles de langage. Son objectif est d'atteindre la qualité du MHA tout en maintenant la vitesse du MQA. GroupedQueryAttention regroupe les requêtes et les requêtes au sein de chaque groupe partagent le même poids d'attention, ce qui permet de réduire la complexité de calcul et d'augmenter la vitesse d'inférence. Dans cet article, nous expliquerons l'idée de GQA et comment la traduire en code. GQA est dans le document GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint
