
 Périphériques technologiques
IA
Dix indicateurs de performance du modèle d'apprentissage automatique
Périphériques technologiques
IA
Dix indicateurs de performance du modèle d'apprentissage automatique
Dix indicateurs de performance du modèle d'apprentissage automatique

Bien que les grands modèles soient très puissants, la résolution de problèmes pratiques ne repose pas nécessairement entièrement sur les grands modèles. Une analogie moins précise pour expliquer des phénomènes physiques dans la réalité sans forcément recourir à la mécanique quantique. Pour certains problèmes relativement simples, une distribution statistique suffira peut-être. Pour l’apprentissage automatique, il va sans dire que l’apprentissage profond et les réseaux de neurones sont nécessaires. La clé est de clarifier les limites du problème.
Alors, comment évaluer les performances d'un modèle d'apprentissage automatique lors de l'utilisation du ML pour résoudre des problèmes relativement simples ? Voici 10 indicateurs d’évaluation relativement couramment utilisés, dans l’espoir d’être utiles aux étudiants de l’industrie et de la recherche.
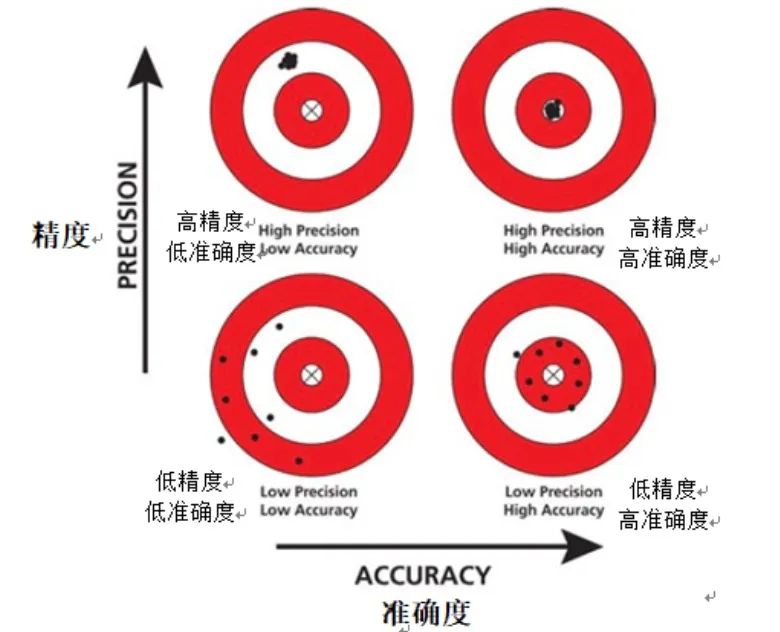
1. Précision
La précision est un indice d'évaluation de base dans le domaine de l'apprentissage automatique et est généralement utilisée pour comprendre rapidement les performances du modèle. La précision fournit un moyen intuitif de mesurer la précision d'un modèle en calculant simplement le rapport entre le nombre d'instances correctement prédites par le modèle et le nombre total d'instances dans l'ensemble de données.
 Photos
Photos
Cependant, la précision, en tant que mesure d'évaluation, peut être inadéquate lorsqu'il s'agit d'ensembles de données déséquilibrés. Un ensemble de données déséquilibré fait référence à un ensemble de données dans lequel le nombre d'instances d'une certaine catégorie dépasse largement celui des autres catégories. Dans ce cas, le modèle peut avoir tendance à prédire un plus grand nombre de catégories, ce qui donne lieu à une précision faussement élevée.
De plus, l'exactitude ne peut pas fournir d'informations sur les faux positifs et les faux négatifs. Un faux positif se produit lorsque le modèle prédit incorrectement une instance négative comme une instance positive, tandis qu'un faux négatif se produit lorsque le modèle prédit incorrectement une instance positive comme une instance négative. Lors de l’évaluation des performances du modèle, il est important de faire la distinction entre les faux positifs et les faux négatifs, car ils ont des effets différents sur les performances du modèle.
En résumé, bien que la précision soit une mesure d'évaluation simple et facile à comprendre, lorsque nous traitons d'ensembles de données déséquilibrés, nous devons être plus prudents dans l'interprétation des résultats de précision.
2. Précision
La précision est un indice d'évaluation important, qui se concentre sur la mesure de la précision de la prédiction du modèle pour les échantillons positifs. Contrairement à l'exactitude, la précision calcule la proportion d'instances réellement positives parmi les instances prédites positives par le modèle. En d’autres termes, l’exactitude répond à la question : « Lorsque le modèle prédit qu’une instance est positive, quelle est la probabilité que cette prédiction soit exacte ? » Un modèle de haute précision signifie que lorsqu’il prédit qu’une instance est positive, cette instance. Il est très probable qu'il s'agisse effectivement d'un échantillon positif.
 Photos
Photos
Dans certaines applications, comme le diagnostic médical ou la détection de fraude, la précision du modèle est particulièrement importante. Dans ces scénarios, les conséquences des faux positifs (c’est-à-dire la prédiction incorrecte des échantillons négatifs comme des échantillons positifs) peuvent être très graves. Par exemple, dans le cadre d’un diagnostic médical, un diagnostic faussement positif peut conduire à un traitement ou à un examen inutile, provoquant un stress psychologique et physique inutile pour le patient. Lors de la détection des fraudes, les faux positifs peuvent conduire à ce que des utilisateurs innocents soient qualifiés à tort d'acteurs frauduleux, ce qui a un impact sur l'expérience utilisateur et la réputation de l'entreprise.
Par conséquent, dans ces applications, il est crucial de garantir que le modèle ait une grande précision. Ce n’est qu’en améliorant la précision que nous pourrons réduire le risque de faux positifs et donc l’impact négatif des erreurs de jugement.
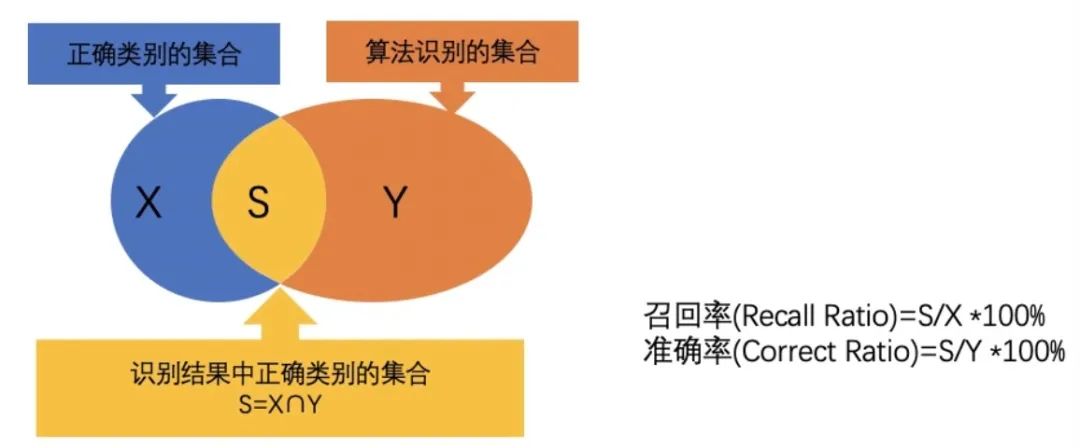
3. Taux de rappel
Le taux de rappel est un indice d'évaluation important, utilisé pour mesurer la capacité du modèle à prédire correctement tous les échantillons positifs réels. Plus précisément, le rappel est calculé comme le rapport entre les instances prédites par le modèle comme étant de vrais positifs et le nombre total d'exemples positifs réels. Cette métrique répond à la question : « Combien d'exemples positifs réels le modèle a-t-il prédit correctement ? »
Contrairement à la précision, le rappel se concentre sur la capacité du modèle à rappeler des exemples positifs réels. Même si le modèle a une faible probabilité de prédiction pour un certain échantillon positif, tant que l'échantillon est réellement un échantillon positif et est correctement prédit comme un échantillon positif par le modèle, cette prédiction sera incluse dans le calcul du taux de rappel. . Par conséquent, le rappel concerne davantage la capacité du modèle à trouver autant d’échantillons positifs que possible, et pas seulement ceux dont les probabilités prédites sont plus élevées.
 Photos
Photos
Dans certains scénarios d'application, l'importance du taux de rappel est particulièrement importante. Par exemple, dans la détection d'une maladie, si le modèle oublie les patients réellement malades, cela peut entraîner des retards et une aggravation de la maladie, et avoir de graves conséquences pour les patients. Pour un autre exemple, dans la prévision du taux de désabonnement des clients, si le modèle n'identifie pas correctement les clients susceptibles de se désintéresser, l'entreprise peut perdre l'opportunité de prendre des mesures de fidélisation, perdant ainsi des clients importants.
Par conséquent, dans ces scénarios, le rappel devient une mesure cruciale. Un modèle avec un rappel élevé est plus à même de trouver de véritables échantillons positifs, réduisant ainsi le risque d'omissions et évitant ainsi d'éventuelles conséquences graves.
4. Score F1
Le score F1 est un indice d'évaluation complet qui vise à trouver un équilibre entre précision et rappel. Il s'agit en fait de la moyenne harmonieuse de la précision et du rappel, combinant ces deux métriques en un seul score, offrant ainsi un mode d'évaluation qui prend en compte à la fois les faux positifs et les faux négatifs.
 Images
Images
Dans de nombreuses applications pratiques, nous devons souvent faire un compromis entre précision et rappel. La précision se concentre sur l'exactitude des prédictions du modèle, tandis que le rappel se concentre sur la capacité du modèle à trouver tous les échantillons positifs réels. Cependant, accorder trop d’importance à une mesure peut souvent nuire aux performances de l’autre. Par exemple, pour améliorer le rappel, un modèle peut augmenter les prédictions pour les échantillons positifs, mais cela peut également augmenter le nombre de faux positifs, réduisant ainsi la précision.
Le scoring F1 est conçu pour résoudre ce problème. Cela prend en compte la précision et le rappel, nous évitant de sacrifier une métrique pour en optimiser une autre. En calculant la moyenne harmonique de précision et de rappel, le score F1 établit un équilibre entre les deux, permettant d'évaluer les performances du modèle sans prendre parti.
Le score F1 est donc un outil très utile lorsque vous avez besoin d’une métrique combinant précision et rappel, et que vous ne voulez pas privilégier une métrique par rapport à l’autre. Il fournit un score unique qui simplifie le processus d'évaluation des performances du modèle et nous aide à mieux comprendre les performances du modèle dans les applications du monde réel.
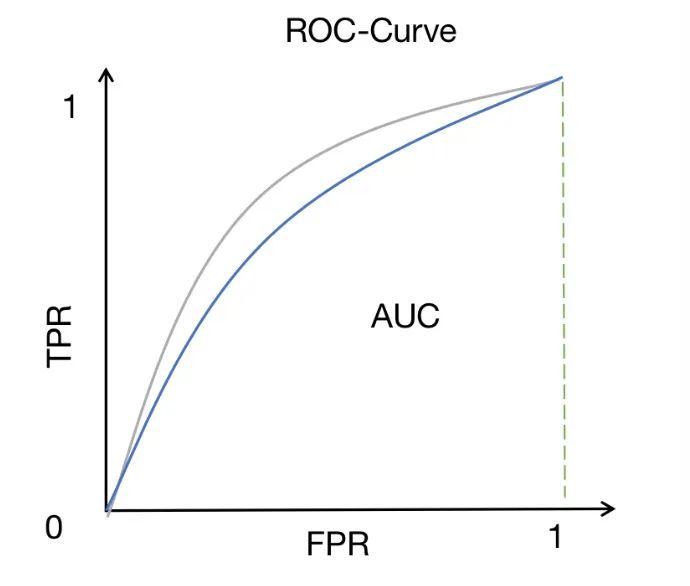
5. ROC-AUC
ROC-AUC est une méthode de mesure des performances largement utilisée dans les problèmes de classification binaire. Il mesure l'aire sous la courbe ROC, qui représente la relation entre le taux de vrais positifs (également appelé sensibilité ou rappel) et le taux de faux positifs à différents seuils.
 Images
Images
Les courbes ROC offrent un moyen intuitif d'observer les performances du modèle sous différents paramètres de seuil. En modifiant le seuil, nous pouvons ajuster le taux de vrais positifs et le taux de faux positifs du modèle pour obtenir différents résultats de classification. Plus la courbe ROC est proche du coin supérieur gauche, meilleures sont les performances du modèle pour distinguer les échantillons positifs et négatifs.
L'AUC (aire sous la courbe) fournit un indicateur quantitatif pour évaluer la capacité de discrimination du modèle. La valeur de l'AUC est comprise entre 0 et 1. Plus elle est proche de 1, plus la capacité de discrimination du modèle est forte. Un score AUC élevé signifie que le modèle peut bien distinguer les échantillons positifs des échantillons négatifs, c'est-à-dire que la probabilité prédite du modèle pour les échantillons positifs est supérieure à la probabilité prédite pour les échantillons négatifs.
Par conséquent, ROC-AUC est une métrique très utile lorsque nous voulons évaluer la capacité d'un modèle à distinguer les classes. Par rapport à d’autres indicateurs, le ROC-AUC présente des avantages uniques. Il n'est pas affecté par la sélection des seuils et peut prendre en compte de manière exhaustive les performances du modèle sous différents seuils. De plus, ROC-AUC est relativement robuste aux problèmes de déséquilibre de classes et peut toujours donner des résultats d'évaluation significatifs même lorsque le nombre d'échantillons positifs et négatifs est déséquilibré.
ROC-AUC est une mesure de performance très précieuse, notamment pour les problèmes de classification binaire. En observant et en comparant les scores ROC-AUC de différents modèles, nous pouvons acquérir une compréhension plus complète des performances du modèle et sélectionner le modèle ayant la meilleure capacité de discrimination.
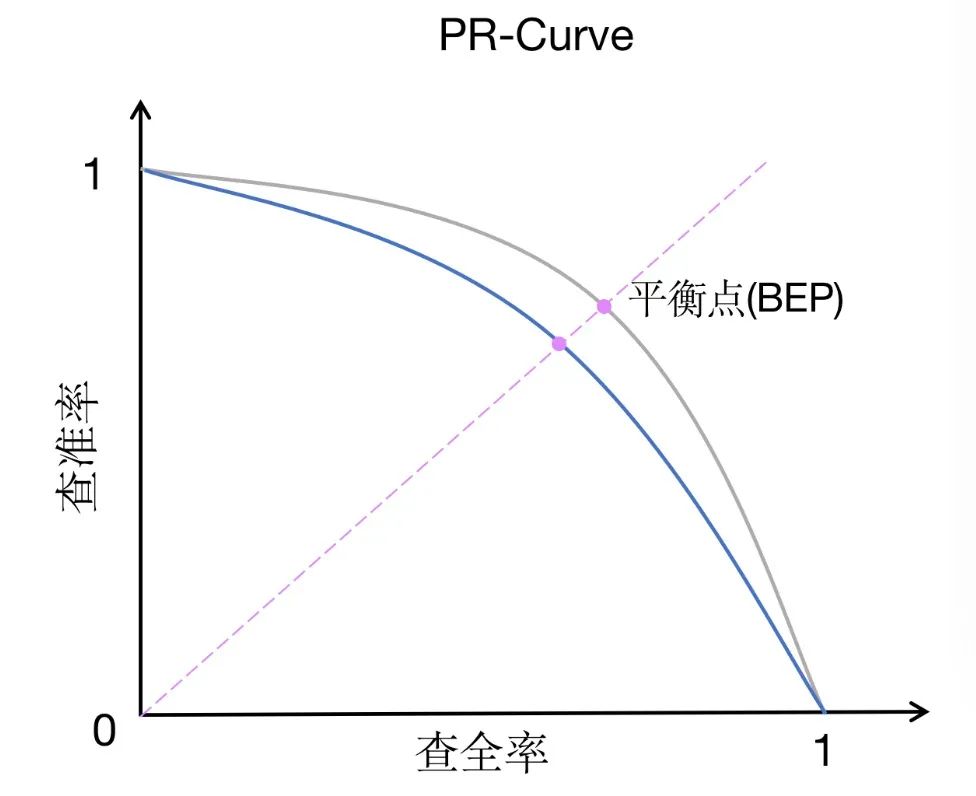
6. PR-AUC
PR-AUC (aire sous la courbe de précision-rappel) est une méthode de mesure des performances similaire à ROC-AUC, mais a un objectif légèrement différent. PR-AUC mesure l’aire sous la courbe précision-rappel, qui décrit la relation entre précision et rappel à différents seuils.
 Photos
Photos
Par rapport au ROC-AUC, le PR-AUC accorde plus d'attention au compromis entre précision et rappel. La précision mesure la proportion d'instances que le modèle prédit comme étant positives qui sont réellement positives, tandis que le rappel mesure la proportion d'instances que le modèle prédit correctement comme étant positives parmi toutes les instances qui sont réellement positives. Le compromis entre précision et rappel est particulièrement important dans les ensembles de données déséquilibrés ou lorsque les faux positifs sont plus préoccupants que les faux négatifs.
Dans un ensemble de données déséquilibré, le nombre d'échantillons dans une catégorie peut dépasser de loin le nombre d'échantillons dans une autre catégorie. Dans ce cas, ROC-AUC peut ne pas refléter avec précision les performances du modèle car il se concentre principalement sur la relation entre le taux de vrais positifs et le taux de faux positifs sans prendre directement en compte le déséquilibre des classes. En revanche, PR-AUC évalue de manière plus complète les performances du modèle grâce au compromis entre précision et rappel, et peut mieux refléter l'effet du modèle sur des ensembles de données déséquilibrés.
De plus, PR-AUC est également une mesure plus appropriée lorsque les faux positifs sont plus préoccupants que les faux négatifs. Parce que dans certains scénarios d’application, prédire incorrectement les échantillons négatifs comme des échantillons positifs (faux positifs) peut entraîner des pertes plus importantes ou des impacts négatifs. Par exemple, dans le cadre d’un diagnostic médical, diagnostiquer incorrectement une personne en bonne santé comme une personne malade peut entraîner un traitement inutile et de l’anxiété. Dans ce cas, nous préférerions que le modèle ait une grande précision pour réduire le nombre de faux positifs.
Pour résumer, PR-AUC est une méthode de mesure des performances adaptée aux ensembles de données déséquilibrés ou aux scénarios où les faux positifs sont préoccupants. Cela peut nous aider à mieux comprendre le compromis entre précision et rappel des modèles et à choisir un modèle approprié pour répondre aux besoins réels.
7. FPR/TNR
Le taux de faux positifs (FPR) est une mesure importante qui mesure la proportion d'échantillons que le modèle prédit à tort comme positifs parmi tous les échantillons négatifs réels. C'est un indicateur complémentaire de spécificité et correspond au taux de vrais négatifs (TNR). Le FPR devient un élément clé lorsque l'on souhaite évaluer la capacité d'un modèle à éviter les faux positifs. Les faux positifs peuvent entraîner des inquiétudes inutiles ou un gaspillage de ressources. Il est donc crucial de comprendre le FPR d'un modèle pour déterminer sa fiabilité dans les applications du monde réel. En abaissant le FPR, nous pouvons améliorer la précision et l’exactitude du modèle, en garantissant que les prédictions positives ne sont émises que lorsqu’il existe réellement des échantillons positifs.
 Photos
Photos
D'autre part, le taux véritablement négatif (TNR), également connu sous le nom de spécificité, est une mesure de la manière dont un modèle identifie correctement les échantillons négatifs. Il calcule la proportion d'instances prédites par le modèle comme étant de vrais négatifs par rapport au total réel de négatifs. Lors de l'évaluation d'un modèle, nous nous concentrons souvent sur sa capacité à identifier des échantillons positifs, mais la performance du modèle à identifier des échantillons négatifs est tout aussi importante. Un TNR élevé signifie que le modèle peut identifier avec précision les échantillons négatifs, c'est-à-dire que parmi les instances qui sont réellement des échantillons négatifs, le modèle prédit une proportion plus élevée d'échantillons négatifs. Ceci est crucial pour éviter les faux positifs et améliorer les performances globales du modèle.
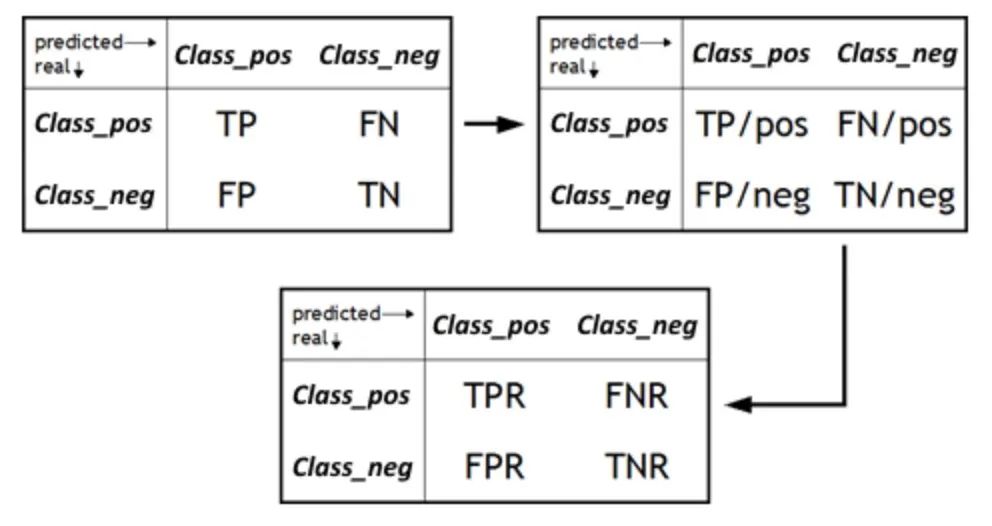
8. Coefficient de corrélation de Matthews (MCC)
MCC (Coefficient de corrélation de Matthews) est une mesure utilisée dans les problèmes de classification binaire. Elle nous fournit une considération complète des vrais positifs, des vrais négatifs et des faux. évalué. Par rapport à d'autres méthodes de mesure, l'avantage du MCC est qu'il s'agit d'une valeur unique allant de -1 à 1, où -1 signifie que la prédiction du modèle est complètement incompatible avec le résultat réel et 1 signifie que la prédiction du modèle est complètement cohérente. avec le résultat réel.
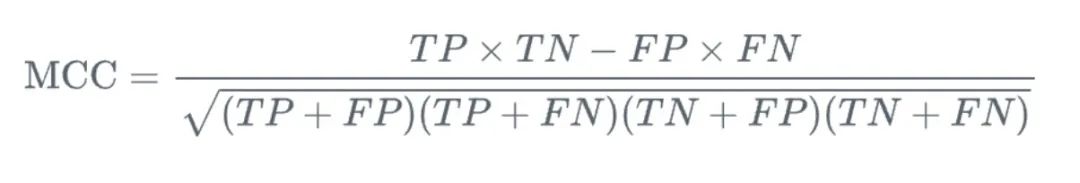 Photos
Photos
Plus important encore, MCC fournit un moyen équilibré de mesurer la qualité de la classification binaire. Dans les problèmes de classification binaire, nous nous concentrons généralement sur la capacité du modèle à identifier des échantillons positifs et négatifs, tandis que MCC considère les deux aspects. Il se concentre non seulement sur la capacité du modèle à prédire correctement les échantillons positifs (c'est-à-dire les vrais positifs), mais également sur la capacité du modèle à prédire correctement les échantillons négatifs (c'est-à-dire les vrais négatifs). Dans le même temps, MCC prend également en compte les faux positifs et les faux négatifs pour évaluer de manière plus complète les performances du modèle.
Dans les applications pratiques, MCC est particulièrement adapté à la gestion d'ensembles de données déséquilibrés. Étant donné que dans un ensemble de données déséquilibré, le nombre d’échantillons dans une catégorie est beaucoup plus grand que celui d’une autre catégorie, cela entraîne souvent un biais du modèle vers la prédiction de la catégorie avec un nombre plus grand. Cependant, MCC est capable de prendre en compte les quatre mesures (vrais positifs, vrais négatifs, faux positifs et faux négatifs) de manière équilibrée, de sorte qu'il peut généralement fournir une évaluation des performances plus précise et plus complète pour les ensembles de données déséquilibrés.
Dans l'ensemble, MCC est un outil de mesure des performances puissant et complet pour la classification binaire. Il prend non seulement en compte tous les résultats de prédiction possibles, mais fournit également une valeur numérique intuitive et bien définie pour mesurer la cohérence entre les prédictions et les résultats réels. Que ce soit sur des ensembles de données équilibrés ou déséquilibrés, le MCC est une métrique utile qui peut nous aider à comprendre plus en profondeur les performances du modèle.
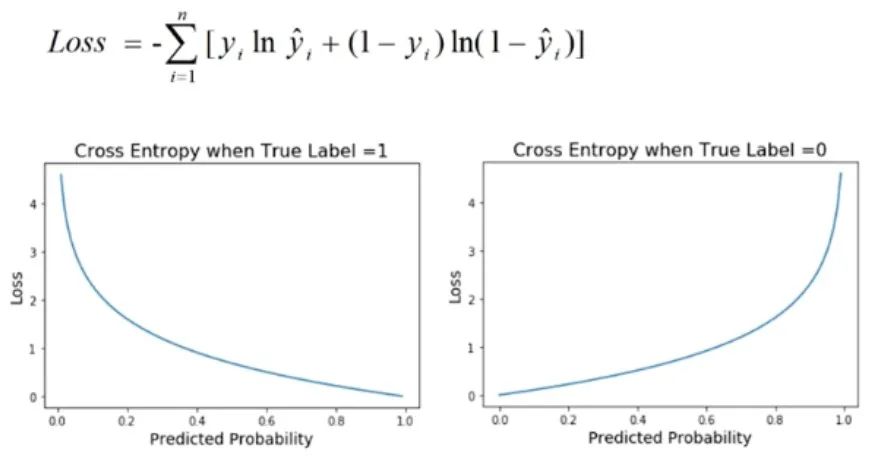
9. Perte d'entropie croisée
La perte d'entropie croisée est une mesure de performance couramment utilisée dans les problèmes de classification, en particulier lorsque la sortie du modèle est une valeur de probabilité. Cette fonction de perte est utilisée pour quantifier la différence entre la distribution de probabilité prédite par le modèle et la distribution réelle des étiquettes.
 Images
Images
Dans les problèmes de classification, le but du modèle est généralement de prédire la probabilité qu'un échantillon appartienne à différentes catégories. La perte d'entropie croisée est utilisée pour évaluer la cohérence entre les probabilités prédites du modèle et les résultats binaires réels. Il dérive la valeur de la perte en prenant le logarithme de la probabilité prédite et en le comparant avec l'étiquette réelle. Par conséquent, la perte d’entropie croisée est également appelée perte logarithmique.
L'avantage de la perte d'entropie croisée est qu'elle constitue une bonne mesure de la précision de la prédiction du modèle pour les distributions de probabilité. Lorsque la distribution de probabilité prédite du modèle est similaire à la distribution d'étiquettes réelle, la valeur de la perte d'entropie croisée est faible ; à l'inverse, lorsque la distribution de probabilité prédite est significativement différente de la distribution d'étiquettes réelle, la valeur de la perte d'entropie croisée est ; haut. Par conséquent, une valeur de perte d’entropie croisée plus faible signifie que les prédictions du modèle sont plus précises, c’est-à-dire que le modèle présente de meilleures performances d’étalonnage.
Dans les applications pratiques, nous recherchons généralement des valeurs de perte d'entropie croisée plus faibles, car cela signifie que les prédictions du modèle pour les problèmes de classification sont plus précises et plus fiables. En optimisant la perte d'entropie croisée, nous pouvons améliorer les performances du modèle et lui donner une meilleure capacité de généralisation dans des applications pratiques. Par conséquent, la perte d'entropie croisée est l'un des indicateurs importants pour évaluer les performances d'un modèle de classification. Elle peut nous aider à mieux comprendre la précision des prévisions du modèle et si une optimisation plus poussée des paramètres et de la structure du modèle est nécessaire.
10. Coefficient kappa de Cohen
Le coefficient kappa de Cohen est un outil statistique utilisé pour mesurer la cohérence entre les prédictions du modèle et les étiquettes réelles. Il est particulièrement adapté à l'évaluation des tâches de classification. Par rapport à d'autres méthodes de mesure, elle calcule non seulement l'accord simple entre les prédictions du modèle et les étiquettes réelles, mais corrige également l'accord qui peut survenir par hasard, fournissant ainsi un résultat d'évaluation plus précis et plus fiable.
Dans les applications pratiques, en particulier lorsque plusieurs évaluateurs sont impliqués dans la classification du même ensemble d'échantillons, le coefficient kappa de Cohen est très utile. Dans ce cas, nous devons non seulement nous concentrer sur la cohérence des prédictions du modèle avec les étiquettes réelles, mais également prendre en compte la cohérence entre les différents évaluateurs. Parce que s'il existe une incohérence significative entre les évaluateurs, les résultats de l'évaluation des performances du modèle peuvent être affectés par la subjectivité des évaluateurs, entraînant des résultats d'évaluation inexacts.
En utilisant le coefficient kappa de Cohen, cette cohérence qui peut survenir par hasard peut être corrigée pour une évaluation plus précise des performances du modèle. Plus précisément, il calcule une valeur comprise entre -1 et 1, où 1 représente une cohérence parfaite, -1 représente une incohérence totale et 0 représente une cohérence aléatoire. Par conséquent, une valeur Kappa plus élevée signifie que l’accord entre les prédictions du modèle et les étiquettes réelles dépasse l’accord attendu par hasard, ce qui indique que le modèle a de meilleures performances.
 Pictures
Pictures
Le coefficient kappa de Cohen peut nous aider à évaluer plus précisément la cohérence entre les prédictions du modèle et les étiquettes réelles dans les tâches de classification, tout en corrigeant la cohérence qui peut survenir par hasard. C’est particulièrement important dans les scénarios impliquant plusieurs évaluateurs, car cela peut fournir une évaluation plus objective et plus précise.
Résumé
Il existe de nombreux indicateurs pour l'évaluation des modèles d'apprentissage automatique. Cet article donne quelques-uns des principaux indicateurs :
- Précision (Précision) : la proportion du nombre d'échantillons correctement prédits par rapport au nombre total d'échantillons.
- Précision : proportion d'échantillons vrais positifs (TP) par rapport à tous les échantillons positifs prédits (TP et FP), reflétant la capacité du modèle à identifier les échantillons positifs.
- Rappel : la proportion d'échantillons vrais positifs (TP) par rapport à tous les échantillons vrais positifs (TP et FN), reflétant la capacité du modèle à découvrir des échantillons positifs.
- Valeur F1 : La moyenne harmonique de la précision et du rappel, prenant en compte à la fois la précision et le rappel.
- ROC-AUC : L'aire sous la courbe ROC La courbe ROC est fonction du taux de vrais positifs (True Positive Rate, TPR) et du taux de faux positifs (False Positive Rate, FPR). Plus l’AUC est grande, meilleures sont les performances de classification du modèle.
- PR-AUC : zone sous la courbe précision-rappel, qui se concentre sur le compromis entre précision et rappel et est plus adaptée aux ensembles de données déséquilibrés.
- FPR/TNR : FPR mesure la capacité du modèle à signaler des faux positifs, et TNR mesure la capacité du modèle à identifier correctement les échantillons négatifs.
- Perte d'entropie croisée : utilisée pour évaluer la différence entre la probabilité prédite du modèle et l'étiquette réelle. Des valeurs inférieures indiquent un meilleur calibrage et une meilleure précision du modèle.
- Coefficient de corrélation de Matthews (MCC) : une métrique qui prend en compte les relations entre les vrais positifs, les vrais négatifs, les faux positifs et les faux négatifs, fournissant une mesure équilibrée de la qualité de la classification binaire.
- Kappa de Cohen : un outil important pour évaluer les performances du modèle dans les tâches de classification. Il peut mesurer avec précision la cohérence entre les prédictions et les étiquettes et corriger la cohérence accidentelle, en particulier dans les scénarios à plusieurs évaluateurs.
Chacun des indicateurs ci-dessus a ses propres caractéristiques et convient à différents scénarios de problèmes. Dans les applications pratiques, plusieurs indicateurs peuvent devoir être combinés pour évaluer de manière globale les performances du modèle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
À la pointe de la technologie logicielle, le groupe de l'UIUC Zhang Lingming, en collaboration avec des chercheurs de l'organisation BigCode, a récemment annoncé le modèle de grand code StarCoder2-15B-Instruct. Cette réalisation innovante a permis une percée significative dans les tâches de génération de code, dépassant avec succès CodeLlama-70B-Instruct et atteignant le sommet de la liste des performances de génération de code. Le caractère unique de StarCoder2-15B-Instruct réside dans sa stratégie d'auto-alignement pur. L'ensemble du processus de formation est ouvert, transparent et complètement autonome et contrôlable. Le modèle génère des milliers d'instructions via StarCoder2-15B en réponse au réglage fin du modèle de base StarCoder-15B sans recourir à des annotations manuelles coûteuses.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
1. Introduction Au cours des dernières années, les YOLO sont devenus le paradigme dominant dans le domaine de la détection d'objets en temps réel en raison de leur équilibre efficace entre le coût de calcul et les performances de détection. Les chercheurs ont exploré la conception architecturale de YOLO, les objectifs d'optimisation, les stratégies d'expansion des données, etc., et ont réalisé des progrès significatifs. Dans le même temps, le recours à la suppression non maximale (NMS) pour le post-traitement entrave le déploiement de bout en bout de YOLO et affecte négativement la latence d'inférence. Dans les YOLO, la conception de divers composants manque d’une inspection complète et approfondie, ce qui entraîne une redondance informatique importante et limite les capacités du modèle. Il offre une efficacité sous-optimale et un potentiel d’amélioration des performances relativement important. Dans ce travail, l'objectif est d'améliorer encore les limites d'efficacité des performances de YOLO à la fois en post-traitement et en architecture de modèle. à cette fin
 Comparaison des performances de différents frameworks Java
Jun 05, 2024 pm 07:14 PM
Comparaison des performances de différents frameworks Java
Jun 05, 2024 pm 07:14 PM
Comparaison des performances de différents frameworks Java : Traitement des requêtes API REST : Vert.x est le meilleur, avec un taux de requêtes de 2 fois SpringBoot et 3 fois Dropwizard. Requête de base de données : HibernateORM de SpringBoot est meilleur que l'ORM de Vert.x et Dropwizard. Opérations de mise en cache : le client Hazelcast de Vert.x est supérieur aux mécanismes de mise en cache de SpringBoot et Dropwizard. Cadre approprié : choisissez en fonction des exigences de l'application. Vert.x convient aux services Web hautes performances, SpringBoot convient aux applications gourmandes en données et Dropwizard convient à l'architecture de microservices.
 Apprentissage automatique en C++ : un guide pour la mise en œuvre d'algorithmes d'apprentissage automatique courants en C++
Jun 03, 2024 pm 07:33 PM
Apprentissage automatique en C++ : un guide pour la mise en œuvre d'algorithmes d'apprentissage automatique courants en C++
Jun 03, 2024 pm 07:33 PM
En C++, la mise en œuvre d'algorithmes d'apprentissage automatique comprend : Régression linéaire : utilisée pour prédire des variables continues. Les étapes comprennent le chargement des données, le calcul des poids et des biais, la mise à jour des paramètres et la prédiction. Régression logistique : utilisée pour prédire des variables discrètes. Le processus est similaire à la régression linéaire, mais utilise la fonction sigmoïde pour la prédiction. Machine à vecteurs de support : un puissant algorithme de classification et de régression qui implique le calcul de vecteurs de support et la prédiction d'étiquettes.
 L'Université Tsinghua a pris le relais et YOLOv10 est sorti : les performances ont été grandement améliorées et il figurait sur la hot list de GitHub
Jun 06, 2024 pm 12:20 PM
L'Université Tsinghua a pris le relais et YOLOv10 est sorti : les performances ont été grandement améliorées et il figurait sur la hot list de GitHub
Jun 06, 2024 pm 12:20 PM
La série de référence YOLO de systèmes de détection de cibles a une fois de plus reçu une mise à niveau majeure. Depuis la sortie de YOLOv9 en février de cette année, le relais de la série YOLO (YouOnlyLookOnce) a été passé entre les mains de chercheurs de l'Université Tsinghua. Le week-end dernier, la nouvelle du lancement de YOLOv10 a attiré l'attention de la communauté IA. Il est considéré comme un cadre révolutionnaire dans le domaine de la vision par ordinateur et est connu pour ses capacités de détection d'objets de bout en bout en temps réel, poursuivant l'héritage de la série YOLO en fournissant une solution puissante alliant efficacité et précision. Adresse de l'article : https://arxiv.org/pdf/2405.14458 Adresse du projet : https://github.com/THU-MIG/yo
