


Dans les entreprises modernes, la gestion des connaissances est un maillon crucial. Il peut aider les entreprises à organiser et à utiliser efficacement les ressources de connaissances internes et externes, améliorant ainsi leur efficacité et leur compétitivité. Afin de mieux gérer les connaissances, de nombreuses entreprises ont introduit le concept de gestionnaires de connaissances. L'intendant des connaissances est un rôle ou un système spécifiquement chargé de gérer et de diffuser les connaissances de l'entreprise. Grâce aux gestionnaires des connaissances, les entreprises peuvent mieux collecter et organiser
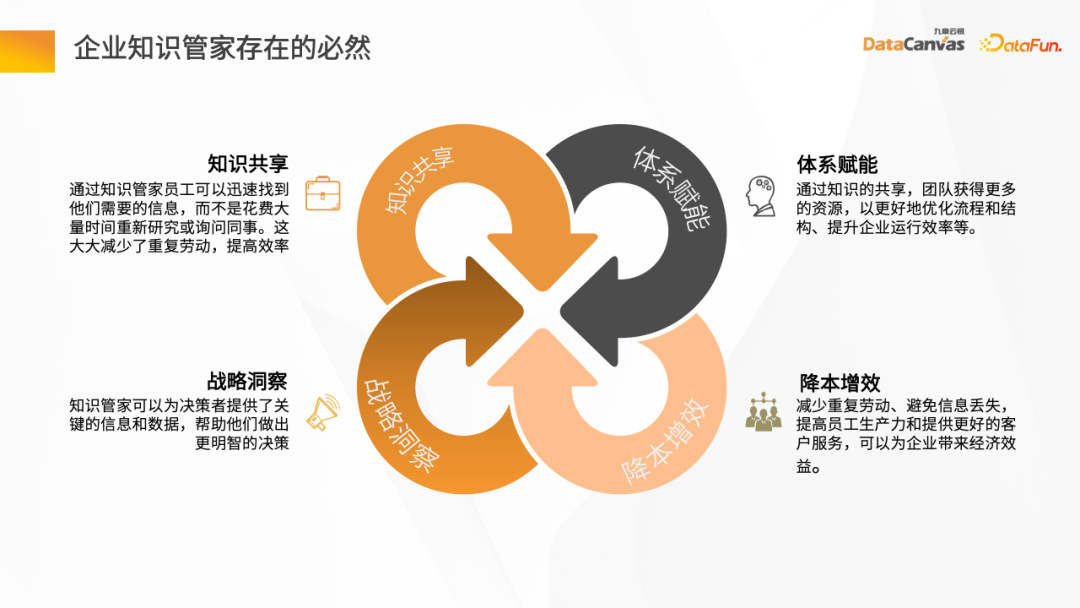
Avec le développement rapide des applications Internet et la croissance explosive des connaissances, les entreprises sont confrontées au défi du partage des connaissances. Comment transférer et partager efficacement les connaissances au sein d’une entreprise est devenu une question importante. Grâce au partage des connaissances, les entreprises peuvent non seulement améliorer l’efficacité du travail, mais également éviter la duplication des tâches.
Une autre façon consiste à utiliser le modèle de partage des connaissances pour établir un mécanisme qui peut responsabiliser les entreprises, optimisant ainsi mieux les processus et les résultats et améliorant l'efficacité opérationnelle des entreprises. Ce modèle permet aux employés de l'entreprise de partager leurs connaissances et leur expérience afin que tous les membres de l'équipe puissent en bénéficier. En partageant leurs connaissances, les entreprises peuvent éviter la duplication des efforts, réduire les erreurs et les fautes et être mieux à même de répondre aux défis et aux changements. Ceci
De plus, en tant que gestionnaire des connaissances, il peut également fournir des informations et des données clés aux décideurs pour les aider à prendre des décisions plus éclairées. Knowledge Butler dispose de puissantes capacités de récupération et d'analyse d'informations, et peut extraire des informations utiles à partir de données massives, les intégrer et les analyser. Ces informations et données peuvent inclure les tendances du marché, l'analyse des concurrents, les informations sur les consommateurs, le développement technologique, etc.
De plus, un facteur très clé est de réduire la charge de travail des employés de l'entreprise, d'éviter la perte d'informations et d'améliorer la productivité des employés. . l'efficacité du travail et les niveaux de service à la clientèle, atteignant ainsi les objectifs de réduction des coûts et d'amélioration de l'efficacité.
Avant l'existence d'un grand modèle, la logique de création d'un intendant des connaissances était assez compliquée. Habituellement, nous utilisons le concept de base de connaissances pour construire une base de connaissances à l'aide d'un graphe de connaissances d'entreprise ou de données internes de l'entreprise. Cependant, de nombreux défis sont rencontrés au cours de ce processus de construction. Premièrement, la construction d’une base de connaissances nécessite beaucoup de main d’œuvre et d’investissement en temps. Collecter, organiser et résumer les connaissances et les informations au sein d’une entreprise est une tâche fastidieuse et chronophage. Une équipe professionnelle est nécessaire pour traiter et gérer ces données et garantir qu'elles sont
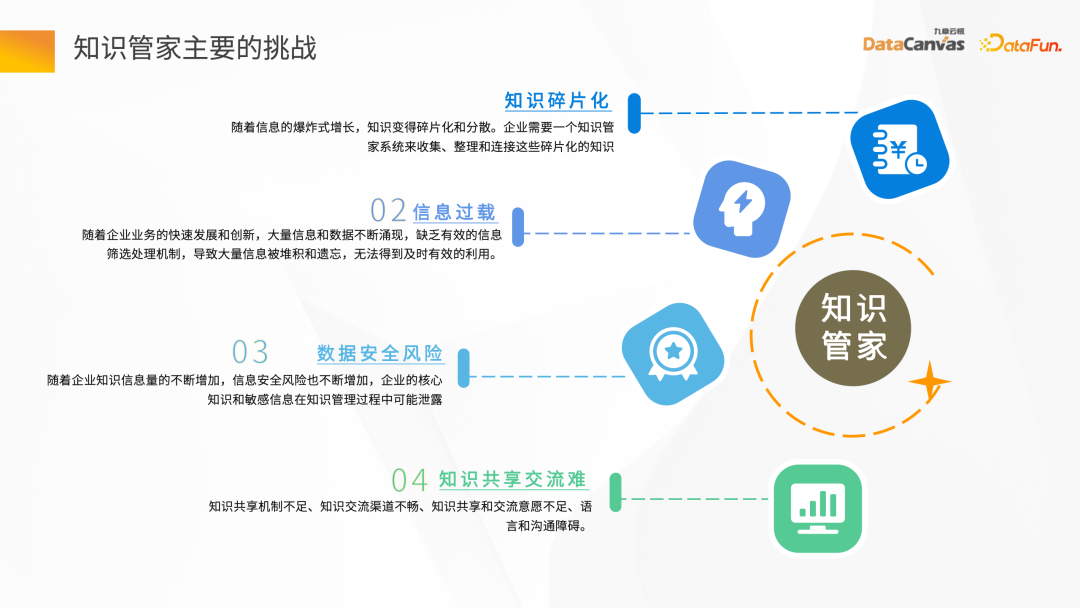
La fragmentation des connaissances se reflète principalement sous deux aspects. dispersés , Par exemple, les données du système OA appartiennent à différents départements et différentes équipes. En revanche, ces données sont essentiellement fournies sous des formes non structurées, telles que Word, PDF, images, vidéos, etc. Dans le processus de création de gestionnaires de connaissances, le premier défi consiste à centraliser rapidement ces connaissances fragmentées.
Avec le développement rapide des activités des entreprises et l'émergence continue de grandes quantités d'informations et de données, comment établir un mécanisme de filtrage des données massives pour garantir l'exactitude et l'actualité des informations est aussi un grand défi.
Les entreprises ne partagent généralement pas leurs données privées avec d'autres institutions ou organisations. Elles accordent généralement plus d'attention à la sécurité des données du domaine privé de l'entreprise, elles doivent donc également y faire face. avec un risque pour la sécurité des données.
Différentes entreprises ont des structures organisationnelles différentes, certaines sont plus techniques, certaines sont plus orientées business et certaines sont un mélange de technologie et de business dans le processus. de la communication commerciale et technologique, une mauvaise communication est un problème auquel chaque entreprise sera confrontée dans le partage des connaissances.
Enterprise Knowledge Butler est similaire au cerveau d'une personne pour aider à stocker l'ensemble des connaissances, ainsi qu'à comprendre et créer des connaissances.
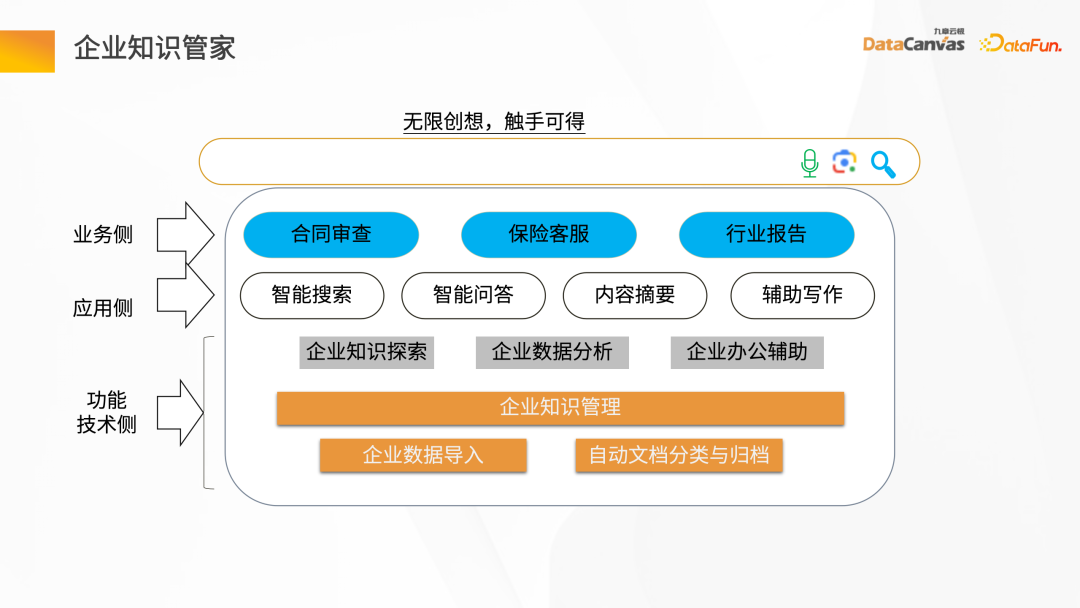
L'intendant des connaissances d'entreprise est généralement divisé en trois niveaux : Le premier niveau correspond aux besoins fonctionnels et techniques, principalement responsable de la gestion des connaissances d'entreprise, y compris l'importation des données d'entreprise, la classification automatique et l'archivage des documents, et autres Les besoins des fonctions de base ; la couche intermédiaire correspond aux besoins du côté application, y compris la fourniture de questions et réponses intelligentes, la recherche intelligente, la génération de résumés, l'écriture auxiliaire et d'autres fonctions ; y compris l'examen des contrats, le service client des assurances et la génération de rapports sectoriels.
Il existe généralement trois modes d'interface présentés par Knowledge Butler : la première interface est similaire à une zone de texte, permettant l'exploration et l'analyse des connaissances ; l'autre consiste à utiliser des jetons API pour intégrer des agents intelligents impliqués dans différents scénarios d'application. dans le jeton API pour l'intégrer au système commercial de l'entreprise ; la troisième voie est l'agent intelligent, qui explore et analyse les connaissances via le mode conversation.
Enterprise Knowledge Steward est principalement responsable de la gestion et de la création de connaissances spécifiques à l'entreprise, y compris les scénarios commerciaux suivants :

combinaison Les données du domaine privé de l'entreprise sont vectorisées et stockées dans une base de données vectorielle. Elle utilise le mode questions et réponses pour créer des scénarios de questions et réponses intelligents. Grâce à ces scénarios, de nombreux besoins commerciaux plus spécifiques peuvent être dérivés.
Faites de l'exploration et de l'analyse à travers des documents, comme l'exploration du document, vous pouvez poser des questions sur le contenu du document, vous pouvez également effectuer une analyse indépendante du document, fournissant l'intégralité du document Aperçu segmenté, récupération contextuelle, résumé et autres fonctionnalités.
Combiné les données du domaine privé de différents rôles au sein de l'entreprise, ainsi que le mode mot d'invite, pour permettre la conception de certains scénarios personnalisés, tels que la rédaction assistée de documents et les procès-verbaux des réunions, etc.
adopte le mode de dialogue homme-machine pour examiner certaines informations clés des clauses de divers contrats de l'entreprise afin de voir si les informations correspondantes sont exactes.
Les principales fonctions du produit Enterprise Knowledge Manager comprennent :
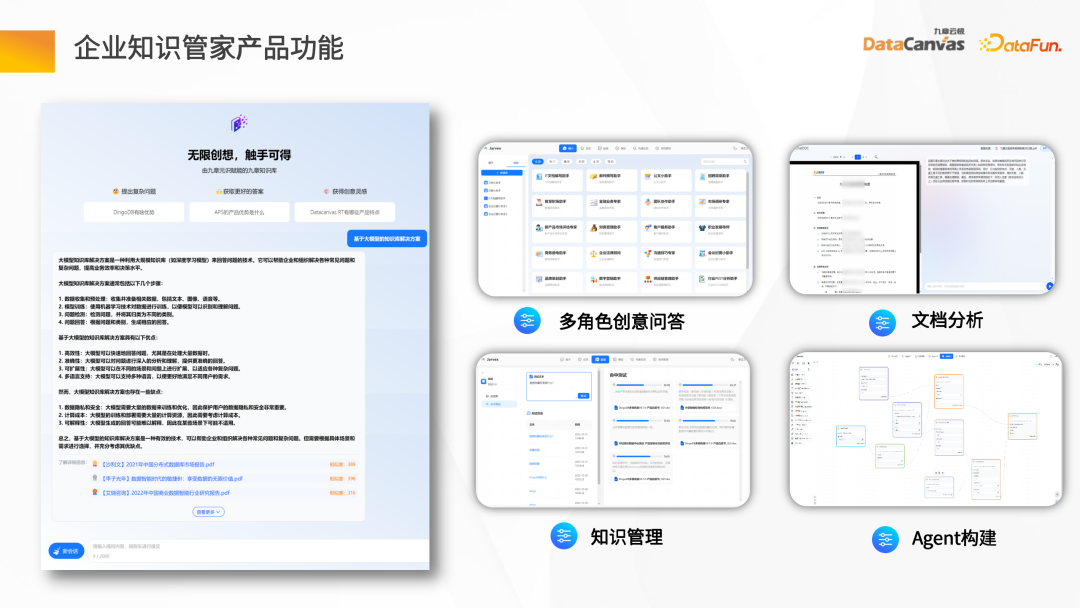
Architecture fonctionnelle du Knowledge Manager :
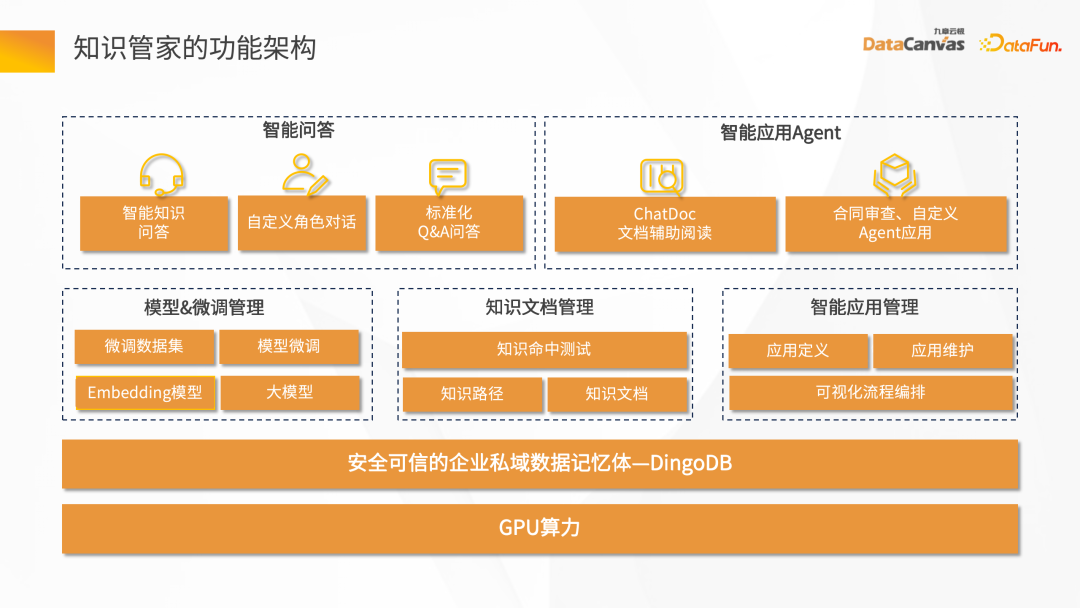
Le fond est la puissance de calcul du GPU, qui comprend deux catégories, l'une est la puissance de calcul du raisonnement et l'autre est le réglage fin de la puissance de calcul. La couche intermédiaire est une mémoire de données de domaine privé d'entreprise sécurisée et digne de confiance - la base de données vectorielles multimode DingoDB.
Une autre couche de points fonctionnels pour l'ensemble de la couche technique, y compris la gestion du réglage fin des modèles, la gestion des documents de connaissances et la gestion intelligente des applications.
Les principaux sont les besoins basés sur des scénarios commerciaux. Dans les questions et réponses intelligentes, vous pouvez personnaliser certains dialogues de rôles, les questions et réponses d'assurance qualité standard et les agents pour les applications intelligentes, la lecture auxiliaire basée sur des documents, la révision des contrats et les assistants personnels d'assurance.
Ensuite, nous présenterons l'ensemble du processus de construction de Knowledge Butler à travers des scénarios de questions et réponses intelligents.
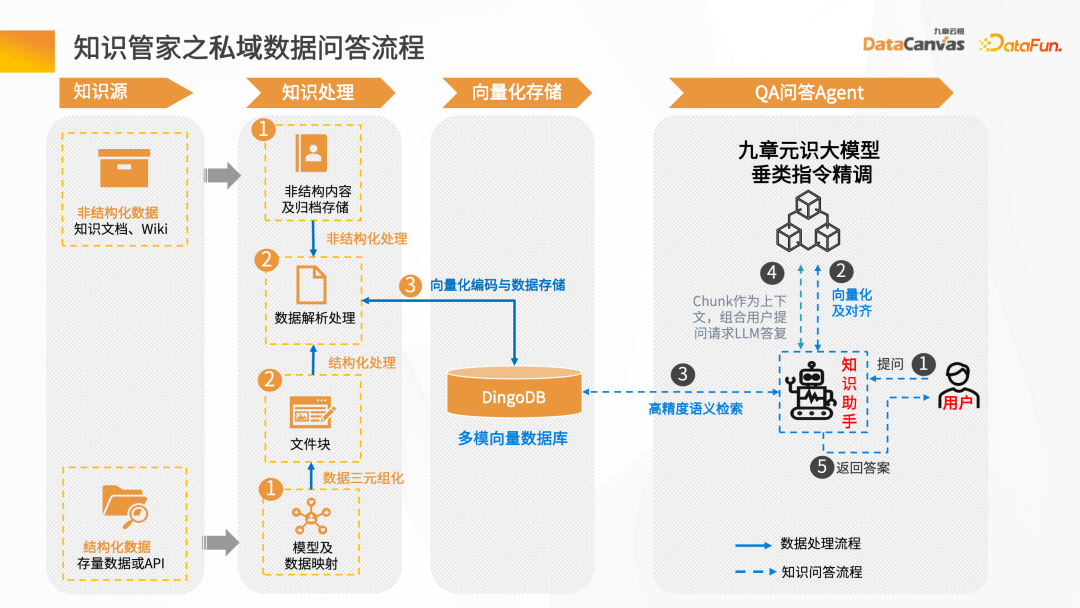
Tout d'abord, vous devez disposer d'une source de données. Il peut y avoir des données structurées et non structurées. De manière générale, la construction d'une base de connaissances repose principalement sur des données non structurées, telles que Word, PDF, Excel,. et systèmes d'entreprise, Jira, plateforme de gestion des connaissances, etc.
Ces données font l'objet d'un traitement de connaissances et sont converties en vecteurs et stockées dans la base de données. Vous devez d'abord charger le document, puis donner les informations de mise en page ou les informations de structure du document, effectuer une analyse vectorielle du document pour générer des blocs de fichiers, puis appeler le modèle d'intégration correspondant basé sur les blocs de fichiers pour les convertir en vecteurs et stocker les vecteurs. .
Le processus d'interaction intelligente entre questions et réponses : une fois que l'utilisateur a posé une question, la question est d'abord vectorisée à l'aide d'un assistant intelligent, puis la base de données est utilisée pour la récupération sémantique afin d'obtenir le contexte de l'article avec sémantique similaire. Le contexte est combiné avec les mots d'invite, et après un grand nombre de Le modèle effectue l'inférence et renvoie finalement la réponse.
Le processus global est un processus d'itération continue et d'optimisation des commentaires. Ce n'est qu'ainsi que nous pourrons obtenir le rôle d'expert intelligent exclusif basé sur les données du domaine privé de l'entreprise.
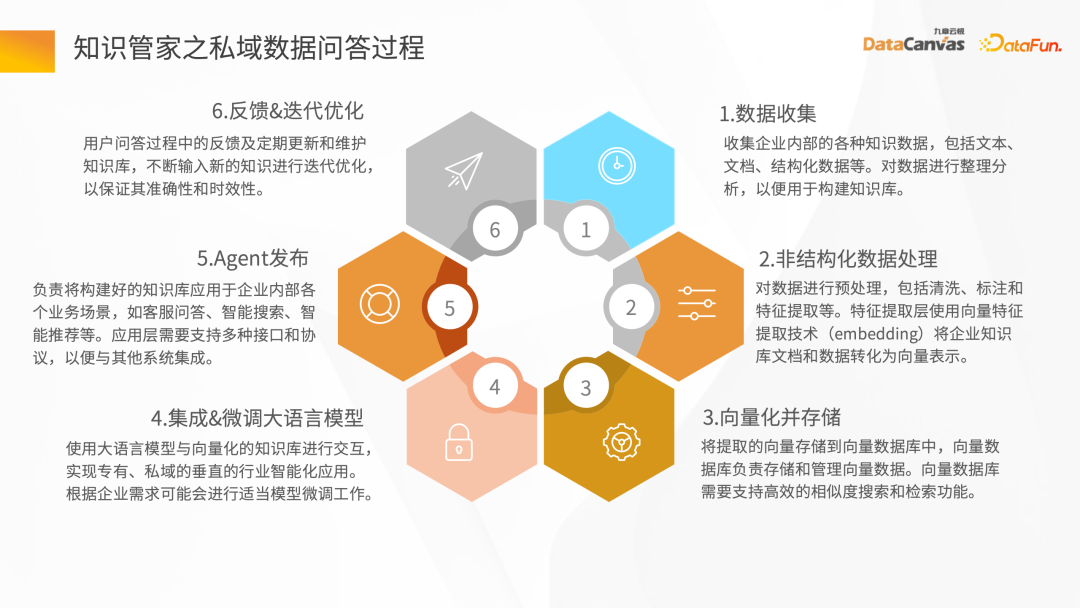
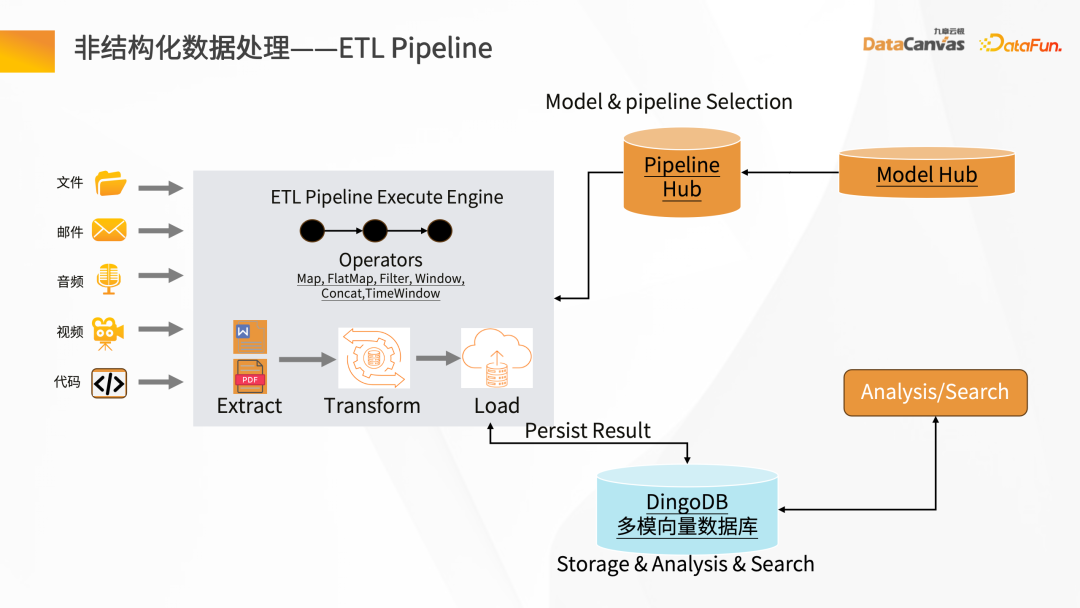
Le traitement ETL des données non structurées nécessite l'aide de quelques outils. Knowledge Manager fournit des opérateurs spéciaux à partir du modèle technique. Ces opérateurs peuvent nettoyer l'intégralité des modifications basées sur la carte, le filtre et la fenêtre, et convertir les données dans l'ensemble du pipeline ETL.
En analysant divers fichiers (tels que les analyseurs PDF), puis en passant par les opérateurs de hub de différents scénarios d'application correspondant à la couche intermédiaire, le Pipeline Hub peut être rapidement construit, puis les données sont nettoyées et converties en intégration. , et enfin stocké dans la base de données vectorielles.
Pour obtenir un bon effet de débogage du modèle, il est nécessaire de garantir des données précises et complètes et d'avoir une bonne qualité de traitement des données.
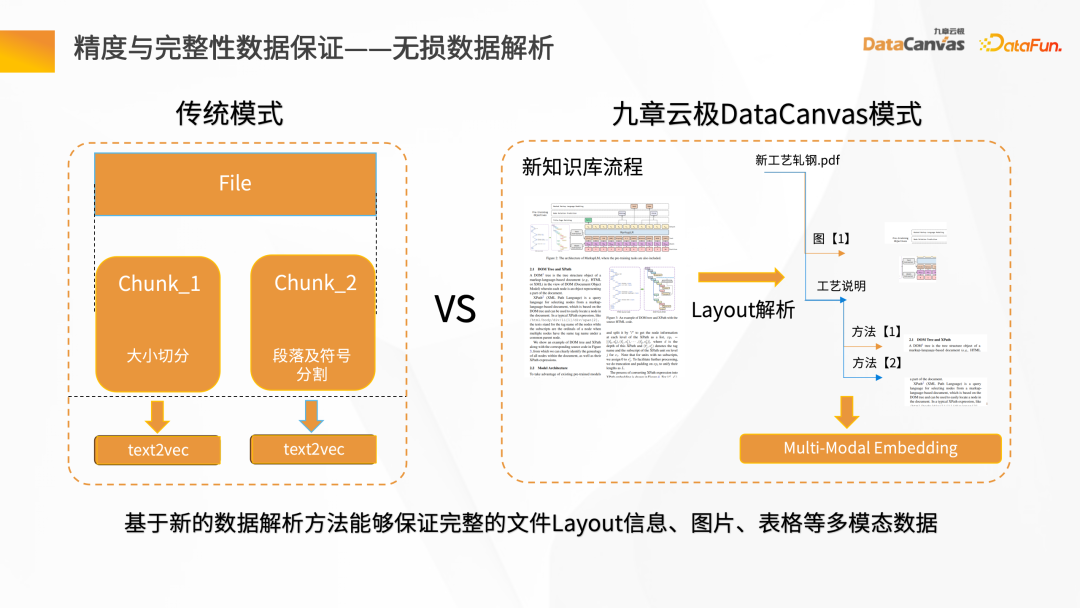
Construire une récupération de données traditionnelle est très simple, mais la connaissance réelle est plus compliquée. En plus des informations contenues dans le texte lui-même, il y a aussi des images, des données de tableau, des informations de paragraphe, etc. À cet égard, Jiuzhang Yunji DataCanvas fournit un mode d'analyse de mise en page, qui peut réaliser le stockage complet de données multimodales telles que des informations de mise en page, des tableaux et des images, et améliore considérablement la qualité du processus d'analyse des données.
Une fois le document vectorisé et stocké dans la base de données vectorielles multimodale DingoDB, il est récupéré via Query, et le contenu de récupération lui-même sera inclus dans les résultats de récupération. Les résultats incluront également les résultats de corrélation. À ce stade, il est nécessaire d'effectuer un filtrage secondaire du reclassement sur les fragments récupérés et rappelés.
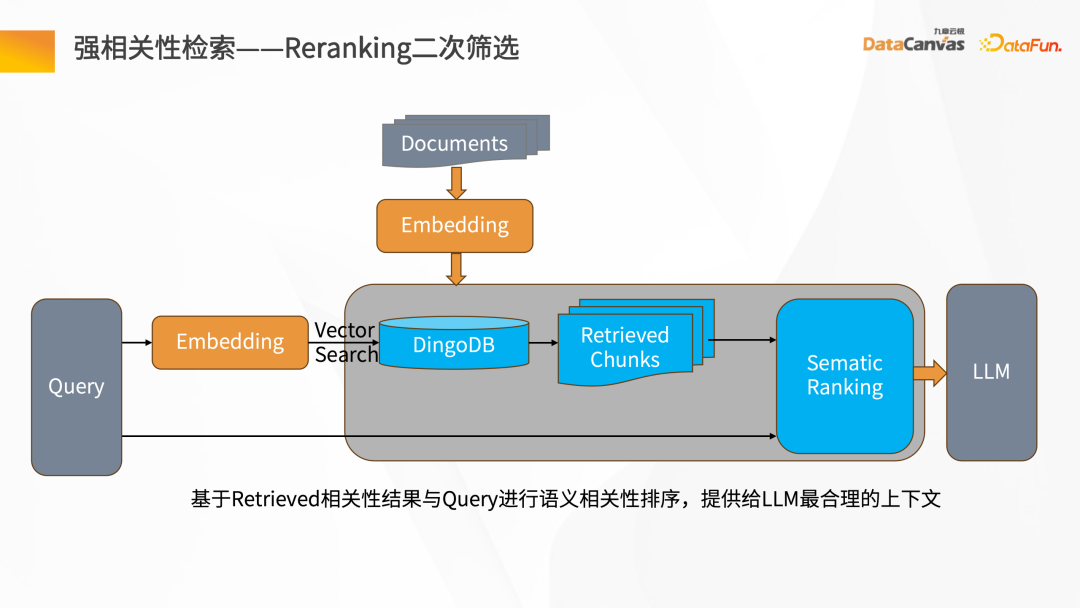
Pendant le filtrage secondaire du reclassement, le morceau de récupération et la requête correspondante doivent être analysés pour la sémantique de corrélation, y compris la recherche de la correspondance sémantique la plus proche, puis le réexamen du morceau de récupération Push to. grands modèles de langage.
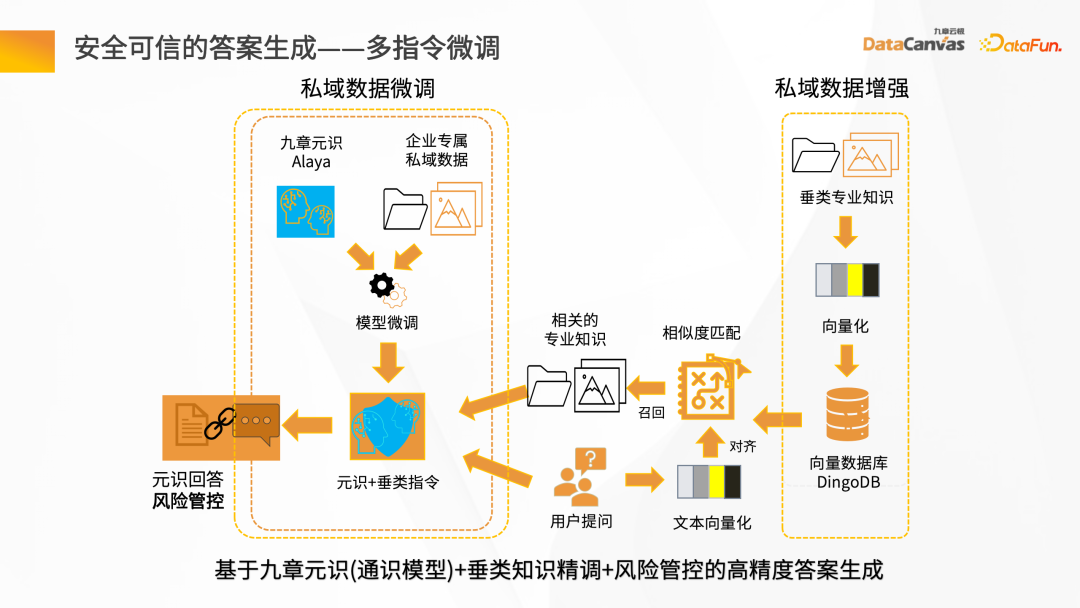
Afin de garantir la sécurité et la fiabilité du processus de génération de réponses, Jiuzhang Yunji DataCanvas est basé sur un modèle universel grand modèle de parole, adapté au rappel. Les données sont utilisées pour limiter les mots d'invite, et le grand modèle est affiné avec des connaissances verticales basées sur les données du domaine privé de l'entreprise, couplées au mécanisme de contrôle de la direction du vent pour garantir une grande précision dans génération de réponses.
DingoDB peut fournir une variété d'API, prendre en charge les requêtes de données via les boîtes à outils SQL et Python, et également fournir un moyen intégré de structurer et les requêtes syndicales non structurées. Pour les scénarios en temps réel, DingoDB offre la possibilité d'interroger en temps réel en écrivant en temps réel, et peut effectuer une récupération en temps réel lors de l'importation de données.
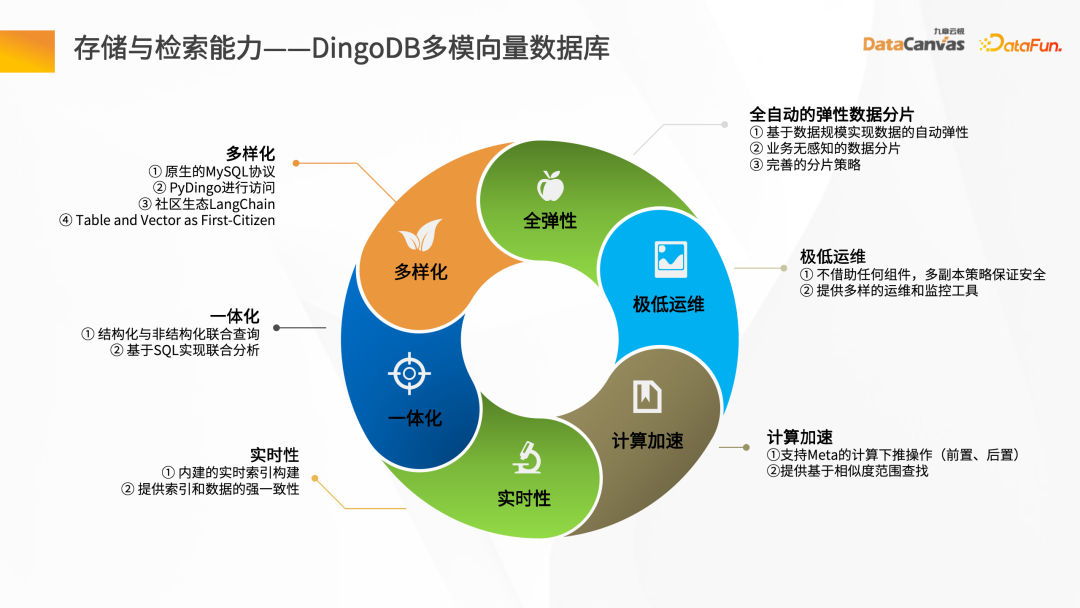
DingoDB fournit également des capacités d'accélération de calcul et prend en charge le pré- et post-filtrage des méta, ainsi que les recherches de plage basées sur la similarité. DingoDB fournit également des outils multi-copies qui peuvent effectuer une migration partielle et une migration de données. Il fournit également des outils d'exploitation, de maintenance et de surveillance diversifiés pour réduire les coûts d'exploitation et de maintenance. DingoDB peut également fournir des capacités de partitionnement élastique automatique, qui peuvent équilibrer dynamiquement les données sur différentes machines pour obtenir un équilibrage de charge sur chaque nœud.
Sur les données du domaine privé d'entreprise, un réglage fin est nécessaire pour les scénarios courants afin de créer un grand modèle de langage spécifique à l'entreprise dans un certain scénario. Le gestionnaire de connaissances résume les points faibles de l'ensemble du processus de réglage fin et propose une approche basée sur des outils dans le produit. Les données sur tous les problèmes peuvent être obtenues en téléchargeant des documents. Après avoir obtenu les données, le réglage fin peut être effectué directement sur l'interface en configurant les paramètres. En même temps, le produit fournit également des indicateurs de données de réglage fin pour évaluer les résultats du réglage fin.

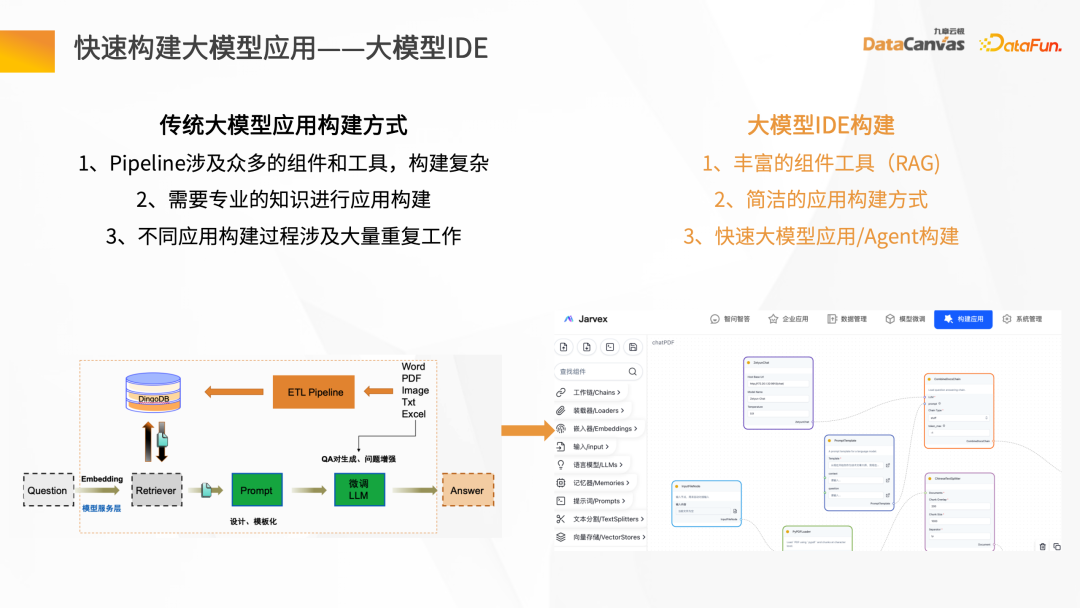
Les applications de grands modèles traditionnelles sont souvent complexes à créer. Knowledge Butler a construit sa propre application de grands modèles basée sur les capacités FS de Jiuzhang Yunji. DataCanvas Model IDE peut fournir une multitude de composants et d'outils et publier les modèles créés dans des agents d'application intelligents via une méthode de construction d'application simple.
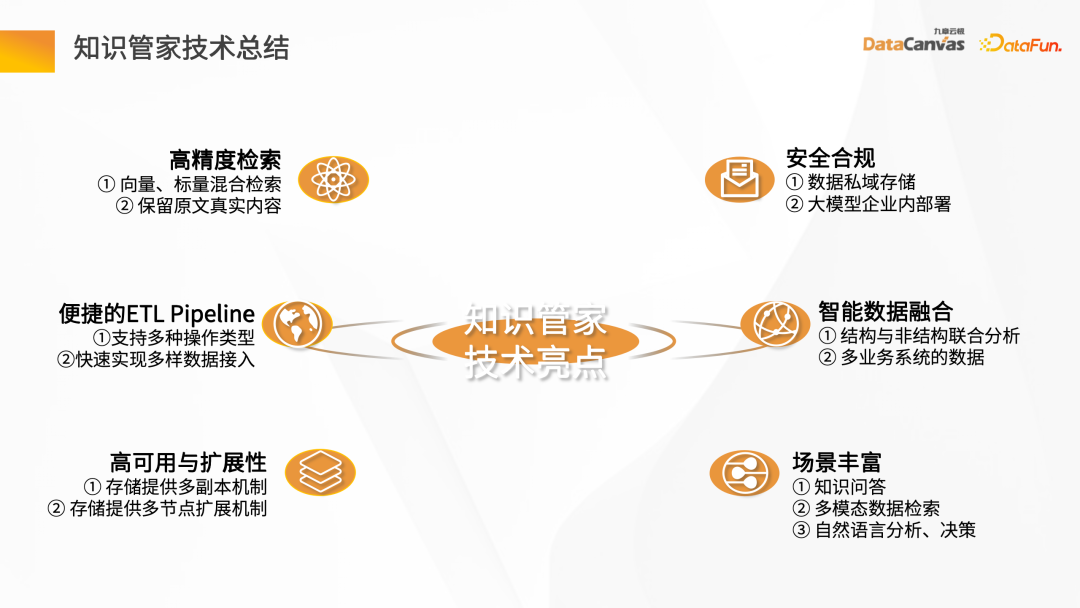
Les points forts techniques de Knowledge Butler incluent principalement les six aspects suivants : récupération de haute précision, pipeline ETL pratique. , haute disponibilité et évolutivité, conformité en matière de sécurité, fusion intelligente des données et scénarios riches.
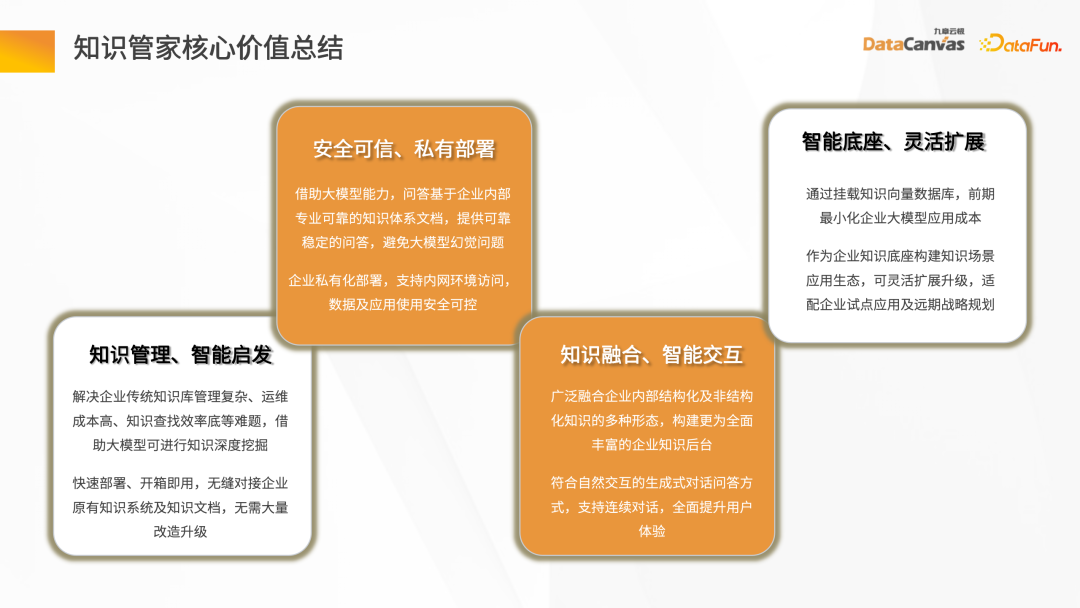
Les valeurs fondamentales de Knowledge Butler incluent : fournir les capacités de base de gestion des connaissances et d'inspiration intelligente, et fournir une méthode de déploiement de privatisation d'applications sûre et fiable, incluant toutes les données de l'entreprise, permettant la réalisation de connaissances Fusion et interaction intelligente. En tant que base intelligente, il offre des capacités d'extension flexibles et peut développer de nouveaux agents basés sur de grands modèles sur Knowledge Manager.
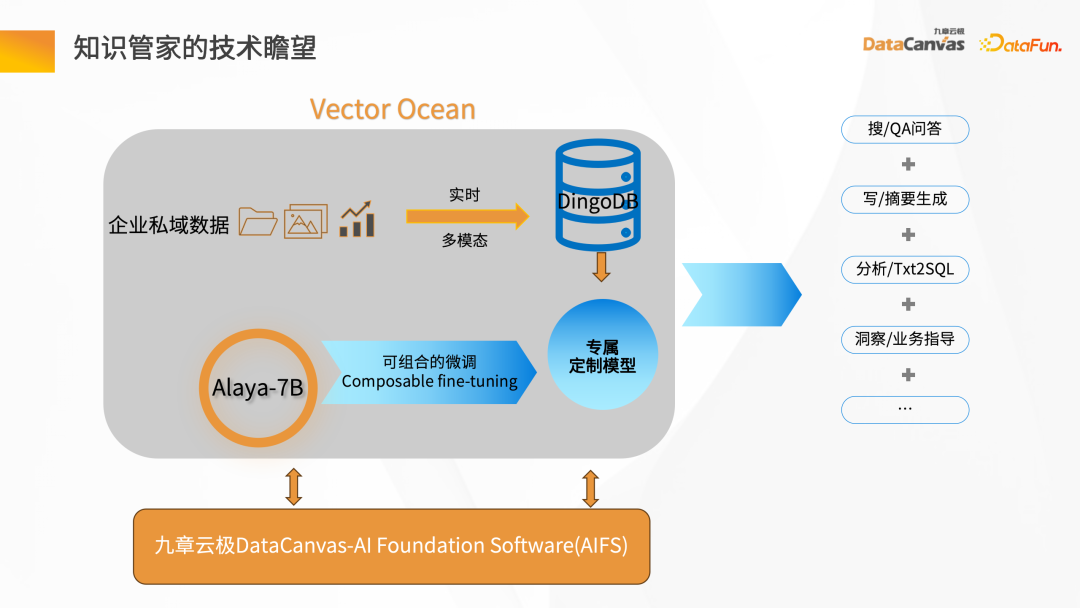
Knowledge Manager est AIFS basé sur Jiuzhang Yunji DataCanvas, qui fournit un ensemble complet de modes Pipeline allant du bare metal à la puissance de calcul GPU et à la planification de modèles, et implémente le réglage fin des modèles. Il utilise le modèle linguistique général et les données du domaine privé de l'entreprise pour effectuer des combinaisons et des ajustements afin de former le propre grand modèle linguistique de l'entreprise. Basé sur l'évolutivité du grand modèle de langage et combiné à la base de données vectorielles multimodale DingoDB, il peut réaliser des recherches de questions et réponses, la génération de résumés et d'autres applications dans l'entreprise, et effectuer la gestion des connaissances d'entreprise.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Base de données trois paradigmes
Base de données trois paradigmes
 Comment supprimer une base de données
Comment supprimer une base de données
 Comment se connecter à la base de données en VB
Comment se connecter à la base de données en VB
 Base de données de restauration MySQL
Base de données de restauration MySQL
 Comment se connecter pour accéder à la base de données en VB
Comment se connecter pour accéder à la base de données en VB
 Comment résoudre le problème du nom d'objet de base de données invalide
Comment résoudre le problème du nom d'objet de base de données invalide
 Comment connecter VB pour accéder à la base de données
Comment connecter VB pour accéder à la base de données
 Comment se connecter à la base de données en utilisant VB
Comment se connecter à la base de données en utilisant VB








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



