
 Périphériques technologiques
IA
Rendu temps réel : modélisation dynamique de scènes urbaines basée sur les Street Gaussians
Périphériques technologiques
IA
Rendu temps réel : modélisation dynamique de scènes urbaines basée sur les Street Gaussians
Rendu temps réel : modélisation dynamique de scènes urbaines basée sur les Street Gaussians

Pour être honnête, la vitesse de mise à jour technologique est en effet très rapide, ce qui a également entraîné le remplacement progressif de certaines anciennes méthodes universitaires par de nouvelles méthodes. Récemment, une équipe de recherche de l’Université du Zhejiang a proposé une nouvelle méthode appelée Gaussiennes, qui a suscité un large intérêt. Cette méthode présente des avantages uniques dans la résolution de problèmes et a été utilisée avec succès dans le travail. Bien que Nerf ait progressivement perdu une certaine influence dans le monde universitaire
Afin d'aider les joueurs qui n'ont pas encore réussi le niveau, jetons un coup d'œil aux méthodes spécifiques de résolution d'énigmes du jeu.
Pour aider les joueurs qui n'ont pas encore réussi le niveau, nous pouvons apprendre ensemble les méthodes spécifiques pour résoudre le puzzle. Pour cela, j'ai trouvé un article sur la résolution d'énigmes, le lien est ici : https://arxiv.org/pdf/2401.01339.pdf. Vous pouvez en apprendre davantage sur les techniques de résolution d’énigmes en lisant cet article. J'espère que cela aidera les joueurs !
Cet article vise à résoudre le problème de la modélisation de scènes de rue urbaines dynamiques à partir de vidéos monoculaires. Des méthodes récentes ont étendu le NeRF pour incorporer des poses de véhicules de suivi dans des véhicules animés, permettant ainsi une synthèse de vues photoréalistes de scènes de rue urbaines dynamiques. Cependant, leurs limites importantes sont la lenteur de l’entraînement et des vitesses de rendu, associées au besoin urgent d’une grande précision dans le suivi des poses des véhicules. Cet article présente les Street Gaussians, une nouvelle représentation de scène explicite qui répond à toutes ces limitations. Plus précisément, les rues dynamiques des villes sont représentées comme un ensemble de nuages de points équipés de logits sémantiques et de gaussiennes 3D, chacun associé à un véhicule ou à un arrière-plan de premier plan.
Pour modéliser la dynamique des véhicules objets au premier plan, chaque nuage de points d'objet peut être optimisé à l'aide de poses de suivi optimisables ainsi que de modèles harmoniques sphériques dynamiques d'apparence dynamique. Cette représentation explicite permet une synthèse simple des véhicules cibles et des arrière-plans, ainsi que des opérations d'édition de scène et de rendu à 133 FPS (résolution 1066×1600) dans la demi-heure suivant la formation. Les chercheurs ont évalué cette approche sur plusieurs critères difficiles, notamment les ensembles de données KITTI et Waymo Open.
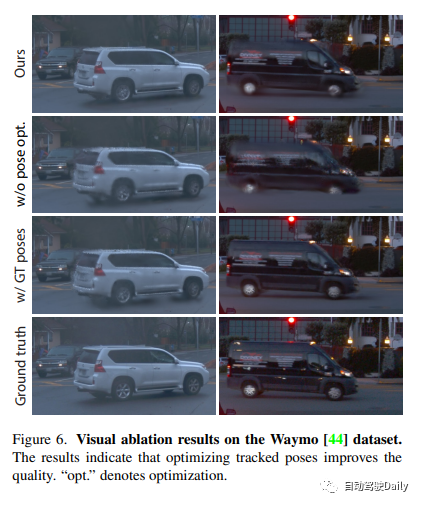
Les résultats expérimentaux montrent que la méthode proposée surpasse systématiquement les techniques existantes sur tous les ensembles de données. Bien que nous nous appuyions uniquement sur les informations de pose provenant de trackers disponibles dans le commerce, notre représentation offre des performances comparables à celles obtenues en utilisant des informations de pose réelles.
Afin d'aider les joueurs n'ayant pas encore réussi le niveau, je vous mets à disposition un lien : https://zju3dv.github.io/streetgaussians/, où vous pourrez trouver la méthode spécifique de résolution d'énigmes. Vous pouvez cliquer sur le lien pour référence, j'espère que cela pourra vous aider.
Introduction à la méthode Street Gaussians
Étant donné une séquence d'images capturées à partir d'un véhicule en mouvement dans une scène de rue urbaine, l'objectif de cet article est de développer une méthode capable de générer des images photoréalistes pour n'importe quel pas de temps d'entrée donné et n’importe quel point de vue. Pour atteindre cet objectif, une nouvelle représentation de scène, appelée Street Gaussians, est proposée, spécifiquement conçue pour représenter des scènes de rue dynamiques. Comme le montre la figure 2, la scène de rue urbaine dynamique est représentée comme un ensemble de nuages de points, chaque nuage de points correspondant à un arrière-plan statique ou à un véhicule en mouvement. La représentation explicite basée sur des points permet une composition simple de modèles individuels, permettant un rendu en temps réel ainsi qu'une décomposition des objets de premier plan pour les applications d'édition. La représentation de la scène proposée peut être entraînée efficacement en utilisant uniquement des images RVB ainsi que des poses de véhicules suivis à partir de trackers disponibles dans le commerce, améliorées par notre stratégie d'optimisation de pose de véhicules suivis.
Aperçu des Gaussiens de rue Comme indiqué ci-dessous, les scènes de rue urbaines dynamiques sont représentées comme un ensemble de cibles d'arrière-plan et de premier plan basées sur des points avec des poses de véhicules suivis optimisées. Chaque point se voit attribuer une gaussienne 3D comprenant la position, l'opacité et la covariance comprenant la rotation et l'échelle pour représenter la géométrie. Pour représenter l'apparence, chaque point d'arrière-plan se voit attribuer un modèle harmonique sphérique, tandis que le point de premier plan est associé à un modèle harmonique sphérique dynamique. La représentation explicite basée sur des points permet une combinaison simple de modèles distincts, ce qui permet le rendu en temps réel d'images et de cartes sémantiques de haute qualité (facultatif si des informations sémantiques 2D sont fournies pendant la formation), ainsi que la décomposition des objets de premier plan pour l'édition de l'application

Comparaison des résultats expérimentaux
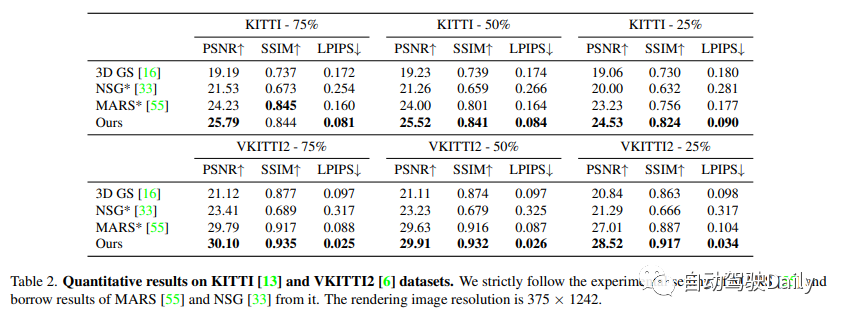
Nous avons mené des expériences sur l'ensemble de données ouvertes Waymo et le benchmark KITTI. Sur l'ensemble de données ouvertes Waymo, 6 séquences d'enregistrement ont été sélectionnées, contenant un grand nombre d'objets en mouvement, des mouvements d'ego importants et des conditions d'éclairage complexes. La longueur de toutes les séquences est d'environ 100 images, et toutes les 10 images de la séquence sont sélectionnées comme images de test et les images restantes sont utilisées pour l'entraînement. Lorsqu'il a été constaté que notre méthode de base avait un coût de mémoire élevé lors de l'entraînement avec des images haute résolution, les images d'entrée ont été réduites à 1 066 × 1 600. Sur KITTI et Vitural KITTI 2, les paramètres de MARS ont été suivis et évalués en utilisant différents paramètres de répartition train/test. Utilisez les boîtes englobantes générées par le détecteur et le tracker sur l'ensemble de données Waymo et utilisez la trajectoire cible officiellement fournie par KITTI.

Comparez notre méthode avec trois méthodes récentes.
(1) NSG représente l'arrière-plan sous la forme d'une image multiplan et modélise les objets en mouvement à l'aide de codes latents appris pour chaque objet et de décodeurs partagés.
(2) MARS crée des graphiques de scène basés sur Nerfstudio.
(3) La Gaussienne 3D modélise la scène à l'aide d'un ensemble de Gaussiennes anisotropes.
NSG et MARS sont tous deux formés et évalués à l'aide de boîtes GT, différentes versions de leurs implémentations sont essayées ici et les meilleurs résultats pour chaque séquence sont rapportés. Nous remplaçons également les nuages de points SfM dans les cartes gaussiennes 3D par la même entrée que notre méthode pour une comparaison équitable. Voir les informations supplémentaires pour plus de détails.



Lien original : https://mp.weixin.qq.com/s/oikZWcR47otm7xfU90JH4g
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Comment implémenter des tables modifiables dans Vue
Nov 08, 2023 pm 12:51 PM
Comment implémenter des tables modifiables dans Vue
Nov 08, 2023 pm 12:51 PM
Les tableaux sont un composant essentiel dans de nombreuses applications Web. Les tableaux contiennent généralement de grandes quantités de données. Ils nécessitent donc certaines fonctionnalités spécifiques pour améliorer l'expérience utilisateur. L'une des fonctionnalités importantes est la possibilité de modification. Dans cet article, nous explorerons comment implémenter des tables modifiables à l'aide de Vue.js et fournirons des exemples de code spécifiques. Étape 1 : préparer les données Tout d'abord, nous devons préparer les données pour le tableau. Nous pouvons utiliser un objet JSON pour stocker les données de la table et les stocker dans la propriété data de l'instance Vue. Dans ce cas
 Le mode veille d'iOS 17 transforme un iPhone en chargement en hub domestique
Jun 06, 2023 am 08:20 AM
Le mode veille d'iOS 17 transforme un iPhone en chargement en hub domestique
Jun 06, 2023 am 08:20 AM
Dans iOS 17, Apple introduit le mode veille, une nouvelle expérience d'affichage conçue pour charger les iPhones en orientation horizontale. Dans cette position, l'iPhone est capable d'afficher une série de widgets en plein écran, le transformant en un hub domestique utile. Le mode veille s'active automatiquement sur un iPhone sous iOS 17 placé horizontalement sur le chargeur. Vous pouvez afficher l'heure, la météo, le calendrier, les commandes musicales, les photos et bien plus encore. Vous pouvez faire glisser votre doigt vers la gauche ou la droite parmi les options de veille disponibles, puis appuyer longuement ou glisser vers le haut/bas pour personnaliser. Par exemple, vous pouvez choisir entre une vue analogique, une vue numérique, une police à bulles et une vue lumière du jour, où la couleur d'arrière-plan change en fonction du temps qui passe. Il existe quelques options
 Comprendre les différences et les comparaisons entre SpringBoot et SpringMVC
Dec 29, 2023 am 09:20 AM
Comprendre les différences et les comparaisons entre SpringBoot et SpringMVC
Dec 29, 2023 am 09:20 AM
Comparez SpringBoot et SpringMVC et comprenez leurs différences Avec le développement continu du développement Java, le framework Spring est devenu le premier choix pour de nombreux développeurs et entreprises. Dans l'écosystème Spring, SpringBoot et SpringMVC sont deux composants très importants. Bien qu'ils soient tous deux basés sur le framework Spring, il existe certaines différences dans les fonctions et l'utilisation. Cet article se concentrera sur la comparaison de SpringBoot et Spring
 Comment utiliser le framework CodeIgniter4 en php ?
May 31, 2023 pm 02:51 PM
Comment utiliser le framework CodeIgniter4 en php ?
May 31, 2023 pm 02:51 PM
PHP est un langage de programmation très populaire et CodeIgniter4 est un framework PHP couramment utilisé. Lors du développement d'applications Web, l'utilisation de frameworks est très utile. Elle peut accélérer le processus de développement, améliorer la qualité du code et réduire les coûts de maintenance. Cet article expliquera comment utiliser le framework CodeIgniter4. Installation du framework CodeIgniter4 Le framework CodeIgniter4 peut être téléchargé depuis le site officiel (https://codeigniter.com/). Vers le bas
 Développement Laravel : Comment générer des vues avec Laravel View ?
Jun 14, 2023 pm 03:28 PM
Développement Laravel : Comment générer des vues avec Laravel View ?
Jun 14, 2023 pm 03:28 PM
Laravel est actuellement l'un des frameworks PHP les plus populaires et ses puissantes capacités de génération de vues sont impressionnantes. Une vue est une page ou un élément visuel affiché à l'utilisateur dans une application Web, qui contient du code tel que HTML, CSS et JavaScript. LaravelView permet aux développeurs d'utiliser un langage de modèle structuré pour créer des pages Web et générer les vues correspondantes via les contrôleurs et le routage. Dans cet article, nous explorerons comment générer des vues à l'aide de LaravelView. 1. Quoi
 Quelles sont les opinions de Word ?
Mar 19, 2024 pm 06:10 PM
Quelles sont les opinions de Word ?
Mar 19, 2024 pm 06:10 PM
Je suppose que de nombreux étudiants souhaitent acquérir les compétences de composition de Word, mais l'éditeur vous dit secrètement qu'avant d'acquérir les compétences de composition, vous devez comprendre clairement les vues de mots. Dans Word2007, 5 vues sont proposées aux utilisateurs. les vues incluent la vue pages, la vue mise en page de lecture, la vue mise en page Web, la vue plan et la vue normale. Découvrons ces 5 vues de mots avec l'éditeur aujourd'hui. 1. Vue de page La vue de page peut afficher l'apparence du résultat d'impression du document Word2007, qui comprend principalement les en-têtes, les pieds de page, les objets graphiques, les paramètres de colonne, les marges de page et d'autres éléments. Il s'agit de la vue de page la plus proche du résultat d'impression. 2. Mode de lecture Le mode de lecture affiche les documents Word2007 et Office dans le style de colonne d'un livre.
 Dans quels scénarios ClassCastException se produit-il en Java ?
Jun 25, 2023 pm 09:19 PM
Dans quels scénarios ClassCastException se produit-il en Java ?
Jun 25, 2023 pm 09:19 PM
Java est un langage fortement typé qui nécessite une correspondance des types de données au moment de l'exécution. En raison du mécanisme strict de conversion de type de Java, s'il y a une incompatibilité de type de données dans le code, une ClassCastException se produira. ClassCastException est l'une des exceptions les plus courantes dans le langage Java. Cet article présentera les causes de ClassCastException et comment l'éviter. Qu'est-ce que ClassCastException
