
 développement back-end
Tutoriel Python
Compréhension approfondie des techniques de suppression des données de lignes dans les pandas
développement back-end
Tutoriel Python
Compréhension approfondie des techniques de suppression des données de lignes dans les pandas
Compréhension approfondie des techniques de suppression des données de lignes dans les pandas


Compétences en traitement de données : Explication détaillée de la façon de supprimer des lignes dans les pandas
En traitement de données, il est souvent nécessaire de supprimer certaines lignes de données dans le DataFrame. Pandas est une puissante bibliothèque de traitement de données qui fournit diverses méthodes pour implémenter des opérations de suppression de données de ligne. Cet article présentera en détail plusieurs méthodes courantes de suppression de lignes dans les pandas et fournira des exemples de code spécifiques.
- Utilisez la méthode drop
L'objet DataFrame de pandas fournit la méthode drop, qui peut supprimer des lignes en spécifiant l'index de la ligne ou l'étiquette de la ligne. Voici un exemple simple :
import pandas as pd
data = {'Name': ['Tom', 'Nick', 'John', 'David'],
'Age': [20, 25, 30, 35],
'Gender': ['M', 'M', 'M', 'M']}
df = pd.DataFrame(data)
# 删除索引为2的行数据
df = df.drop(2)
print(df)Le résultat est le suivant :
Name Age Gender 0 Tom 20 M 1 Nick 25 M 3 David 35 M
Comme vous pouvez le voir, la méthode drop renvoie un nouveau DataFrame et supprime les lignes spécifiées dans le résultat.
- Utilisation de l'indexation booléenne
Dans certains cas, nous devrons peut-être supprimer des lignes en fonction d'une condition. L'indexation booléenne de Pandas fournit un moyen simple de procéder. Voici un exemple :
import pandas as pd
data = {'Name': ['Tom', 'Nick', 'John', 'David'],
'Age': [20, 25, 30, 35],
'Gender': ['M', 'M', 'M', 'M']}
df = pd.DataFrame(data)
# 删除所有年龄小于30的行数据
df = df[df['Age'] >= 30]
print(df)Le résultat est le suivant :
Name Age Gender 2 John 30 M 3 David 35 M
Comme vous pouvez le voir, en définissant l'index booléen sur True ou False, nous pouvons filtrer les données de ligne qui doivent être conservées.
- Utiliser l'opération de découpage
Si vous souhaitez supprimer plusieurs lignes de données consécutives, vous pouvez utiliser l'opération de découpage pour y parvenir. Voici un exemple :
import pandas as pd
data = {'Name': ['Tom', 'Nick', 'John', 'David'],
'Age': [20, 25, 30, 35],
'Gender': ['M', 'M', 'M', 'M']}
df = pd.DataFrame(data)
# 删除索引为1到2的行数据
df = df.drop(df.index[1:3])
print(df)Le résultat est le suivant :
Name Age Gender 0 Tom 20 M 3 David 35 M
Comme vous pouvez le voir, en définissant la plage d'index de l'opération de découpage, nous pouvons supprimer plusieurs lignes de données consécutives.
- Utilisez les méthodes set_index et reset_index
Si l'index de ligne du DataFrame est de type numérique et qu'il manque des lignes, vous pouvez utiliser les méthodes set_index et reset_index pour supprimer les lignes manquantes. Voici un exemple :
import pandas as pd
data = {'Name': ['Tom', 'Nick', 'John', 'David'],
'Age': [20, 25, 30, 35],
'Gender': ['M', 'M', 'M', 'M']}
df = pd.DataFrame(data)
# 设置第三行的索引为缺失
df.set_index(pd.Index(['0', '1', '3']), inplace=True)
# 重置索引并删除缺失的行
df.reset_index(drop=True, inplace=True)
print(df)Le résultat est le suivant :
Name Age Gender 0 Tom 20 M 1 Nick 25 M 2 David 35 M
Comme vous pouvez le voir, en définissant l'index sur la ligne manquante et en utilisant la méthode reset_index pour réinitialiser l'index et supprimer la ligne manquante, nous pouvons supprimer une ligne spécifique.
Pour résumer, voici plusieurs méthodes courantes pour supprimer les données de ligne dans pandas DataFrame. En fonction des différents besoins, nous pouvons choisir une méthode appropriée pour réaliser la tâche de traitement des données. Dans les applications pratiques, des méthodes appropriées peuvent être sélectionnées pour supprimer les données de ligne en fonction de circonstances spécifiques afin d'améliorer l'efficacité et la précision du traitement des données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment supprimer des amis WeChat ? Comment supprimer des amis WeChat
Mar 04, 2024 am 11:10 AM
Comment supprimer des amis WeChat ? Comment supprimer des amis WeChat
Mar 04, 2024 am 11:10 AM
WeChat est l'un des outils de chat traditionnels. Nous pouvons rencontrer de nouveaux amis, contacter d'anciens amis et entretenir l'amitié entre amis grâce à WeChat. Tout comme il n’existe pas de banquet qui ne se termine jamais, des désaccords surviendront inévitablement lorsque les gens s’entendront bien. Lorsqu'une personne affecte extrêmement votre humeur ou que vous constatez que vos points de vue sont incohérents lorsque vous vous entendez bien et que vous ne pouvez plus communiquer, nous devrons peut-être supprimer les amis WeChat. Comment supprimer des amis WeChat ? La première étape pour supprimer des amis WeChat : appuyez sur [Carnet d'adresses] sur l'interface principale de WeChat ; la deuxième étape : cliquez sur l'ami que vous souhaitez supprimer et entrez [Détails] ; la troisième étape : cliquez sur [...] en haut. coin droit ; Étape 4 : Cliquez sur [Supprimer] ci-dessous ; Étape 5 : Après avoir compris les invites de la page, cliquez sur [Supprimer le contact] ;
 Comment écrire un roman dans l'application Tomato Free Novel Partagez le tutoriel sur la façon d'écrire un roman dans l'application Tomato Novel
Mar 28, 2024 pm 12:50 PM
Comment écrire un roman dans l'application Tomato Free Novel Partagez le tutoriel sur la façon d'écrire un roman dans l'application Tomato Novel
Mar 28, 2024 pm 12:50 PM
Tomato Novel est un logiciel de lecture de romans très populaire. Nous avons souvent de nouveaux romans et bandes dessinées à lire dans Tomato Novel. De nombreux amis souhaitent également gagner de l'argent de poche et éditer le contenu de leur roman. Je veux écrire dans du texte. Alors, comment pouvons-nous y écrire le roman ? Mes amis ne le savent pas, alors allons ensemble sur ce site. Prenons le temps de regarder une introduction à la façon d'écrire un roman. Partagez le didacticiel du roman Tomato sur la façon d'écrire un roman. 1. Ouvrez d'abord l'application de roman gratuite Tomato sur votre téléphone mobile et cliquez sur Personal Center - Writer Center 2. Accédez à la page Tomato Writer Assistant - cliquez sur Créer un nouveau livre. à la fin du roman.
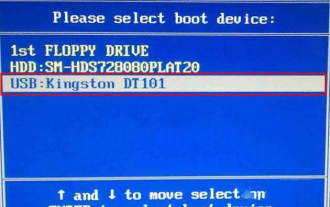 Comment entrer dans le bios sur la carte mère Colorful ? Apprenez-vous deux méthodes
Mar 13, 2024 pm 06:01 PM
Comment entrer dans le bios sur la carte mère Colorful ? Apprenez-vous deux méthodes
Mar 13, 2024 pm 06:01 PM
Les cartes mères colorées jouissent d'une grande popularité et d'une part de marché élevée sur le marché intérieur chinois, mais certains utilisateurs de cartes mères colorées ne savent toujours pas comment accéder au BIOS pour les paramètres ? En réponse à cette situation, l'éditeur vous a spécialement proposé deux méthodes pour accéder au bios coloré de la carte mère. Venez l'essayer ! Méthode 1 : utilisez la touche de raccourci de démarrage du disque U pour accéder directement au système d'installation du disque U. La touche de raccourci de la carte mère Colorful pour démarrer le disque U en un seul clic est ESC ou F11. Tout d'abord, utilisez Black Shark Installation Master pour créer un Black. Disque de démarrage Shark U, puis allumez l'ordinateur lorsque vous voyez l'écran de démarrage, appuyez continuellement sur la touche ESC ou F11 du clavier pour accéder à une fenêtre de sélection de la séquence d'éléments de démarrage. Déplacez le curseur à l'endroit où "USB. " s'affiche, puis
 Comment récupérer des contacts supprimés sur WeChat (un tutoriel simple vous explique comment récupérer des contacts supprimés)
May 01, 2024 pm 12:01 PM
Comment récupérer des contacts supprimés sur WeChat (un tutoriel simple vous explique comment récupérer des contacts supprimés)
May 01, 2024 pm 12:01 PM
Malheureusement, les gens suppriment souvent certains contacts accidentellement pour certaines raisons. WeChat est un logiciel social largement utilisé. Pour aider les utilisateurs à résoudre ce problème, cet article explique comment récupérer les contacts supprimés de manière simple. 1. Comprendre le mécanisme de suppression des contacts WeChat. Cela nous offre la possibilité de récupérer les contacts supprimés. Le mécanisme de suppression des contacts dans WeChat les supprime du carnet d'adresses, mais ne les supprime pas complètement. 2. Utilisez la fonction intégrée « Récupération du carnet de contacts » de WeChat. WeChat fournit une « Récupération du carnet de contacts » pour économiser du temps et de l'énergie. Les utilisateurs peuvent récupérer rapidement les contacts précédemment supprimés grâce à cette fonction. 3. Accédez à la page des paramètres WeChat et cliquez sur le coin inférieur droit, ouvrez l'application WeChat « Moi » et cliquez sur l'icône des paramètres dans le coin supérieur droit pour accéder à la page des paramètres.
 Résumé des méthodes pour obtenir les droits d'administrateur dans Win11
Mar 09, 2024 am 08:45 AM
Résumé des méthodes pour obtenir les droits d'administrateur dans Win11
Mar 09, 2024 am 08:45 AM
Un résumé de la façon d'obtenir les droits d'administrateur Win11 Dans le système d'exploitation Windows 11, les droits d'administrateur sont l'une des autorisations très importantes qui permettent aux utilisateurs d'effectuer diverses opérations sur le système. Parfois, nous pouvons avoir besoin d'obtenir des droits d'administrateur pour effectuer certaines opérations, telles que l'installation de logiciels, la modification des paramètres du système, etc. Ce qui suit résume quelques méthodes pour obtenir les droits d'administrateur Win11, j'espère que cela pourra vous aider. 1. Utilisez les touches de raccourci. Dans le système Windows 11, vous pouvez ouvrir rapidement l'invite de commande via les touches de raccourci.
 Comment définir la taille de la police sur le téléphone mobile (ajustez facilement la taille de la police sur le téléphone mobile)
May 07, 2024 pm 03:34 PM
Comment définir la taille de la police sur le téléphone mobile (ajustez facilement la taille de la police sur le téléphone mobile)
May 07, 2024 pm 03:34 PM
La définition de la taille de la police est devenue une exigence de personnalisation importante à mesure que les téléphones mobiles deviennent un outil important dans la vie quotidienne des gens. Afin de répondre aux besoins des différents utilisateurs, cet article présentera comment améliorer l'expérience d'utilisation du téléphone mobile et ajuster la taille de la police du téléphone mobile grâce à des opérations simples. Pourquoi avez-vous besoin d'ajuster la taille de la police de votre téléphone mobile - L'ajustement de la taille de la police peut rendre le texte plus clair et plus facile à lire - Adapté aux besoins de lecture des utilisateurs d'âges différents - Pratique pour les utilisateurs malvoyants qui souhaitent utiliser la taille de la police fonction de configuration du système de téléphonie mobile - Comment accéder à l'interface des paramètres du système - Dans Rechercher et entrez l'option "Affichage" dans l'interface des paramètres - recherchez l'option "Taille de la police" et ajustez-la. application - téléchargez et installez une application prenant en charge l'ajustement de la taille de la police - ouvrez l'application et entrez dans l'interface des paramètres appropriée - en fonction de l'individu
 Le secret de l'éclosion des œufs de dragon mobiles est révélé (étape par étape pour vous apprendre à réussir l'éclosion des œufs de dragon mobiles)
May 04, 2024 pm 06:01 PM
Le secret de l'éclosion des œufs de dragon mobiles est révélé (étape par étape pour vous apprendre à réussir l'éclosion des œufs de dragon mobiles)
May 04, 2024 pm 06:01 PM
Les jeux mobiles font désormais partie intégrante de la vie des gens avec le développement de la technologie. Il a attiré l'attention de nombreux joueurs avec sa jolie image d'œuf de dragon et son processus d'éclosion intéressant, et l'un des jeux qui a beaucoup attiré l'attention est la version mobile de Dragon Egg. Pour aider les joueurs à mieux cultiver et faire grandir leurs propres dragons dans le jeu, cet article vous présentera comment faire éclore des œufs de dragon dans la version mobile. 1. Choisissez le type d'œuf de dragon approprié. Les joueurs doivent choisir soigneusement le type d'œuf de dragon qu'ils aiment et qui leur conviennent, en fonction des différents types d'attributs et de capacités d'œuf de dragon fournis dans le jeu. 2. Améliorez le niveau de la machine d'incubation. Les joueurs doivent améliorer le niveau de la machine d'incubation en accomplissant des tâches et en collectant des accessoires. Le niveau de la machine d'incubation détermine la vitesse d'éclosion et le taux de réussite de l'éclosion. 3. Collectez les ressources nécessaires à l'éclosion. Les joueurs doivent être dans le jeu.
 Explication détaillée de la méthode de requête de version Oracle
Mar 07, 2024 pm 09:21 PM
Explication détaillée de la méthode de requête de version Oracle
Mar 07, 2024 pm 09:21 PM
Explication détaillée de la méthode de requête de version Oracle Oracle est l'un des systèmes de gestion de bases de données relationnelles les plus populaires au monde. Il offre des fonctions riches et des performances puissantes et est largement utilisé dans les entreprises. Dans le processus de gestion et de développement de bases de données, il est très important de comprendre la version de la base de données Oracle. Cet article présentera en détail comment interroger les informations de version de la base de données Oracle et donnera des exemples de code spécifiques. Interrogez la version de base de données de l'instruction SQL dans la base de données Oracle en exécutant une simple instruction SQL
