
 Java
javaDidacticiel
Comparaison des frameworks de robots d'exploration Java : quel est le meilleur choix ?
Java
javaDidacticiel
Comparaison des frameworks de robots d'exploration Java : quel est le meilleur choix ?
Comparaison des frameworks de robots d'exploration Java : quel est le meilleur choix ?


Exploration du meilleur framework de robot d'exploration Java : lequel est le meilleur ?
À l’ère de l’information d’aujourd’hui, une grande quantité de données est constamment générée et mise à jour sur Internet. Afin d’extraire des informations utiles à partir de données massives, la technologie des robots d’exploration a vu le jour. Dans la technologie des robots d'exploration, Java, en tant que langage de programmation puissant et largement utilisé, propose de nombreux excellents frameworks de robots d'exploration. Cet article explorera plusieurs frameworks de robots d'exploration Java courants, analysera leurs caractéristiques et les scénarios applicables, et enfin trouvera le meilleur.
- Jsoup
Jsoup est un framework de robots d'exploration Java très populaire qui peut traiter des documents HTML de manière simple et flexible. Jsoup fournit une API simple et puissante qui facilite grandement l'analyse, la navigation et la manipulation du HTML. Voici un exemple de base de Jsoup :
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupExample {
public static void main(String[] args) throws Exception {
// 发送HTTP请求获取HTML文档
String url = "http://example.com";
Document doc = Jsoup.connect(url).get();
// 解析并遍历HTML文档
Elements links = doc.select("a[href]");
for (Element link : links) {
System.out.println(link.attr("href"));
}
}
}- Apache Nutch
Apache Nutch est un logiciel open source de scraping Web et de moteur de recherche. Il est développé sur la base de Java et offre des fonctions riches et une évolutivité flexible. Apache Nutch prend en charge l'exploration distribuée à grande échelle et peut traiter efficacement de grandes quantités de données de pages Web. Voici un exemple simple d'Apache Nutch :
import org.apache.nutch.crawl.CrawlDatum;
import org.apache.nutch.crawl.Inlinks;
import org.apache.nutch.fetcher.Fetcher;
import org.apache.nutch.parse.ParseResult;
import org.apache.nutch.protocol.Content;
import org.apache.nutch.util.NutchConfiguration;
public class NutchExample {
public static void main(String[] args) throws Exception {
String url = "http://example.com";
// 创建Fetcher对象
Fetcher fetcher = new Fetcher(NutchConfiguration.create());
// 抓取网页内容
Content content = fetcher.fetch(new CrawlDatum(url));
// 处理网页内容
ParseResult parseResult = fetcher.parse(content);
Inlinks inlinks = parseResult.getInlinks();
// 输出入链的数量
System.out.println("Inlinks count: " + inlinks.getInlinks().size());
}
}- WebMagic
WebMagic est un framework d'exploration Java open source basé sur Jsoup et HttpClient et fournit une API simple et facile à utiliser. WebMagic prend en charge l'analyse simultanée multithread, ce qui facilite la définition des règles d'analyse et le traitement des résultats de l'analyse. Ce qui suit est un exemple simple de WebMagic :
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
public class WebMagicExample implements PageProcessor {
public void process(Page page) {
// 解析HTML页面
String title = page.getHtml().$("title").get();
// 获取链接并添加新的抓取任务
page.addTargetRequests(page.getHtml().links().regex("http://example.com/.*").all());
// 输出结果
page.putField("title", title);
}
public Site getSite() {
return Site.me().setRetryTimes(3).setSleepTime(1000);
}
public static void main(String[] args) {
Spider.create(new WebMagicExample())
.addUrl("http://example.com")
.addPipeline(new ConsolePipeline())
.run();
}
}Comparaison complète des frameworks de robots ci-dessus, ils ont tous leurs propres avantages et scénarios applicables. Jsoup convient aux scénarios relativement simples d'analyse et d'exploitation de HTML ; Apache Nutch convient à l'exploration et à la recherche de données distribuées à grande échelle ; WebMagic fournit une API simple et facile à utiliser et des fonctionnalités d'analyse simultanée multithread. En fonction des besoins spécifiques et des caractéristiques du projet, le choix du cadre le plus approprié est essentiel.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment activer la fonction nfc sur Xiaomi Mi 14 Pro ?
Mar 19, 2024 pm 02:28 PM
Comment activer la fonction nfc sur Xiaomi Mi 14 Pro ?
Mar 19, 2024 pm 02:28 PM
De nos jours, les performances et les fonctions des téléphones mobiles deviennent de plus en plus puissantes. Presque tous les téléphones mobiles sont équipés de fonctions NFC pratiques pour faciliter le paiement mobile et l'authentification de l'identité des utilisateurs. Cependant, certains utilisateurs de Xiaomi 14Pro ne savent peut-être pas comment activer la fonction NFC. Ensuite, permettez-moi de vous le présenter en détail. Comment activer la fonction nfc sur Xiaomi 14Pro ? Étape 1 : Ouvrez le menu des paramètres de votre téléphone. Étape 2 : Recherchez et cliquez sur l'option « Connecter et partager » ou « Sans fil et réseaux ». Étape 3 : Dans le menu Connexion et partage ou Sans fil et réseaux, recherchez et cliquez sur « NFC et paiements ». Étape 4 : Recherchez et cliquez sur « NFC Switch ». Généralement, la valeur par défaut est désactivée. Étape 5 : Sur la page du commutateur NFC, cliquez sur le bouton du commutateur pour l'activer.
 Comment utiliser TikTok sur Huawei Pocket2 à distance ?
Mar 18, 2024 pm 03:00 PM
Comment utiliser TikTok sur Huawei Pocket2 à distance ?
Mar 18, 2024 pm 03:00 PM
Faire glisser l'écran dans les airs est une fonctionnalité de Huawei très appréciée dans la série Huawei mate60. Cette fonctionnalité utilise le capteur laser du téléphone et la caméra de profondeur 3D de la caméra frontale pour compléter une série de fonctions qui ne nécessitent pas de fonction. fonction de toucher l'écran, comme faire glisser TikTok depuis les airs, mais comment utiliser le Huawei Pocket 2 pour faire glisser TikTok depuis les airs ? Comment faire des captures d'écran depuis les airs avec Huawei Pocket2 ? 1. Ouvrez les paramètres de Huawei Pocket2. 2. Sélectionnez ensuite [Accessibilité]. 3. Cliquez pour ouvrir [Perception intelligente]. 4. Activez simplement les commutateurs [Air Swipe Screen], [Air Screenshot] et [Air Press]. 5. Lorsque vous l'utilisez, vous devez le tenir à 20 ~ 40 cm de l'écran, ouvrir votre paume et attendre que l'icône de la paume apparaisse sur l'écran.
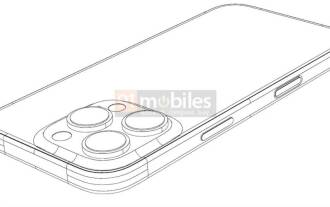 Les dessins CAO de l'iPhone 16 Pro exposés, ajoutant un deuxième nouveau bouton
Mar 09, 2024 pm 09:07 PM
Les dessins CAO de l'iPhone 16 Pro exposés, ajoutant un deuxième nouveau bouton
Mar 09, 2024 pm 09:07 PM
Les fichiers CAO de l'iPhone 16 Pro ont été exposés et la conception est conforme aux rumeurs précédentes. L'automne dernier, l'iPhone 15 Pro a ajouté un bouton d'action, et cet automne, Apple semble prévoir d'apporter des ajustements mineurs à la taille du matériel. Ajout d'un bouton Capture Selon les rumeurs, l'iPhone 16 Pro pourrait ajouter un deuxième nouveau bouton, ce qui sera la deuxième année consécutive à ajouter un nouveau bouton après l'année dernière. La rumeur veut que le nouveau bouton Capture soit placé sur le côté inférieur droit de l'iPhone 16 Pro. Cette conception devrait rendre le contrôle de l'appareil photo plus pratique et permettre également d'utiliser le bouton Action pour d'autres fonctions. Ce bouton ne sera plus un simple déclencheur ordinaire. Concernant la caméra, à partir de l'iP actuelle
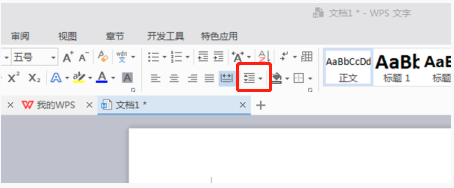 Comment définir l'espacement des lignes dans WPS Word pour rendre le document plus soigné
Mar 20, 2024 pm 04:30 PM
Comment définir l'espacement des lignes dans WPS Word pour rendre le document plus soigné
Mar 20, 2024 pm 04:30 PM
WPS est notre logiciel bureautique couramment utilisé lors de l'édition d'articles longs, les polices sont souvent trop petites pour être clairement visibles, c'est pourquoi les polices et l'ensemble du document sont ajustés. Par exemple : ajuster l'espacement des lignes du document rendra l'ensemble du document très clair. Je suggère à tous les amis d'apprendre cette étape de l'opération. Je la partagerai avec vous aujourd'hui. Les étapes de l'opération spécifiques sont les suivantes, venez jeter un oeil ! Ouvrez le fichier texte WPS que vous souhaitez ajuster, recherchez la barre d'outils de configuration des paragraphes dans le menu [Démarrer] et vous verrez la petite icône de configuration de l'espacement des lignes (représentée par un cercle rouge dans l'image). 2. Cliquez sur le petit triangle inversé dans le coin inférieur droit du paramètre d'espacement des lignes et la valeur d'espacement des lignes correspondante apparaîtra. Vous pouvez choisir 1 à 3 fois l'espacement des lignes (comme indiqué par la flèche sur la figure). 3. Ou cliquez avec le bouton droit sur le paragraphe et il apparaîtra.
 Comment changer de langue dans les équipes Microsoft
Feb 23, 2024 pm 09:00 PM
Comment changer de langue dans les équipes Microsoft
Feb 23, 2024 pm 09:00 PM
Il existe de nombreuses langues parmi lesquelles choisir dans Microsoft Teams, alors comment changer de langue ? Les utilisateurs doivent cliquer sur le menu, puis rechercher Paramètres, y sélectionner Général, puis cliquer sur Langue, sélectionner la langue et l'enregistrer. Cette introduction aux méthodes de changement de langue peut vous indiquer le contenu spécifique. Ce qui suit est une introduction détaillée. Bar! Comment changer de langue dans Microsoft Teams Réponse : Sélectionnez le processus spécifique dans Paramètres-Général-Langue : 1. Tout d'abord, cliquez sur les trois points à côté de l'avatar pour entrer les paramètres. 2. Cliquez ensuite sur les options générales à l'intérieur. 3. Cliquez ensuite sur la langue et faites défiler vers le bas pour voir plus de langues. 4. Enfin, cliquez sur Enregistrer et redémarrer.
 Comment définir une sonnerie personnalisée pour Redmi K70E ?
Feb 24, 2024 am 10:00 AM
Comment définir une sonnerie personnalisée pour Redmi K70E ?
Feb 24, 2024 am 10:00 AM
Le Redmi K70E est sans aucun doute excellent. En tant que téléphone mobile avec un prix d'un peu plus de 2 000 yuans, le Redmi K70E peut être considéré comme l'un des téléphones mobiles les plus économiques de sa catégorie. De nombreux utilisateurs à la recherche de rentabilité ont acheté ce téléphone pour profiter de diverses fonctions sur le Redmi K70E. Alors comment définir une sonnerie personnalisée pour Redmi K70E ? Comment définir une sonnerie personnalisée pour Redmi K70E ? Pour définir une sonnerie d'appel entrant personnalisée pour Redmi K70E, vous pouvez suivre les étapes ci-dessous : Ouvrez l'application des paramètres de votre téléphone, recherchez l'option "Sons et vibrations" ou "Son" dans l'application des paramètres, puis cliquez sur "Sonnerie d'appel entrant". ou "Sonnerie du téléphone" ". Dans les paramètres de sonnerie
 TrendX Research Institute : analyse du projet Merlin Chain et inventaire écologique
Mar 24, 2024 am 09:01 AM
TrendX Research Institute : analyse du projet Merlin Chain et inventaire écologique
Mar 24, 2024 am 09:01 AM
Selon les statistiques du 2 mars, la TVL totale du réseau de deuxième couche de Bitcoin, MerlinChain, a atteint 3 milliards de dollars. Parmi eux, les actifs écologiques Bitcoin représentaient 90,83 %, dont BTC d’une valeur de 1,596 milliard de dollars et les actifs BRC-20 d’une valeur de 404 millions de dollars. Le mois dernier, le TVL total de MerlinChain a atteint 1,97 milliard de dollars américains dans les 14 jours suivant le lancement des activités de jalonnement, dépassant Blast, qui a été lancé en novembre de l'année dernière et est également le plus récent et tout aussi accrocheur. Le 26 février, la valeur totale des NFT dans l'écosystème MerlinChain a dépassé 420 millions de dollars américains, devenant ainsi le projet de chaîne publique avec la valeur marchande NFT la plus élevée après Ethereum. Introduction du projet MerlinChain est un support OKX
 Comparaison et analyse des avantages et inconvénients des versions PHP7.2 et 5
Feb 27, 2024 am 10:51 AM
Comparaison et analyse des avantages et inconvénients des versions PHP7.2 et 5
Feb 27, 2024 am 10:51 AM
Comparaison et analyse des avantages et des inconvénients de PHP7.2 et 5. PHP est un langage de script côté serveur extrêmement populaire et largement utilisé dans le développement Web. Cependant, PHP est constamment mis à jour et amélioré dans différentes versions pour répondre à l'évolution des besoins. Actuellement, PHP7.2 est la dernière version, qui présente de nombreuses différences et améliorations notables par rapport à la version précédente de PHP5. Dans cet article, nous comparerons les versions PHP7.2 et PHP5, analyserons leurs avantages et inconvénients et fournirons des exemples de code spécifiques. 1. PH des performances
