
 Périphériques technologiques
IA
Morph Studio : un puissant logiciel de montage vidéo Dark Horse gratuit, 1080P, de 7 secondes, arrive
Périphériques technologiques
IA
Morph Studio : un puissant logiciel de montage vidéo Dark Horse gratuit, 1080P, de 7 secondes, arrive
Morph Studio : un puissant logiciel de montage vidéo Dark Horse gratuit, 1080P, de 7 secondes, arrive

"Des méduses lumineuses s'élèvent lentement de l'océan", continuez à taper ce que vous voulez voir dans Morph Studio, "se transformant en constellations étincelantes dans le ciel nocturne".
Après quelques minutes, Morph Studio génère une courte vidéo. Une méduse est complètement transparente et scintillante, tournant et s'élevant, sa silhouette ondulante contrastant avec les étoiles du ciel nocturne.
Des méduses lumineuses surgissent d'une mer enchanteresse, se transformant en étoiles scintillantes dans le ciel sombre
Entrez dans "le cinéma du joker", et le visage qui a autrefois pris d'assaut le monde est de retour.
Joaquin Phoenix offre une performance hyper-réaliste dans le rôle du Joker dans le plan cinématographique se déroulant dans les rues éclairées au néon de New York. De la fumée s'élève autour de lui, ajoutant à l'atmosphère de chaos et d'obscurité.
Récemment, Startup Morph Studio a effectué une mise à jour majeure de sa technologie et de sa communauté de génération de texte en vidéo. Leur modèle a subi une mise à jour majeure et ces productions vidéo présentent le modèle mis à jour avec des images claires et des détails éclatants.
Morph Studio est la première équipe au monde à lancer publiquement des produits de conversion texte-vidéo que le public peut tester à volonté, avant que Runway ne lance la version bêta publique de Gen2.
Comparé à d'autres produits de conversion texte-vidéo populaires, Morph Studio est différent en termes de services gratuits. Il offre une résolution par défaut de 1080P et un temps de construction maximum de 7 secondes dès le départ. Pour les produits texte-vidéo, une résolution plus élevée, un temps de génération plus long et une meilleure expression de l'intention sont trois indicateurs clés. Morph a atteint le dernier niveau de l'industrie dans ces trois indicateurs.
La durée moyenne d'un seul plan d'un film hollywoodien est de 6 secondes. L'extension du temps de génération à 7 secondes peut répondre aux besoins créatifs d'un plus grand nombre d'utilisateurs.
Découvrir les modèles de Morph Studio est simple, vous pouvez l'utiliser gratuitement en vous inscrivant sur Discord.
Le modèle avec le mot « pro » dans la case rouge sur l'écran est le modèle mis à jour et fait l'objet de l'expérience de cet article.
Le mouvement de la caméra est le langage de base de la production vidéo et un puissant dispositif narratif. Morph propose plusieurs langages généraux de caméra, notamment le zoom, le panoramique (haut, bas, gauche, droite), la rotation (dans le sens des aiguilles d'une montre ou dans le sens inverse) et les prises de vue fixes.
Morph fournit également la fonction MOTION (1-10) pour contrôler le mouvement vidéo. Plus la valeur est grande, plus l’action est violente et exagérée. Plus la valeur est petite, plus l’action est subtile et douce.
Frame rate (FPS) offre une plage de réglage de 8 à 30. Plus la valeur est élevée, plus la vidéo est fluide et plus la taille est grande. Par exemple, -FPS 30 produira la vidéo la plus fluide mais aussi la plus grande. Par défaut, toutes les vidéos sont créées à 24 images par seconde.
La durée de la vidéo par défaut est de 3 secondes Pour générer une vidéo de 7 secondes, vous pouvez saisir -s 7 dans la commande. De plus, le modèle propose 5 ratios vidéo parmi lesquels choisir.
Si vous avez des exigences concernant des détails tels que l'objectif, la fréquence d'images et la durée de la vidéo, veuillez continuer à saisir les paramètres correspondants après avoir entré l'invite de contenu. (Actuellement, seule la saisie en anglais est prise en charge.)
Nous avons expérimenté le service de modèles mis à jour et avons fortement ressenti le choc visuel apporté par 1080P.
Jusqu'à récemment, les humains avaient la première photo d'un léopard des neiges marchant sous les étoiles :

La première photo d'un léopard des neiges marchant sous les étoiles.
Nous voulons savoir, le modèle de Morph Studio peut-il générer des vidéos de cet animal relativement rare ?
Avec la même invite, nous mettons les œuvres de Morph Studio dans la partie supérieure de la vidéo, et les œuvres générées avec Pika dans la partie inférieure de la vidéo.
un léopard des neiges marchant sous une nuit étoilée, réaliste cinématographique, super détail, -motion 10, -ar 16:9, -zoom avant, -pan up, -fps 30, -s 7. négatif : membres supplémentaires, Bras et jambes manquants, doigts et jambes fusionnés, doigts supplémentaires, défiguration
La feuille de réponses de Morph Studio permet une compréhension précise du texte. Sur la photo 1080P, les cheveux du léopard des neiges sont riches en détails et réalistes. La Voie lactée et les étoiles sont visibles en arrière-plan. Cependant, le mouvement du léopard des neiges n’est pas évident.
Dans les devoirs de Pika, le léopard des neiges marche effectivement, mais le ciel nocturne semble être compris comme une nuit avec de gros flocons de neige. Il existe encore une lacune en termes de style, de détails et de clarté d’image de Snow Leopard.
Regardons à nouveau l'effet de la génération de personnages.
chef-d'œuvre de la meilleure qualité vidéo RAW ultra détaillée 1 fille dansant en solo peinture numérique belle fille cyborg âgée de 21 ans longs cheveux roux ondulés yeux bleus peau blanche pâle délicate corps parfait chantant dans la lumière étrange de l'aube dans un post-apocalypse
Morph Dans les œuvres générées par Studio, la haute résolution apporte des contours du visage et des micro-expressions extrêmement délicats, et sous la lumière de l'aube, les détails des cheveux sont clairement visibles.
Sous réserve du manque de résolution, de couleur et de niveaux de lumière, les images générées par Pika sont globalement bleutées, et les détails du visage des personnages ne sont pas satisfaisants.
Les gens et les animaux en ont tous fait l'expérience, jetons un coup d'œil à l'effet de génération des bâtiments (objets fabriqués par l'homme).
La torre eifel nuit étoilée de van gogh épique élégant beaux-arts complexes couleurs profondes coulant des nuages en mouvement
Comparé au travail de Pika, qui ressemble davantage à une peinture, le travail de Morph Studio équilibre mieux les éléments de Van Gogh et les éléments réalistes , les niveaux de lumière sont très riches, en particulier les détails fluides de la mer de nuages, et le ciel dans les œuvres de Pika est presque statique.
Enfin, expérimentez la création de paysages naturels.
Un petit matin, le soleil s'est lentement levé du niveau de la mer et les vagues ont doucement touché la plage.
Vous vous demandez peut-être si les œuvres de Morph Studio sont de véritables photos prises par des photographes humains dans des conditions naturelles.
En raison du manque de niveaux de lumière et d'ombre délicats, la vidéo générée par Pika donne l'impression que les vagues et la plage sont plates, et les mouvements des vagues frappant la plage sont relativement ternes.
En plus de l'expérience choquante apportée par la haute résolution, avec la même invite à générer des vidéos (comme des thèmes d'animaux, de bâtiments, de personnes et de paysages naturels), les adversaires "manqueront" plus ou moins certaines tâches de génération, et Morph Studio fonctionne relativement bien. Il est plus stable, comporte relativement moins de cas particuliers et peut prédire plus précisément les intentions des utilisateurs.
Dès le début, la compréhension de Vincent Video par cette startup est que la vidéo doit être capable de décrire très précisément les entrées de l'utilisateur, et tous les travaux d'optimisation vont également dans cette direction. La structure du modèle de Morph Studio a une compréhension plus approfondie des intentions textuelles. Cette mise à jour a apporté quelques modifications structurelles et a spécialement créé des annotations plus détaillées pour certaines données.
En plus de la capacité de compréhension de texte relativement bonne, le traitement détaillé de l'image n'est pas gêné par la sortie haute résolution. En fait, après la mise à jour du modèle, le contenu de mouvement de l'écran était plus riche, ce qui se reflète également dans les œuvres que nous avons générées à l'aide de Morph Studio.
Lorsque la « Fille à la perle » bouge la tête, les boucles d'oreilles tremblent également légèrement ; les images impliquant des actions plus complexes telles que l'équitation sont également plus fluides, cohérentes et logiques, et le résultat des mouvements de la main est bien aussi.
1080P signifie que le modèle doit traiter plus de pixels, ce qui pose de plus grands défis dans la génération de détails. Cependant, à en juger par les résultats, non seulement l'image ne s'effondre pas, mais elle est plus expressive en raison du riche niveau de détails. .
Il s'agit d'un ensemble de paysages naturels que nous avons générés à l'aide de modèles, comprenant d'énormes vagues spectaculaires et des éruptions volcaniques, ainsi que de délicats gros plans de fleurs.
La sortie haute résolution apporte un meilleur plaisir visuel aux utilisateurs, mais elle prolonge également le temps de sortie du modèle et affecte l'expérience.
Morph Studio génère désormais des vidéos 1080p en 3 minutes et demie, soit la même vitesse que les vidéos 720P de Pika. Les start-up disposent de ressources informatiques limitées, il n'est donc pas facile pour Morph Studio de maintenir SOTA.
De plus, en termes de style vidéo, en plus du réalisme cinématographique, les modèles Morph Studio prennent également en charge des styles courants tels que la bande dessinée et l'animation 3D.
Morph Studio se concentre sur la technologie texte-vidéo et est considéré comme la prochaine étape du concours de l'industrie de l'IA.
« La vidéo instantanée pourrait représenter le prochain pas en avant dans la technologie de l'IA », a déclaré le New York Times dans le titre d'un rapport technologique, affirmant qu'elle sera aussi importante que le navigateur Web et l'iPhone.
En septembre 2022, l'équipe d'ingénieurs en apprentissage automatique de Meta a lancé un nouveau système appelé Make-A-Video. Les utilisateurs saisissent une description approximative de la scène et le système générera une courte vidéo correspondante.
En novembre 2022, des chercheurs de l'Université Tsinghua et de l'Académie d'intelligence artificielle de Pékin (BAAI) ont également publié CogVideo.
À cette époque, les vidéos générées par ces modèles étaient non seulement floues (par exemple, la résolution vidéo générée par CogVideo n'était que de 480 x 480), les images étaient également relativement déformées et il y avait de nombreuses limitations techniques. Mais ils représentent encore une évolution significative dans la génération de contenu IA.
En apparence, une vidéo n'est qu'une série d'images (images fixes) assemblées de manière à donner l'illusion du mouvement. Il est cependant beaucoup plus difficile d’assurer la cohérence d’une série d’images dans le temps et dans l’espace.
L'émergence du modèle de diffusion a accéléré l'évolution de la technologie. Les chercheurs ont tenté de généraliser le modèle de diffusion à d’autres domaines tels que l’audio, la 3D et la vidéo, et la technologie de synthèse vidéo a fait des progrès significatifs.
La technologie basée sur le modèle de diffusion permet principalement au réseau neuronal d'apprendre automatiquement certains modèles en triant des images massives, des vidéos et des descriptions textuelles. Lorsque vous saisissez les exigences de contenu, le réseau neuronal génère une liste de toutes les fonctionnalités qui, selon lui, pourraient être utilisées pour créer l'image (pensez au contour des oreilles d'un chat, aux bords d'un téléphone).
Ensuite, le deuxième réseau de neurones (également connu sous le nom de modèle de diffusion) est chargé de créer l'image et de générer les pixels requis pour ces caractéristiques, et de convertir les pixels en une image cohérente.
En analysant des milliers de vidéos, l'IA peut apprendre à enchaîner de nombreuses images fixes de manière tout aussi cohérente. La clé est de former un modèle qui comprend réellement les relations et la cohérence entre chaque image.
"C'est l'une des technologies les plus impressionnantes que nous ayons construites au cours des cent dernières années", a déclaré un jour Cristóbal Valenzuela, PDG de Runway, aux médias, "Vous devez amener les gens à l'utiliser réellement
2023." est considérée par certains acteurs de l'industrie comme une année décisive pour la synthèse vidéo. Il n'existait pas de modèle public de conversion texte-vidéo en janvier et, à la fin de l'année, il existait des dizaines de produits similaires et des millions d'utilisateurs.
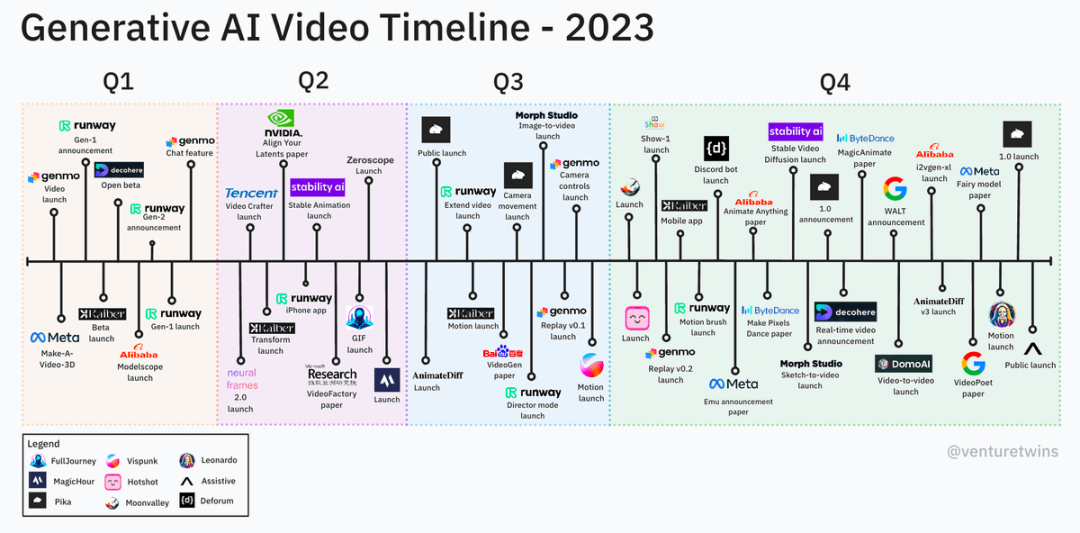
Justine Moore, partenaire de a16z, a partagé la chronologie du modèle vidéo de Vincent sur les plateformes sociales. De là, nous pouvons voir qu'en plus des grands fabricants, il existe de nombreuses startups. De plus, la vitesse d'itération technologique est très. rapide.
Les vidéos actuelles générées par l'IA n'ont pas formé un paradigme technique unifié et clair similaire à celui du LLM. L'industrie en est encore au stade exploratoire sur la manière de générer des vidéos stables. Mais les chercheurs pensent que ces failles peuvent être éliminées à mesure que leur système est entraîné avec de plus en plus de données. À terme, cette technologie rendra la création de vidéos aussi simple que l’écriture de phrases.
Un investisseur national senior de l'industrie de l'IA nous a déclaré que plusieurs des articles les plus importants sur Vincent Video Technology ont été publiés en juillet-août 2022. Par analogie avec le processus d'industrialisation de Vincent Video, cette technologie est proche de l'industrie La transformation Le nœud apparaîtra un an plus tard, soit juillet-août 2023.
L'ensemble de la technologie vidéo se développe très rapidement et la technologie devient de plus en plus mature. Cet investisseur a déclaré que, sur la base de son expérience d'investissement antérieure dans le domaine du GAN, il prédit que la technologie texte-vidéo sera un produit. dans les six prochains mois à un an.
L'équipe Morph rassemble les meilleurs jeunes chercheurs dans le domaine de la génération vidéo. Après une recherche et un développement intensifs jour et nuit au cours de l'année écoulée, le fondateur Xu Huaizhe, ainsi que les co-fondateurs Li Feng, Yin Zixin et Zhao Shihao. , Liu Shaoteng et d'autres piliers techniques de base ont surmonté le casse-tête de la génération vidéo IA.
En plus de l'équipe technique, Morph Studio a également récemment renforcé son équipe produit Hexin, un producteur sous contrat de Maoyan Films, juge du Festival international du film de Shanghai et membre principal de l'ancienne société AIGC dans Silicon. Valley, a également récemment rejoint Morph Studio.
Haising a déclaré que Morph Studio occupe une position de leader dans l'ensemble de l'industrie en termes de recherche technique ; l'équipe est plate, l'efficacité de la communication et l'exécution sont particulièrement élevées ; chaque membre est passionné par l'industrie. Son plus grand rêve était de rejoindre une société d'animation. Après l'avènement de l'ère de l'IA, elle s'est rapidement rendu compte que l'industrie de l'animation allait changer à l'avenir. Au cours des dernières décennies, la base de l'animation était constituée de moteurs 3D et une nouvelle ère de moteurs d'IA allait bientôt inaugurer. Le Pixar du futur naîtra dans une entreprise d’IA. Et Morph était son choix.
Le fondateur Xu Huaizhe a déclaré que Morph prépare activement la piste vidéo IA. Nous sommes déterminés à être une super application à l'ère de la vidéo IA et à réaliser les rêves des utilisateurs.
La piste aura son propre moment Midjourney en 2024, a-t-il ajouté.
PS : Pour découvrir le plaisir original de la génération vidéo 1080P gratuite, veuillez vous rendre sur :
https://discord.com/invite/VVqS8QnBkA
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Comment publier des vidéos sur Weibo sans compresser la qualité de l'image_Comment publier des vidéos sur Weibo sans compresser la qualité de l'image
Mar 30, 2024 pm 12:26 PM
Comment publier des vidéos sur Weibo sans compresser la qualité de l'image_Comment publier des vidéos sur Weibo sans compresser la qualité de l'image
Mar 30, 2024 pm 12:26 PM
1. Ouvrez d'abord Weibo sur votre téléphone mobile et cliquez sur [Moi] dans le coin inférieur droit (comme indiqué sur l'image). 2. Cliquez ensuite sur [Gear] dans le coin supérieur droit pour ouvrir les paramètres (comme indiqué sur l'image). 3. Ensuite, recherchez et ouvrez [Paramètres généraux] (comme indiqué sur l'image). 4. Entrez ensuite l'option [Video Follow] (comme indiqué sur l'image). 5. Ensuite, ouvrez le paramètre [Résolution de téléchargement vidéo] (comme indiqué sur l'image). 6. Enfin, sélectionnez [Qualité d'image originale] pour éviter la compression (comme indiqué sur l'image).
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
