
 Périphériques technologiques
IA
Les recherches de Google DeepMind ont révélé que les attaques contradictoires peuvent affecter la reconnaissance visuelle des humains et de l'IA, en confondant un vase avec un chat !
Périphériques technologiques
IA
Les recherches de Google DeepMind ont révélé que les attaques contradictoires peuvent affecter la reconnaissance visuelle des humains et de l'IA, en confondant un vase avec un chat !
Les recherches de Google DeepMind ont révélé que les attaques contradictoires peuvent affecter la reconnaissance visuelle des humains et de l'IA, en confondant un vase avec un chat !

Quelle est la relation entre le réseau neuronal humain (cerveau) et le réseau neuronal artificiel (ANN) ?
Un enseignant l'a un jour comparé ainsi : c'est comme la relation entre une souris et Mickey Mouse.
Les réseaux neuronaux réels sont puissants, mais complètement différents de la façon dont les humains perçoivent, apprennent et comprennent.
Par exemple, les ANN présentent des vulnérabilités qui ne sont généralement pas visibles dans la perception humaine, et elles sont sensibles aux perturbations adverses.
Une image peut n'avoir besoin que de modifier les valeursde quelques pixels, ou d'ajouter des données de bruit.
D'un point de vue humain, aucune différence ne peut être observée, mais pour les réseaux de classification d'images, c'est le cas. sera reconnue comme une catégorie totalement hors de propos.
Cependant, les dernières recherches de Google DeepMind montrent que notre point de vue précédent est peut-être erroné !
Même des changements subtils dans les images numériques peuvent affecter la perception humaine.
En d’autres termes, le jugement humain peut également être affecté par cette perturbation contradictoire.

Adresse papier : https://www.nature.com/articles/s41467-023-40499-0
Cet article de Google DeepMind a été publié dans Nature Communications.
L'article explore si les humains pourraient également présenter une sensibilité aux mêmes perturbations dans des conditions de test contrôlées.
Grâce à une série d'expériences, les chercheurs l'ont prouvé.
En même temps, cela montre également les similitudes entre la vision humaine et la vision industrielle.
Images contradictoires
Les images contradictoires sont des changements subtils apportés à une image qui amènent le modèle d'IA à mal classer le contenu de l'image - cette tromperie intentionnelle est appelée une frappe contradictoire.
Par exemple, une attaque pourrait être ciblée pour amener un modèle d'IA à classer un vase comme un chat ou comme autre chose qu'un vase.

L'image ci-dessus montre le processus d'attaque contradictoire (pour la commodité de l'observation humaine, les perturbations aléatoires au milieu sont exagérées).
Dans les images numériques, chaque pixel de l'image RVB a une valeur comprise entre 0 et 255 (à une profondeur de 8 bits), et la valeur représente l'intensité d'un seul pixel.
Pour les attaques contradictoires, l'effet d'attaque peut être obtenu en modifiant la valeur du pixel dans une petite plage.
Dans le monde réel, des attaques contradictoires contre des objets physiques peuvent également réussir, par exemple en faisant reconnaître par erreur des panneaux d'arrêt comme des panneaux de limitation de vitesse.
Ainsi, pour des raisons de sécurité, les chercheurs travaillent déjà sur les moyens de se défendre contre les attaques adverses et de réduire leurs risques.
Effets contradictoires sur la perception humaine
Des recherches antérieures ont montré que les gens peuvent être sensibles aux grandes perturbations de l'image qui fournissent des indices de forme clairs.
Cependant, quel impact des attaques adverses plus nuancées ont-elles sur les humains ? Les gens perçoivent-ils les perturbations dans les images comme un bruit d’image aléatoire inoffensif, et cela affecte-t-il la perception humaine ?
Pour le savoir, les chercheurs ont mené des expériences comportementales contrôlées.
Tout d'abord, une série d'images brutes est prise et deux attaques contradictoires sont effectuées sur chaque image pour produire plusieurs paires d'images perturbées.
Dans l'exemple animé ci-dessous, l'image originale est classée par le modèle comme un "vase".
En raison de l'attaque contradictoire, le modèle a mal classé les deux images perturbées comme "chat" et "camion" avec une grande confiance.

Ensuite, les participants humains ont vu ces deux images et ont posé une question ciblée : quelle image ressemble le plus à un chat ?
Même si aucune des deux photos ne ressemblait à un chat, ils ont dû faire un choix.
Habituellement, les sujets pensent avoir fait un choix aléatoire, mais est-ce vraiment le cas ?
Si le cerveau est insensible aux attaques adverses subtiles, les sujets choisiront chaque image 50% du temps.
Cependant, des expériences ont montré que le taux de sélection (c'est-à-dire le biais de perception humaine) est en réalité supérieur au hasard (50 %), et en fait l'ajustement des pixels de l'image est très faible.
Du point de vue du participant, on a l'impression qu'on lui demande de faire la différence entre deux images presque identiques. Cependant, des recherches antérieures ont montré que les gens utilisent des signaux perceptuels faibles lorsqu'ils font des choix, même si ces signaux sont trop faibles pour transmettre confiance ou conscience.
Dans cet exemple, nous pourrions voir un vase, mais une activité cérébrale nous indique qu'il a l'ombre d'un chat.
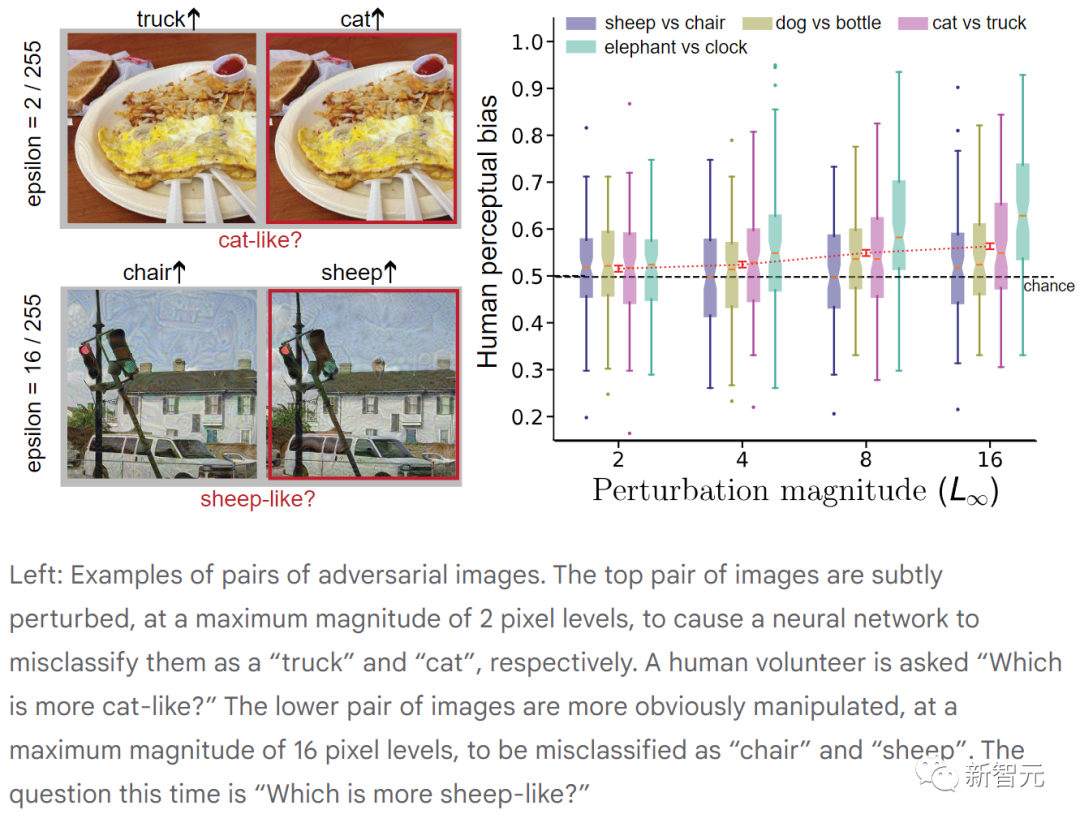
L'image ci-dessus montre des paires d'images contradictoires. La paire d'images du haut est subtilement perturbée, avec une amplitude maximale de 2 pixels, ce qui amène le réseau neuronal à les classer à tort respectivement comme « camion » et « chat ». (Il a été demandé aux volontaires "Lequel ressemble le plus à un chat ?")
Les deux images ci-dessous présentent des perturbations plus évidentes, avec une amplitude maximale de 16 pixels, et ont été incorrectement classées comme "chaise" et "mouton" par le réseau neuronal. (Cette fois, la question était « Lequel ressemble le plus à un mouton ? »)
Dans chaque expérience, les participants ont sélectionné de manière fiable l'image contradictoire correspondant à la question cible plus de la moitié du temps. Bien que la vision humaine ne soit pas aussi sensible aux perturbations adverses que la vision industrielle, ces perturbations peuvent néanmoins biaiser les humains en faveur des décisions prises par les machines.
Si la perception humaine peut être affectée par des images contradictoires, il s'agira alors d'un problème de sécurité nouveau mais critique.
Cela nous oblige à mener des recherches approfondies pour explorer les similitudes et les différences entre le comportement des systèmes visuels d'intelligence artificielle et la perception humaine, et à construire des systèmes d'intelligence artificielle plus sûrs.
Paper Details
La procédure standard pour générer des perturbations contradictoires commence par un classificateur ANN pré-entraîné qui mappe les images RVB à une distribution de probabilité sur un ensemble fixe de classes.
Toute modification de l'image (comme l'augmentation de l'intensité rouge d'un pixel spécifique) produira un léger changement dans la distribution de probabilité de sortie.
Les images contradictoires sont recherchées (descente de gradient) pour obtenir une perturbation de l'image originale qui amène l'ANN à réduire la probabilité d'être affecté à la bonne classe (attaque non ciblée) ou à attribuer une forte probabilité à certains spécifiés. classe alternative (attaques ciblées).
Pour garantir que les perturbations ne s'écartent pas trop de l'image d'origine, la contrainte de norme L (∞) est souvent appliquée dans la littérature sur l'apprentissage automatique contradictoire, spécifiant qu'aucun pixel ne peut s'écarter de sa valeur d'origine de plus de ±ε , ε étant généralement beaucoup plus petit que [ 0–255] Plage d'intensité des pixels.
Cette contrainte s'applique aux pixels de chaque plan de couleur RVB. Bien que cette limitation n'empêche pas les individus de détecter les changements dans l'image, en choisissant ε de manière appropriée, le signal principal indiquant la catégorie d'image d'origine reste pratiquement intact dans l'image perturbée.
Expériences
Dans des expériences initiales, les auteurs ont étudié les réponses de classification humaine à de brèves images contradictoires masquées.
En limitant le temps d'exposition pour augmenter les erreurs de classification, l'expérience a été conçue pour augmenter la sensibilité d'un individu aux aspects d'un stimulus qui autrement ne pourraient pas influencer les décisions de classification.
Une perturbation contradictoire est effectuée sur l'image de la classe réelle T. En optimisant la perturbation, l'ANN a tendance à mal classer l'image en A. Il a été demandé aux participants de faire un choix forcé entre T et A.
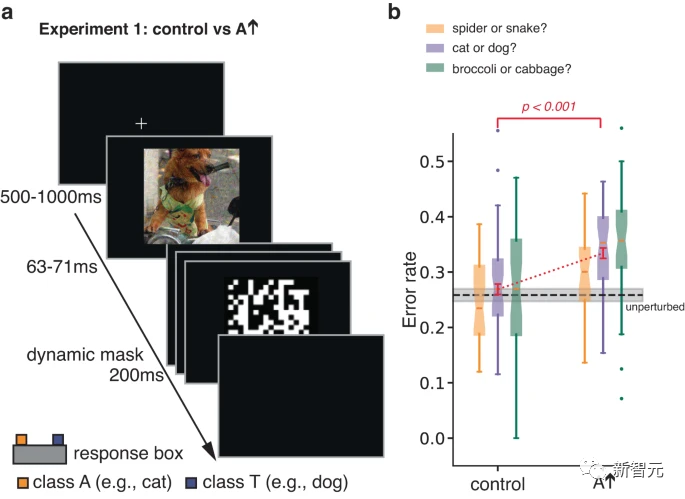
Les chercheurs ont également testé les participants sur des images de contrôle, formées en retournant de haut en bas des images perturbées de manière contradictoire obtenues dans la condition A.
Cette simple transformation rompt la correspondance pixel à pixel entre les perturbations contradictoires et les images, éliminant largement l'impact des perturbations contradictoires sur l'ANN, tout en préservant les spécifications de la perturbation et d'autres statistiques.
Les résultats ont montré que les participants étaient plus susceptibles de juger l'image perturbée comme étant de catégorie A par rapport à l'image témoin.
L'expérience 1 ci-dessus a utilisé une brève démonstration de masquage pour limiter l'influence de la catégorie d'image d'origine (signal primaire) sur la réponse, révélant ainsi la sensibilité aux perturbations adverses (signal subordonné).
Les chercheurs ont également conçu trois expériences supplémentaires ayant les mêmes objectifs, mais en évitant le besoin de perturbations à grande échelle et de visualisations à exposition limitée.
Dans ces expériences, le signal dominant dans l'image ne guide pas systématiquement la sélection de la réponse, laissant émerger l'influence du signal subordonné.
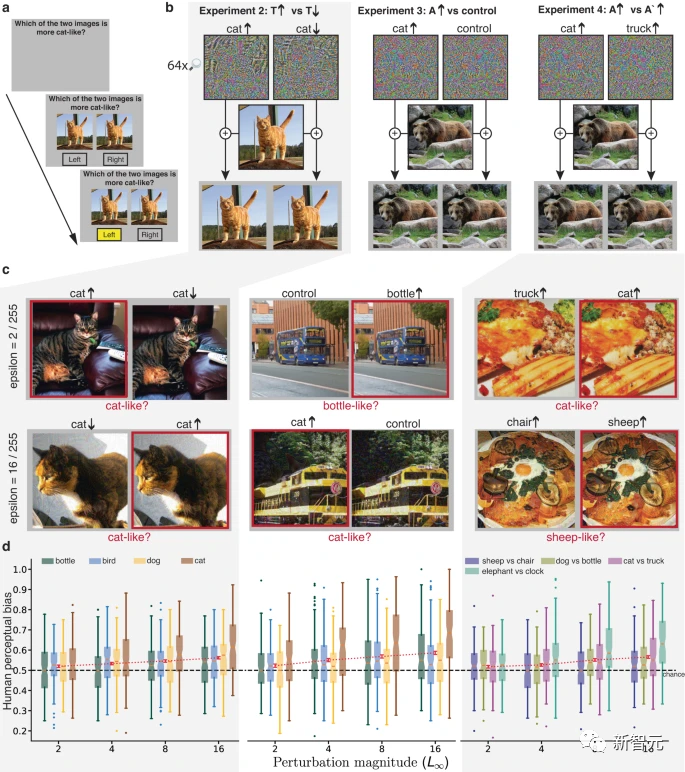
Dans chaque expérience, une paire presque identique de stimuli non masqués est présentée et reste visible jusqu'à ce qu'une réponse soit sélectionnée. La paire de stimuli a le même signal dominant, ils sont tous deux des modulations de la même image sous-jacente, mais ont des signaux esclaves différents. Les participants ont été invités à sélectionner des images qui ressemblaient davantage à des instances de la catégorie cible.
Dans l'expérience 2, les deux stimuli étaient des images appartenant à la catégorie T. L'un d'eux était perturbé et l'ANN prédisait qu'il ressemblerait davantage à la catégorie T, et l'autre était perturbé et prédit qu'il ressemblerait moins à la catégorie T. .
Dans l'expérience 3, le stimulus est une image appartenant à la catégorie réelle T, dont l'une est perturbée pour changer la classification de l'ANN pour la rapprocher de la catégorie adverse cible A, et l'autre utilise la même perturbation, Mais inversé à gauche et à droite comme condition de contrôle.
L'effet de ce contrôle est de préserver la norme et d'autres statistiques de la perturbation, mais d'être plus conservateur que le contrôle de l'expérience 1, car les côtés gauche et droit de l'image peuvent avoir des statistiques plus similaires que le côté supérieur. et les parties inférieures de l'image.
La paire d'images de l'expérience 4 sont également des modulations de la vraie catégorie T, l'une est perturbée pour ressembler davantage à la catégorie A, et l'autre ressemble davantage à la catégorie 3. Les essais alternaient entre demander aux participants de choisir une image qui ressemblait davantage à la catégorie A ou une image qui ressemblait davantage à la catégorie 3.
Dans les expériences 2 à 4, le biais de perception humaine de chaque image était significativement corrélé positivement avec le biais de l'ANN. Les amplitudes de perturbation variaient de 2 à 16, ce qui est plus petit que les perturbations précédemment étudiées sur des participants humains et similaire à celles utilisées dans les études d'apprentissage automatique contradictoires.
Étonnamment, des perturbations de même 2 niveaux d'intensité de pixels suffisent pour affecter de manière fiable la perception humaine.
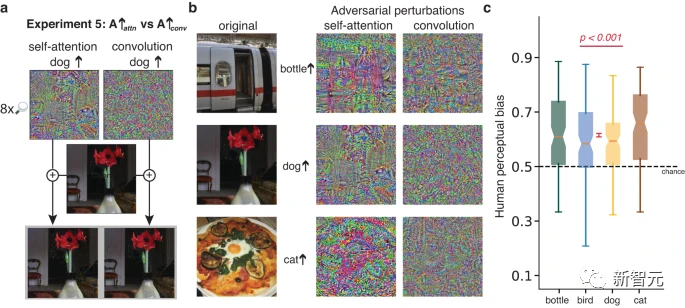
L'avantage de l'expérience 2 est qu'elle oblige les participants à faire des jugements intuitifs (par exemple, laquelle de deux images de chat perturbés ressemble le plus à un chat
Cependant, l'expérience 2 autorise uniquement des perturbations contradictoires) ; En accentuant ou en rendant une image floue, vous pouvez la rendre plus ou moins semblable à un chat.
L'avantage de l'expérience 3 est que toutes les statistiques des perturbations comparées correspondent, pas seulement l'amplitude maximale des perturbations.
Cependant, la correspondance des statistiques de perturbation ne garantit pas que la perturbation est également perceptible lorsqu'elle est ajoutée à l'image, et par conséquent, les participants peuvent faire des choix basés sur la distorsion de l'image.
La force de l'expérience 4 est de démontrer que les participants sont sensibles aux questions qui leur sont posées, car les mêmes paires d'images produisent systématiquement des réponses différentes selon la question posée.
Cependant, l'expérience 4 a demandé aux participants de répondre à une question apparemment absurde (par exemple, laquelle de deux images d'omelette ressemble le plus à un chat ?), ce qui entraîne une variabilité dans la façon dont la question a été interprétée.
En résumé, les expériences 2 à 4 fournissent des preuves convergentes que même si l'amplitude de perturbation est très faible et que le temps de visualisation n'est pas limité, les signaux antagonistes esclaves qui ont un fort impact sur le réseau d'IA affecteront la perception humaine et jugement dans le même sens.
De plus, prolonger le temps d'observation (environnement naturellement perçu) est essentiel pour que les perturbations adverses aient des conséquences réelles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Gérer les journaux Hadoop sur Debian, vous pouvez suivre les étapes et les meilleures pratiques suivantes: l'agrégation de journal Activer l'agrégation de journaux: définir yarn.log-aggregation-inable à true dans le fichier yarn-site.xml pour activer l'agrégation de journaux. Configurer la stratégie de rétention du journal: Définissez Yarn.log-agregation.retain-secondes pour définir le temps de rétention du journal, tel que 172800 secondes (2 jours). Spécifiez le chemin de stockage des journaux: via yarn.n
