
 Périphériques technologiques
IA
Le premier système universel de modélisation graphique et textuelle 3D pour meubles et appareils électroménagers qui ne nécessite aucun guidage et peut être utilisé dans des modèles de visualisation généralisés.
Périphériques technologiques
IA
Le premier système universel de modélisation graphique et textuelle 3D pour meubles et appareils électroménagers qui ne nécessite aucun guidage et peut être utilisé dans des modèles de visualisation généralisés.
Le premier système universel de modélisation graphique et textuelle 3D pour meubles et appareils électroménagers qui ne nécessite aucun guidage et peut être utilisé dans des modèles de visualisation généralisés.

De nos jours, toutes les tâches ménagères sont prises en charge par des robots.
Le robot de Stanford capable d'utiliser des casseroles vient d'apparaître, et le robot capable d'utiliser des machines à café vient d'arriver, Figure-01.

Figure-01 Il suffit de regarder la vidéo de démonstration et de suivre 10 heures de formation pour pouvoir utiliser la machine à café avec compétence. De l’insertion de la capsule de café à l’appui sur le bouton de démarrage, tout se fait en une seule fois.
Cependant, il est difficile de permettre à un robot d'apprendre de manière autonome à utiliser divers meubles et appareils électroménagers sans avoir besoin de vidéos de démonstration lorsqu'il les rencontre. Cela nécessite que le robot ait de fortes capacités de perception visuelle et de prise de décision, ainsi que des compétences de manipulation précises.

Lien papier : https://arxiv.org/abs/2312.01307
Page d'accueil du projet : https://geometry.stanford.edu/projects/sage/
Code : https://github.com/ geng-haoran/SAGE
Aperçu du problème de recherche

Figure 1 : Selon les instructions humaines, le bras robotique peut utiliser divers appareils électroménagers sans aucune instruction.
Récemment, PaLM-E et GPT-4V ont favorisé l'application de grands modèles graphiques dans la planification des tâches des robots, et le contrôle généralisé des robots guidé par le langage visuel est devenu un domaine de recherche populaire.
Une méthode courante dans le passé consistait à construire un système à deux couches. Le grand modèle graphique de la couche supérieure effectue la planification et la planification des compétences, et le modèle de stratégie de compétences de contrôle de la couche inférieure est responsable de l'exécution physique des actions. Mais lorsque les robots seront confrontés à une variété d'appareils électroménagers qu'ils n'ont jamais vus auparavant et nécessiteront des opérations en plusieurs étapes dans les tâches ménagères, les couches supérieures et inférieures des méthodes existantes seront impuissantes.
Prenons comme exemple le modèle graphique le plus avancé GPT-4V. Bien qu'il puisse décrire une seule image avec du texte, il est encore plein d'erreurs en matière de détection, de comptage, de positionnement et d'estimation de l'état des pièces utilisables. Les surlignages rouges sur la figure 2 correspondent aux diverses erreurs commises par GPT-4V lors de la description d'images de commodes, de fours et d'armoires sur pied. Sur la base d'une description erronée, la planification des compétences du robot n'est évidemment pas fiable.

Figure 2 : GPT-4V ne peut pas gérer des tâches axées sur le contrôle généralisé telles que le comptage, la détection, le positionnement et l'estimation d'état.
Le modèle de stratégie de compétences de contrôle de niveau inférieur est responsable de l'exécution des tâches confiées par le modèle graphique et textuel de niveau supérieur dans diverses situations réelles. La plupart des résultats de recherche existants codent de manière rigide les points de préhension et les méthodes de fonctionnement de certains objets connus sur la base de règles, et ne peuvent généralement pas traiter de nouvelles catégories d'objets qui n'ont jamais été vues auparavant. Cependant, les modèles de fonctionnement de bout en bout (tels que RT-1, RT-2, etc.) utilisent uniquement la modalité RVB, manquent de perception précise de la distance et ont une mauvaise généralisation aux changements dans de nouveaux environnements tels que la hauteur.
Inspirée par le précédent travail CVPR Highlight de l’équipe du professeur Wang He, GAPartNet [1], l’équipe de recherche s’est concentrée sur les pièces communes (GAParts) dans diverses catégories d’appareils électroménagers. Bien que les appareils électroménagers soient en constante évolution, il existe toujours quelques pièces indispensables. Il existe des géométries et des modèles d'interaction similaires entre chaque appareil électroménager et ces pièces communes.
En conséquence, l'équipe de recherche a introduit le concept de GAPart dans l'article GAPartNet [1]. GAPart fait référence à un composant généralisable et interactif. GAPart apparaît sur différentes catégories d'objets battants. Par exemple, les portes battantes peuvent être trouvées dans les coffres-forts, les armoires et les réfrigérateurs. Comme le montre la figure 3, GAPartNet [1] annote la sémantique et la pose de GAPart sur différents types d'objets.

Figure 3 : GAPart : parties généralisables et interactives [1].
Sur la base de recherches antérieures, l'équipe de recherche a introduit de manière créative GAPart basé sur la vision tridimensionnelle dans le système de manipulation d'objets du robot SAGE. SAGE fournira des informations pour VLM et LLM grâce à une détection de pièces 3D généralisable et une estimation précise de la pose. Au niveau de la prise de décision, la nouvelle méthode résout le problème des capacités de calcul et de raisonnement précises insuffisantes du modèle graphique bidimensionnel ; au niveau de l'exécution, la nouvelle méthode réalise des opérations généralisées sur chaque pièce grâce à une API d'opération physique robuste basée sur GAPart pose.
SAGE constitue le premier système de modèles graphiques et textuels incarnés en trois dimensions à grande échelle, fournissant de nouvelles idées pour l'ensemble du lien entre les robots, de la perception à l'interaction physique jusqu'au feedback, et explorant de nouvelles façons pour les robots de contrôler intelligemment et universellement des objets complexes tels que comme les meubles et les appareils électroménagers.
Introduction au système
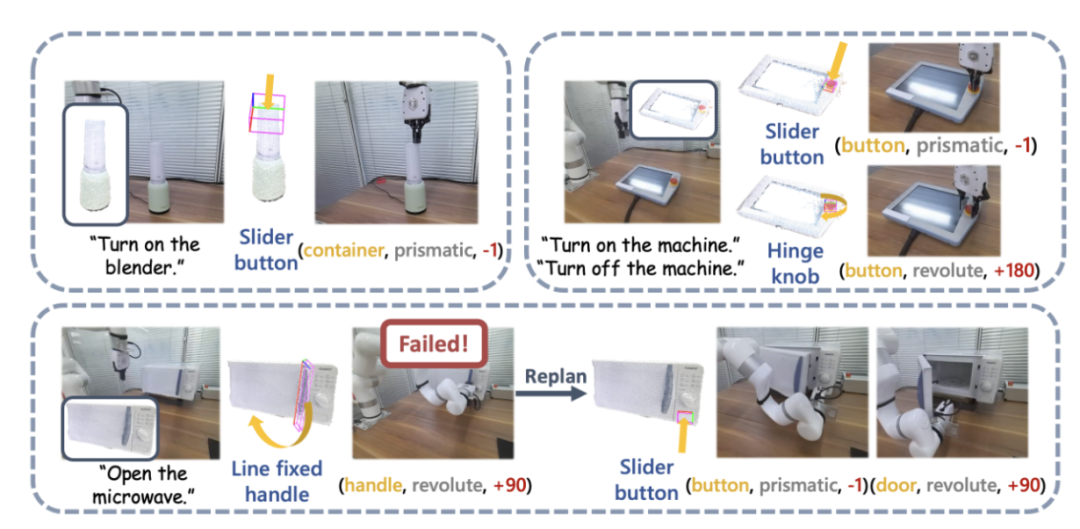
La figure 4 montre le processus de base de SAGE. Premièrement, un module d'interprétation des instructions capable d'interpréter le contexte analysera les instructions entrées dans le robot et ses observations, et convertira ces analyses en le prochain programme d'action du robot et ses parties sémantiques associées. Ensuite, SAGE mappe la partie sémantique (telle que le conteneur) à la partie qui doit être actionnée (telle que le bouton coulissant) et génère des actions (telles que l'action « appuyer » sur le bouton) pour terminer la tâche.

Figure 4 : Aperçu des méthodes.
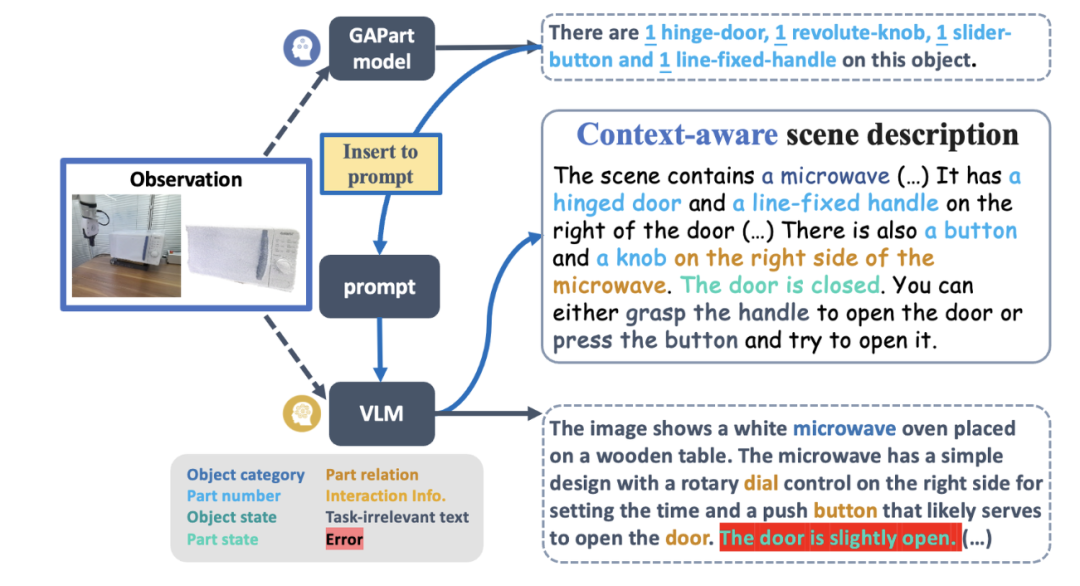
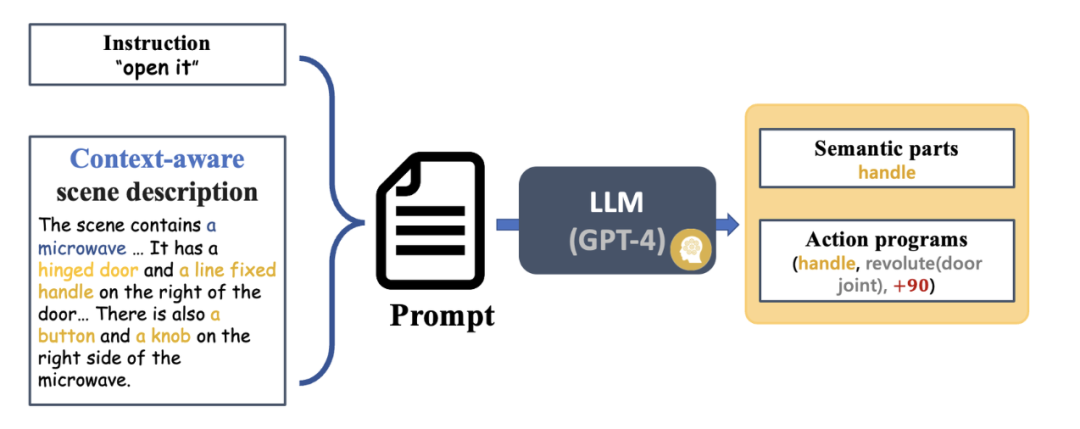
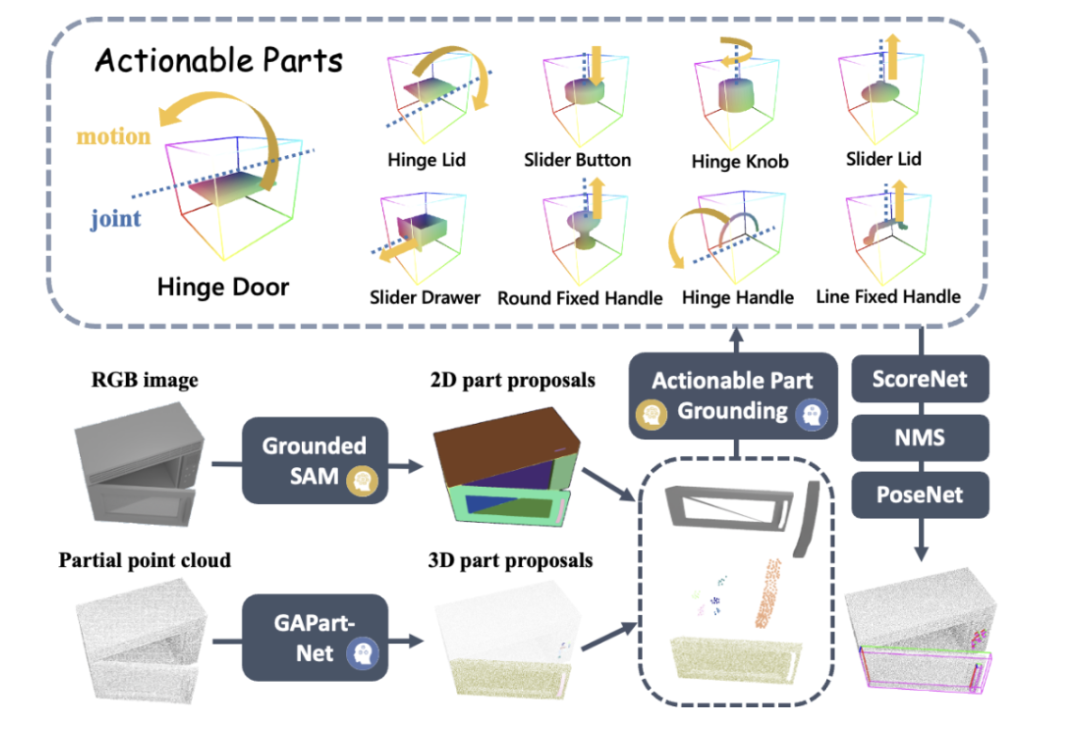



Figure 11 : Expérience de simulation SAPIEN.
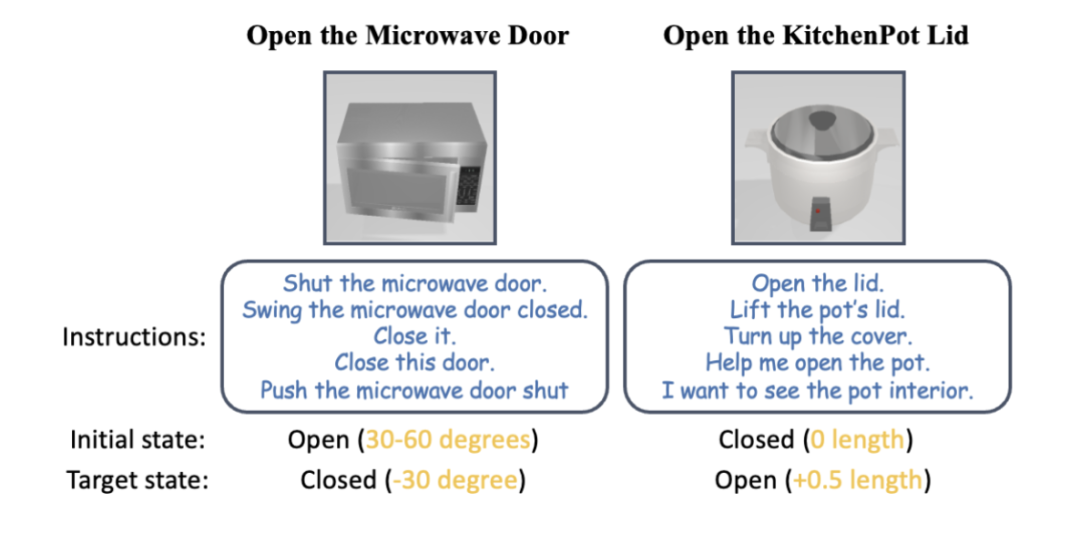
Ils ont utilisé l'environnement SAPIEN [4] pour mener des expériences de simulation et ont conçu 12 tâches de manipulation d'objets articulés guidées par le langage. Pour chaque catégorie de fours à micro-ondes, de meubles de rangement et d'armoires, 3 tâches ont été conçues, comprenant des états ouvert et fermé dans différents états initiaux. Les autres tâches sont « Ouvrir le couvercle du pot », « Appuyer sur le bouton de la télécommande » et « Démarrer le mixeur ». Les résultats expérimentaux montrent que SAGE fonctionne bien dans presque toutes les tâches.
Résumé
SAGE est le premier cadre de modèle de langage visuel 3D capable de générer des instructions générales de manipulation pour des objets articulés complexes tels que des meubles et des appareils électroménagers. Il convertit les actions ordonnées par le langage en manipulations exécutables en reliant la sémantique des objets et la compréhension de l'opérabilité au niveau des pièces.
Présentation de l'équipe
SAGE Ce résultat de recherche provient du laboratoire du professeur Leonidas Guibas de l'Université de Stanford, de l'Emboded Perception and Interaction (EPIC Lab) du professeur Wang He de l'Université de Pékin et de l'Institut de recherche sur l'intelligence artificielle Zhiyuan. Les auteurs de l'article sont Geng Haoran (co-auteur), étudiant à l'Université de Pékin et chercheur invité à l'Université de Stanford, Wei Songlin, doctorant à l'Université de Pékin (co-auteur), Deng Congyue et Shen Bokui, doctorants à l'Université de Stanford, et les superviseurs sont le professeur Leonidas. Guibas et le professeur Wang He.Références :
[2] Kirillov, Alexander, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao et al. "Segmentez n'importe quoi."
[3] Zhang, Hao, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni et Heung-Yeung Shum. « Dino : Detr avec des boîtes d'ancrage de débruitage améliorées pour une utilisation de bout en bout. détection d'objet final." Préimpression arXiv arXiv : 2203.03605 (2022). environnement interactif." Dans Actes de la conférence IEEE/CVF sur la vision par ordinateur et la reconnaissance de formes, pp.11097-11107.2020.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
Il s'agit également d'une vidéo Tusheng, mais PaintsUndo a emprunté une voie différente. L'auteur de ControlNet, LvminZhang, a recommencé à vivre ! Cette fois, je vise le domaine de la peinture. Le nouveau projet PaintsUndo a reçu 1,4kstar (toujours en hausse folle) peu de temps après son lancement. Adresse du projet : https://github.com/lllyasviel/Paints-UNDO Grâce à ce projet, l'utilisateur saisit une image statique et PaintsUndo peut automatiquement vous aider à générer une vidéo de l'ensemble du processus de peinture, du brouillon de ligne au suivi du produit fini. . Pendant le processus de dessin, les changements de lignes sont étonnants. Le résultat vidéo final est très similaire à l’image originale : jetons un coup d’œil à un dessin complet.
 Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Dans le processus de développement de l'intelligence artificielle, le contrôle et le guidage des grands modèles de langage (LLM) ont toujours été l'un des principaux défis, visant à garantir que ces modèles sont à la fois puissant et sûr au service de la société humaine. Les premiers efforts se sont concentrés sur les méthodes d’apprentissage par renforcement par feedback humain (RL
 En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Les auteurs de cet article font tous partie de l'équipe de l'enseignant Zhang Lingming de l'Université de l'Illinois à Urbana-Champaign (UIUC), notamment : Steven Code repair ; doctorant en quatrième année, chercheur
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
Montrez la chaîne causale à LLM et il pourra apprendre les axiomes. L'IA aide déjà les mathématiciens et les scientifiques à mener des recherches. Par exemple, le célèbre mathématicien Terence Tao a partagé à plusieurs reprises son expérience de recherche et d'exploration à l'aide d'outils d'IA tels que GPT. Pour que l’IA soit compétitive dans ces domaines, des capacités de raisonnement causal solides et fiables sont essentielles. La recherche présentée dans cet article a révélé qu'un modèle Transformer formé sur la démonstration de l'axiome de transitivité causale sur de petits graphes peut se généraliser à l'axiome de transitivité sur de grands graphes. En d’autres termes, si le Transformateur apprend à effectuer un raisonnement causal simple, il peut être utilisé pour un raisonnement causal plus complexe. Le cadre de formation axiomatique proposé par l'équipe est un nouveau paradigme pour l'apprentissage du raisonnement causal basé sur des données passives, avec uniquement des démonstrations.
 Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
acclamations! Qu’est-ce que ça fait lorsqu’une discussion sur papier se résume à des mots ? Récemment, des étudiants de l'Université de Stanford ont créé alphaXiv, un forum de discussion ouvert pour les articles arXiv qui permet de publier des questions et des commentaires directement sur n'importe quel article arXiv. Lien du site Web : https://alphaxiv.org/ En fait, il n'est pas nécessaire de visiter spécifiquement ce site Web. Il suffit de remplacer arXiv dans n'importe quelle URL par alphaXiv pour ouvrir directement l'article correspondant sur le forum alphaXiv : vous pouvez localiser avec précision les paragraphes dans. l'article, Phrase : dans la zone de discussion sur la droite, les utilisateurs peuvent poser des questions à l'auteur sur les idées et les détails de l'article. Par exemple, ils peuvent également commenter le contenu de l'article, tels que : "Donné à".
 Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Récemment, l’hypothèse de Riemann, connue comme l’un des sept problèmes majeurs du millénaire, a réalisé une nouvelle avancée. L'hypothèse de Riemann est un problème mathématique non résolu très important, lié aux propriétés précises de la distribution des nombres premiers (les nombres premiers sont les nombres qui ne sont divisibles que par 1 et par eux-mêmes, et jouent un rôle fondamental dans la théorie des nombres). Dans la littérature mathématique actuelle, il existe plus d'un millier de propositions mathématiques basées sur l'établissement de l'hypothèse de Riemann (ou sa forme généralisée). En d’autres termes, une fois que l’hypothèse de Riemann et sa forme généralisée seront prouvées, ces plus d’un millier de propositions seront établies sous forme de théorèmes, qui auront un impact profond sur le domaine des mathématiques et si l’hypothèse de Riemann s’avère fausse, alors parmi eux ; ces propositions qui en font partie perdront également de leur efficacité. Une nouvelle percée vient du professeur de mathématiques du MIT, Larry Guth, et de l'Université d'Oxford
 Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
Jul 23, 2024 pm 02:05 PM
Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
Jul 23, 2024 pm 02:05 PM
Actuellement, les modèles linguistiques autorégressifs à grande échelle utilisant le prochain paradigme de prédiction de jetons sont devenus populaires partout dans le monde. Dans le même temps, un grand nombre d'images et de vidéos synthétiques sur Internet nous ont déjà montré la puissance des modèles de diffusion. Récemment, une équipe de recherche de MITCSAIL (dont Chen Boyuan, doctorant au MIT) a intégré avec succès les puissantes capacités du modèle de diffusion en séquence complète et du prochain modèle de jeton, et a proposé un paradigme de formation et d'échantillonnage : le forçage de diffusion (DF ). Titre de l'article : DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Adresse de l'article : https://
