
 Périphériques technologiques
IA
PixelLM, un grand modèle multimodal d'octets qui implémente efficacement le raisonnement au niveau des pixels sans dépendance SA
Périphériques technologiques
IA
PixelLM, un grand modèle multimodal d'octets qui implémente efficacement le raisonnement au niveau des pixels sans dépendance SA
PixelLM, un grand modèle multimodal d'octets qui implémente efficacement le raisonnement au niveau des pixels sans dépendance SA

Les grands modèles multimodaux explosent. Êtes-vous prêt à vous lancer dans des applications pratiques dans des tâches précises telles que l'édition d'images, la conduite autonome et la robotique ?
À l'heure actuelle, les capacités de la plupart des modèles sont encore limitées à la génération de descriptions textuelles de l'image globale ou de zones spécifiques, et leurs capacités de compréhension au niveau des pixels (telles que la segmentation d'objets) sont relativement limitées.
En réponse à ce problème, certains travaux ont commencé pour explorer l'utilisation de grands modèles multimodaux pour gérer les instructions de segmentation des utilisateurs (par exemple, "Veuillez segmenter les fruits riches en vitamine C dans l'image").
Cependant, les méthodes disponibles sur le marché souffrent de deux inconvénients principaux :
1) Incapacité à gérer des tâches impliquant plusieurs objets cibles, ce qui est indispensable dans des scénarios réels
2) S'appuyer sur des outils comme SAM Pour un tel pré-apprentissage ; -modèle de segmentation d'image entraîné, la quantité de calcul requise pour une propagation directe de SAM est suffisante pour que Llama-7B génère plus de 500 jetons.
Afin de résoudre ce problème, l'équipe de création intelligente de ByteDance s'est associée à des chercheurs de l'Université Jiaotong de Pékin et de l'Université des sciences et technologies de Pékin pour proposer PixelLM, le premier modèle d'inférence efficace à grande échelle au niveau des pixels qui ne repose pas sur SAM.
Avant de l'introduire en détail, expérimentons les effets réels de segmentation de plusieurs groupes de PixelLM :
Par rapport aux travaux précédents, les avantages de PixelLM sont :
- Il peut gérer habilement n'importe quel nombre de cibles de domaine ouvert et divers raisonnements complexes. Divisez les tâches.
- Éviter les modèles de segmentation supplémentaires et coûteux, améliorer l'efficacité et les capacités de migration vers différentes applications.
De plus, afin de soutenir la formation et l'évaluation des modèles dans ce domaine de recherche, l'équipe de recherche a construit un ensemble de données MUSE pour des scénarios de segmentation de raisonnement multi-objectifs basés sur l'ensemble de données LVIS et GPT-4V. Il contient 200 000 plus de 900 000. paires question-réponse, impliquant plus de 900 000 masques de segmentation d’instance.


Afin d'obtenir les effets ci-dessus, comment cette recherche a-t-elle été menée ?
Le principe derrière
 Images
Images
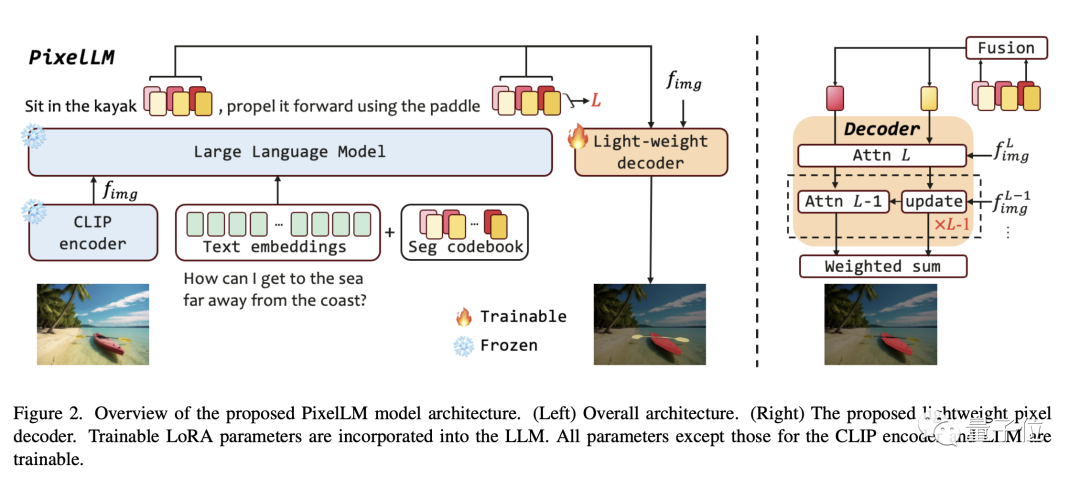
Comme le montre le schéma-cadre de l'article, l'architecture PixelLM est très simple et se compose de quatre parties principales. Les deux dernières sont le cœur de PixelLM :
- Pré-. Encodeur de vision CLIP-ViT formé
- Grand modèle de langage
- Décodeur de pixels léger
- Table de codes de segment Seg Codebook
Le livre de codes Seg contient des jetons apprenables, qui sont utilisés pour encoder des informations cibles à différentes échelles de CLIP-ViT. Ensuite, le décodeur de pixels génère des résultats de segmentation d'objets basés sur ces jetons et les caractéristiques d'image de CLIP-ViT. Grâce à cette conception, PixelLM peut générer des résultats de segmentation de haute qualité sans modèle de segmentation externe, améliorant ainsi considérablement l'efficacité du modèle.
Selon la description du chercheur, les jetons du livre de codes Seg peuvent être divisés en L groupes, chaque groupe contient N jetons et chaque groupe correspond à une échelle de fonctionnalités visuelles CLIP-ViT.
Pour l'image d'entrée, PixelLM extrait les caractéristiques de l'échelle L des caractéristiques de l'image produites par l'encodeur visuel CLIP-ViT. La dernière couche couvre les informations globales de l'image et sera utilisée par LLM pour comprendre le contenu de l'image.
Les jetons du livre de codes Seg seront saisis dans le LLM avec les instructions textuelles et la dernière couche de caractéristiques de l'image pour produire une sortie sous forme d'autorégression. La sortie comprendra également les jetons du livre de codes Seg traités par LLM, qui seront entrés dans le décodeur de pixels avec les fonctionnalités CLIP-ViT à l'échelle L pour produire le résultat final de segmentation.
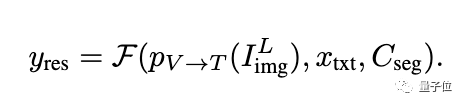 Images
Images
 Images
Images
Alors pourquoi devons-nous définir chaque groupe pour qu'il contienne N jetons ? Les chercheurs ont expliqué en conjonction avec la figure suivante :
Dans les scénarios impliquant plusieurs cibles ou la sémantique contenue dans les cibles est très complexe, bien que LLM puisse fournir une réponse textuelle détaillée, l'utilisation d'un seul jeton peut ne pas capturer complètement toute la sémantique cible. contenu.
Afin d'améliorer la capacité du modèle dans des scénarios de raisonnement complexes, les chercheurs ont introduit plusieurs jetons dans chaque groupe d'échelle et ont effectué une opération de fusion linéaire d'un jeton. Avant que le jeton ne soit transmis au décodeur, une couche de projection linéaire est utilisée pour fusionner les jetons au sein de chaque groupe.
L'image ci-dessous montre l'effet lorsqu'il y a plusieurs jetons dans chaque groupe. La carte d'attention représente à quoi ressemble chaque jeton après avoir été traité par le décodeur. Cette visualisation montre que plusieurs jetons fournissent des informations uniques et complémentaires, ce qui permet d'obtenir une sortie de segmentation plus efficace.
 Photos
Photos
De plus, afin d'améliorer la capacité du modèle à distinguer plusieurs cibles, PixelLM a également conçu une perte de raffinement de cible supplémentaire.
Ensemble de données MUSE
Bien que les solutions ci-dessus aient été proposées, afin d'exploiter pleinement les capacités du modèle, le modèle nécessite toujours des données de formation appropriées. En examinant les ensembles de données publiques actuellement disponibles, nous constatons que les données existantes présentent les limitations majeures suivantes :
1) Description insuffisante des détails de l'objet ;
2) Manque de paires question-réponse avec un raisonnement complexe et des nombres cibles divers ;
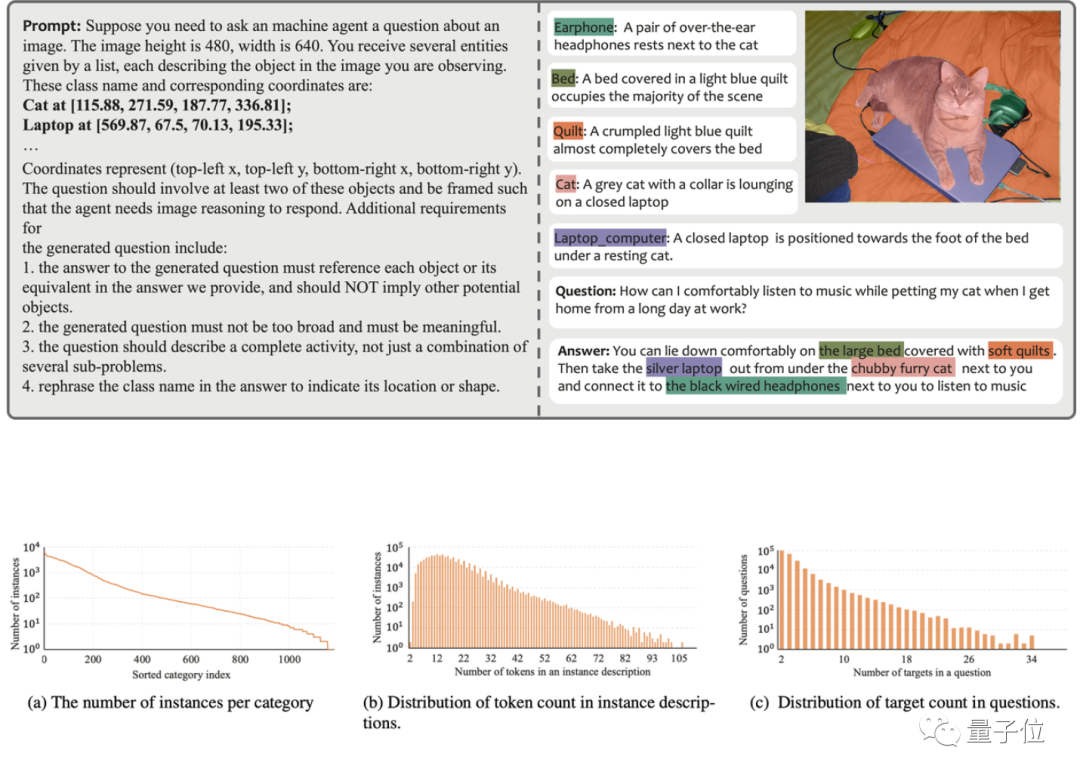
Afin de résoudre ces problèmes, l'équipe de recherche a utilisé GPT-4V pour créer un pipeline d'annotation de données automatisé, et a ainsi généré l'ensemble de données MUSE. La figure ci-dessous montre un exemple des invites utilisées lors de la génération de MUSE et des données générées.
 Images
Images
Dans MUSE, tous les masques d'instance proviennent de l'ensemble de données LVIS, et des descriptions textuelles détaillées générées en fonction du contenu de l'image sont ajoutées. MUSE contient 246 000 paires de questions-réponses, et chaque paire de questions-réponses implique en moyenne 3,7 objets cibles. De plus, l'équipe de recherche a mené une analyse statistique exhaustive de l'ensemble de données :
Statistiques de catégorie : il existe plus de 1 000 catégories dans MUSE à partir de l'ensemble de données LVIS d'origine, et 900 000 instances avec des descriptions uniques basées sur des paires de questions-réponses varient en fonction de l'ensemble de données. contexte. La figure (a) montre le nombre d'instances de chaque catégorie dans toutes les paires question-réponse.
Statistiques du nombre de jetons : La figure (b) montre la répartition du nombre de jetons décrits dans les exemples, dont certains contiennent plus de 100 jetons. Ces descriptions ne se limitent pas à de simples noms de catégories ; elles sont plutôt enrichies d'informations détaillées sur chaque instance, y compris l'apparence, les propriétés et les relations avec d'autres objets, via un processus de génération de données basé sur GPT-4V. La profondeur et la diversité des informations contenues dans l'ensemble de données améliorent la capacité de généralisation du modèle formé, lui permettant de résoudre efficacement les problèmes du domaine ouvert.
Statistiques du nombre de cibles : la figure (c) montre les statistiques du nombre de cibles pour chaque paire question-réponse. Le nombre moyen de cibles est de 3,7 et le nombre maximum de cibles peut atteindre 34. Ce nombre peut couvrir la plupart des scénarios d'inférence cible pour une seule image.
Évaluation de l'algorithme
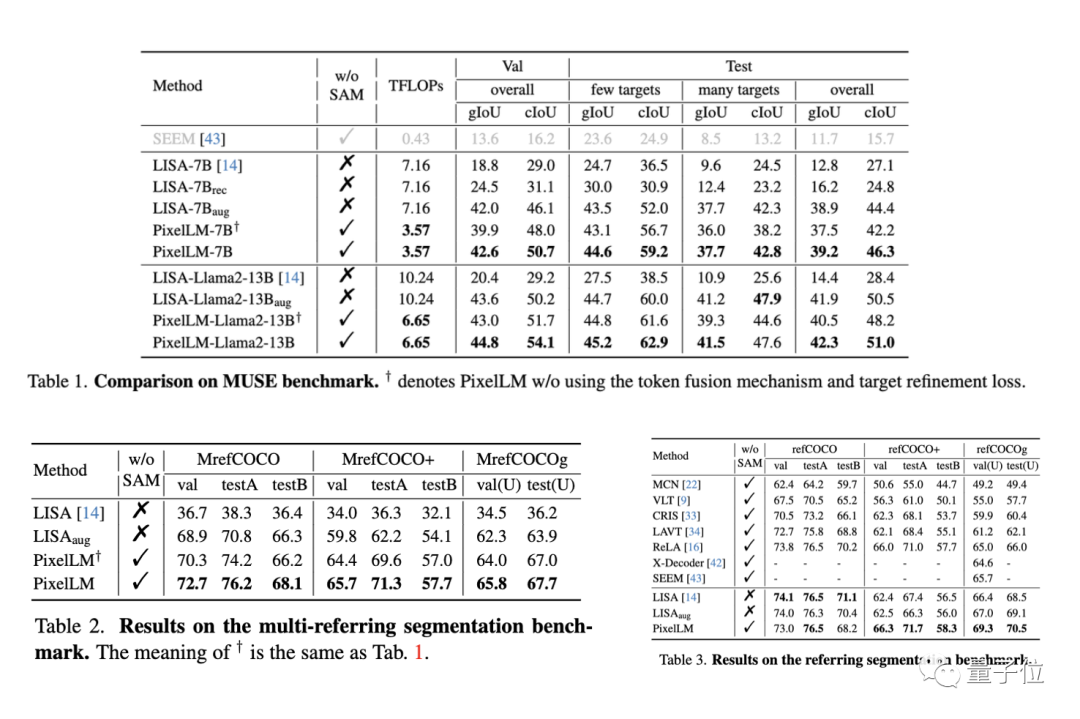
L'équipe de recherche a évalué les performances de PixelLM sur trois benchmarks, dont le benchmark MUSE, le benchmark de segmentation référent et le benchmark de segmentation multi-référence, l'équipe de recherche exige que le modèle soit présent. un problème Segmentez en continu plusieurs objets contenus dans chaque image dans le benchmark de segmentation référent.
Dans le même temps, puisque PixelLM est le premier modèle à gérer des tâches complexes de raisonnement en pixels impliquant plusieurs cibles, l'équipe de recherche a établi quatre lignes de base pour mener une analyse comparative des modèles.
Trois des lignes de base sont basées sur LISA, le travail le plus pertinent sur PixelLM, notamment :
1) LISA originale
2) LISA_rec : entrez d'abord la question dans LLAVA-13B pour obtenir la réponse textuelle de la cible, puis utilisez LISA pour segmenter le texte ;
3) LISA_aug : ajoutez directement MUSE aux données d'entraînement de LISA.
4) L'autre est SEEM, un modèle de segmentation général qui n'utilise pas de LLM.
 Photos
Photos
Sur la plupart des indicateurs des trois benchmarks, les performances de PixelLM sont meilleures que celles des autres méthodes, et comme PixelLM ne s'appuie pas sur SAM, ses TFLOP sont bien inférieurs à ceux des modèles de même taille.
Les amis intéressés peuvent d'abord y prêter attention et attendre que le code soit open source~
Lien de référence :
[1]https://www.php.cn/link/9271858951e6fe9504d1f05ae8576001
[2]https:/ /www.php.cn/link/f1686b4badcf28d33ed632036c7ab0b8
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Afin d'aligner les grands modèles de langage (LLM) sur les valeurs et les intentions humaines, il est essentiel d'apprendre les commentaires humains pour garantir qu'ils sont utiles, honnêtes et inoffensifs. En termes d'alignement du LLM, une méthode efficace est l'apprentissage par renforcement basé sur le retour humain (RLHF). Bien que les résultats de la méthode RLHF soient excellents, certains défis d’optimisation sont impliqués. Cela implique de former un modèle de récompense, puis d'optimiser un modèle politique pour maximiser cette récompense. Récemment, certains chercheurs ont exploré des algorithmes hors ligne plus simples, dont l’optimisation directe des préférences (DPO). DPO apprend le modèle politique directement sur la base des données de préférence en paramétrant la fonction de récompense dans RLHF, éliminant ainsi le besoin d'un modèle de récompense explicite. Cette méthode est simple et stable
 Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
À la pointe de la technologie logicielle, le groupe de l'UIUC Zhang Lingming, en collaboration avec des chercheurs de l'organisation BigCode, a récemment annoncé le modèle de grand code StarCoder2-15B-Instruct. Cette réalisation innovante a permis une percée significative dans les tâches de génération de code, dépassant avec succès CodeLlama-70B-Instruct et atteignant le sommet de la liste des performances de génération de code. Le caractère unique de StarCoder2-15B-Instruct réside dans sa stratégie d'auto-alignement pur. L'ensemble du processus de formation est ouvert, transparent et complètement autonome et contrôlable. Le modèle génère des milliers d'instructions via StarCoder2-15B en réponse au réglage fin du modèle de base StarCoder-15B sans recourir à des annotations manuelles coûteuses.
 Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
1. Introduction Au cours des dernières années, les YOLO sont devenus le paradigme dominant dans le domaine de la détection d'objets en temps réel en raison de leur équilibre efficace entre le coût de calcul et les performances de détection. Les chercheurs ont exploré la conception architecturale de YOLO, les objectifs d'optimisation, les stratégies d'expansion des données, etc., et ont réalisé des progrès significatifs. Dans le même temps, le recours à la suppression non maximale (NMS) pour le post-traitement entrave le déploiement de bout en bout de YOLO et affecte négativement la latence d'inférence. Dans les YOLO, la conception de divers composants manque d’une inspection complète et approfondie, ce qui entraîne une redondance informatique importante et limite les capacités du modèle. Il offre une efficacité sous-optimale et un potentiel d’amélioration des performances relativement important. Dans ce travail, l'objectif est d'améliorer encore les limites d'efficacité des performances de YOLO à la fois en post-traitement et en architecture de modèle. à cette fin
 Li Feifei révèle l'orientation entrepreneuriale de « l'intelligence spatiale » : la visualisation se transforme en aperçu, la vue devient compréhension et la compréhension mène à l'action
Jun 01, 2024 pm 02:55 PM
Li Feifei révèle l'orientation entrepreneuriale de « l'intelligence spatiale » : la visualisation se transforme en aperçu, la vue devient compréhension et la compréhension mène à l'action
Jun 01, 2024 pm 02:55 PM
Stanford Li Feifei a dévoilé pour la première fois le nouveau concept « d'intelligence spatiale » après avoir lancé sa propre entreprise. Ce n'est pas seulement son orientation entrepreneuriale, mais aussi « l'étoile du Nord » qui la guide, elle la considère comme « la pièce clé du puzzle pour résoudre le problème de l'intelligence artificielle ». La visualisation mène à la perspicacité ; la vue mène à la compréhension ; la compréhension mène à l’action. Basé sur la conférence TED de 15 minutes de Li Feifei, il est entièrement révélé, depuis l'origine de l'évolution de la vie il y a des centaines de millions d'années, jusqu'à la façon dont les humains ne sont pas satisfaits de ce que la nature leur a donné et développent l'intelligence artificielle, jusqu'à la façon de construire l'intelligence spatiale dans la prochaine étape. Il y a neuf ans, Li Feifei a présenté au monde le nouveau ImageNet sur la même scène - l'un des points de départ de cette explosion d'apprentissage profond. Elle a elle-même encouragé les internautes : si vous regardez les deux vidéos, vous pourrez comprendre la vision par ordinateur des 10 dernières années.
 Comparaison des performances de différents frameworks Java
Jun 05, 2024 pm 07:14 PM
Comparaison des performances de différents frameworks Java
Jun 05, 2024 pm 07:14 PM
Comparaison des performances de différents frameworks Java : Traitement des requêtes API REST : Vert.x est le meilleur, avec un taux de requêtes de 2 fois SpringBoot et 3 fois Dropwizard. Requête de base de données : HibernateORM de SpringBoot est meilleur que l'ORM de Vert.x et Dropwizard. Opérations de mise en cache : le client Hazelcast de Vert.x est supérieur aux mécanismes de mise en cache de SpringBoot et Dropwizard. Cadre approprié : choisissez en fonction des exigences de l'application. Vert.x convient aux services Web hautes performances, SpringBoot convient aux applications gourmandes en données et Dropwizard convient à l'architecture de microservices.
