
 Périphériques technologiques
IA
Percée de NeRF dans les performances de généralisation BEV : le premier code open source inter-domaines implémente avec succès Sim2Real
Périphériques technologiques
IA
Percée de NeRF dans les performances de généralisation BEV : le premier code open source inter-domaines implémente avec succès Sim2Real
Percée de NeRF dans les performances de généralisation BEV : le premier code open source inter-domaines implémente avec succès Sim2Real

Écrit devant et résumé personnel de l'auteur
La détection à œil d'oiseau (BEV) est une méthode de détection par fusion de plusieurs caméras à vue panoramique. La plupart des algorithmes actuels sont entraînés et évalués sur le même ensemble de données, ce qui entraîne un surajustement de ces algorithmes aux paramètres internes (type de caméra) et externes (emplacement de la caméra) inchangés de la caméra. Cet article propose un cadre de détection BEV basé sur le rendu implicite, qui peut résoudre le problème de la détection d'objets dans des domaines inconnus. Le framework utilise le rendu implicite pour établir la relation entre la position 3D de l'objet et la position en perspective d'une vue unique, qui peut être utilisée pour corriger le biais de perspective. Cette méthode permet d'obtenir des améliorations significatives des performances en matière de généralisation de domaine (DG) et d'adaptation de domaine non supervisée (UDA). Cette méthode est la première tentative visant à utiliser uniquement des ensembles de données virtuelles pour la formation et l'évaluation de la détection BEV dans des scénarios réels, ce qui peut briser les barrières entre virtuel et réel pour réaliser des tests en boucle fermée.
- Lien papier : https://arxiv.org/pdf/2310.11346.pdf
- Lien code : https://github.com/EnVision-Research/Generallessly-BEV

Domaine de détection BEV général Contexte du problème
La détection multi-caméras fait référence à la tâche consistant à utiliser plusieurs caméras pour détecter et localiser des objets dans un espace tridimensionnel. En combinant les informations provenant de différents points de vue, la détection d'objets 3D multi-caméras peut fournir des résultats de détection d'objets plus précis et plus robustes, en particulier dans les situations où les cibles de certains points de vue peuvent être masquées ou partiellement visibles. Ces dernières années, la méthode Bird eye's view (BEV) a reçu une grande attention dans les tâches de détection multi-caméras. Bien que ces méthodes présentent des avantages dans la fusion d’informations multi-caméras, leurs performances peuvent être gravement dégradées lorsque l’environnement de test est significativement différent de l’environnement de formation.
Actuellement, la plupart des algorithmes de détection BEV sont formés et évalués sur le même ensemble de données, ce qui rend ces algorithmes trop sensibles aux changements des paramètres internes et externes des caméras et aux conditions des routes urbaines, entraînant de graves problèmes de surajustement. Cependant, dans les applications pratiques, les algorithmes de détection BEV doivent souvent s’adapter à différents nouveaux modèles et nouvelles caméras, ce qui conduit à l’échec de ces algorithmes. Par conséquent, il est important d’étudier la généralisabilité de la détection du BEV. En outre, la simulation en boucle fermée est également très importante pour la conduite autonome, mais elle ne peut actuellement être évaluée que dans des moteurs virtuels tels que Carla. Par conséquent, il est nécessaire de résoudre le problème des différences de domaine entre les moteurs virtuels et les scènes réelles. La généralisation de domaine (DG) et l'adaptation de domaine non supervisée (UDA) sont deux méthodes prometteuses pour atténuer les changements de direction de la distribution. Les méthodes DG découplent et éliminent souvent les fonctionnalités spécifiques au domaine, améliorant ainsi les performances de généralisation dans des domaines invisibles. Pour l'UDA, les méthodes récentes atténuent le déplacement de domaine en générant des pseudo-étiquettes ou un alignement de distribution de fonctionnalités latentes. Cependant, l'apprentissage de fonctionnalités indépendantes du point de vue et de l'environnement pour une perception visuelle pure est très difficile sans utiliser de données provenant de différents points de vue, paramètres de caméra et environnements.
Les observations montrent que la détection 2D depuis une seule perspective (plan de la caméra) a tendance à avoir des capacités de généralisation plus fortes que la détection d'objets 3D depuis plusieurs perspectives, comme le montre la figure. Certaines études ont exploré l'intégration de la détection 2D dans la détection BEV, par exemple en fusionnant des informations 2D dans des détecteurs 3D ou en établissant une cohérence 2D-3D. La fusion d'informations 2D est une méthode basée sur l'apprentissage plutôt qu'une méthode de modélisation de mécanismes, et elle est encore gravement affectée par la migration de domaine. Les méthodes de cohérence 2D-3D existantes projettent les résultats 3D sur un plan bidimensionnel et établissent la cohérence. Cette contrainte peut nuire aux informations sémantiques du domaine cible au lieu de modifier les informations géométriques du domaine cible. De plus, cette approche de cohérence 2D-3D rend difficile une approche unifiée pour toutes les têtes de détection.
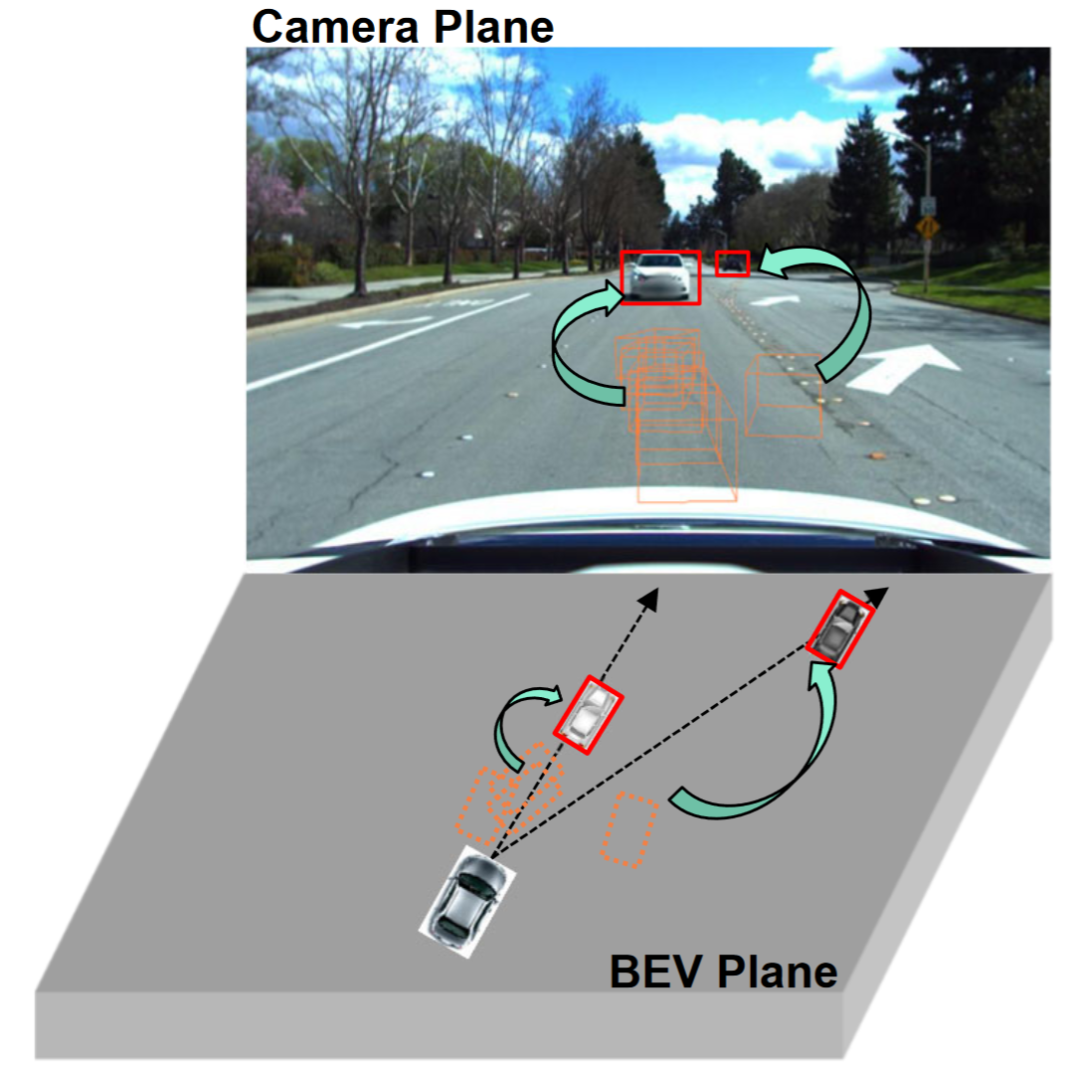
Cet article propose un cadre de détection BEV généralisé basé sur le débiaisme de perspective. Ce cadre peut non seulement aider le modèle à apprendre la perspective et les caractéristiques invariantes du contexte dans le domaine source, Des détecteurs bidimensionnels peuvent également être utilisés pour corriger davantage les caractéristiques géométriques parasites dans le domaine cible.
- Cet article est la première tentative d'étude de l'adaptation de domaine non supervisée sur la détection BEV et établit une référence. Des résultats de pointe sont obtenus sur les protocoles UDA et DG.
- Cet article est le premier à explorer la formation sur un moteur virtuel sans annotations de scène réelles pour réaliser des tâches de détection BEV dans le monde réel.
Définition du problème
La recherche se concentre principalement sur l'amélioration de la généralisation de la détection BEV. Pour atteindre cet objectif, cet article explore deux protocoles avec une application pratique répandue, à savoir la généralisation de domaine (DG) et l'adaptation de domaine non supervisée (UDA) :
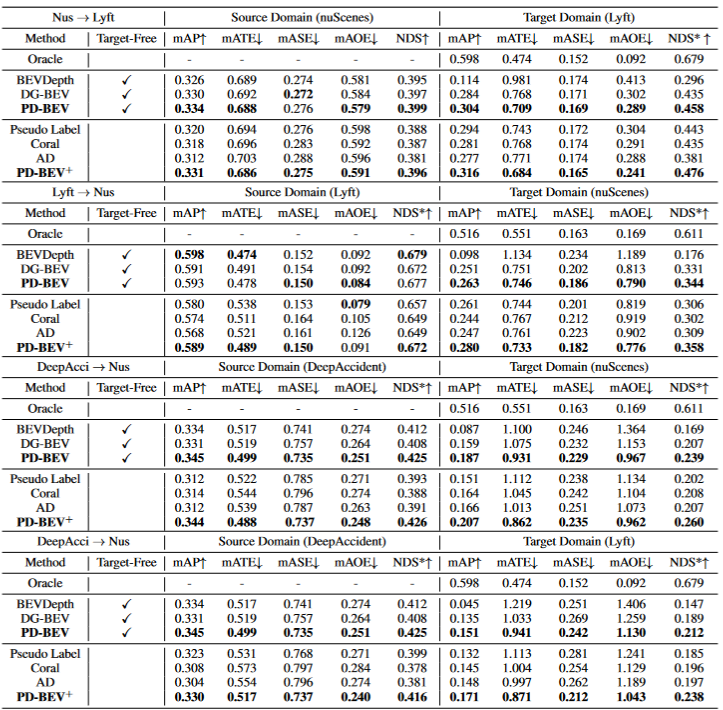
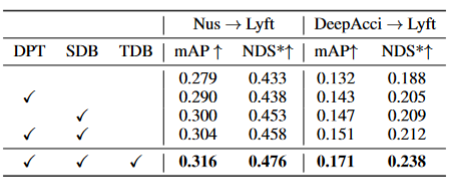
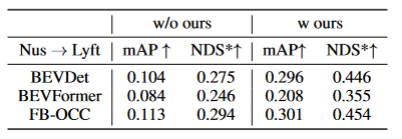
Domaines détectés par la généralisation BEV (DG) :Former un algorithme de détection BEV sur un système existant ensemble de données (domaine source) pour améliorer les performances de détection sur un ensemble de données inconnu (domaine cible). Par exemple, la formation d'un modèle de détection BEV dans un véhicule ou un scénario spécifique peut être directement généralisée à une variété de véhicules et de scénarios différents. Adaptation de domaine non supervisée (UDA) pour la détection BEV : Formez un algorithme de détection BEV sur un ensemble de données existant (domaine source) et utilisez des données non étiquetées dans le domaine cible pour améliorer les performances de détection. Par exemple, dans un nouveau véhicule ou une nouvelle ville, il vous suffit de collecter certaines données non supervisées pour améliorer les performances du modèle dans le nouveau véhicule et le nouvel environnement. Il convient de mentionner que la seule différence entre DG et UDA est de savoir si les données non étiquetées du domaine cible peuvent être utilisées. Afin de détecter l'inconnu L=[x,y,z] de l'objet, la plupart des détections BEV comporteront deux parties clés : (1) Obtenir les caractéristiques de l'image sous différents angles de vue ; 2) Fusion de ces images Les caractéristiques sont transférées vers l'espace BEV et le résultat final de la prédiction est obtenu : La formule ci-dessus décrit que l'écart de domaine peut provenir de l'étape d'extraction de caractéristiques ou de l'étape de fusion BEV. Ensuite, cet article a été poussé en annexe et a obtenu l'écart d'angle de vue du résultat final de la prédiction 3D projeté sur le résultat 2D comme : où k_u, b_u, k_v et b_v sont liés au décalage de domaine de l'encodeur BEV, d (u, v) est l'information finale sur la profondeur prévue du modèle. c_u et c_v représentent les coordonnées du centre optique de la caméra sur le plan image uv. L'équation ci-dessus fournit plusieurs corollaires importants : (1) L'existence d'un décalage de position finale entraînera un biais de perspective, ce qui montre que l'optimisation du biais de perspective peut aider à atténuer le décalage de domaine. (2) Même la position du point sur le rayon central optique de la caméra sur le plan d'imagerie à vue unique changera. Intuitivement, le changement de domaine modifie la position des fonctionnalités BEV, ce qui est dû à un surajustement dû à des points de vue limités sur les données d'entraînement et aux paramètres de la caméra. Pour atténuer ce problème, il est crucial de restituer de nouvelles images de vue à partir des fonctionnalités BEV, permettant ainsi au réseau d'apprendre des fonctionnalités indépendantes de la vue et de l'environnement. Dans cette optique, cette recherche vise à résoudre l'écart de perspective lié aux différents points de vue de rendu afin d'améliorer la capacité de généralisation du modèle PD-BEV est divisé en trois parties : sémantique Le rendu, le biais de suppression du domaine source et le débiasing du domaine cible sont illustrés à la figure 1. Le rendu sémantique explique comment établir la relation de perspective entre la 2D et la 3D via les fonctionnalités BEV. Le débiasement du domaine source décrit comment améliorer les capacités de généralisation du modèle grâce au rendu sémantique dans le domaine source. Le débiasage du domaine cible décrit l'utilisation de données non étiquetées dans le domaine cible pour améliorer les capacités de généralisation du modèle grâce au rendu sémantique. Étant donné que de nombreux algorithmes compresseront le volume BEV en caractéristiques bidimensionnelles, nous utilisons d'abord le décodeur BEV pour convertir les caractéristiques BEV en volume : La formule ci-dessus est en fait le plan BEV Pour amélioration, une dimension de hauteur est ajoutée. Ensuite, les paramètres internes et externes de la caméra peuvent être échantillonnés dans ce volume pour devenir une carte de fonctionnalités 2D, puis la carte de fonctionnalités 2D et les paramètres internes et externes de la caméra sont envoyés à un RenderNet pour prédire la carte thermique et les propriétés de l'objet de la perspective correspondante. Grâce à de telles opérations similaires à Nerf, un pont entre la 2D et la 3D peut être établi. Pour améliorer les performances de généralisation du modèle, plusieurs points clés doivent être améliorés dans le domaine source. Premièrement, la boîte 3D du domaine source peut être utilisée pour surveiller la carte thermique et les propriétés de la vue nouvellement rendue afin de réduire le biais de perspective. Deuxièmement, les informations de profondeur normalisées peuvent être utilisées pour aider les encodeurs d’images à mieux apprendre les informations géométriques. Ces améliorations contribueront à améliorer les performances de généralisation du modèle Supervision sémantique en perspective : Basé sur le rendu sémantique, les cartes thermiques et les attributs sont rendus sous différentes perspectives (sortie de RenderNet). Dans le même temps, les paramètres internes et externes d'une caméra sont échantillonnés de manière aléatoire et la boîte de l'objet est projetée à partir des coordonnées 3D dans le plan bidimensionnel de la caméra à l'aide de ces paramètres internes et externes. Utilisez ensuite la perte focale et la perte L1 pour contraindre la 2Dbox projetée et les résultats du rendu : Grâce à cette opération, le surajustement des paramètres internes et externes de la caméra peut être réduit et la robustesse aux nouvelles perspectives peut être améliorée. Il convient de mentionner que cet article convertit l'apprentissage supervisé à partir d'images RVB en cartes thermiques des centres d'objets pour éviter les défauts dus au manque de nouvelle perspective de supervision RVB dans le domaine de la conduite sans pilote. Supervision géométrique : Fournir des informations explicites sur la profondeur peut être efficace améliorer les performances de détection d'objets 3D multi-caméras. Cependant, la profondeur des prédictions du réseau a tendance à surajuster les paramètres intrinsèques. Par conséquent, cet article s'appuie sur une méthode de profondeur virtuelle : où BCE() représente la perte d'entropie croisée binaire et D_{pre} représente la profondeur prédite de DepthNet. f_u et f_v sont respectivement les distances focales u et v du plan image, et U est une constante. Il convient de noter que la profondeur ici correspond aux informations de profondeur de premier plan fournies en utilisant des boîtes 3D plutôt que des nuages de points. En faisant cela, DepthNet est plus susceptible de se concentrer sur la profondeur des objets au premier plan. Enfin, la profondeur virtuelle est reconvertie en profondeur réelle lorsque les caractéristiques sémantiques sont élevées vers le plan BEV en utilisant les informations de profondeur réelles. Il n'y a pas d'étiquette dans le domaine cible, la supervision de boîte 3D ne peut donc pas être utilisée pour améliorer la capacité de généralisation du modèle. Cet article explique donc que les résultats de détection 2D sont plus robustes que les résultats 3D. Cet article utilise donc des détecteurs 2D pré-entraînés dans le domaine source pour superviser la perspective rendue, et utilise également le mécanisme de pseudo-étiquette : Cette opération peut utiliser efficacement une détection 2D précise pour corriger la position de la cible au premier plan dans l'espace BEV, ce qui constitue une régularisation non supervisée du domaine cible. Afin d'améliorer encore la capacité de correction de la prédiction 2D, une pseudo-méthode est utilisée pour améliorer la confiance de la carte thermique de prédiction. Cet article fournit des preuves mathématiques en 3.2 et du matériel supplémentaire pour expliquer la cause des erreurs de projection 2D dans les résultats 3D. Cela explique également pourquoi les biais peuvent être supprimés de cette manière. Pour plus de détails, veuillez vous référer au document original. Bien que certains réseaux aient été ajoutés dans cet article pour faciliter la formation, ces réseaux ne sont pas nécessaires lors de l'inférence. En d’autres termes, notre méthode est applicable à la situation dans laquelle la plupart des méthodes de détection BEV apprennent des caractéristiques invariantes en perspective. Pour tester l'efficacité de notre framework, nous choisissons d'utiliser BEVDepth pour l'évaluation. La perte originale de BEVDepth est utilisée sur le domaine source comme principale supervision de détection 3D. En résumé, la perte finale de l'algorithme est : Le tableau 1 montre la comparaison des effets de différentes méthodes sous les protocoles de généralisation de domaine (DG) et d'adaptation de domaine non supervisée (UDA). Parmi eux, Target-Free représente le protocole DG, et Pseudo Label, Coral et AD sont quelques méthodes UDA courantes. Comme le montre le graphique, ces méthodes permettent toutes d’obtenir des améliorations significatives dans le domaine cible. Cela suggère que le rendu sémantique sert de pont pour aider à apprendre les fonctionnalités invariantes de perspective contre les changements de domaine. De plus, ces méthodes ne sacrifient pas les performances du domaine source et apportent même quelques améliorations dans la plupart des cas. Il convient notamment de mentionner que DeepAccident est développé sur la base du moteur virtuel Carla. Après une formation sur DeepAccident, l'algorithme a atteint des capacités de généralisation satisfaisantes. De plus, d’autres méthodes de détection BEV ont été testées, mais leurs performances de généralisation sont très médiocres sans conception particulière. Afin de vérifier davantage la capacité à utiliser des ensembles de données non supervisés dans le domaine cible, un benchmark UDA a également été établi et les méthodes UDA (notamment Pseudo Label, Coral et AD) ont été appliquées sur DG-BEV. Les expériences montrent que ces méthodes améliorent considérablement les performances. Le rendu implicite exploite pleinement les détecteurs 2D avec de meilleures performances de généralisation pour corriger les fausses informations géométriques des détecteurs 3D. De plus, il s’avère que la plupart des algorithmes ont tendance à dégrader les performances du domaine source, alors que notre méthode est relativement douce. Il convient de mentionner qu'AD et Coral montrent des améliorations significatives lors du passage d'ensembles de données virtuels à des ensembles de données réels, mais affichent une dégradation des performances lors des tests réels. En effet, ces deux algorithmes sont conçus pour gérer les changements de style, mais dans les scènes comportant de petits changements de style, ils peuvent détruire les informations sémantiques. Quant à l'algorithme Pseudo Label, il peut améliorer les performances de généralisation du modèle en augmentant la confiance dans certains domaines cibles relativement bons, mais augmenter aveuglément la confiance dans le domaine cible aggravera en fait le modèle. Les résultats expérimentaux prouvent que cet algorithme a obtenu une amélioration significative des performances dans DG et UDA. Les résultats expérimentaux d'ablation sur trois composants clés sont présentés dans le tableau 2 : pré-entraînement du détecteur 2D (DPT), biais de suppression du domaine source (SDB) et domaine cible. Débiasage (TDB). Les résultats expérimentaux montrent que chaque composant a obtenu des améliorations, parmi lesquelles SDB et TDB montrent des effets relativement significatifs Le tableau 3 montre que l'algorithme de l'algorithme peut être migré vers les algorithmes BEVFormer et FB-OCC. Étant donné que cet algorithme ne nécessite que des opérations supplémentaires sur les caractéristiques de l'image et les fonctionnalités BEV, il peut améliorer les algorithmes avec les fonctionnalités BEV. La figure 5 montre les objets non étiquetés détectés. La première ligne est la boîte 3D de l'étiquette et la deuxième ligne est le résultat de détection de l'algorithme. Les cases bleues indiquent que l'algorithme peut détecter certaines cases sans étiquette. Cela montre que la méthode peut même détecter des échantillons non étiquetés dans le domaine cible, tels que des véhicules trop éloignés ou dans des bâtiments des deux côtés de la rue. Cet article propose un cadre universel de détection d'objets 3D multi-caméras basé sur la dépolarisation en perspective, qui peut résoudre le problème de détection d'objets dans des domaines inconnus. Le cadre permet une détection cohérente et précise en projetant les résultats de détection 3D sur un plan de caméra 2D et en corrigeant le biais de perspective. De plus, le cadre introduit également une stratégie de débiaisation de perspective pour améliorer la robustesse du modèle en restituant des images sous différentes perspectives. Les résultats expérimentaux montrent que cette méthode permet d'obtenir des améliorations significatives des performances en matière de généralisation de domaine et d'adaptation de domaine non supervisée. En outre, cette méthode peut également être entraînée sur des ensembles de données virtuels sans nécessiter d'annotation de scène réelle, ce qui est pratique pour les applications en temps réel et le déploiement à grande échelle. Ces points forts démontrent les défis et le potentiel de la méthode pour résoudre la détection d'objets 3D multi-caméras. Cet article tente d'utiliser les idées de Nerf pour améliorer la capacité de généralisation de BEV et peut également utiliser des données de domaine source étiquetées et des données de domaine cible non étiquetées. En outre, le paradigme expérimental Sim2Real a été testé, ce qui présente une valeur potentielle pour la conduite autonome en boucle fermée. Il y a de bons résultats à la fois qualitatifs et quantitatifs, et le code open source vaut le détour Lien original : https://mp.weixin.qq.com/s/GRLu_JW6qZ_nQ9sLiE0p2gDéfinition de l'écart de l'angle de vue
Explication détaillée de l'algorithme PD-BEV
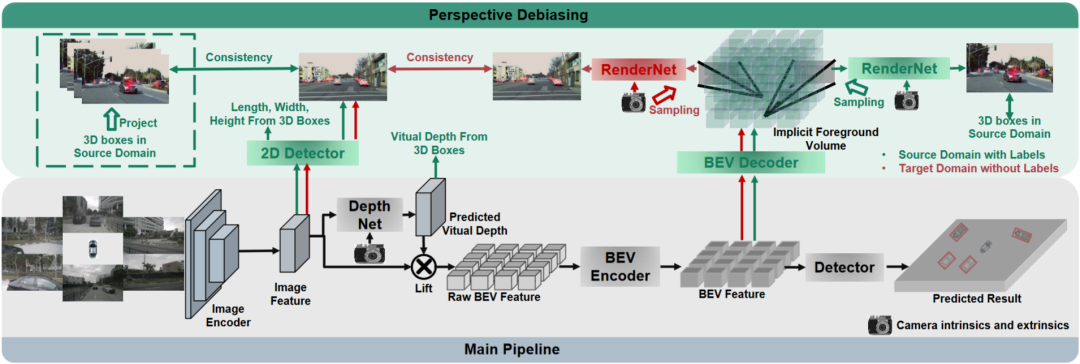
Rendu sémantique
Débiasage du domaine source
Débiaisation du domaine cible
Supervision globale
Résultats expérimentaux inter-domaines
Résumé

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le dernier chef-d'œuvre du MIT : utiliser GPT-3.5 pour résoudre le problème de la détection des anomalies des séries chronologiques
Jun 08, 2024 pm 06:09 PM
Le dernier chef-d'œuvre du MIT : utiliser GPT-3.5 pour résoudre le problème de la détection des anomalies des séries chronologiques
Jun 08, 2024 pm 06:09 PM
Aujourd'hui, j'aimerais vous présenter un article publié par le MIT la semaine dernière, utilisant GPT-3.5-turbo pour résoudre le problème de la détection des anomalies des séries chronologiques et vérifiant dans un premier temps l'efficacité du LLM dans la détection des anomalies des séries chronologiques. Il n'y a pas de réglage fin dans l'ensemble du processus et GPT-3.5-turbo est utilisé directement pour la détection des anomalies. Le cœur de cet article est de savoir comment convertir des séries temporelles en entrées pouvant être reconnues par GPT-3.5-turbo et comment concevoir. des invites ou des pipelines pour laisser LLM résoudre la tâche de détection des anomalies. Permettez-moi de vous présenter une introduction détaillée à ce travail. Titre de l'article image : Largelangagemodelscanbezero-shotanomalydete
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Comment évaluer la rentabilité du support commercial des frameworks Java
Jun 05, 2024 pm 05:25 PM
Comment évaluer la rentabilité du support commercial des frameworks Java
Jun 05, 2024 pm 05:25 PM
L'évaluation du rapport coût/performance du support commercial pour un framework Java implique les étapes suivantes : Déterminer le niveau d'assurance requis et les garanties de l'accord de niveau de service (SLA). L’expérience et l’expertise de l’équipe d’appui à la recherche. Envisagez des services supplémentaires tels que les mises à niveau, le dépannage et l'optimisation des performances. Évaluez les coûts de support commercial par rapport à l’atténuation des risques et à une efficacité accrue.
 Comment la courbe d'apprentissage des frameworks PHP se compare-t-elle à celle d'autres frameworks de langage ?
Jun 06, 2024 pm 12:41 PM
Comment la courbe d'apprentissage des frameworks PHP se compare-t-elle à celle d'autres frameworks de langage ?
Jun 06, 2024 pm 12:41 PM
La courbe d'apprentissage d'un framework PHP dépend de la maîtrise du langage, de la complexité du framework, de la qualité de la documentation et du support de la communauté. La courbe d'apprentissage des frameworks PHP est plus élevée par rapport aux frameworks Python et inférieure par rapport aux frameworks Ruby. Par rapport aux frameworks Java, les frameworks PHP ont une courbe d'apprentissage modérée mais un temps de démarrage plus court.
 Comment les options légères des frameworks PHP affectent-elles les performances des applications ?
Jun 06, 2024 am 10:53 AM
Comment les options légères des frameworks PHP affectent-elles les performances des applications ?
Jun 06, 2024 am 10:53 AM
Le framework PHP léger améliore les performances des applications grâce à une petite taille et une faible consommation de ressources. Ses fonctionnalités incluent : une petite taille, un démarrage rapide, une faible utilisation de la mémoire, une vitesse de réponse et un débit améliorés et une consommation de ressources réduite. Cas pratique : SlimFramework crée une API REST, seulement 500 Ko, une réactivité élevée et un débit élevé.
 Bonnes pratiques en matière de documentation du framework Golang
Jun 04, 2024 pm 05:00 PM
Bonnes pratiques en matière de documentation du framework Golang
Jun 04, 2024 pm 05:00 PM
La rédaction d'une documentation claire et complète est cruciale pour le framework Golang. Les meilleures pratiques incluent le respect d'un style de documentation établi, tel que le Go Coding Style Guide de Google. Utilisez une structure organisationnelle claire, comprenant des titres, des sous-titres et des listes, et fournissez la navigation. Fournit des informations complètes et précises, notamment des guides de démarrage, des références API et des concepts. Utilisez des exemples de code pour illustrer les concepts et l'utilisation. Maintenez la documentation à jour, suivez les modifications et documentez les nouvelles fonctionnalités. Fournir une assistance et des ressources communautaires telles que des problèmes et des forums GitHub. Créez des exemples pratiques, tels que la documentation API.
 RedMagic Tablet 3D Explorer Edition propose un affichage 3D sans lunettes
Sep 06, 2024 am 06:45 AM
RedMagic Tablet 3D Explorer Edition propose un affichage 3D sans lunettes
Sep 06, 2024 am 06:45 AM
La RedMagic Tablet 3D Explorer Edition a été lancée aux côtés de la Gaming Tablet Pro. Cependant, alors que ce dernier est davantage destiné aux joueurs, le premier est davantage destiné au divertissement. La nouvelle tablette Android est dotée de ce que l'entreprise appelle une « 3D à l'oeil nu ».
 Comment choisir le meilleur framework Golang pour différents scénarios d'application
Jun 05, 2024 pm 04:05 PM
Comment choisir le meilleur framework Golang pour différents scénarios d'application
Jun 05, 2024 pm 04:05 PM
Choisissez le meilleur framework Go en fonction des scénarios d'application : tenez compte du type d'application, des fonctionnalités du langage, des exigences de performances et de l'écosystème. Frameworks Go courants : Gin (application Web), Echo (service Web), Fibre (haut débit), gorm (ORM), fasthttp (vitesse). Cas pratique : construction de l'API REST (Fiber) et interaction avec la base de données (gorm). Choisissez un framework : choisissez fasthttp pour les performances clés, Gin/Echo pour les applications Web flexibles et gorm pour l'interaction avec la base de données.
