

Comment résoudre le problème de consommation répétée chez Kafka

Solutions au problème de consommation répétée de Kafka : 1. Gérer les échecs des consommateurs ; 2. Utiliser le traitement idempotent ; 3. Utiliser la technologie de déduplication des messages ; 5. Concevoir des producteurs idempotents ; . Surveiller et alerter. Introduction détaillée : 1. Gérer les échecs des consommateurs. Les consommateurs Kafka peuvent échouer ou se fermer anormalement, provoquant la nouvelle consommation des messages traités. 2. Utiliser le traitement idempotent fait référence au traitement du même message. comme un seul processus, et ainsi de suite.

Résoudre le problème de consommation répétée de Kafka nécessite diverses mesures, notamment la gestion des échecs des consommateurs, l'utilisation du traitement idempotent, la technologie de déduplication des messages, l'utilisation d'identifiants de message uniques, etc. Ces mesures seront présentées en détail ci-dessous :
1. Gestion des échecs des consommateurs
Les consommateurs Kafka peuvent échouer ou se fermer anormalement, entraînant la nouvelle consommation des messages traités. Afin d'éviter cette situation, vous pouvez prendre les mesures suivantes :
Permettre aux consommateurs de soumettre automatiquement des compensations : activez la fonction de soumission automatique des compensations dans le programme consommateur pour garantir que chaque message consommé avec succès sera correctement soumis au milieu Kafka. Cela garantit que même si le consommateur échoue, cela n'entraînera pas une consommation répétée des messages traités.
Utiliser le stockage persistant : stockez le décalage du consommateur dans un stockage persistant, tel qu'une base de données ou RocksDB. De cette façon, même en cas de défaillance du consommateur, la compensation peut être restaurée à partir du stockage persistant pour éviter une consommation répétée.
2. Utiliser le traitement idempotent
Le traitement idempotent signifie traiter le même message plusieurs fois, et le résultat est le même que le traiter une seule fois. Chez les consommateurs Kafka, la consommation répétée peut être évitée par un traitement idempotent des messages. Par exemple, dédoublonnez les messages au fur et à mesure de leur traitement ou utilisez des identifiants uniques pour identifier les messages en double. Cela garantit que même si le message est consommé à plusieurs reprises, il ne provoquera pas d’effets secondaires.
3. Technologie de déduplication des messages
La technologie de déduplication des messages est une méthode courante pour résoudre le problème de la consommation répétée. La déduplication des messages peut être réalisée en conservant un enregistrement des messages traités au sein de l'application ou en utilisant un stockage externe tel qu'une base de données. Avant de consommer un message, vérifiez si le message a été traité. S'il a été traité, ignorez le message. Cela peut effectivement éviter le problème de la consommation répétée.
4. Utiliser l'identifiant unique du message
Ajoutez un identifiant unique à chaque message et enregistrez l'identifiant traité dans l'application. Avant de consommer un message, vérifiez si l'identifiant unique du message existe déjà dans l'enregistrement traité, et ignorez le message s'il existe. Cela garantit que même si un message est envoyé à plusieurs reprises, il peut être identifié et traité grâce à l'identifiant unique.
5. Concevoir un producteur idempotent
Implémentez l'idempotence du côté production du message pour garantir que l'envoi répété du même message n'entraînera pas de consommation répétée. Ceci peut être réalisé en attribuant un identifiant unique à chaque message ou en utilisant une stratégie de messagerie idempotente. Cela garantit que même si le producteur envoie des messages en double, cela ne provoquera pas de problèmes de consommation en double.
6. Optimiser la configuration et les paramètres client de Kafka
En optimisant la configuration et les paramètres client de Kafka, les performances et la fiabilité de Kafka peuvent être améliorées, réduisant ainsi l'apparition de problèmes de consommation répétés. Par exemple, vous pouvez augmenter le nombre de partitions Kafka et augmenter la vitesse de consommation du consommateur, ou ajuster les paramètres de configuration du consommateur pour améliorer sa fiabilité et sa stabilité.
7. Surveillance et alarme
En surveillant les indicateurs de performance et le mécanisme d'alarme de Kafka, les problèmes de consommation répétés peuvent être découverts et traités en temps opportun. Par exemple, vous pouvez surveiller la vitesse de consommation des consommateurs, la soumission des compensations, la taille de la file d'attente Kafka et d'autres indicateurs, et définir des seuils d'alarme en fonction des conditions réelles. Lorsque le seuil d'alarme est atteint, le personnel concerné peut être rapidement informé par SMS, e-mail, etc. pour traitement. De cette manière, les problèmes peuvent être découverts et résolus à temps pour éviter l'expansion de problèmes de consommation répétés.
En résumé, résoudre le problème de consommation répétée de Kafka nécessite une prise en compte approfondie d'une variété de mesures, notamment la gestion des échecs des consommateurs, l'utilisation du traitement idempotent, la technologie de déduplication des messages, l'utilisation d'identifiants de message uniques, la conception de producteurs idempotents et l'optimisation de la configuration de Kafka et des paramètres du consommateur. comme surveillance et alarmes, etc. Il est nécessaire de choisir la méthode appropriée pour résoudre le problème de consommation répétée en fonction de la situation réelle, et de surveiller et d'optimiser en permanence pour améliorer les performances et la fiabilité globales.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1205
24
52
1205
24

 Comment mettre en œuvre une analyse boursière en temps réel à l'aide de PHP et Kafka
Jun 28, 2023 am 10:04 AM
Comment mettre en œuvre une analyse boursière en temps réel à l'aide de PHP et Kafka
Jun 28, 2023 am 10:04 AM
Avec le développement d’Internet et de la technologie, l’investissement numérique est devenu un sujet de préoccupation croissant. De nombreux investisseurs continuent d’explorer et d’étudier des stratégies d’investissement, dans l’espoir d’obtenir un retour sur investissement plus élevé. Dans le domaine du trading d'actions, l'analyse boursière en temps réel est très importante pour la prise de décision, et l'utilisation de la file d'attente de messages en temps réel Kafka et de la technologie PHP constitue un moyen efficace et pratique. 1. Introduction à Kafka Kafka est un système de messagerie distribué de publication et d'abonnement à haut débit développé par LinkedIn. Les principales fonctionnalités de Kafka sont
 Comment spécifier dynamiquement plusieurs sujets à l'aide de @KafkaListener dans springboot+kafka
May 20, 2023 pm 08:58 PM
Comment spécifier dynamiquement plusieurs sujets à l'aide de @KafkaListener dans springboot+kafka
May 20, 2023 pm 08:58 PM
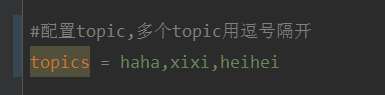
Expliquez que ce projet est un projet d'intégration springboot+kafak, il utilise donc l'annotation de consommation kafak @KafkaListener dans springboot. Tout d'abord, configurez plusieurs sujets séparés par des virgules dans application.properties. Méthode : utilisez l'expression SpEl de Spring pour configurer les sujets comme : @KafkaListener(topics="#{’${topics}’.split(’,’)}") pour exécuter le programme. L'effet d'impression de la console est le suivant.
 Comment SpringBoot intègre la classe d'outils de configuration Kafka
May 12, 2023 pm 09:58 PM
Comment SpringBoot intègre la classe d'outils de configuration Kafka
May 12, 2023 pm 09:58 PM
spring-kafka est basé sur l'intégration de la version java de kafkaclient et spring. Il fournit KafkaTemplate, qui encapsule diverses méthodes pour une utilisation facile. Il encapsule le client kafka d'Apache, et il n'est pas nécessaire d'importer le client pour dépendre de l'organisation. .springframework.kafkaspring-kafkaYML configuration kafka:#bootstrap-servers:server1:9092,server2:9093#adresse de développement de kafka,#producteur de configuration du producteur:#clé de classe de sérialisation et de désérialisation fournie par Kafka.
 Comment créer des applications de traitement de données en temps réel à l'aide de React et Apache Kafka
Sep 27, 2023 pm 02:25 PM
Comment créer des applications de traitement de données en temps réel à l'aide de React et Apache Kafka
Sep 27, 2023 pm 02:25 PM
Comment utiliser React et Apache Kafka pour créer des applications de traitement de données en temps réel Introduction : Avec l'essor du Big Data et du traitement de données en temps réel, la création d'applications de traitement de données en temps réel est devenue la priorité de nombreux développeurs. La combinaison de React, un framework front-end populaire, et d'Apache Kafka, un système de messagerie distribué hautes performances, peut nous aider à créer des applications de traitement de données en temps réel. Cet article expliquera comment utiliser React et Apache Kafka pour créer des applications de traitement de données en temps réel, et
 Cinq sélections d'outils de visualisation pour explorer Kafka
Feb 01, 2024 am 08:03 AM
Cinq sélections d'outils de visualisation pour explorer Kafka
Feb 01, 2024 am 08:03 AM
Cinq options pour les outils de visualisation Kafka ApacheKafka est une plateforme de traitement de flux distribué capable de traiter de grandes quantités de données en temps réel. Il est largement utilisé pour créer des pipelines de données en temps réel, des files d'attente de messages et des applications basées sur des événements. Les outils de visualisation de Kafka peuvent aider les utilisateurs à surveiller et gérer les clusters Kafka et à mieux comprendre les flux de données Kafka. Ce qui suit est une introduction à cinq outils de visualisation Kafka populaires : ConfluentControlCenterConfluent
 Analyse comparative des outils de visualisation kafka : Comment choisir l'outil le plus approprié ?
Jan 05, 2024 pm 12:15 PM
Analyse comparative des outils de visualisation kafka : Comment choisir l'outil le plus approprié ?
Jan 05, 2024 pm 12:15 PM
Comment choisir le bon outil de visualisation Kafka ? Analyse comparative de cinq outils Introduction : Kafka est un système de file d'attente de messages distribué à haute performance et à haut débit, largement utilisé dans le domaine du Big Data. Avec la popularité de Kafka, de plus en plus d'entreprises et de développeurs ont besoin d'un outil visuel pour surveiller et gérer facilement les clusters Kafka. Cet article présentera cinq outils de visualisation Kafka couramment utilisés et comparera leurs caractéristiques et fonctions pour aider les lecteurs à choisir l'outil qui répond à leurs besoins. 1. KafkaManager
 Exemple de code pour le projet Springboot pour configurer plusieurs kafka
May 14, 2023 pm 12:28 PM
Exemple de code pour le projet Springboot pour configurer plusieurs kafka
May 14, 2023 pm 12:28 PM
1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2. Informations relatives au fichier de configuration kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#Le nombre de threads pouvant être consommés simultanément (généralement cohérent avec le nombre de partitions )kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 La pratique du go-zero et Kafka+Avro : construire un système de traitement de données interactif performant
Jun 23, 2023 am 09:04 AM
La pratique du go-zero et Kafka+Avro : construire un système de traitement de données interactif performant
Jun 23, 2023 am 09:04 AM
Ces dernières années, avec l'essor du Big Data et des communautés open source actives, de plus en plus d'entreprises ont commencé à rechercher des systèmes de traitement de données interactifs hautes performances pour répondre aux besoins croissants en matière de données. Dans cette vague de mises à niveau technologiques, le go-zero et Kafka+Avro suscitent l’attention et sont adoptés par de plus en plus d’entreprises. go-zero est un framework de microservices développé sur la base du langage Golang. Il présente les caractéristiques de hautes performances, de facilité d'utilisation, d'extension facile et de maintenance facile. Il est conçu pour aider les entreprises à créer rapidement des systèmes d'applications de microservices efficaces. sa croissance rapide
