
 Périphériques technologiques
IA
La technologie TF-T2V développée conjointement par Huake, Ali et d'autres sociétés réduit le coût de production vidéo IA !
Périphériques technologiques
IA
La technologie TF-T2V développée conjointement par Huake, Ali et d'autres sociétés réduit le coût de production vidéo IA !
La technologie TF-T2V développée conjointement par Huake, Ali et d'autres sociétés réduit le coût de production vidéo IA !

Au cours des deux dernières années, avec l'ouverture d'ensembles de données d'images et de textes à grande échelle tels que LAION-5B, une série de méthodes étonnantes ont émergé dans le domaine de la génération d'images, telles que Stable Diffusion, DALL-E 2, ControlNet et Composer. L’émergence de ces méthodes a permis de grandes percées et progrès dans le domaine de la génération d’images. Le domaine de la génération d’images s’est développé rapidement au cours des deux dernières années seulement.
Cependant, la génération vidéo est encore confrontée à d'énormes défis. Premièrement, par rapport à la génération d’images, la génération vidéo doit traiter des données de plus grande dimension et prendre en compte des dimensions temporelles supplémentaires, ce qui pose le problème de la modélisation temporelle. Pour favoriser l’apprentissage de la dynamique temporelle, nous avons besoin de davantage de données sur les paires vidéo-texte. Cependant, une annotation temporelle précise des vidéos est très coûteuse, ce qui limite la taille des ensembles de données vidéo-texte. Actuellement, l'ensemble de données vidéo WebVid10M existant ne contient que 10,7 millions de paires vidéo-texte. Par rapport à l'ensemble de données d'images LAION-5B, la taille des données est très différente. Cela restreint considérablement la possibilité d’une expansion à grande échelle des modèles de génération vidéo.
Pour résoudre les problèmes ci-dessus, l'équipe de recherche conjointe de l'Université des sciences et technologies de Huazhong, du groupe Alibaba, de l'université du Zhejiang et du groupe Ant a récemment publié la solution vidéo TF-T2V :

Paper adresse : https://arxiv.org/abs/2312.15770
Page d'accueil du projet : https://tf-t2v.github.io/
Le code source sera bientôt publié : https://github.com /ali-vilab/i2vgen -xl (projet VGen).
Cette solution adopte une nouvelle approche et propose une génération de vidéo basée sur des données vidéo annotées sans texte à grande échelle, qui peuvent apprendre une dynamique de mouvement riche.
Tout d'abord, jetons un coup d'œil à l'effet de génération vidéo du TF-T2V :
Tâche vidéo Vincent
Mots rapides : générer une vidéo d'une grande créature ressemblant à du givre sur la neige- terrain couvert.

Mot rapide : Générez une vidéo animée d'une abeille de dessin animé.

Mot rapide : Générez une vidéo contenant une moto fantastique futuriste.

Mot rapide : Générez une vidéo d'un petit garçon souriant joyeusement.

Mot rapide : Générez une vidéo d'un vieil homme ressentant un mal de tête. Tâche de génération vidéo combinée synthèse vidéo en résolution :

Réglage semi-supervisé
La méthode TF-T2V dans le cadre semi-supervisé peut également générer des vidéos qui correspondent à la description textuelle du mouvement, telles que "Les gens courent de droite à gauche".


Introduction à la méthode
L'idée principale de TF-T2V est de diviser le modèle en une branche de mouvement et une branche d'apparence. La branche de mouvement est utilisée pour modéliser la dynamique du mouvement, et. la branche apparence est utilisée pour apprendre les informations apparentes. Ces deux branches sont formées conjointement et peuvent enfin réaliser une génération vidéo basée sur du texte.
Afin d'améliorer la cohérence temporelle des vidéos générées, l'équipe d'auteur a également proposé une perte de cohérence temporelle pour apprendre explicitement la continuité entre les images vidéo.
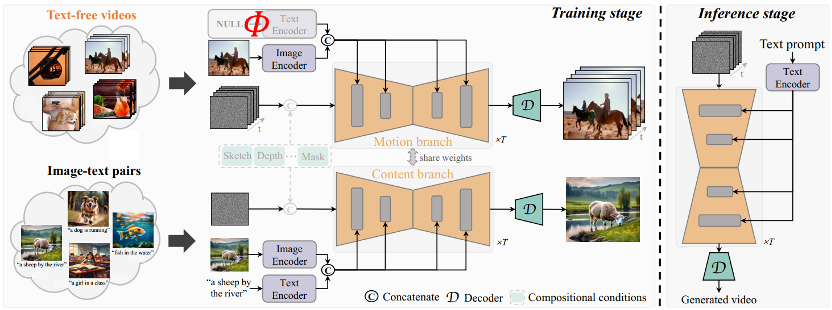
Il convient de mentionner que TF-T2V est un cadre général qui convient non seulement aux tâches vidéo Vincent, mais également aux tâches de génération vidéo combinées, telles que le croquis en vidéo, l'inpainting vidéo, la première image. -vers la vidéo, etc.
Pour des détails spécifiques et des résultats plus expérimentaux, veuillez vous référer à l'article original ou à la page d'accueil du projet.
De plus, l'équipe d'auteurs a également utilisé TF-T2V comme modèle d'enseignant et a utilisé une technologie de distillation cohérente pour obtenir le modèle VideoLCM :

Adresse papier : https://arxiv.org/abs/ 2312.09109
Page d'accueil du projet : https://tf-t2v.github.io/
Le code source sera bientôt publié : https://github.com/ali-vilab/i2vgen-xl (projet VGen) .
Contrairement à la méthode de génération vidéo précédente qui nécessitait environ 50 étapes de débruitage DDIM, la méthode VideoLCM basée sur TF-T2V peut générer des vidéos haute fidélité avec seulement environ 4 étapes de débruitage d'inférence, ce qui améliore considérablement l'efficacité de la génération vidéo. efficacité.
Jetons un coup d'œil aux résultats de l'inférence de débruitage en 4 étapes de VideoLCM :

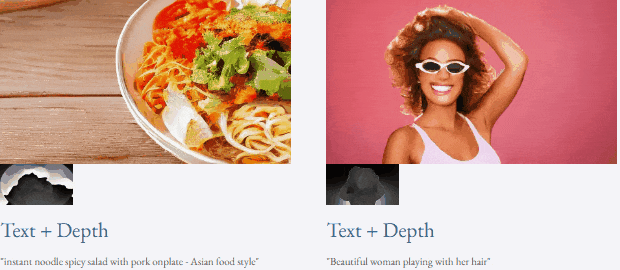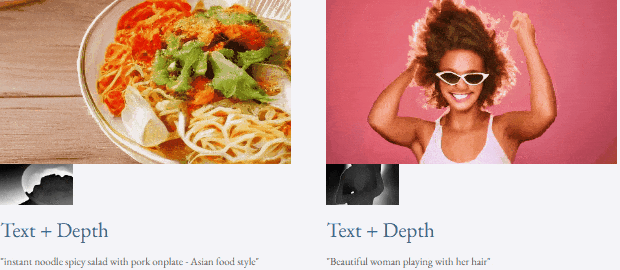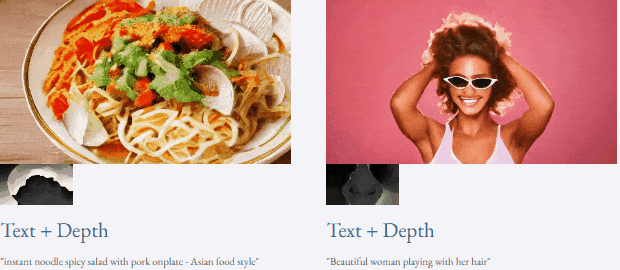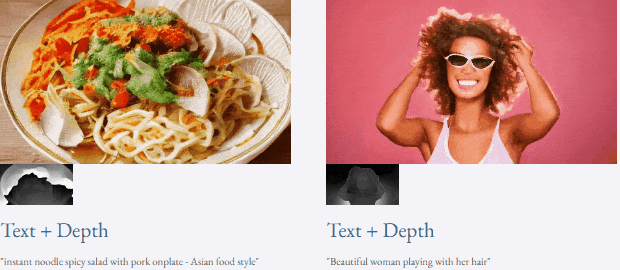

Pour des détails spécifiques et des résultats plus expérimentaux, veuillez vous référer à l'article original de VideoLCM ou au projet page d'accueil.
Dans l'ensemble, la solution TF-T2V apporte de nouvelles idées dans le domaine de la génération vidéo et surmonte les défis posés par la taille des ensembles de données et les problèmes d'étiquetage. Tirant parti des données vidéo d'annotation sans texte à grande échelle, TF-T2V est capable de générer des vidéos de haute qualité et est appliqué à une variété de tâches de génération vidéo. Cette innovation favorisera le développement de la technologie de génération vidéo et apportera des scénarios d'application et des opportunités commerciales plus larges à tous les horizons.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Est-ce une infraction de publier des vidéos d'autres personnes sur Douyin ? Comment éditer des vidéos sans infraction ?
Mar 21, 2024 pm 05:57 PM
Est-ce une infraction de publier des vidéos d'autres personnes sur Douyin ? Comment éditer des vidéos sans infraction ?
Mar 21, 2024 pm 05:57 PM
Avec l'essor des plateformes de vidéos courtes, Douyin est devenu un élément indispensable de la vie quotidienne de chacun. Sur TikTok, nous pouvons voir des vidéos intéressantes du monde entier. Certaines personnes aiment publier les vidéos d’autres personnes, ce qui soulève une question : Douyin enfreint-il la publication de vidéos d’autres personnes ? Cet article abordera ce problème et vous expliquera comment éditer des vidéos sans infraction et comment éviter les problèmes d'infraction. 1. Cela porte-t-il atteinte à la publication par Douyin de vidéos d'autres personnes ? Selon les dispositions de la loi sur le droit d'auteur de mon pays, l'utilisation non autorisée des œuvres du titulaire du droit d'auteur sans l'autorisation du titulaire du droit d'auteur constitue une infraction. Par conséquent, publier des vidéos d’autres personnes sur Douyin sans l’autorisation de l’auteur original ou du titulaire des droits d’auteur constitue une infraction. 2. Comment monter une vidéo sans contrefaçon ? 1. Utilisation de contenu du domaine public ou sous licence : Public
 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Comment gagner de l'argent en publiant des vidéos sur Douyin ? Comment un débutant peut-il gagner de l'argent sur Douyin ?
Mar 21, 2024 pm 08:17 PM
Comment gagner de l'argent en publiant des vidéos sur Douyin ? Comment un débutant peut-il gagner de l'argent sur Douyin ?
Mar 21, 2024 pm 08:17 PM
Douyin, la plateforme nationale de courtes vidéos, nous permet non seulement de profiter d'une variété de courtes vidéos intéressantes et originales pendant notre temps libre, mais nous donne également une scène pour nous montrer et réaliser nos valeurs. Alors, comment gagner de l’argent en postant des vidéos sur Douyin ? Cet article répondra à cette question en détail et vous aidera à gagner plus d’argent sur TikTok. 1. Comment gagner de l’argent en publiant des vidéos sur Douyin ? Après avoir posté une vidéo et obtenu un certain nombre de vues sur Douyin, vous aurez la possibilité de participer au plan de partage publicitaire. Cette méthode de revenus est l’une des plus connues des utilisateurs de Douyin et constitue également la principale source de revenus pour de nombreux créateurs. Douyin décide d'offrir ou non des opportunités de partage de publicités en fonction de divers facteurs tels que le poids du compte, le contenu vidéo et les commentaires du public. La plateforme TikTok permet aux téléspectateurs de soutenir leurs créateurs préférés en envoyant des cadeaux,
 Comment publier des vidéos sur Weibo sans compresser la qualité de l'image_Comment publier des vidéos sur Weibo sans compresser la qualité de l'image
Mar 30, 2024 pm 12:26 PM
Comment publier des vidéos sur Weibo sans compresser la qualité de l'image_Comment publier des vidéos sur Weibo sans compresser la qualité de l'image
Mar 30, 2024 pm 12:26 PM
1. Ouvrez d'abord Weibo sur votre téléphone mobile et cliquez sur [Moi] dans le coin inférieur droit (comme indiqué sur l'image). 2. Cliquez ensuite sur [Gear] dans le coin supérieur droit pour ouvrir les paramètres (comme indiqué sur l'image). 3. Ensuite, recherchez et ouvrez [Paramètres généraux] (comme indiqué sur l'image). 4. Entrez ensuite l'option [Video Follow] (comme indiqué sur l'image). 5. Ensuite, ouvrez le paramètre [Résolution de téléchargement vidéo] (comme indiqué sur l'image). 6. Enfin, sélectionnez [Qualité d'image originale] pour éviter la compression (comme indiqué sur l'image).
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Comment publier les œuvres vidéo de Xiaohongshu ? À quoi dois-je faire attention lorsque je publie des vidéos ?
Mar 23, 2024 pm 08:50 PM
Comment publier les œuvres vidéo de Xiaohongshu ? À quoi dois-je faire attention lorsque je publie des vidéos ?
Mar 23, 2024 pm 08:50 PM
Avec l'essor des plateformes de vidéos courtes, Xiaohongshu est devenue une plateforme permettant à de nombreuses personnes de partager leur vie, de s'exprimer et de gagner du trafic. Sur cette plateforme, la publication d’œuvres vidéo est un moyen d’interaction très prisé. Alors, comment publier les œuvres vidéo de Xiaohongshu ? 1. Comment publier les œuvres vidéo de Xiaohongshu ? Tout d’abord, assurez-vous d’avoir un contenu vidéo prêt à partager. Vous pouvez utiliser votre téléphone portable ou un autre équipement photo pour prendre des photos, mais vous devez faire attention à la qualité de l'image et à la clarté du son. 2. Editer la vidéo : Afin de rendre le travail plus attrayant, vous pouvez éditer la vidéo. Vous pouvez utiliser un logiciel de montage vidéo professionnel, tel que Douyin, Kuaishou, etc., pour ajouter des filtres, de la musique, des sous-titres et d'autres éléments. 3. Choisissez une couverture : La couverture est la clé pour inciter les utilisateurs à cliquer. Choisissez une image claire et intéressante comme couverture pour inciter les utilisateurs à cliquer dessus.
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
