

Ces dernières années, China Telecom a continué à travailler dur dans le sens de la technologie de l'intelligence artificielle. Le 28 novembre 2023, la branche des technologies d'intelligence numérique de China Telecom a officiellement changé son nom pour devenir China Telecom Artificial Intelligence Technology Co., Ltd. (ci-après dénommée « Société d'IA de télécommunications »). En 2023, Telecom AI Company a remporté des prix consécutifs dans 21 grands concours nationaux et étrangers d'IA, a déposé plus de 100 brevets et a publié plus de 30 articles dans des conférences et revues de premier plan telles que CVPR, ACM MM et ICCV, démontrant les performances de entreprises centrales publiques. Premiers résultats dans le domaine de la technologie de l’intelligence artificielle
En tant qu'entreprise professionnelle permettant à China Telecom de mener des activités d'intelligence artificielle, Telecom AI Company est une entreprise basée sur la technologie, les capacités et la plate-forme. L'entreprise s'engage à conquérir les technologies de base de l'intelligence artificielle, à rechercher des technologies de pointe et à promouvoir l'expansion de l'espace industriel, dans le but de devenir un fournisseur de services d'intelligence artificielle de plusieurs dizaines de milliards. Au cours des deux dernières années, Telecom AI Company a développé avec succès de manière indépendante une série de résultats d'applications innovantes, telles que la plateforme d'autonomisation de l'entrepôt d'algorithmes Galaxy AI, la plateforme de puissance informatique Nebula AI niveau 4 et le grand modèle Star Universal Basic. Aujourd'hui, l'entreprise compte plus de 800 employés âgés en moyenne de 31 ans, dont 80 % sont du personnel de R&D et 70 % proviennent de grandes sociétés Internet nationales et étrangères et de grandes sociétés d'IA. Afin d'accélérer les progrès de la R&D à l'ère des grands modèles, l'entreprise dispose de plus de 2 500 cartes de formation avec une puissance de calcul équivalente à A100 et de plus de 300 personnes à temps plein pour l'annotation des données. Dans le même temps, la société coopère également avec des instituts de recherche scientifique tels que le laboratoire d'intelligence artificielle de Shanghai, l'université Jiaotong de Xi'an, l'université des postes et télécommunications de Pékin et l'institut de recherche Zhiyuan pour créer conjointement une technologie et une technologie d'intelligence artificielle de classe mondiale pour la Chine. Les 60 millions de réseaux vidéo de Telecom et des centaines de millions de scénarios d'utilisateurs Application
.Ensuite, nous examinerons et partagerons quelques résultats de recherche scientifique importants obtenus par les entreprises d’IA des télécommunications en 2023. Ce partage présentera les réalisations techniques de l'équipe d'algorithmes CV du Centre de R&D IA qui a remporté le championnat sur piste de localisation d'action temporelle lors de l'événement ICCV 2023. L'ICCV est l'une des trois principales conférences internationales dans le domaine de la vision par ordinateur. Elle a lieu tous les deux ans et jouit d'une grande réputation dans l'industrie. Cet article partagera les idées et solutions algorithmiques adoptées par l'équipe dans ce défi
ICCV 2023 Test de perception Challenge-Time Action Positioning Champion Partage technologique

Aperçu de la compétition et historique de l'équipe
Le premier défi de tests perceptuels ICCV 2023 lancé par DeepMind vise à évaluer les capacités du modèle dans les modalités vidéo, audio et texte. Le concours couvre quatre domaines de compétences, quatre types de raisonnement et six tâches informatiques pour évaluer de manière exhaustive les capacités des modèles de perception multimodaux. Parmi eux, la tâche principale du volet Localisation des actions temporelles est de procéder à une compréhension approfondie et à un positionnement précis des actions du contenu vidéo non édité. Cette technologie revêt une grande importance pour divers scénarios d'application tels que les systèmes de conduite autonome et l'analyse de la vidéosurveillance
.Dans ce concours, l'équipe participante est composée de membres de la direction des algorithmes de trafic de la société d'IA en télécommunications. L'équipe s'appelle CTCV. Les sociétés d’IA en télécommunications ont mené des recherches approfondies dans le domaine de la technologie de vision par ordinateur et accumulé une riche expérience. Ses acquis technologiques ont été largement utilisés dans de nombreux domaines d'affaires tels que la gouvernance urbaine ou la sécurité routière, et continuent de servir un grand nombre d'utilisateurs
L'introduction est le début d'un article et est destinée à intéresser le lecteur et à fournir des informations de base. Une bonne introduction attire l'attention du lecteur, résume le sujet de l'article et incite le lecteur à continuer la lecture. Lorsque vous rédigez une introduction, vous devez faire attention à un langage concis et clair et à un contenu précis et puissant. Le but de l'introduction est de guider le lecteur dans le sujet de l'article, il est donc nécessaire de citer des faits, des données ou des questions pertinentes qui suscitent la réflexion. Bref, l'introduction est la porte d'entrée vers l'article et peut décider si le lecteur continuera à lire
Un problème difficile dans la compréhension vidéo est la tâche de localisation et de classification des actions dans les vidéos, à savoir la localisation des actions temporelles (TAL)
La technologieTAL a fait des progrès significatifs récemment. Par exemple, TadTR et ReAct adoptent un décodeur basé sur Transformer similaire à DETR pour la détection d'actions, modélisant les instances d'action sous la forme d'un ensemble apprenable. TallFormer utilise un encodeur basé sur Transformer pour extraire les représentations vidéo
Bien que les méthodes ci-dessus aient obtenu de bons résultats en matière de localisation temporelle des actions, il existe certaines limites dans les capacités de perception vidéo. Pour mieux localiser les instances d’action, une représentation fiable des fonctionnalités vidéo est essentielle. Notre équipe a d'abord utilisé le framework VideoMAE-v2, ajouté la couche adaptateur + linéaire, formé un modèle de prédiction de catégorie d'action avec deux réseaux fédérateurs différents et utilisé la couche précédente de la couche de classification du modèle pour extraire des fonctionnalités pour la tâche TAL. Ensuite, nous avons entraîné la tâche TAL à l'aide du cadre ActionFormer amélioré et modifié la méthode WBF pour l'adapter à la tâche TAL. Au final, notre méthode a obtenu un mAP de 0,50 sur l'ensemble d'évaluation, se classant premier, 3 points de pourcentage devant l'équipe deuxième et 34 points de pourcentage de plus que le modèle de référence fourni par Google DeepMind
2 Solution de concurrence
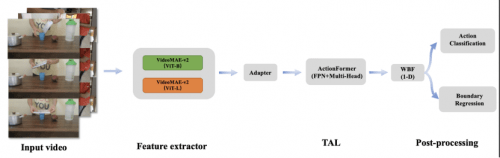
L'aperçu de l'algorithme est présenté dans la figure ci-dessous :
2.1 Amélioration des données
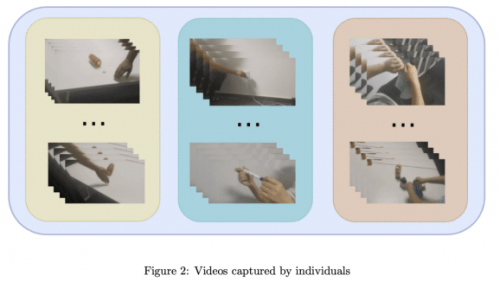
Dans la piste de localisation d'action temporelle, l'ensemble de données utilisé par l'équipe CTCV est une vidéo non découpée pour la localisation d'action, a une haute résolution et contient les caractéristiques de plusieurs instances d'action. En analysant l'ensemble de données, il a été constaté que l'ensemble de formation manquait de trois étiquettes de catégorie par rapport à l'ensemble de validation. Afin de garantir l'adéquation de la vérification du modèle et de répondre aux exigences du concours, l'équipe a collecté une petite quantité de données vidéo et l'a ajoutée à l'ensemble de données d'entraînement pour enrichir les échantillons d'entraînement. Dans le même temps, afin de simplifier le processus d'annotation, chaque préréglage vidéo ne contient qu'une seule action
Veuillez vous référer à l'échantillon vidéo auto-collecté dans la figure 2
2.2 Reconnaissance d'actions et extraction de fonctionnalités
Ces dernières années, de nombreux modèles de base basés sur la formation de données à grande échelle ont vu le jour. Ces modèles appliquent les puissantes capacités de généralisation des modèles de base à plusieurs tâches en aval grâce à la reconnaissance d'échantillon nul, à la détection linéaire, à un réglage fin rapide et à un réglage fin. et d'autres méthodes, ont efficacement favorisé les progrès dans de nombreux aspects du domaine de l'intelligence artificielle
La localisation et la reconnaissance des mouvements dans les pistes TAL sont très difficiles. Par exemple, les deux actions « faire semblant de déchirer quelque chose en morceaux » et « déchirer quelque chose en morceaux » sont très similaires, ce qui apporte sans aucun doute de plus grands défis au niveau des fonctionnalités. Par conséquent, l'effet de l'utilisation directe de modèles pré-entraînés existants pour extraire des fonctionnalités n'est pas idéal
Par conséquent, notre équipe a converti l'ensemble de données TAL en un ensemble de données de reconnaissance d'actions en analysant le fichier d'annotation JSON. Ensuite, nous utilisons Vit-B et Vit-L comme réseaux fédérateurs, ajoutons une couche d'adaptation et une couche linéaire pour la classification après le réseau VideoMAE-v2 et formons des classificateurs d'actions dans le même domaine de données. Nous supprimons également la couche linéaire du modèle de classification des actions et l'utilisons pour l'extraction de fonctionnalités vidéo. La dimension des fonctionnalités du modèle VitB est de 768, tandis que la dimension des fonctionnalités du modèle ViTL est de 1024. Lorsque nous concaténons ces deux fonctionnalités en même temps, nous générons une nouvelle fonctionnalité avec une dimension de 1792, qui sera utilisée comme alternative pour entraîner le modèle de localisation d'action temporelle. Au début de la formation, nous avons essayé les fonctionnalités audio, mais les résultats expérimentaux ont révélé que l'indice mAP diminuait. Par conséquent, lors des expériences ultérieures, nous n'avons pas pris en compte les fonctionnalités audio
2.3 Positionnement à action séquentielle
Actionformer est un modèle sans ancrage conçu avec un positionnement d'action séquentiel dans le temps. Il intègre des fonctionnalités multi-échelles et une attention personnelle locale dans la dimension temporelle. Dans ce concours, l'équipe CTCV a sélectionné Actionformer comme modèle de référence pour le positionnement de l'action, utilisé pour prédire les limites (heures de début et de fin) et les catégories d'occurrences d'action
L'équipe CTCV a unifié le traitement des tâches de régression des limites d'action et de classification des actions. Par rapport à la structure de formation de base, les fonctionnalités vidéo sont d'abord codées dans un transformateur multi-échelle. Ensuite, une couche de pyramide de caractéristiques est introduite dans la branche principale de la régression et de la classification du modèle pour améliorer la capacité d'expression des caractéristiques du réseau. La branche principale de chaque pas de temps génère un candidat à l'action. Dans le même temps, en augmentant le nombre de têtes à 32 et en introduisant la structure fpn1D, les capacités de positionnement et de reconnaissance du modèle sont encore améliorées
1-D 2.4 WBF
Weighted Boxes Fusion (WBF) est une méthode innovante de fusion de cadres de détection. Cette méthode utilise la confiance de toutes les trames de détection pour construire la trame de prédiction finale et montre de bons résultats dans la détection de cibles d'image. Contrairement aux méthodes NMS et soft-NMS, la fusion de boîtes pondérées n'écarte aucune prédiction, mais utilise les scores de confiance de toutes les boîtes englobantes proposées pour construire une boîte moyenne. Cette méthode améliore considérablement la précision de la prédiction des rectangles
Inspirée par WBF, l'équipe CTCV a analogisé le cadre de délimitation unidimensionnel d'une action avec un segment de ligne unidimensionnel et a modifié la méthode WBF pour la rendre adaptée aux tâches TAL. Les résultats expérimentaux montrent l'efficacité de cette méthode, comme le montre la figure 3
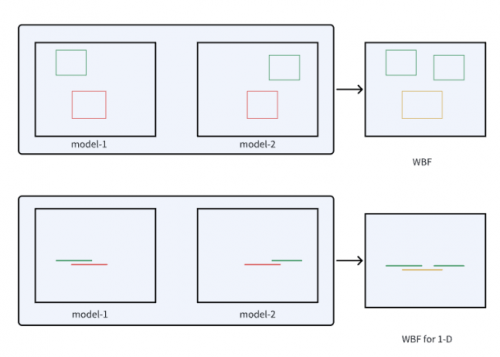
Le diagramme WBF unidimensionnel amélioré est présenté dans la figure 3
3 Résultats expérimentaux
3.1 Indicateurs d'évaluation. Critères d'évaluation
La métrique d'évaluation est mAP, qui est utilisée pour ce défi. mAP est déterminé en calculant la précision moyenne pour différentes catégories d’actions et seuils IoU. L'équipe CTCV évalue les seuils IoU par incréments de 0,1, allant de 0,1 à 0,5
3.2 Les détails expérimentaux sont réécrits comme suit :
Afin d'obtenir un modèle diversifié, l'équipe CTCV a rééchantillonné 80 % de l'ensemble de données d'entraînement, soit un total de 5 fois. Les caractéristiques de Vit-B, Vit-L et concat ont été utilisées pour la formation de modèles et 15 modèles différents ont été obtenus avec succès. Enfin, les résultats d'évaluation de ces modèles sont entrés dans le module WBF, et le même poids de fusion est attribué à chaque résultat de modèle
Les résultats expérimentaux sont les suivants :
La comparaison des performances des différentes fonctionnalités est présentée dans le tableau 1. Les première et deuxième lignes montrent les résultats utilisant les fonctionnalités ViT-B et ViT-L. La troisième ligne montre les résultats de la cascade de fonctionnalités ViT-B et ViT-L
Au cours de l'expérience, l'équipe CTCV a constaté que la précision moyenne (mAP) des caractéristiques de la cascade était légèrement inférieure à celle du ViT-L, mais toujours meilleure que celle du ViT-B. Néanmoins, grâce à l'exécution de diverses méthodes sur l'ensemble de vérification, nous avons fusionné les résultats de prédiction de différentes fonctionnalités dans l'ensemble d'évaluation avec l'aide de WBF, et le mAP finalement soumis au système était de 0,50
Le contenu à réécrire est : 4 Conclusion
L'équipe CTCV a adopté un certain nombre de stratégies pour améliorer les performances dans cette compétition. Premièrement, ils ont augmenté les données de formation avec des classes manquantes dans l'ensemble de validation grâce à la collecte de données. Deuxièmement, ils ont utilisé le framework VideoMAE-v2 pour ajouter une couche d'adaptateur afin de former l'extracteur de fonctionnalités vidéo, et ont formé la tâche TAL via le framework ActionFormer amélioré. En outre, ils ont modifié la méthode WBF pour fusionner efficacement les résultats des tests. Au final, l’équipe CTCV a obtenu un mAP de 0,50 sur l’ensemble d’évaluation, se classant ainsi en première position. Les entreprises d'IA en télécommunications ont toujours adhéré à la philosophie de développement selon laquelle « la technologie vient des affaires et va aux affaires ». Ils considèrent les concours comme une plate-forme importante pour tester et améliorer les capacités techniques, et continuent d'optimiser et d'améliorer les solutions techniques en participant à des concours afin de fournir aux clients des services de meilleure qualité. Dans le même temps, la participation au concours offre également de précieuses opportunités d'apprentissage et de croissance aux membres de l'équipe
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



