
 Périphériques technologiques
IA
Le robot DeepMind de Google a publié trois résultats d'affilée ! Les deux capacités ont été entièrement améliorées et le système de collecte de données peut gérer 20 robots en même temps.
Périphériques technologiques
IA
Le robot DeepMind de Google a publié trois résultats d'affilée ! Les deux capacités ont été entièrement améliorées et le système de collecte de données peut gérer 20 robots en même temps.
Le robot DeepMind de Google a publié trois résultats d'affilée ! Les deux capacités ont été entièrement améliorées et le système de collecte de données peut gérer 20 robots en même temps.

Presque en même temps que le robot « Shrimp Fried and Dishwashing » de Stanford, Google DeepMind a également publié ses derniers résultats en matière d'intelligence incarnée.

et c'est trois plans consécutifs :
Tout d'abord, un nouveau modèle qui se concentre sur l'amélioration de la vitesse de prise de décision, ce qui augmente la vitesse de fonctionnement du robot (par rapport au transformateur robotique d'origine) de 14 % - rapide Dans le même temps, la qualité n'a pas diminué et la précision a augmenté de 10,6 %.

Ensuite, il existe un nouveau cadre spécialisé dans les capacités de généralisation, qui peut créer des invites de trajectoire de mouvement pour le robot, lui permettant de faire face à 41 tâches inédites et d'atteindre un taux de réussite de 63 %.

Ne sous-estimez pas ce tableau, Par rapport aux 29% précédents, l'amélioration est assez importante.
Le dernier est un système de collecte de données sur les robots, qui peut gérer 20 robots à la fois. Jusqu'à présent, 77 000 données expérimentales ont été collectées à partir de leurs activités. Elles aideront Google à mieux mener à bien les travaux de formation ultérieurs.
Alors, quels sont ces trois résultats spécifiquement ? Regardons-les un par un.
La première étape dans l'application quotidienne des robots : vous pouvez effectuer directement des tâches que vous n'avez jamais vues auparavant
Google a souligné que pour réaliser un robot capable de véritablement entrer dans le monde réel, deux défis fondamentaux doivent être résolus.
1. Nouvelle capacité de promotion de tâches
2. Améliorer la vitesse de prise de décision
Les deux premiers résultats de cette série en trois parties sont principalement des améliorations dans ces deux domaines, et tous deux sont basés sur le modèle de robot de base de Google, Robotics Transformer( En abrégé RT) .
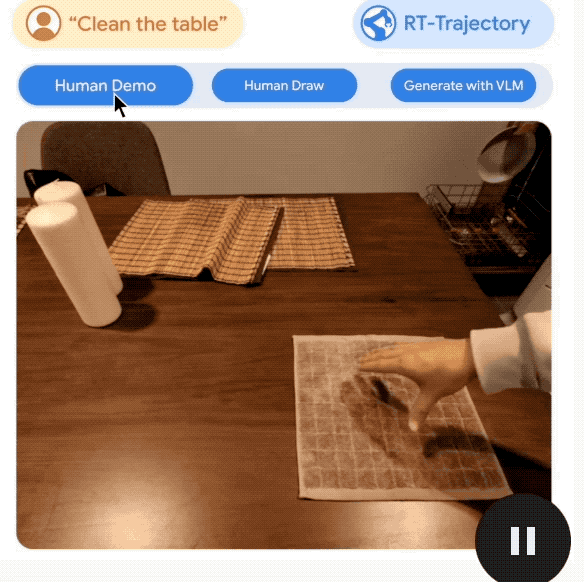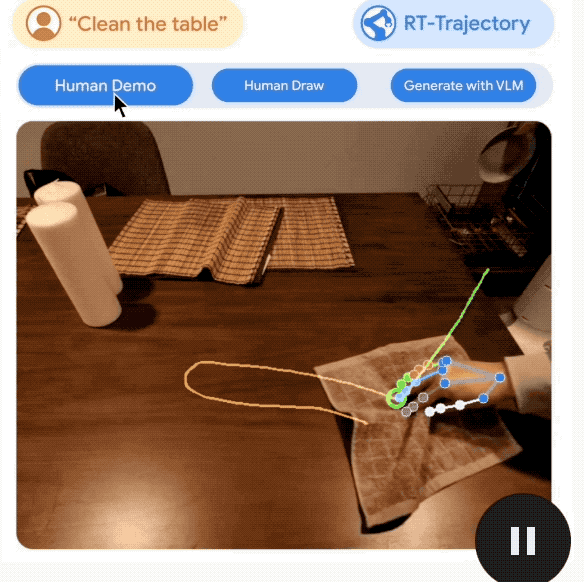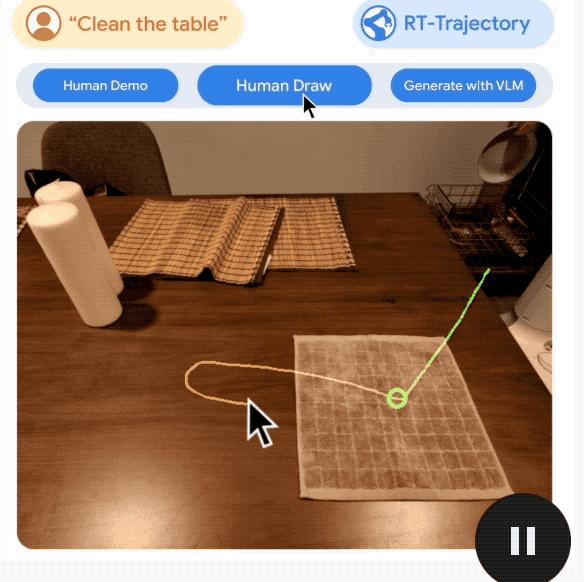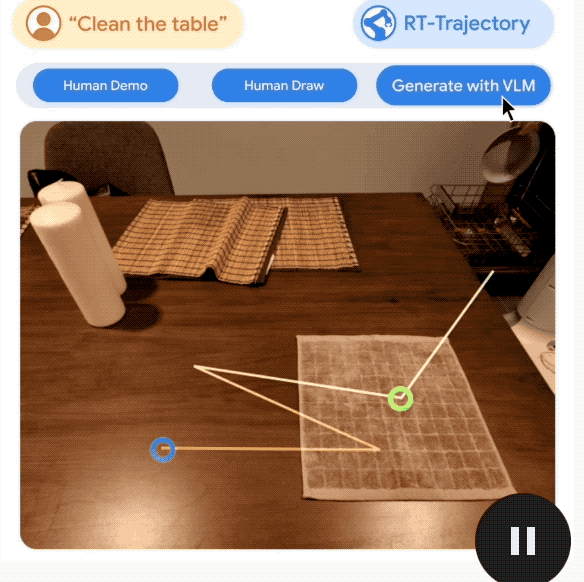
Regardons d'abord le premier : RT-Trajectory qui aide les robots à généraliser.
Pour les humains, des tâches telles que nettoyer la table sont faciles à comprendre, mais les robots ne les comprennent pas très bien.
Mais heureusement, nous pouvons lui transmettre cette instruction de diverses manières possibles, afin qu'il puisse entreprendre de véritables actions physiques.
D'une manière générale, la méthode traditionnelle consiste à mapper la tâche en une action spécifique, puis à laisser le bras du robot la terminer. Par exemple, essuyer la table peut être démonté en « fermez la pince, bougez à gauche, bougez à droite ».
Évidemment, la capacité de généralisation de cette méthode est très faible.
Ici, la nouvelle trajectoire RT proposée par Google apprend au robot à effectuer des tâches en lui fournissant des repères visuels.
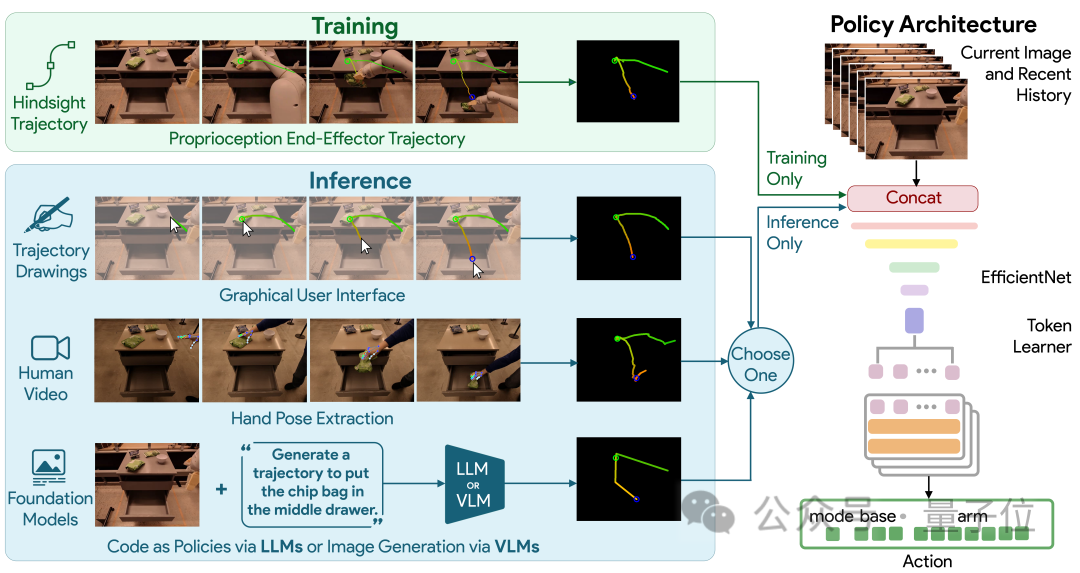
Plus précisément, les robots contrôlés par RT-Trajectory ajouteront des données améliorées de trajectoire 2D pendant l'entraînement.
Ces trajectoires sont présentées sous forme d'images RVB, comprenant des itinéraires et des points clés, fournissant des conseils de bas niveau mais très utiles à mesure que le robot apprend à effectuer des tâches.
Avec ce modèle, le taux de réussite des robots effectuant des tâches inédites a été directement augmenté jusqu'à 1 fois (par rapport au modèle de robot de base RT-2 de Google, de 29% => 63%) .
Ce qui mérite d'être mentionné, c'est que RT-Trajectory peut créer des trajectoires de diverses manières, notamment :
en regardant des démonstrations humaines, en acceptant des croquis dessinés à la main et générés par VLM (Modèle de langage visuel).
La deuxième étape de la robotisation quotidienne : la vitesse de prise de décision doit être rapide
Une fois la capacité de généralisation améliorée, nous nous concentrerons sur la vitesse de prise de décision.
Le modèle RT de Google utilise l'architecture Transformer Bien que le Transformer soit puissant, il s'appuie fortement sur le module d'attention à complexité quadratique.
Par conséquent, une fois que l'entrée du modèle RT est doublée (par exemple, en équipant le robot d'un capteur à plus haute résolution) , les ressources informatiques nécessaires pour le traiter augmenteront jusqu'à quatre fois, ce qui ralentira sérieusement la décision. -vitesse de fabrication.
Afin d'améliorer la vitesse des robots, Google a développé SARA-RT sur le modèle de base Robotics Transformer.
SARA-RT utilise une nouvelle méthode de réglage fin du modèle pour rendre le modèle RT d'origine plus efficace.
Cette méthode est appelée "up training" par Google. Sa fonction principale est de convertir la complexité quadratique originale en complexité linéaire tout en conservant la qualité du traitement.
Lorsque SARA-RT est appliqué au modèle RT-2 avec des milliards de paramètres, ce dernier peut atteindre des vitesses de fonctionnement plus rapides et une plus grande précision sur une variété de tâches.
Il convient également de mentionner que SARA-RT fournit une méthode universelle pour accélérer Transformer sans pré-formation coûteuse, afin qu'il puisse être bien promu.
Pas assez de données ? Créez-le vous-même
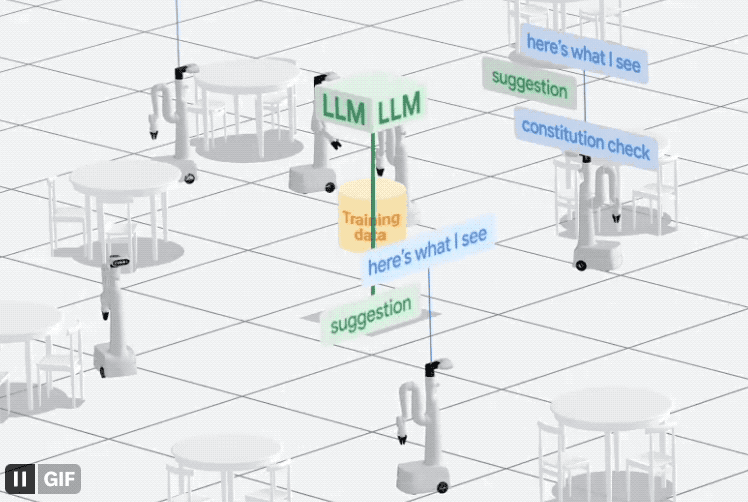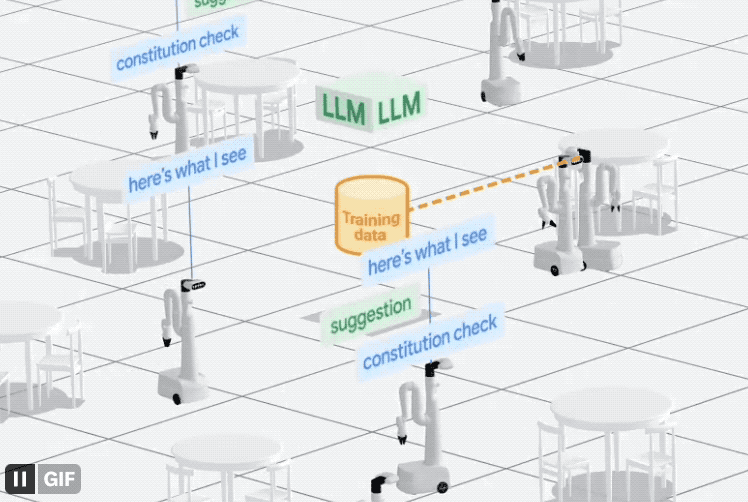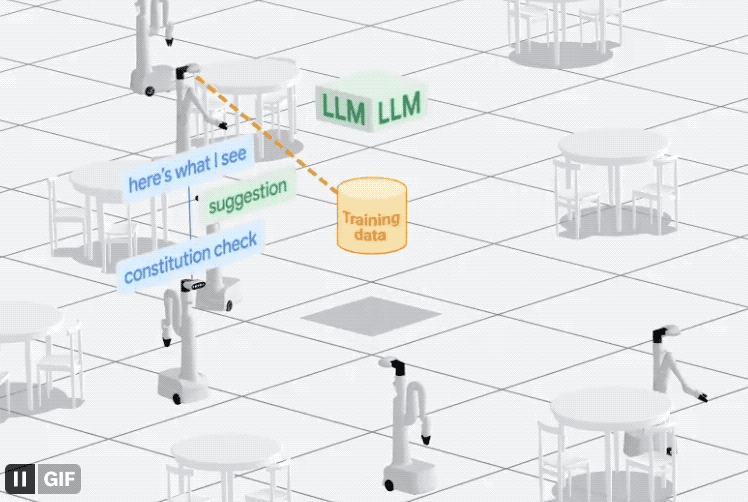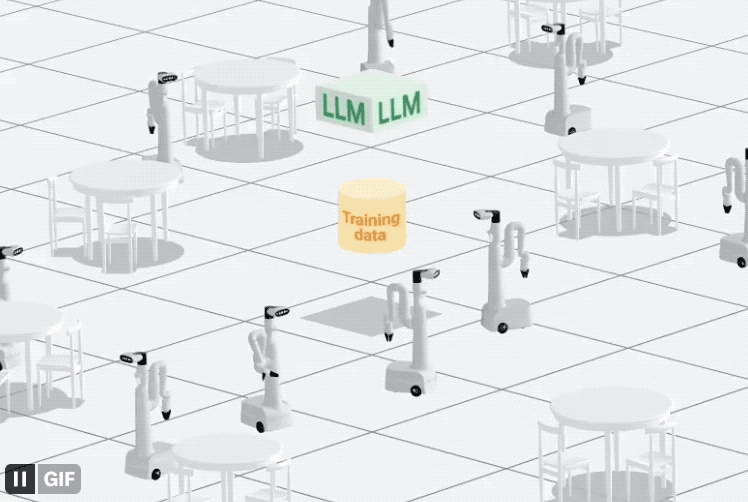
Enfin, afin d'aider les robots à mieux comprendre les tâches assignées par les humains, Google est également parti des données et a directement construit un système de collecte : AutoRT.
Ce système combine de grands modèles (y compris LLM et VLM) avec des modèles de contrôle de robot (RT) pour diriger en continu le robot afin qu'il effectue diverses tâches dans le monde réel, générant et collectant ainsi des données.
Le processus spécifique est le suivant :
Laissez le robot contacter "librement" l'environnement et se rapprocher de la cible.
Utilisez ensuite l'appareil photo et le modèle VLM pour décrire la scène devant vous, y compris les éléments spécifiques.
Ensuite, LLM utilise ces informations pour générer plusieurs tâches différentes.
Veuillez noter qu'après avoir été généré, le robot ne sera pas exécuté immédiatement. Au lieu de cela, LLM sera utilisé pour filtrerquelles tâches peuvent être accomplies indépendamment, lesquelles nécessitent un contrôle à distance humain et lesquelles ne peuvent pas être accomplies. tous.
Ce qui ne peut pas être fait, c'est "ouvrir le sac de chips" car cela nécessite deux bras robotisés (1 seulement par défaut) .
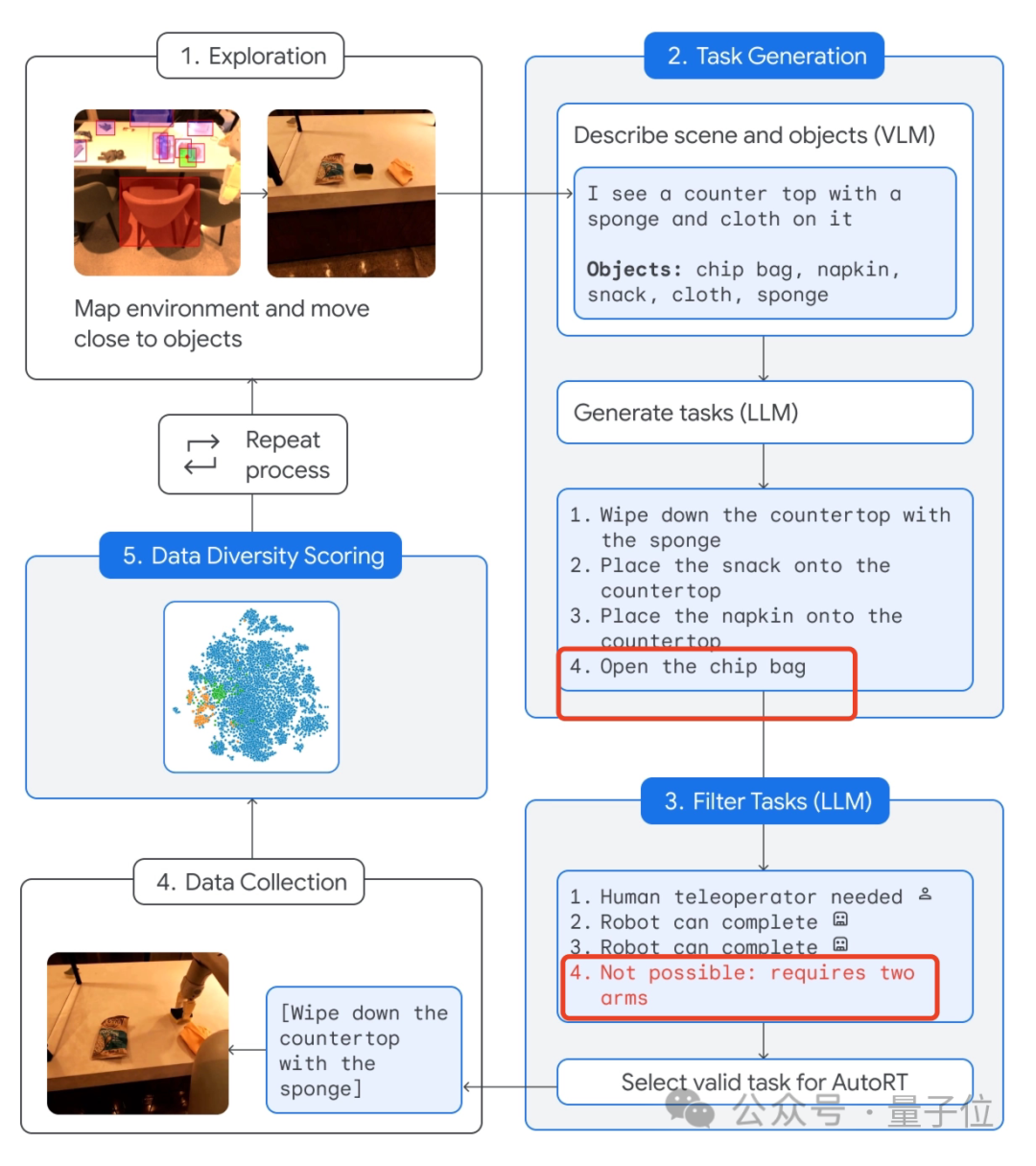
Ensuite, après avoir terminé cette tâche de dépistage, le robot peut réellement l'exécuter.
Enfin, le système AutoRT finalise la collecte de données et effectue une évaluation de la diversité.
Selon les rapports, AutoRT peut coordonner jusqu'à 20 robots à la fois. En 7 mois, un total de 77 000 données de test, dont 6 650 tâches uniques, ont été collectées.
Enfin, pour ce système, Google met également l'accent sur la sécurité.
Après tout, les tâches de collecte d’AutoRT s’appliquent au monde réel et les « garde-corps de sécurité » sont indispensables.
Plus précisément, le code de sécurité de base, fourni par le LLM qui contrôle les tâches des robots, s'inspire en partie des trois lois de la robotique d'Isaac Asimov – avant tout « Un robot ne doit pas nuire à un être humain
La deuxième exigence est. » que le robot ne doit pas tenter de tâches impliquant des humains, des animaux, des objets pointus ou des appareils électriques
Mais cela ne suffit pas
AutoRT est donc également équipé de plusieurs niveaux de mesures de sécurité pratiques dans la robotique ordinaire. Par exemple, le robot s'arrête automatiquement lorsque. la force exercée sur ses articulations dépasse un seuil donné, toutes les actions peuvent être stoppées par des interrupteurs physiques qui restent à la vue humaine, et plus encore
 Envie d'en savoir plus sur cette dernière fournée de résultats de Google
Envie d'en savoir plus sur cette dernière fournée de résultats de Google
Bonne nouvelle, sauf ? pour RT-Trajectory, qui publie uniquement des articles, le reste est publié avec le code et les articles. Vous êtes invités à vérifier plus ~
One More Thing
En parlant des robots Google, nous devons mentionner
RT-2. (Tous les résultats de cet article sont également basés sur cela) Ce modèle a nécessité 7 mois de travail de 54 chercheurs de Google et est sorti fin juillet de cette année
Il intègre le multimodal visuel-texte. modèle VLM, peut non seulement comprendre les « mots humains », mais peut également raisonner sur les « mots humains » et effectuer certaines tâches qui ne peuvent pas être accomplies en une seule étape, comme ramasser avec précision les « animaux disparus » de trois jouets en plastique : des lions, baleines et dinosaures", très étonnant.Maintenant, en un peu plus de 5 mois, il a connu des améliorations rapides de ses capacités de généralisation et de sa vitesse de prise de décision. Nous ne pouvons nous empêcher de soupirer : je ne peux pas imaginer. qu'un robot va vraiment se précipiter dans le monde. À quelle vitesse cela sera-t-il pour des milliers de foyers ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 CentOS8 redémarre SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 redémarre SSH
Apr 14, 2025 pm 09:00 PM
La commande pour redémarrer le service SSH est: SystemCTL Redémarrer SSHD. Étapes détaillées: 1. Accédez au terminal et connectez-vous au serveur; 2. Entrez la commande: SystemCTL Restart SSHD; 3. Vérifiez l'état du service: SystemCTL Status Sshd.
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
