
 Périphériques technologiques
IA
Les fonctionnalités des segments peuvent être apprises en étiquetant une seule image de vidéo, obtenant ainsi des performances entièrement supervisées ! Huake remporte un nouveau SOTA pour la détection de comportement séquentiel
Périphériques technologiques
IA
Les fonctionnalités des segments peuvent être apprises en étiquetant une seule image de vidéo, obtenant ainsi des performances entièrement supervisées ! Huake remporte un nouveau SOTA pour la détection de comportement séquentiel
Les fonctionnalités des segments peuvent être apprises en étiquetant une seule image de vidéo, obtenant ainsi des performances entièrement supervisées ! Huake remporte un nouveau SOTA pour la détection de comportement séquentiel

Comment trouver des extraits intéressants d'une vidéo ? La localisation de l'action temporelle (TAL) est une méthode courante.
Après avoir utilisé le contenu vidéo pour la modélisation, vous pouvez librement rechercher dans toute la vidéo. L'équipe conjointe de l'Université des sciences et technologies de Huazhong et de l'Université du Michigan a récemment apporté de nouveaux progrès à cette technologie - Dans le passé, la modélisation dans TAL se faisait au niveau du segment ou même de l'instance, mais maintenant cela ne prend queune image dans la vidéo Cela peut être réalisé, et l'effet est comparable à une supervision complète.

- Pour le comportement "swing de golf", HR-Pro fait la distinction efficacement entre le comportement et les fragments d'arrière-plan, atténuant ainsi les faux positifs difficiles à gérer avec la prédiction LACP ;
- Pour le comportement de lancer de disque, HR-Pro détecte des segments plus complets que LACP, qui a des valeurs d'activation plus faibles sur les segments d'action non discriminants.
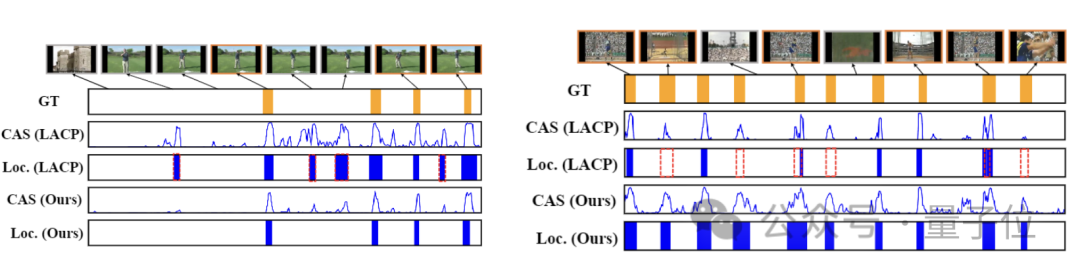 Les résultats des tests sur l'ensemble de données confirment également ce sentiment intuitif.
Les résultats des tests sur l'ensemble de données confirment également ce sentiment intuitif.
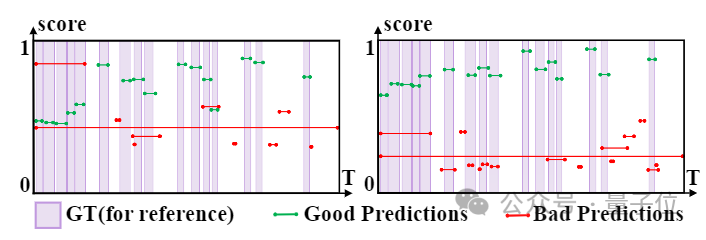
Après avoir visualisé les résultats de détection sur l'ensemble de données THUMOS14, on peut observer qu'après l'apprentissage de l'intégrité au niveau de l'instance, la différence entre les prédictions de haute qualité et les prédictions de faible qualité augmente considérablement.
(Le côté gauche est le résultat avant l'apprentissage de l'intégrité au niveau de l'instance, et le côté droit est le résultat après l'apprentissage. Les axes horizontal et vertical représentent respectivement les scores de temps et de fiabilité.)
 Dans l'ensemble, en général utilisé Dans les 4 ensembles de données, les performances de HR-Pro dépassent largement la méthode de supervision de points de pointe. Le mAP moyen sur l'ensemble de données THUMOS14 atteint 60,3 %, soit une amélioration de 6,5 % par rapport à la méthode SoTA précédente. (53,7 %), et peut-il obtenir des résultats comparables avec certaines méthodes entièrement supervisées.
Dans l'ensemble, en général utilisé Dans les 4 ensembles de données, les performances de HR-Pro dépassent largement la méthode de supervision de points de pointe. Le mAP moyen sur l'ensemble de données THUMOS14 atteint 60,3 %, soit une amélioration de 6,5 % par rapport à la méthode SoTA précédente. (53,7 %), et peut-il obtenir des résultats comparables avec certaines méthodes entièrement supervisées.
Par rapport aux méthodes de pointe précédentes du tableau ci-dessous sur l'ensemble de test THUMOS14, HR-Pro atteint un mAP moyen de 60,3 % pour les seuils IoU compris entre 0,1 et 0,7, soit 6,5 % de plus que le précédent. méthode de pointe CRRC-Net .
Et HR-Pro est capable d'atteindre des performances comparables avec des méthodes concurrentes entièrement supervisées, telles que l'AFSD (le mAP moyen est de 51,1 % contre 52,0 % pour des seuils IoU compris entre 0,3 et 0,7).
 △Comparaison des méthodes HR-Pro et des anciennes méthodes SOTA sur l'ensemble de données THUMOS14
△Comparaison des méthodes HR-Pro et des anciennes méthodes SOTA sur l'ensemble de données THUMOS14
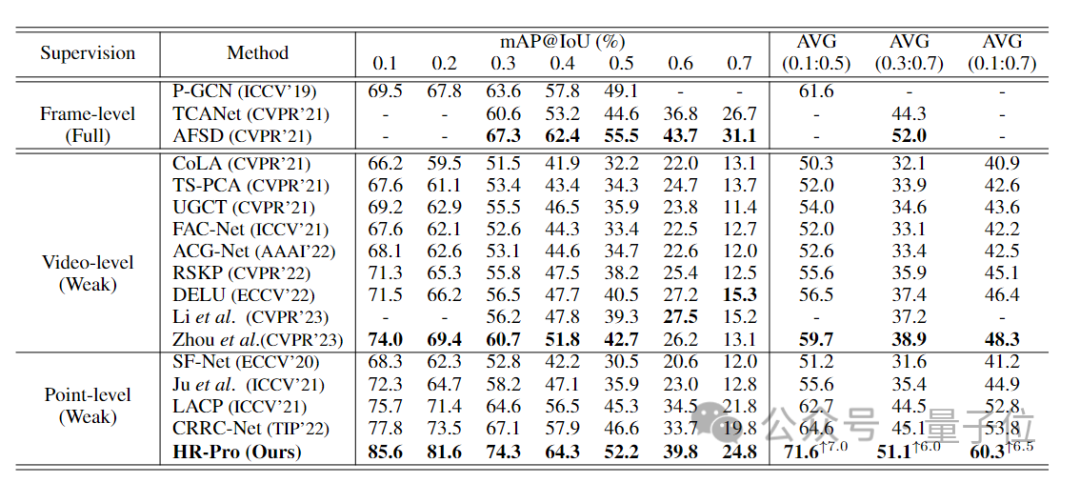 △Comparaison des méthodes HR-Pro et des anciennes méthodes SOTA sur l'ensemble de données THUMOS14
△Comparaison des méthodes HR-Pro et des anciennes méthodes SOTA sur l'ensemble de données THUMOS14HR-Pro est également nettement meilleure que les méthodes existantes en termes de polyvalence et de supériorité sur divers ensembles de données de référence, et dans GTEA, BEOID et ActivityNet 1.3 ont été obtenues des améliorations de 3,8%, 7,6% et 2,0% respectivement.
△Comparaison des méthodes HR-Pro et des anciennes méthodes SOTA sur GTEA et d'autres ensembles de données
 △Comparaison des méthodes HR-Pro et des anciennes méthodes SOTA sur GTEA et d'autres ensembles de données
△Comparaison des méthodes HR-Pro et des anciennes méthodes SOTA sur GTEA et d'autres ensembles de donnéesAlors, comment HR-Pro est-il implémenté ?
L'apprentissage s'effectue en deux étapes
L'équipe de recherche a proposé une méthode de propagation fiable à plusieurs niveaux, introduisant un module de mémoire de fragment fiable au niveau du fragment et utilisant la méthode d'attention croisée pour se propager à d'autres fragments, et proposant la génération de propositions basé sur la supervision ponctuelle au niveau de l'instance. L'association de fragments et d'instances est utilisée pour générer des propositions avec différents niveaux de fiabilité et optimiser davantage la confiance et les limites des propositions au niveau de l'instance.
La structure du modèle de HR-Pro est illustrée dans la figure ci-dessous : La détection du comportement temporel est divisée en un processus d'apprentissage en deux étapes, à savoir
apprentissage discriminant au niveau du fragment et apprentissage d'intégrité au niveau de l'instance. L'équipe de recherche introduit un apprentissage discriminant au niveau des segments sensible à la fiabilité, propose de stocker des prototypes fiables pour chaque catégorie et combine une grande confiance dans ces prototypes via intra-vidéo et inter- méthodes vidéo Les indices de degré sont propagés à d'autres fragments. Construction de prototype fiable au niveau fragment Afin de construire un prototype fiable au niveau fragment, l'équipe a créé une mémoire de prototype mise à jour en ligne pour stocker des prototypes fiables mc de divers comportements (où c = 1, 2, …, C ) pour pouvoir utiliser les informations sur les caractéristiques de l'ensemble de données. L'équipe de recherche a choisi des caractéristiques de segment avec des annotations ponctuelles pour initialiser le prototype : Ensuite, les chercheurs ont utilisé des caractéristiques de segment comportemental pseudo-étiquetées pour mettre à jour les prototypes de chaque catégorie, spécifiquement exprimées comme suit : Optimisation soucieuse de la fiabilité au niveau fragment -attention. L'information est injectée dans d'autres segments, améliorant ainsi la robustesse des caractéristiques du segment et augmentant l'attention sur les segments moins discriminants. Afin d'apprendre des caractéristiques de fragment plus discriminantes, l'équipe a également construit une comparaison de perte de fragment prenant en compte la fiabilité : Phase 2 : Apprentissage de l'intégrité au niveau de l'instance Construction de prototype fiable au niveau de l'instance Afin d'utiliser les informations préalables au niveau de l'instance sur l'annotation de points pendant le processus de formation, l'équipe a proposé une méthode de génération de propositions basée sur l'annotation de points pour générer des propositions avec une fiabilité différente.
, puis utilise des valeurs positives/négatives. exemples de propositions avec L'IoU des propositions fiables est utilisée comme guide pour superviser la prédiction du score d'exhaustivité de la proposition : Afin d'obtenir une proposition de comportement de limite plus précise, le chercheur saisit les caractéristiques de la région de départ et les caractéristiques de la région de fin. de la proposition dans chaque PP dans la régression Dans la tête de prédiction φr, décalez l'heure de début et de fin de la proposition prédite. Calculez davantage les propositions affinées et espérez que les propositions affinées coïncideront avec les propositions fiables. En bref, HR-Pro peut obtenir d'excellents résultats avec seulement quelques annotations, réduisant considérablement le coût d'obtention des étiquettes, et possède en même temps de fortes capacités de généralisation, ce qui le rend adapté à un déploiement réel. candidatures Des conditions favorables sont fournies. Selon cela, l'auteur prédit que HR-Pro aura de larges perspectives d'application dans les domaines de l'analyse du comportement, de l'interaction homme-machine et de l'analyse de la conduite. Adresse papier : https://arxiv.org/abs/2308.12608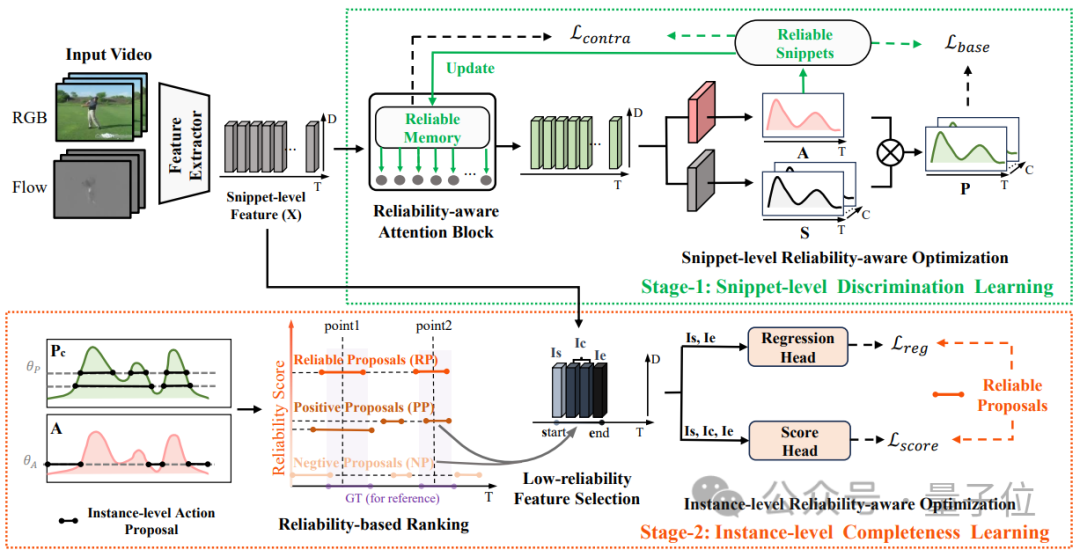
Phase 1 : Apprentissage discriminatif au niveau des segments
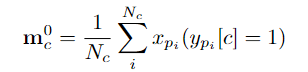
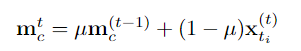
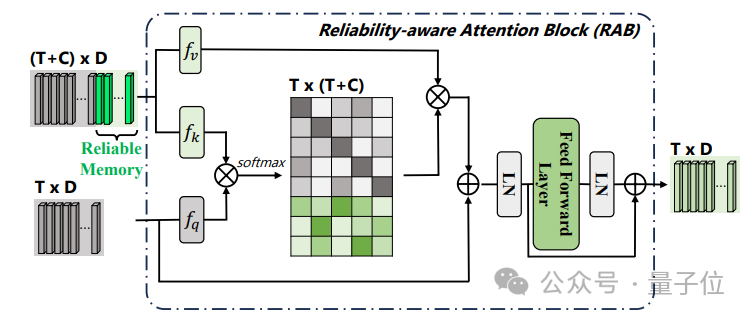
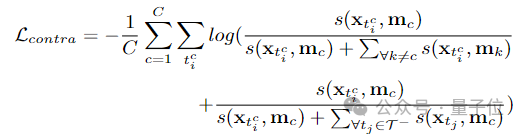
Pour prédire le score d'exhaustivité de chaque proposition, l'équipe de recherche saisit les caractéristiques de la proposition des limites sensibles dans la tête de prédiction du score φs : 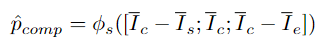
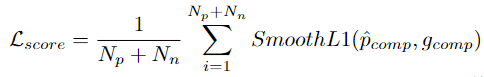
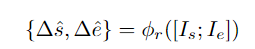
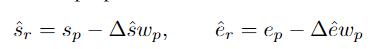
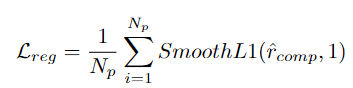
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
