
 Périphériques technologiques
IA
La recherche en IA peut-elle aussi tirer des leçons de l'impressionnisme ? Ces personnes réalistes sont en réalité des modèles 3D
Périphériques technologiques
IA
La recherche en IA peut-elle aussi tirer des leçons de l'impressionnisme ? Ces personnes réalistes sont en réalité des modèles 3D
La recherche en IA peut-elle aussi tirer des leçons de l'impressionnisme ? Ces personnes réalistes sont en réalité des modèles 3D


Le 19ème siècle était la période où le mouvement artistique impressionniste était populaire. Le mouvement était influent dans les domaines de la peinture, de la sculpture, de la gravure et d'autres arts. L'impressionnisme était caractérisé par l'utilisation de coups de pinceau courts et saccadés avec peu de recherche de précision formelle, qui ont ensuite évolué vers le style artistique impressionniste. En bref, les coups de pinceau de l'artiste impressionniste sont inchangés, présentent des caractéristiques évidentes, ne recherchent pas la précision formelle et sont même quelque peu vagues. Les artistes impressionnistes ont introduit les concepts scientifiques de lumière et de couleur dans leurs peintures et ont révolutionné les concepts de couleurs traditionnels.
Dans D3GA, l'auteur a un objectif unique : il espère créer un effet de performance photo-réaliste en faisant le contraire. Afin d'atteindre cet objectif, l'auteur a utilisé de manière créative la technologie d'éclaboussure gaussienne dans D3GA comme un « coup de pinceau segmenté » moderne pour construire la structure et l'apparence des personnages virtuels et obtenir un effet stable et en temps réel.

"Sunrise·Impression" est l'œuvre représentative du célèbre peintre impressionniste Monet.

Afin de créer des images humaines réalistes pouvant générer de nouveaux contenus pour l'animation, la construction d'avatars nécessite actuellement une grande quantité de données multi-vues. En effet, les méthodes monoculaires ont une précision limitée. De plus, les techniques existantes nécessitent un prétraitement complexe, notamment un repérage 3D précis. Cependant, l’obtention de ces données d’enregistrement nécessite une itération et est difficile à intégrer dans un processus de bout en bout. De plus, il existe des méthodes qui ne nécessitent pas d'enregistrement précis et qui sont basées sur les champs de rayonnement neuronal (NeRF). Cependant, ces méthodes sont souvent lentes lors du rendu en temps réel ou rencontrent des difficultés avec l'animation des vêtements.
Kerbl et al. ont proposé une méthode de rendu appelée 3D Gaussian Splatting (3DGS), qui est améliorée sur la base de la méthode de rendu classique Surface Splatting. Comparé aux méthodes de pointe basées sur les champs de rayonnement neuronal, le 3DGS est capable de restituer des images de meilleure qualité à des fréquences d'images plus rapides et sans nécessiter une initialisation 3D très précise.
Cependant, 3DGS a été initialement conçu pour les scènes statiques. À l'heure actuelle, certaines personnes ont proposé la méthode Gaussian Splating basée sur des conditions temporelles, qui peut être utilisée pour restituer des scènes dynamiques. Cette méthode ne peut restituer que ce qui a été observé précédemment et n'est donc pas adaptée pour exprimer un mouvement nouveau ou inédit.
Sur la base du champ de rayonnement neuronal piloté, l'auteur modélise l'apparence et la déformation d'humains 3D, en les plaçant dans un espace normalisé, mais en utilisant des gaussiennes 3D au lieu de champs de rayonnement. En plus de meilleures performances, le Splatting gaussien élimine le besoin d’utiliser l’heuristique d’échantillonnage des rayons de la caméra.
Le problème restant est de définir les signaux qui déclenchent ces déformations de cage. Les technologies de pointe actuelles en matière d'avatars basés sur des pilotes nécessitent des signaux d'entrée denses, tels que des images RVB-D ou même plusieurs caméras, mais ces méthodes peuvent ne pas convenir aux situations où la bande passante de transmission est relativement faible. Dans cette étude, les auteurs utilisent des données plus compactes basées sur des poses humaines, notamment des angles d'articulations squelettiques et des points clés du visage 3D sous forme de quaternions.
En entraînant des modèles spécifiques à chaque individu sur neuf séquences multi-vues de haute qualité couvrant une variété de formes corporelles, de mouvements et de vêtements (sans se limiter aux vêtements intimes), nous pouvons ensuite créer de nouvelles poses pour n'importe quel sujet.
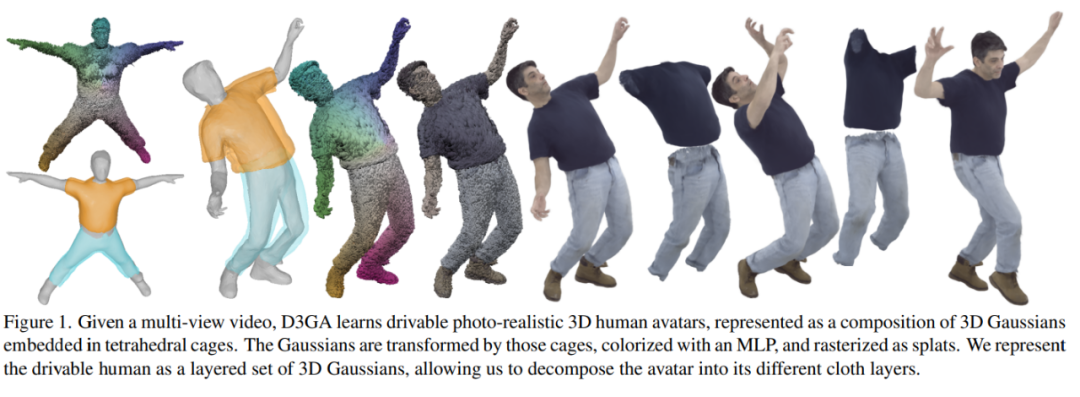

Aperçu de la méthode

- Lien papier : https://arxiv.org/pdf/2311.08581.pdf
- Lien du projet : https://zielon.github.io/d3ga/
Méthodes actuellement utilisées pour volumétriquer dynamiquement les personnages virtuels, soit mapper les points de l'espace de déformation à l'espace canonique, soit s'appuyer uniquement sur le mappage direct. Les méthodes basées sur le back-mapping ont tendance à accumuler des erreurs dans l'espace canonique car elles nécessitent un back-pass sujet aux erreurs et sont problématiques dans la modélisation des effets dépendants de la perspective.
Par conséquent, l'auteur a décidé d'adopter la méthode de cartographie directe uniquement. D3GA est basé sur 3DGS et étendu via une représentation neuronale et une cage pour modéliser respectivement la couleur et la forme géométrique de chaque partie dynamique du personnage virtuel.
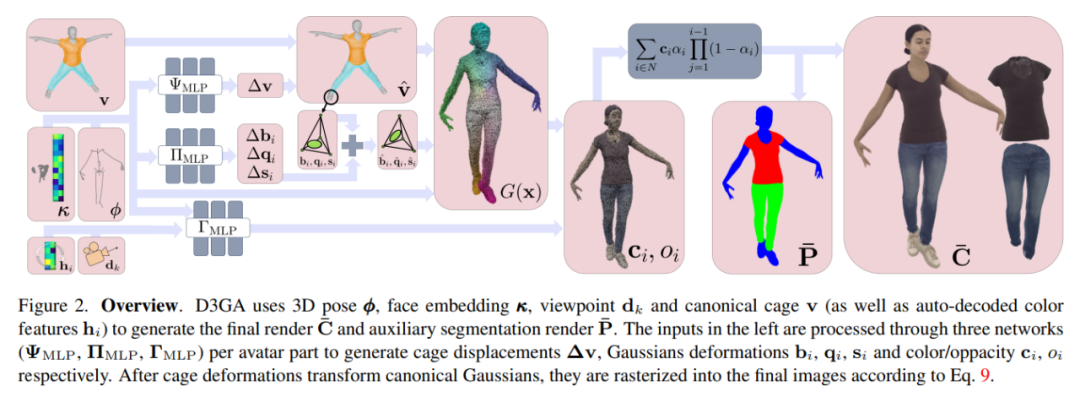
D3GA utilise la pose 3D ϕ, l'intégration du visage κ, le point de vue dk et la cage canonique v (et les caractéristiques de couleur décodées automatiquement hi) pour générer le rendu final C¯ et le rendu de segmentation auxiliaire P¯. L'entrée de gauche est traitée via trois réseaux (ΨMLP, ΠMLP, ΓMLP) par partie de personnage virtuel pour générer un déplacement de cage Δv, des déformations gaussiennes bi, qi, si et une couleur/transparence ci, oi.
Une fois que la déformation en cage a déformé la gaussienne canonique, elles sont pixellisées dans l'image finale via l'équation 9.
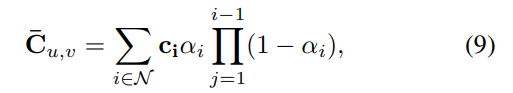
Résultats expérimentaux
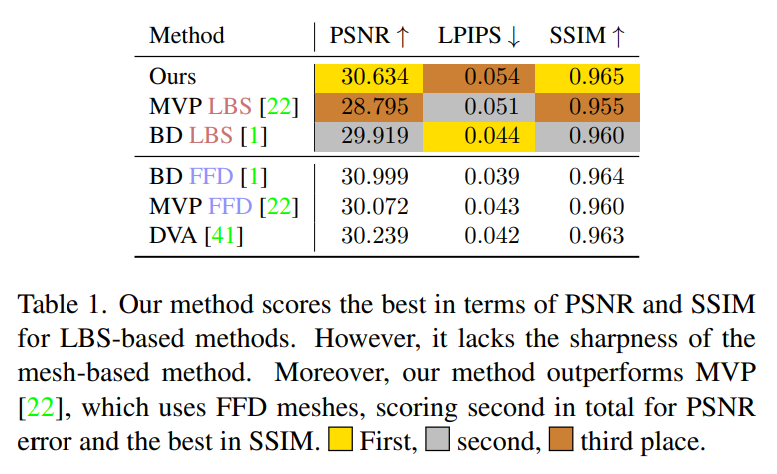
D3GA est évalué sur des métriques telles que SSIM, PSNR et la métrique perceptuelle LPIPS. Le tableau 1 montre que D3GA a les meilleures performances en PSNR et SSIM parmi les méthodes qui utilisent uniquement LBS (c'est-à-dire qu'il n'est pas nécessaire de numériser les données 3D pour chaque image) et surpasse toutes les méthodes FFD dans ces indicateurs, juste derrière pour BD. FFD, malgré son mauvais signal d'entraînement et l'absence d'images de test (le DVA a été testé avec les 200 caméras).
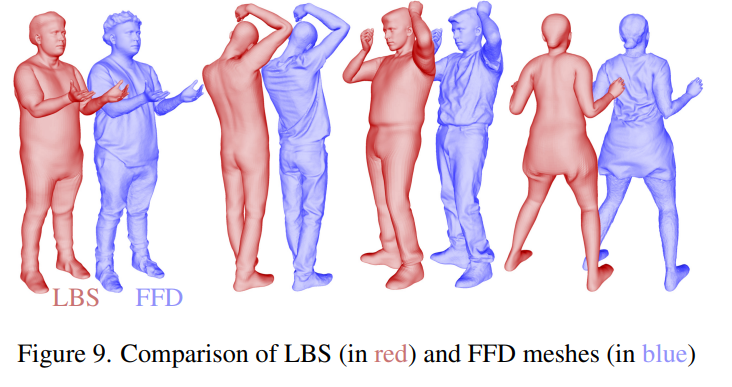
La comparaison qualitative montre que D3GA peut mieux modéliser les vêtements que d'autres méthodes de pointe, en particulier les vêtements amples comme les jupes ou les pantalons de survêtement (Figure 4). FFD signifie Free Deformation Mesh, qui contient des signaux d'entraînement plus riches que les maillages LBS (Figure 9).

Par rapport à sa méthode basée sur le volume, la méthode de l'auteur peut séparer les vêtements du personnage virtuel, et les vêtements sont également pilotables. La figure 5 montre que chaque couche de vêtement individuelle peut être contrôlée uniquement par les angles d'articulation osseuse, sans nécessiter un module d'enregistrement de vêtement spécifique.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
