
 Périphériques technologiques
IA
Modèle de prédiction de réponse de bout en bout sans modèle basé sur des tâches doubles
Périphériques technologiques
IA
Modèle de prédiction de réponse de bout en bout sans modèle basé sur des tâches doubles
Modèle de prédiction de réponse de bout en bout sans modèle basé sur des tâches doubles


Reformaté|
Lien papier : https://doi.org/10.1007/s10489-023-05048-8Code associé : https://github.com/AILBC/BiG2S L'auteur utilise un diagramme de l'essor actuel dans le domaine de la rétrosynthèse sans modèle. Sur la base du cadre du modèle de séquence, nous essayons en outre de construire un modèle BiG2S (Bidirectionnel Graph to Sequence) qui résout simultanément les tâches de prédiction de rétrosynthèse et de prédiction de réaction directe en un seul modèle à la même échelle de paramètres Dans le même temps, l'auteur étudie également l'inverse principal. Une analyse préliminaire a été menée sur l'ensemble de données synthétiques USPTO-50k pour explorer la différence de difficulté de prédiction des différents segments SMILES au cours du processus de formation et de la fluctuation. du taux de correspondance Top-k du modèle sur l'ensemble de validation. Une perte de déséquilibre a été introduite pour résoudre ces problèmes de fonction et des stratégies améliorées de recherche d'ensemble de modèles et de faisceaux
L'auteur utilise un diagramme de l'essor actuel dans le domaine de la rétrosynthèse sans modèle. Sur la base du cadre du modèle de séquence, nous essayons en outre de construire un modèle BiG2S (Bidirectionnel Graph to Sequence) qui résout simultanément les tâches de prédiction de rétrosynthèse et de prédiction de réaction directe en un seul modèle à la même échelle de paramètres Dans le même temps, l'auteur étudie également l'inverse principal. Une analyse préliminaire a été menée sur l'ensemble de données synthétiques USPTO-50k pour explorer la différence de difficulté de prédiction des différents segments SMILES au cours du processus de formation et de la fluctuation. du taux de correspondance Top-k du modèle sur l'ensemble de validation. Une perte de déséquilibre a été introduite pour résoudre ces problèmes de fonction et des stratégies améliorées de recherche d'ensemble de modèles et de faisceaux
Les premiers systèmes de planification rétrosynthétiques reposaient directement sur des informations fournies par des experts du domaine Règles de réaction, ou calculs basés sur la physico-chimie, avec le développement rapide du deep learning. La méthode dominante actuelle dans le domaine consiste à créer un cadre de réseau neuronal spécifique à une tâche pour mener à bien la tâche de prédiction des réactions dans une perspective basée sur les données. Parmi elles, la méthode sans modèle, qui ne repose pas sur des connaissances chimiques préalables spécifiques, est progressivement devenue l'une des principales directions de développement dans le domaine grâce à sa simplicité et sa flexibilité similaires à celles de la traduction automatique de bout en bout.
Actuellement, l'entrée et la sortie de la plupart des modèles rétrosynthétiques sans modèle sont des chaînes de molécules SMILES, c'est-à-dire utilisant un processus séquence à séquence (Seq2Seq). Cette méthode peut faire bon usage du cadre de modèle existant dans le domaine du traitement du langage naturel, ainsi que du flux de traitement de données mature pour la méthode de représentation SMILES. Cependant, puisque SMILES en tant que séquence de chaînes unidimensionnelle ne peut pas bien représenter et utiliser le. les informations structurelles bidimensionnelles/tridimensionnelles contenues dans les graphiques moléculaires, les méthodes graphique à séquence (Graph2Seq) qui utilisent des graphiques moléculaires au lieu de SMILES comme entrée de modèle émergent progressivement dans ce domaine, ou les informations structurelles supplémentaires des graphiques moléculaires sont intégrées en séquences SMILES. Les deux méthodes peuvent faire bon usage des riches caractéristiques structurelles des graphes moléculaires
Sur cette base, cet article est basé sur la méthode émergente graphique-séquence et entraîne simultanément les tâches de rétrosynthèse et de prédiction de réaction directe sur le modèle original basé sur SMILES. Sur la base des références d'exploration pertinentes, nous explorons plus en détail la construction et les expériences de ce type de modèle à double tâche, et explorons et analysons également de manière préliminaire le déséquilibre de difficulté et les fluctuations du taux de correspondance Top-k affichés par le modèle au cours du processus de formation. ;Le modèle BiG2S construit sur cette base peut mieux gérer les tâches de rétrosynthèse et de prédiction de réaction directe dans les ensembles de données courants, et atteint des capacités de prédiction de réaction cohérentes avec d'autres modèles de rétrosynthèse sans modèle sans utiliser d'amélioration des données
Le cadre global doit être réécrit
La structure globale de BiG2S est un codeur-décodeur de bout en bout, comme le montre la figure 1. Le côté codeur utilise un réseau graphique local de transmission de messages dirigés et un transformateur graphique global qui intègre des informations de biais de structure graphique pour générer la représentation finale du nœud du graphique moléculaire. Le décodeur utilise un décodeur Transformer standard pour générer la séquence SMILES de la molécule cible de manière autorégressive. Il convient de noter que afin d'apprendre simultanément la rétrosynthèse et la prédiction de la réaction directe, l'entrée du décodeur contient en outre un double- séquences de chiffres sans ajouter d’informations de position. Dans le même temps, la couche de normalisation et la couche linéaire finale côté décodeur ont deux ensembles de paramètres, qui sont utilisés respectivement pour apprendre la tâche de rétrosynthèse et la tâche de prédiction de réaction directe
Figure 1 : Schéma du cadre global du BiG2SNécessite un cadre de formation à double tâche
La rétrosynthèse et la prédiction de la réaction directe sont deux tâches liées. La tâche de rétrosynthèse utilise des produits comme entrée et des réactifs comme sortie cible, tandis que la tâche de prédiction de la réaction directe fait le contraire. Il existe un lien étroit entre ces deux tâches, car elles peuvent être transformées en une tâche de prédiction de réaction directe en échangeant l'entrée et la sortie cible de la tâche de rétrosynthèse
Par conséquent, certains modèles sans modèle basés sur SMILES ont essayé de synthétiser et de transmettre la prédiction des réactions est utilisée comme objectif de formation pour améliorer la compréhension des réactions chimiques et obtenir certains résultats. Sur la base de cette idée, l'auteur a en outre tenté d'introduire une formation à double tâche dans le modèle graphe-séquence
Plus précisément, l'auteur s'est basé sur la stratégie de partage de paramètres précédemment utilisée sur d'autres méthodes, dans la couche de normalisation du décodeur et dans le couche linéaire finale Deux ensembles de paramètres spécifiques à la tâche sont construits. Dans d'autres modules, les deux types de tâches partagent un ensemble de paramètres. Dans le même temps, des étiquettes supplémentaires à double tâche sont ajoutées aux nœuds du graphique moléculaire d’entrée et à la séquence d’entrée initiale du décodeur. De cette façon, même en contrôlant la taille globale du modèle, le modèle est capable de distinguer les deux types de tâches et d'apprendre leurs différentes distributions de données. et analysé les deux types de problèmes du modèle reflétés dans le processus de formation
Tout d'abord, l'auteur a enregistré la fréquence d'apparition de différents caractères SMILES dans USPTO-50k et leur précision de prédiction correspondante pendant la formation, comme le montre la figure 2. Au cours du processus de formation, pour S et Br, qui représentaient respectivement 0,4 % et 0,3 % dans l'ensemble de formation, la différence absolue dans la précision globale de la prédiction a atteint 8 %. Cela montre initialement qu'il existe des différences évidentes dans la difficulté de prédiction entre les différentes structures/fragments moléculaires. Par conséquent, l'auteur atténue ces problèmes en introduisant une fonction de perte déséquilibrée (telle que la perte focale), afin que le modèle puisse accorder plus d'attention à la fonction de perte. précision pendant l'entraînement. Fragments moléculaires inférieurs
Figure 2 : Dans l'ensemble d'entraînement USPTO-50k, la fréquence d'apparition de différents caractères SMILES et leur précision globale de prédiction pendant l'entraînementDe plus, l'auteur a également enregistré la validation de le modèle pendant la formation La qualité des résultats de prédiction de l'ensemble change, comme le montre la figure 3. L'auteur a constaté qu'au milieu et à la fin des étapes de formation de l'ensemble de données USPTO-50k, la précision Top-1 du modèle sur l'ensemble de validation s'améliorait encore, mais il y avait une baisse de la qualité de prédiction du Top-3, Top-5. , et Top-10 Diminution significative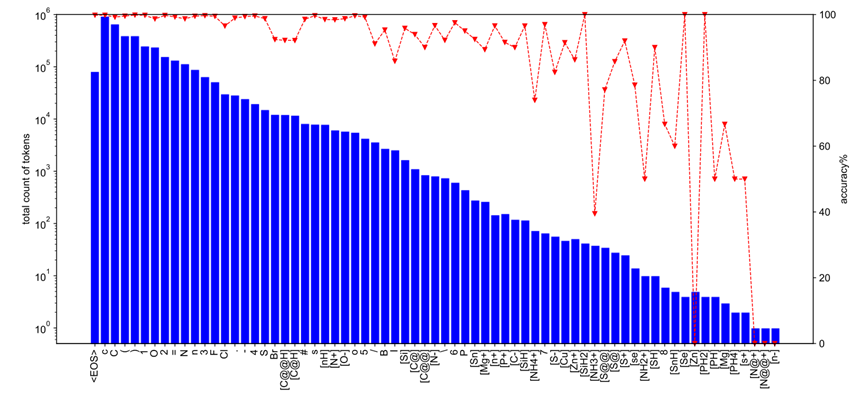 Afin d'améliorer la qualité de prédiction top 1 du modèle tout en maintenant la qualité globale des dix principaux résultats de génération de réactifs du modèle, nous avons en outre construit un type de stratégie d'intégration de modèle basée sur des indicateurs d'évaluation personnalisés . Plus précisément, nous construisons une file d'attente pour stocker les modèles et trions les modèles stockés selon des indicateurs d'évaluation prédéfinis (tels que la précision Top-1, la précision pondérée Top-k, etc.). Tout au long du processus de formation, nous stockons dynamiquement les modèles candidats et générons automatiquement des modèles d'ensemble basés sur les 3 à 5 premiers de la file d'attente, conservant ainsi les modèles Top-k avec la qualité de prédiction la plus élevée. Dans la phase d'inférence, nous avons également reconstruit la stratégie de recherche de faisceau basée sur le nouveau cadre et nous sommes davantage concentrés sur l'étendue de la recherche pour améliorer la qualité globale des résultats générés par le modèle Top-k
Afin d'améliorer la qualité de prédiction top 1 du modèle tout en maintenant la qualité globale des dix principaux résultats de génération de réactifs du modèle, nous avons en outre construit un type de stratégie d'intégration de modèle basée sur des indicateurs d'évaluation personnalisés . Plus précisément, nous construisons une file d'attente pour stocker les modèles et trions les modèles stockés selon des indicateurs d'évaluation prédéfinis (tels que la précision Top-1, la précision pondérée Top-k, etc.). Tout au long du processus de formation, nous stockons dynamiquement les modèles candidats et générons automatiquement des modèles d'ensemble basés sur les 3 à 5 premiers de la file d'attente, conservant ainsi les modèles Top-k avec la qualité de prédiction la plus élevée. Dans la phase d'inférence, nous avons également reconstruit la stratégie de recherche de faisceau basée sur le nouveau cadre et nous sommes davantage concentrés sur l'étendue de la recherche pour améliorer la qualité globale des résultats générés par le modèle Top-k
Nécessite un ensemble de données de référence dans une expérience à double tâche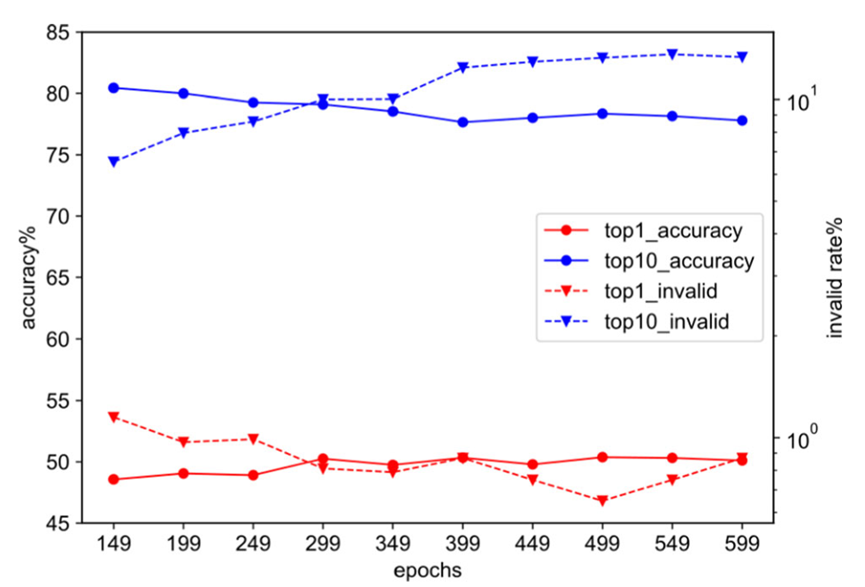
Dans l'ensemble de données à petite échelle, BiG2S a atteint une précision de prédiction de premier plan dans la tâche de rétrosynthèse basée sur un entraînement à deux tâches, tout en conservant une précision de prédiction de réaction directe élevée, mais elle était biaisée ; vers la réaction positive. Dans l'ensemble de données USPTO-MIT pour la prédiction de la réaction et l'ensemble de données à grande échelle USPTO-full, en raison de la limitation de la quantité globale de paramètres du modèle, les performances du modèle après un entraînement à double tâche ont diminué. Néanmoins, la capacité de traiter simultanément la tâche de rétrosynthèse et la tâche de prédiction de réaction directe a été obtenue à partir du modèle à double tâche avec presque le même nombre de paramètres et une légère réduction de la capacité de prédiction de réponse (la différence absolue de précision Top-k est d'environ 0,5 %). Du point de vue des capacités, le modèle BiG2S a atteint les objectifs attendus
Figure 4 : Résultats expérimentaux du modèle double tâche et du modèle monotâche de BiG2S sur trois ensembles de données de référence, où l'exposant b indique l'utilisation d'une tâche unique Le modèle effectue respectivement deux types de tâchesRéanalyser l'expérience d'ablation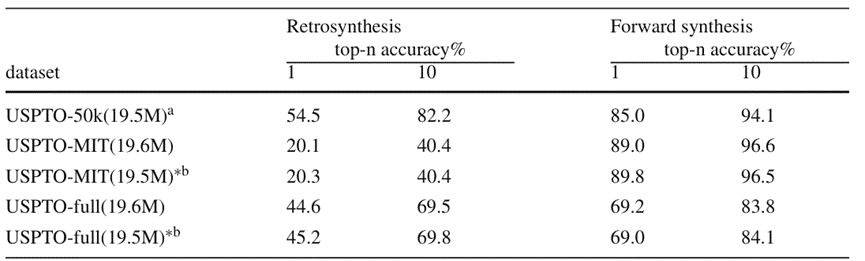
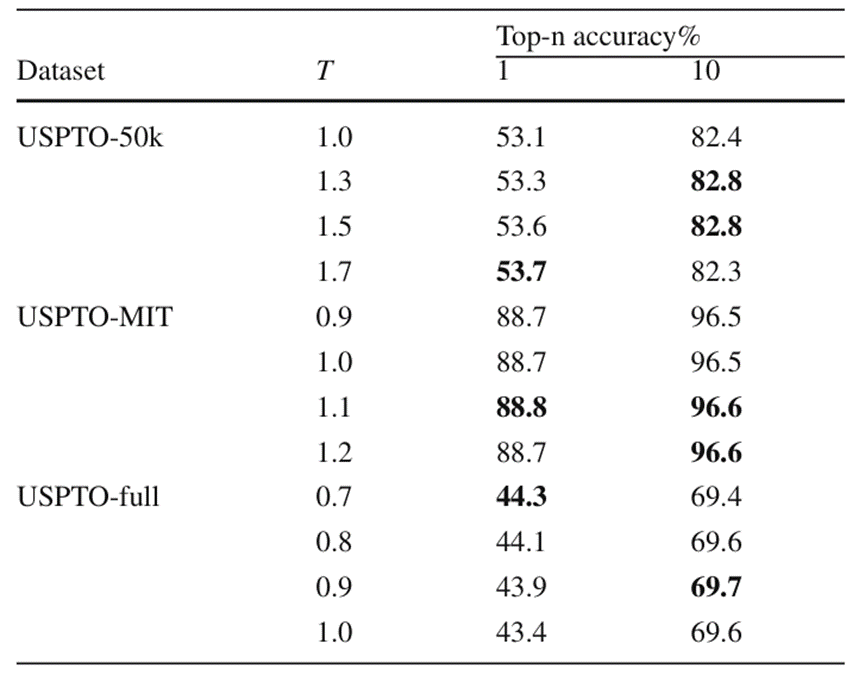
L'auteur a en outre vérifié le nouvel algorithme de recherche de faisceau et les hyperparamètres de température optimaux du BiG2S lors de la prévision dans différents ensembles de données après avoir utilisé la perte de déséquilibre grâce à des expériences d'ablation. L'hyperparamètre de température fait ici référence au paramètre de température T utilisé dans Softmax pour contrôler la distribution de probabilité de sortie. Les résultats expérimentaux sont présentés dans les figures 5 et 6.
Dans l'expérience sur l'algorithme de recherche de faisceau, on peut observer qu'OpenNMT a étendu la largeur de recherche à 3 fois tandis que le temps de recherche n'a augmenté qu'à 1,74 fois, tandis que la nouvelle recherche de faisceau algorithme Lorsque la précision Top-1 est cohérente avec OpenNMT, le temps de recherche global augmente de 1 à 2 fois, mais en termes de qualité des résultats de prédiction Top-10, le nouvel algorithme de recherche de faisceau présente un avantage absolu en termes de précision d'au moins ; 3 % par rapport à OpenNMT En plus d'un avantage de rapport moléculaire effectif de 2 %, on peut dire que le nouvel algorithme de recherche de faisceaux a considérablement amélioré la qualité des résultats globaux de recherche Top-k du modèle au détriment du temps de recherche.
Lors de leurs expériences sur les hyperparamètres de température, les chercheurs ont découvert que l'utilisation de paramètres de température plus grands sur des ensembles de données à petite échelle pouvait améliorer considérablement la précision globale de la prédiction Top-k. Dans des ensembles de données plus grands, étant donné que la taille du modèle BiG2S ne peut pas s'adapter complètement à toutes les données de réaction, le choix de paramètres de température plus petits à ce moment-là aide souvent la recherche du modèle

La conclusion de l'étude montre...
Dans cet article, les auteurs proposent un modèle de prédiction de réaction sans modèle appelé BiG2S, qui peut gérer simultanément la tâche de rétrosynthèse et la tâche de prédiction de réponse directe . En adoptant une stratégie de partage de paramètres appropriée et des étiquettes supplémentaires à double tâche, BiG2S est capable d'effectuer des tâches de rétrosynthèse et des tâches de prédiction de réactions sur des ensembles de données de différentes tailles avec un plus petit nombre de paramètres, et sa capacité de prédiction globale est comparable aux modèles traditionnels
Pour résoudre les problèmes de difficulté de prédiction inégale de différents caractères SMILES et de fluctuations de la précision de prédiction Top-k pendant la formation du modèle, l'auteur a introduit la perte de déséquilibre, une stratégie d'intégration automatique du modèle basée sur des indicateurs d'évaluation personnalisés et un algorithme de recherche de faisceau basé sur un nouveau cadre pour atténuer ces problèmes.
BiG2S a montré de bonnes capacités de prédiction à double tâche sur trois ensembles de données grand public de différentes tailles, et d'autres expériences d'ablation ont également prouvé l'efficacité des stratégies de formation et d'inférence supplémentaires introduites
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Dans la fabrication moderne, une détection précise des défauts est non seulement la clé pour garantir la qualité des produits, mais également la clé de l’amélioration de l’efficacité de la production. Cependant, les ensembles de données de détection de défauts existants manquent souvent de précision et de richesse sémantique requises pour les applications pratiques, ce qui rend les modèles incapables d'identifier des catégories ou des emplacements de défauts spécifiques. Afin de résoudre ce problème, une équipe de recherche de premier plan composée de l'Université des sciences et technologies de Hong Kong, Guangzhou et de Simou Technology a développé de manière innovante l'ensemble de données « DefectSpectrum », qui fournit une annotation à grande échelle détaillée et sémantiquement riche des défauts industriels. Comme le montre le tableau 1, par rapport à d'autres ensembles de données industrielles, l'ensemble de données « DefectSpectrum » fournit le plus grand nombre d'annotations de défauts (5 438 échantillons de défauts) et la classification de défauts la plus détaillée (125 catégories de défauts).
 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les tâches de langage visuel.
 Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Pour l’IA, l’Olympiade mathématique n’est plus un problème. Jeudi, l'intelligence artificielle de Google DeepMind a réalisé un exploit : utiliser l'IA pour résoudre la vraie question de l'Olympiade mathématique internationale de cette année, l'OMI, et elle n'était qu'à un pas de remporter la médaille d'or. Le concours de l'OMI qui vient de se terminer la semaine dernière comportait six questions portant sur l'algèbre, la combinatoire, la géométrie et la théorie des nombres. Le système d'IA hybride proposé par Google a répondu correctement à quatre questions et a marqué 28 points, atteignant le niveau de la médaille d'argent. Plus tôt ce mois-ci, le professeur titulaire de l'UCLA, Terence Tao, venait de promouvoir l'Olympiade mathématique de l'IA (AIMO Progress Award) avec un prix d'un million de dollars. De manière inattendue, le niveau de résolution de problèmes d'IA s'était amélioré à ce niveau avant juillet. Posez les questions simultanément sur l'OMI. La chose la plus difficile à faire correctement est l'OMI, qui a la plus longue histoire, la plus grande échelle et la plus négative.
 Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Editeur | KX À ce jour, les détails structurels et la précision déterminés par cristallographie, des métaux simples aux grandes protéines membranaires, sont inégalés par aucune autre méthode. Cependant, le plus grand défi, appelé problème de phase, reste la récupération des informations de phase à partir d'amplitudes déterminées expérimentalement. Des chercheurs de l'Université de Copenhague au Danemark ont développé une méthode d'apprentissage en profondeur appelée PhAI pour résoudre les problèmes de phase cristalline. Un réseau neuronal d'apprentissage en profondeur formé à l'aide de millions de structures cristallines artificielles et de leurs données de diffraction synthétique correspondantes peut générer des cartes précises de densité électronique. L'étude montre que cette méthode de solution structurelle ab initio basée sur l'apprentissage profond peut résoudre le problème de phase avec une résolution de seulement 2 Angströms, ce qui équivaut à seulement 10 à 20 % des données disponibles à la résolution atomique, alors que le calcul ab initio traditionnel
 Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Editeur | ScienceAI Sur la base de données cliniques limitées, des centaines d'algorithmes médicaux ont été approuvés. Les scientifiques se demandent qui devrait tester les outils et comment le faire au mieux. Devin Singh a vu un patient pédiatrique aux urgences subir un arrêt cardiaque alors qu'il attendait un traitement pendant une longue période, ce qui l'a incité à explorer l'application de l'IA pour réduire les temps d'attente. À l’aide des données de triage des salles d’urgence de SickKids, Singh et ses collègues ont construit une série de modèles d’IA pour fournir des diagnostics potentiels et recommander des tests. Une étude a montré que ces modèles peuvent accélérer les visites chez le médecin de 22,3 %, accélérant ainsi le traitement des résultats de près de 3 heures par patient nécessitant un examen médical. Cependant, le succès des algorithmes d’intelligence artificielle dans la recherche ne fait que le vérifier.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
Editeur | Radis Skin Depuis la sortie du puissant AlphaFold2 en 2021, les scientifiques utilisent des modèles de prédiction de la structure des protéines pour cartographier diverses structures protéiques dans les cellules, découvrir des médicaments et dresser une « carte cosmique » de chaque interaction protéique connue. Tout à l'heure, Google DeepMind a publié le modèle AlphaFold3, capable d'effectuer des prédictions de structure conjointe pour des complexes comprenant des protéines, des acides nucléiques, de petites molécules, des ions et des résidus modifiés. La précision d’AlphaFold3 a été considérablement améliorée par rapport à de nombreux outils dédiés dans le passé (interaction protéine-ligand, interaction protéine-acide nucléique, prédiction anticorps-antigène). Cela montre qu’au sein d’un cadre unique et unifié d’apprentissage profond, il est possible de réaliser
