
 Périphériques technologiques
IA
Application de la méthode de correction de cause à effet dans le scénario de recommandation Ant Marketing
Périphériques technologiques
IA
Application de la méthode de correction de cause à effet dans le scénario de recommandation Ant Marketing
Application de la méthode de correction de cause à effet dans le scénario de recommandation Ant Marketing

1. Contexte du biais causal
1. Génération de biais
Dans le système de recommandation, le modèle de recommandation est formé en collectant des données pour recommander des éléments appropriés aux utilisateurs. Lorsque les utilisateurs interagissent avec les éléments recommandés, les données collectées sont utilisées pour entraîner davantage le modèle, formant ainsi une boucle fermée. Cependant, il peut y avoir divers facteurs d'influence dans cette boucle fermée, entraînant des erreurs. La principale raison de l'erreur est que la plupart des données utilisées pour entraîner le modèle sont des données d'observation plutôt que des données d'entraînement idéales, qui sont affectées par des facteurs tels que la stratégie d'exposition et la sélection des utilisateurs. L’essence de ce biais réside dans la différence entre les attentes des estimations empiriques du risque et les attentes des véritables estimations du risque idéal.

2. Biais courants
Les biais les plus courants dans le système de marketing de recommandation incluent principalement les trois types suivants :
- Biais sélectif : c'est parce que les utilisateurs choisissent activement d'interagir en fonction de leurs propres préférences causées par l'article.
- Biais d'exposition : les éléments recommandés ne sont généralement qu'un sous-ensemble du pool global d'éléments candidats. Les utilisateurs ne peuvent interagir qu'avec les éléments recommandés par le système lors de la sélection, ce qui entraîne un biais dans les données d'observation.
- Biais de popularité : la proportion élevée de certains éléments populaires dans les données d'entraînement amène le modèle à apprendre cette performance et à recommander des éléments plus populaires, provoquant l'effet Matthew.
Il existe d'autres écarts, tels que l'écart de position, l'écart de cohérence, etc.
3. Correction causale
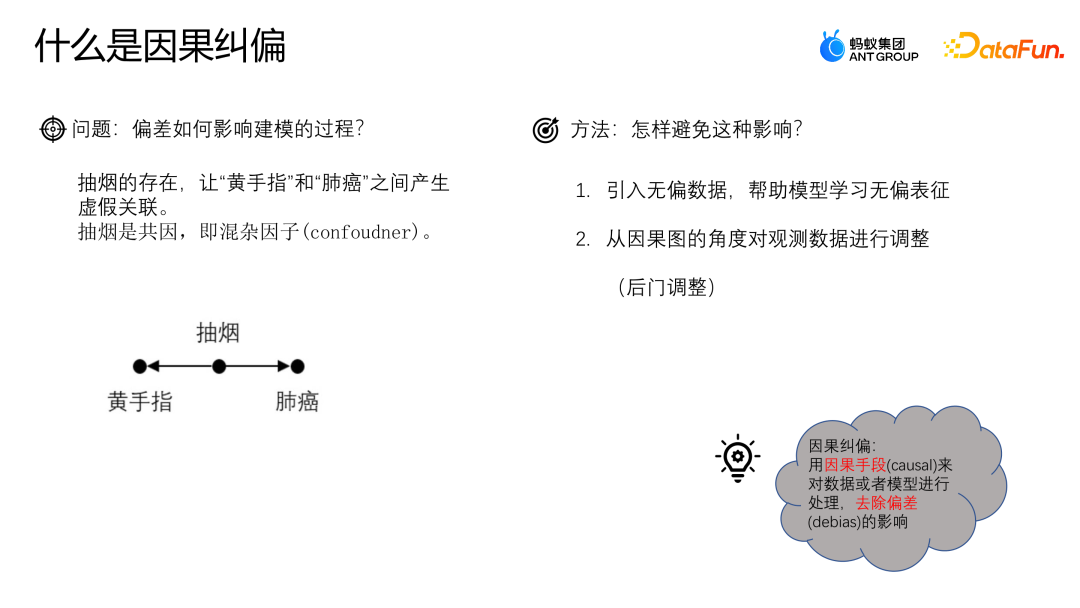
Utilisons un exemple pour comprendre l'impact de l'écart sur le processus de modélisation. Supposons que nous souhaitions étudier la relation entre la consommation de café et les maladies cardiaques. Nous avons constaté que les buveurs de café sont plus susceptibles de développer une maladie cardiaque. On peut donc conclure qu'il existe un lien de causalité direct entre la consommation de café et les maladies cardiaques. Cependant, nous devons être conscients de la présence de facteurs confondants. Par exemple, supposons que les buveurs de café soient également plus susceptibles d’être fumeurs. Le tabagisme lui-même est lié aux maladies cardiaques. Par conséquent, nous ne pouvons pas simplement attribuer la relation entre la consommation de café et les maladies cardiaques à un lien de causalité, mais cela pourrait être dû à la présence du tabagisme comme facteur de confusion. Pour étudier plus précisément la relation entre la consommation de café et les maladies cardiaques, nous devons contrôler les effets du tabagisme. Une approche consiste à mener des études par paires, dans lesquelles les fumeurs sont jumelés à des non-fumeurs, puis comparés pour déterminer la relation entre la consommation de café et les maladies cardiaques. Cela élimine l’effet confondant du tabagisme sur les résultats. La causalité est une question de savoir si, c'est-à-dire si un changement dans la consommation de café entraîne une modification des maladies cardiaques, les autres conditions restant inchangées. Ce n’est qu’après avoir contrôlé les effets des facteurs de confusion que nous pourrons déterminer plus précisément s’il existe une relation causale entre la consommation de café et les maladies cardiaques.
Comment éviter ce problème ? Une méthode courante consiste à introduire des données non biaisées et à utiliser des données non biaisées pour aider le modèle à apprendre des représentations non biaisées. Une autre méthode consiste à partir du point de vue des diagrammes de causalité et à corriger l'écart en ajustant l'observation ; données plus tard. La correction causale consiste à traiter des données ou des modèles par des moyens causals pour supprimer l'influence des biais.
4. Diagramme de cause à effet
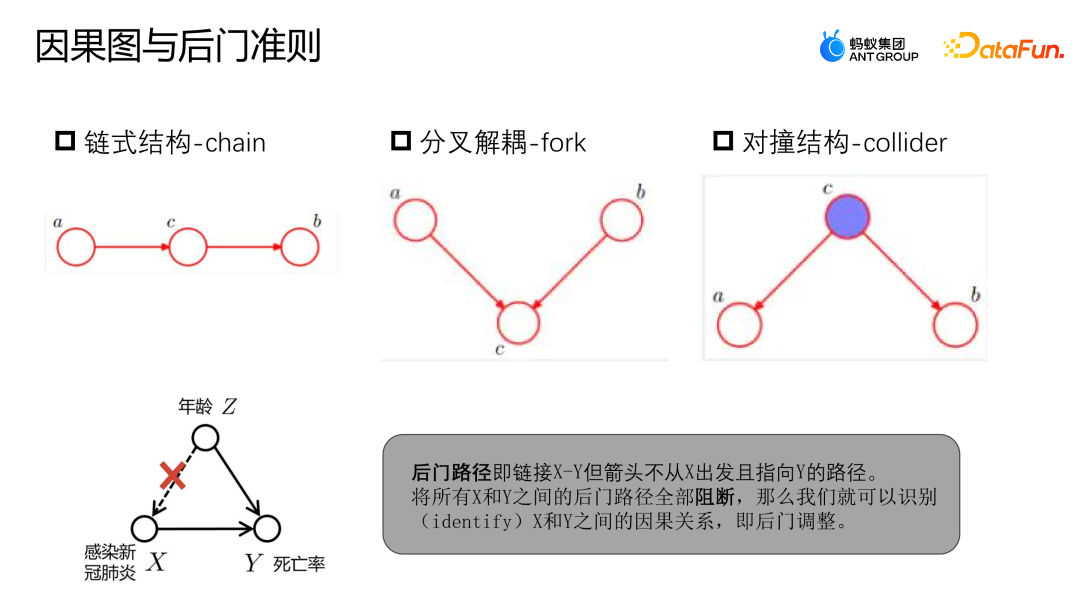
Un diagramme de cause à effet est un graphe acyclique orienté utilisé pour décrire la relation causale entre les nœuds de la scène. Il se compose d’une structure en chaîne, d’une structure bifurquée et d’une structure de collision.
- Structure de la chaîne : étant donné que C, A et B sont indépendants.
- Structure bifurquée : Étant donné C, si A change, B ne changera pas en conséquence.
- Structure de collision : En l'absence de C, on ne peut pas observer que A et B sont indépendants mais après avoir observé C, A et B ne sont pas indépendants ;
Vous pouvez vous référer à l'exemple de l'image ci-dessus pour déterminer le chemin de la porte dérobée et les critères de la porte dérobée. Le chemin de porte dérobée fait référence au chemin qui relie X à Y, mais commence à partir de Z et pointe finalement vers Y. À l’instar de l’exemple précédent, la relation entre l’infection au COVID-19 et la mortalité n’est pas purement causale. L’infection au COVID-19 dépend de l’âge. Les personnes âgées sont plus susceptibles d’être infectées par le COVID-19 et leur taux de mortalité est également plus élevé. Cependant, si nous disposons de suffisamment de données pour bloquer tous les chemins de porte dérobée entre X et Y, c'est-à-dire étant donné Z, alors X et Y peuvent être modélisés comme des relations indépendantes, afin que nous puissions obtenir la véritable relation causale.
2. Correction basée sur la fusion de données
1. Introduction au modèle de correction de fusion de données
Ce qui suit présente le travail de l'équipe Ant basé sur la correction de fusion de données , qui a été publié dans SIGIR2023 sur Industry Track. L'idée du travail est d'utiliser des données impartiales pour augmenter les données et guider la correction du modèle.

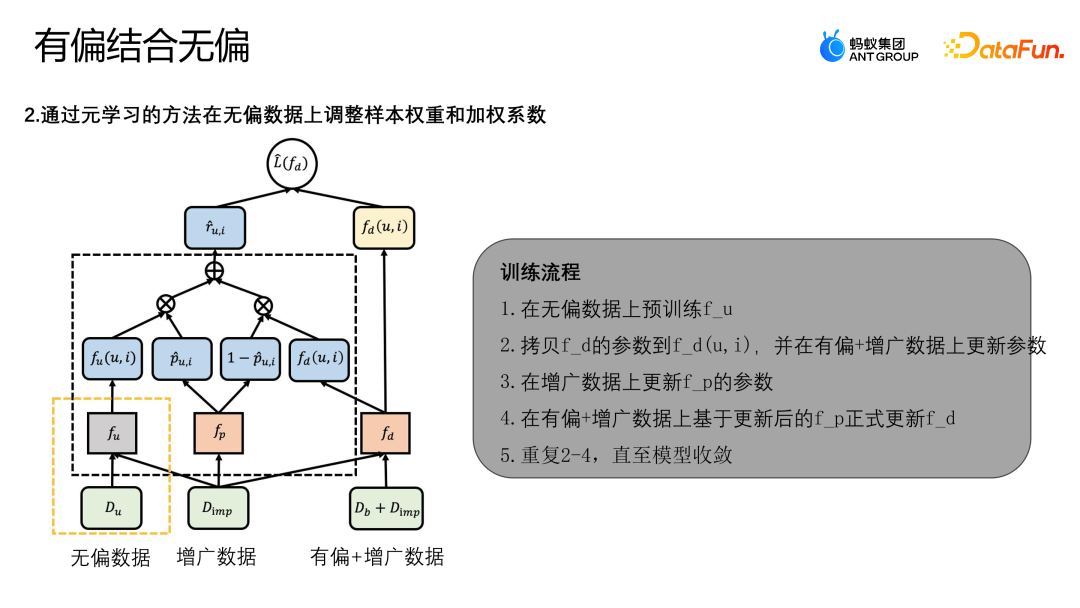
La distribution globale des données non biaisées est différente de celle des données biaisées. Les données biaisées seront concentrées dans une certaine partie de l'ensemble de l'espace échantillon, et les échantillons manquants seront concentrés dans une partie de la zone. avec des données relativement moins biaisées. Par conséquent, si l'échantillon augmenté est proche d'une zone avec des zones plus non biaisées, alors les données non biaisées joueront plus de rôles ; plus de rôles. À cette fin, cet article conçoit un modèle MDI capable de mieux utiliser les données impartiales et biaisées pour augmenter les données.

La figure ci-dessus montre le schéma cadre de l'algorithme. Le modèle MDI utilise la méthode de méta-apprentissage pour ajuster le poids de l'échantillon et le coefficient pondéré sur des données impartiales. Tout d'abord, il y a deux étapes dans la formation du modèle MDI :
- Phase 1 : Utiliser des données impartiales pour former le modèle d'enseignant impartial fu.
- Étape 2 : Utilisez la méthode d'apprentissage originale pour mettre à jour d'autres structures dans le diagramme schématique.
Formez le modèle de débiasage de fusion fd en optimisant la perte d'exploitation de L(fd). La perte finale a principalement deux types, l'un est L-IPS et l'autre est L-IMP. L-IPS est un module IPS que nous utilisons pour l'optimisation à l'aide d'échantillons originaux ; R-UI utilise n'importe quel modèle pour dériver le score de propension (déterminant la probabilité qu'un échantillon appartienne à un échantillon non biaisé ou la probabilité qu'il appartienne à un échantillon biaisé). ; le deuxième élément L-IMP est le poids du module d'augmentation prédéfini, R-UI est l'indice de queue généré par le module d'augmentation prédéfini et 1-P-UI sont le modèle d'enseignant impartial et le modèle de fusion dans le courant ; échantillon. Le score de propension de la méthode à apprendre des informations de modèle plus complexes, fp, est résolu grâce au méta-apprentissage.
Ce qui suit est le processus de formation complet de l'algorithme :
- Pré-entraîner le fu sur des données impartiales.
- Copiez les paramètres de fd dans fd(u,i) et mettez à jour les paramètres sur les données biaisées + augmentées.
- Mettre à jour les paramètres de fp sur les données augmentées.
- Mise à jour officiellement de fd en fonction du fp mis à jour sur des données biaisées + augmentées.
- Répétez 2 à 4 jusqu'à ce que le modèle converge.
2. Expérience sur le modèle de correction de fusion de données
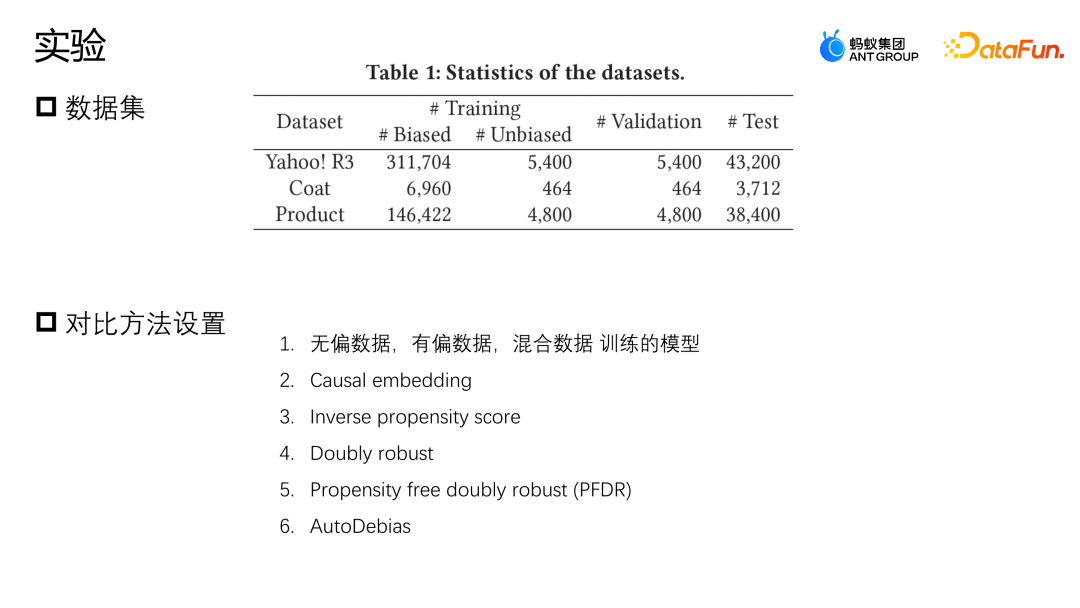
Nous avons effectué une évaluation sur deux ensembles de données publics, Yahoo R3 et Coat. Yahoo R3 a collecté plus de 15 000 évaluations d'utilisateurs sur 1 000 chansons et un total de plus de 310 000 données biaisées et 5 400 données impartiales. L'ensemble de données Coat collecte plus de 6 900 données biaisées et plus de 4 600 données impartiales grâce aux évaluations de 290 utilisateurs sur 300 vêtements. Les notes des utilisateurs dans les deux ensembles de données vont de 1 à 5. Les données biaisées proviennent des utilisateurs de données de la plateforme, et les échantillons impartiaux sont collectés en sélectionnant et en notant les utilisateurs au hasard.
En plus de deux ensembles de données publiques, Ant a également utilisé un ensemble de données provenant de scénarios réels dans l'industrie Afin de simuler la situation où il y a très peu d'échantillons de données impartiaux, nous avons combiné toutes les données biaisées et 10 % des données. données impartiales Pour la formation, 10 % des données impartiales sont conservées à titre de validation et les 80 % restants sont utilisés comme ensemble de test.Les méthodes de comparaison de base que nous utilisons sont principalement les suivantes : la première méthode consiste à utiliser respectivement des modèles formés par des données non biaisées, des données à biais unique et une fusion de données directe ; une représentation régulière est conçue pour contraindre la similarité des représentations de données biaisées et de données non biaisées afin d'effectuer des opérations de correction de biais ; la troisième méthode est la méthode de pondération de probabilité inverse, une probabilité inverse du score de propension ; Le double robustesse est également une méthode de correction courante ; le double robustesse sans propension est une méthode d'augmentation des données, qui utilise d'abord des échantillons non biaisés pour apprendre un modèle augmenté, puis utilise les échantillons augmentés pour aider l'ensemble du modèle à corriger le biais. données impartiales à augmenter pour aider à corriger les biais du modèle.
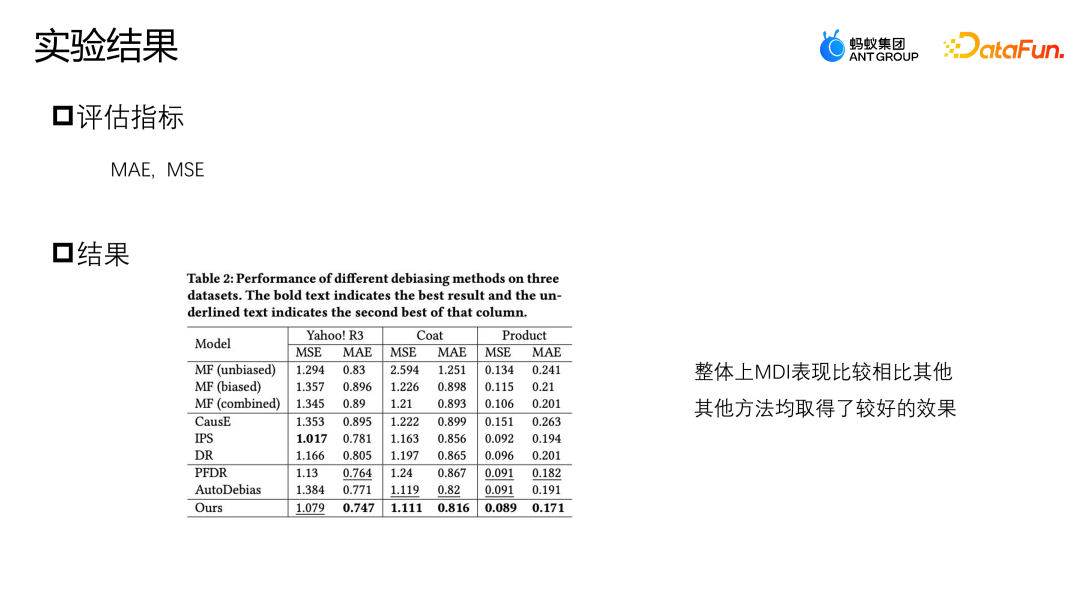
Sur le jeu de données Yahoo R3, la méthode que nous avons proposée présente le meilleur indice de performance sur MAE, et la meilleure performance sur MSE hors IPS. Les trois méthodes d'augmentation des données, PFDR, Auto Debias et notre MDI proposé, fonctionneront mieux dans la plupart des cas. Cependant, étant donné que PFDR utilise des données impartiales pour entraîner le modèle augmenté à l'avance, il s'appuiera donc fortement sur la qualité des données impartiales. ne dispose que de 464 échantillons de données d'entraînement non biaisés sur le modèle Coat. Lorsqu'il y a moins d'échantillons non biaisés, son module d'augmentation sera médiocre et les performances des données seront relativement médiocres.
 AutoDebias fonctionne exactement à l'opposé de PFDR sur différentes données. Étant donné que MDI a conçu une méthode d'augmentation qui utilise à la fois des données impartiales et des données biaisées, il dispose d'un module d'augmentation de données plus puissant, de sorte qu'il peut être obtenu dans les deux cas lorsqu'il y a moins de données impartiales ou lorsqu'il y a suffisamment de données impartiales.
AutoDebias fonctionne exactement à l'opposé de PFDR sur différentes données. Étant donné que MDI a conçu une méthode d'augmentation qui utilise à la fois des données impartiales et des données biaisées, il dispose d'un module d'augmentation de données plus puissant, de sorte qu'il peut être obtenu dans les deux cas lorsqu'il y a moins de données impartiales ou lorsqu'il y a suffisamment de données impartiales.
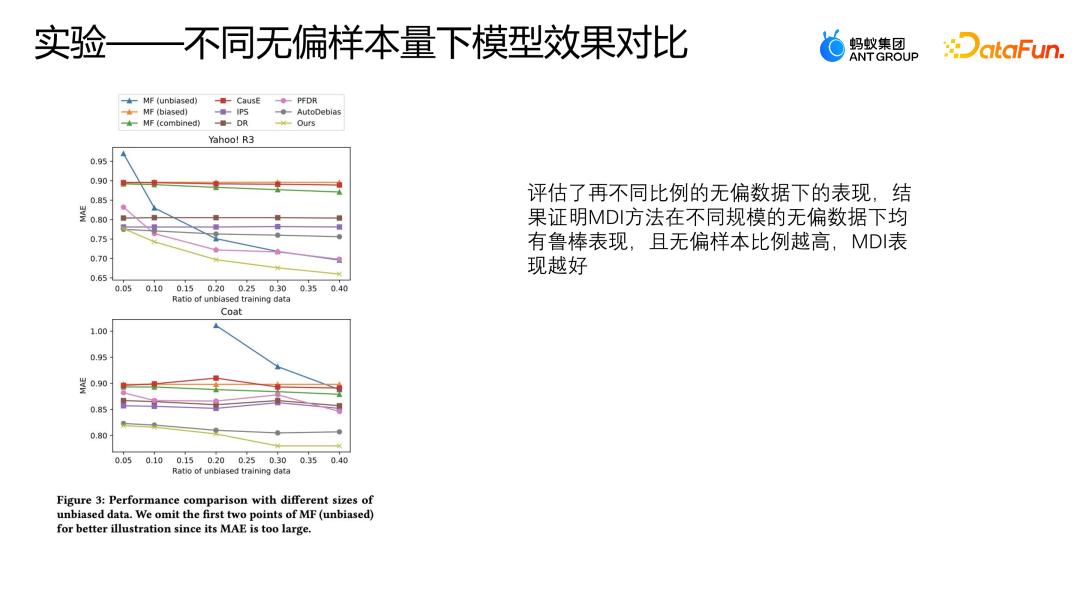
Nous avons également évalué les performances de ces modèles sous différentes proportions de données impartiales sur deux ensembles de données publiques, en utilisant respectivement 50 % à 40 % de données impartiales et toutes les données biaisées pour la formation. Autres La logique est vérifiée avec les premiers 10 % de. les données impartiales et les données restantes sont testées. Ce paramètre est le même que l'expérience précédente.
La figure ci-dessus montre les performances du MAE en utilisant différentes méthodes sous différentes proportions de données impartiales. L'abscisse représente la proportion de données impartiales, et l'ordonnée représente l'effet de chaque méthode sur les données impartiales. les données augmentent, À mesure que la proportion de données partielles augmente, le MAE d'AutoDebias, IPS et DoubleRubus n'a pas de processus de déclin évident. Cependant, au lieu de suivre la méthode Debias, la méthode consistant à utiliser directement la fusion de données originales pour apprendre connaîtra un déclin significatif, car plus la proportion d'échantillon de données non biaisées est élevée, meilleure est la qualité globale de nos données, de sorte que le modèle peut apprendre. Meilleure performance.
Lorsque les données Yahoo R3 utilisent plus de 30 % de données impartiales pour la formation,
Cette méthode surpasse même toutes les autres méthodes de correction des biais, à l'exception du MDI. Cependant, la méthode MDI peut obtenir des performances relativement meilleures, ce qui peut également prouver que la méthode MDI donne des résultats relativement robustes avec des données impartiales de différentes tailles.
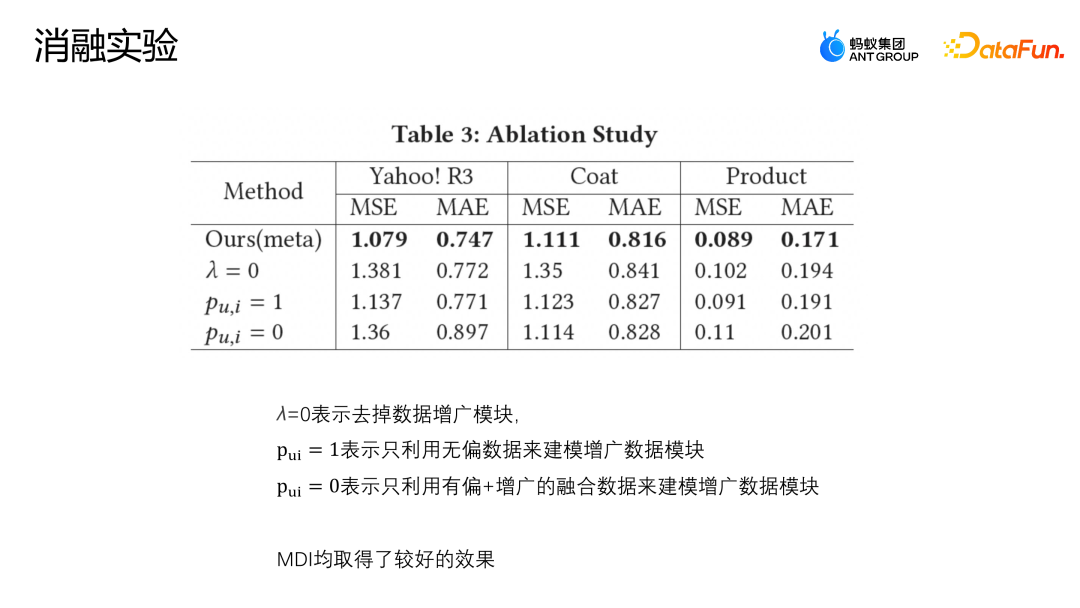
Die Einstellung λ=0 bedeutet, dass das erweiterte Modul direkt entfernt wird; Pu,i = 1 bedeutet, dass nur unverzerrte Daten zur Modellierung des erweiterten Datenmoduls verwendet werden; Pu,i = 0 bedeutet, dass nur verzerrte und erweiterte fusionierte Daten verwendet werden Wird zum Aufbau des Modells verwendet. Die obige Abbildung zeigt die Ergebnisse des Ablationsexperiments. Es ist ersichtlich, dass die MDI-Methode bei den drei Datensätzen relativ gute Ergebnisse erzielt hat, was darauf hinweist, dass das Erweiterungsmodul erforderlich ist. Ob es sich um öffentliche Datensätze oder Datensätze in tatsächlichen Geschäftsszenarien handelt, die von uns vorgeschlagene Erweiterungsmethode zur Zusammenführung unvoreingenommener und voreingenommener Daten liefert bessere Ergebnisse als frühere Datenfusionslösungen, und die Robustheit von MDI wurde auch durch Parameter überprüft Sensitivitätsexperimente und Ablationsexperimente.
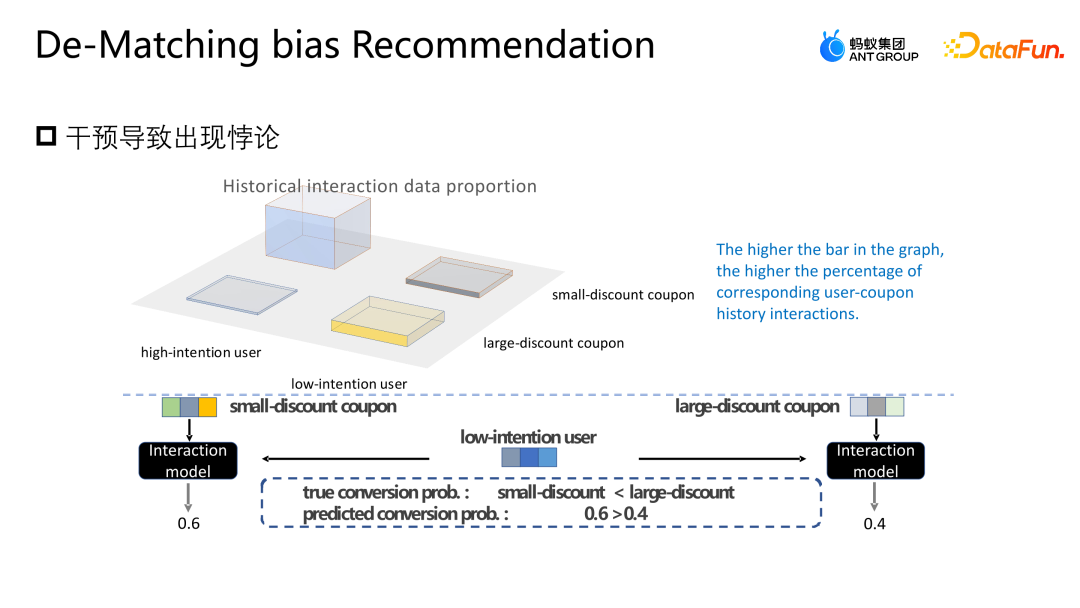
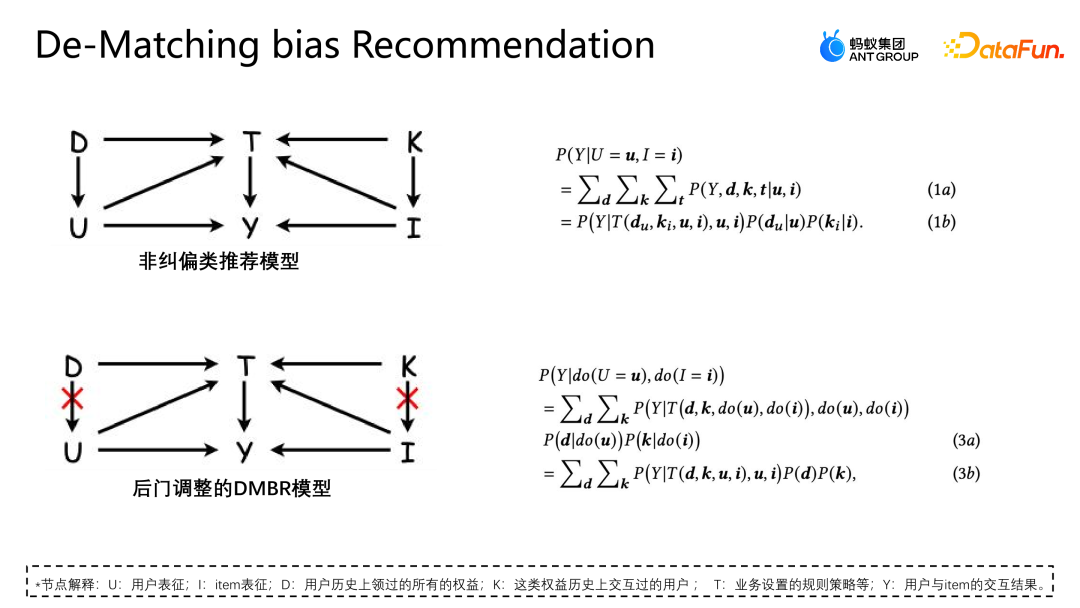
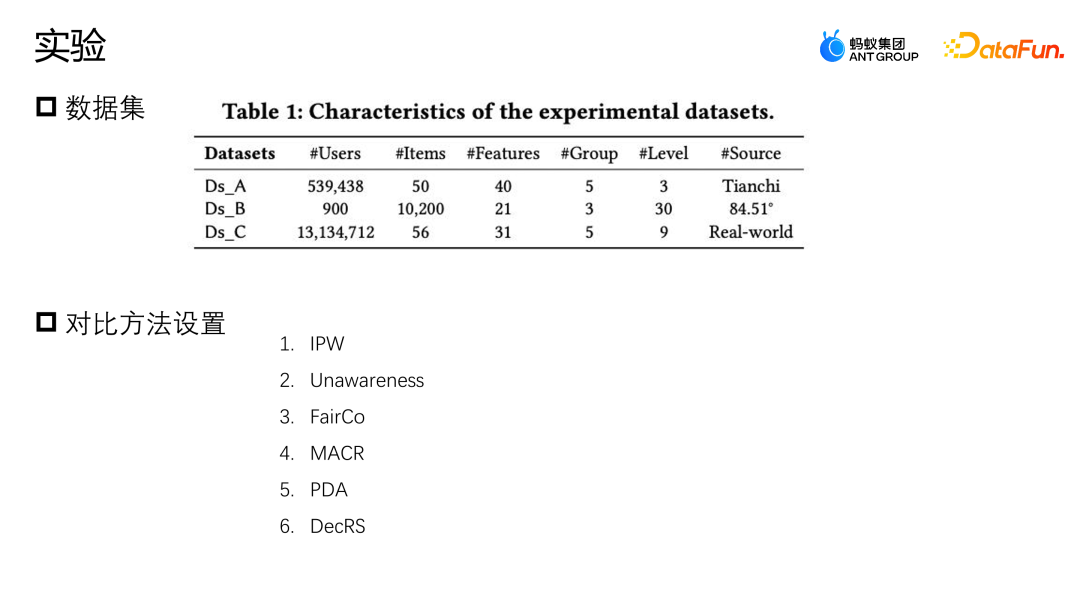
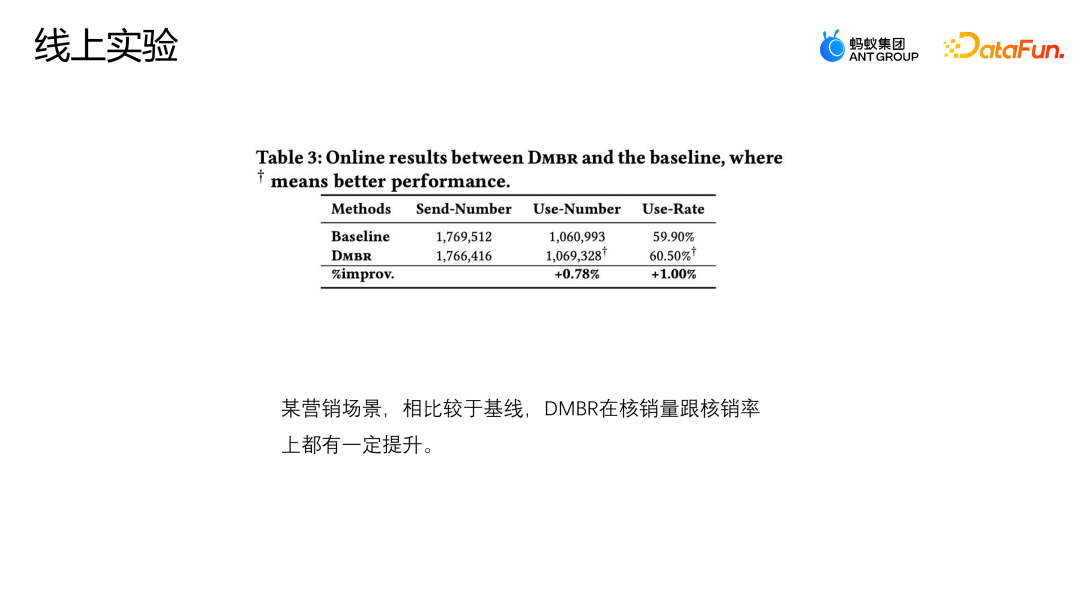
Lassen Sie uns eine weitere Arbeit des Teams vorstellen: Korrektur basierend auf der Hintertür-Anpassung. Diese Arbeit wurde auch auf dem Industry Track von SIGIR2023 veröffentlicht. Das Szenario der Hintertür-Anpassung und -Korrekturanwendung ist das Szenario der Marketingempfehlung. Wie in der folgenden Abbildung dargestellt, besteht keine gleiche Möglichkeit für die Interaktion zwischen dem Benutzer und dem Coupon oder dem Benutzer und einer Werbung oder einem Artikel jeder Interaktion, und jeder Coupon hat auch die gleiche Chance, jedem Benutzer angezeigt zu werden. Aber in tatsächlichen Geschäftsszenarien werden in der Regel eine Reihe von Richtlinienbeschränkungen eingerichtet, um einige kleine Händler zu schützen oder ihnen zu helfen, den Datenverkehr zu erhöhen Bestimmte Coupons werden stärker exponiert, und eine andere Gruppe von Benutzern wird stärker einem anderen Coupon ausgesetzt. Diese Art von Intervention ist der oben erwähnte Mitbegründer. Welche Probleme wird diese Art von Intervention im E-Commerce-Marketing-Szenario verursachen? Wie in der Abbildung oben gezeigt, teilen wir die Benutzer der Einfachheit halber einfach in zwei Kategorien ein: hohe Teilnahmebereitschaft und niedrige Teilnahmebereitschaft, und Gutscheine in zwei Kategorien: große Rabatte und kleine Rabatte. Die Höhe des Histogramms in der Abbildung stellt den globalen Anteil der entsprechenden Stichprobe dar. Je höher das Histogramm, desto größer ist der Anteil der entsprechenden Stichprobe an den gesamten Trainingsdaten. Die in der Abbildung gezeigten kleinen Rabattcoupons und Benutzerproben mit hoher Teilnahmeabsicht machen den Großteil aus, was dazu führt, dass das Modell die in der Abbildung gezeigte Verteilung lernt. Das Modell geht davon aus, dass Benutzer mit hoher Teilnahmeabsicht kleine Rabattcoupons bevorzugen. Tatsächlich werden Benutzer jedoch bei gleicher Nutzungsschwelle definitiv Gutscheine mit höheren Rabatten bevorzugen, damit sie mehr Geld sparen können. Das Modell im Bild zeigt, dass die tatsächliche Umwandlungswahrscheinlichkeit kleiner Rabattgutscheine geringer ist als die großer Rabattgutscheine. Die Schätzung des Modells für eine bestimmte Stichprobe geht jedoch davon aus, dass die Abschreibungswahrscheinlichkeit kleiner Rabattgutscheine höher ist Das Modell wird diese Punktzahl auch empfehlen, was ein Paradoxon darstellt. Analysieren Sie die Gründe für dieses Paradoxon aus der Perspektive eines Kausaldiagramms. Die Struktur des Kausaldiagramms ist in der Abbildung oben dargestellt und ich repräsentiert die Charakterisierung. D und K sind die historischen Wechselwirkungen zwischen der Benutzerperspektive bzw. der Eigenkapitalperspektive. T stellt einige durch das aktuelle Geschäft festgelegte Regelbeschränkungen dar. T kann nicht direkt quantifiziert werden, aber wir können seine Auswirkungen auf Benutzer und Elemente durch D und K erkennen. Auswirkungen. y stellt die Interaktion zwischen dem Benutzer und dem Artikel dar. Das Ergebnis ist, ob der Artikel angeklickt, abgeschrieben usw. wird. Die durch das Kausaldiagramm dargestellte bedingte Wahrscheinlichkeitsformel ist oben rechts in der Abbildung dargestellt. Die Ableitung der Formel folgt der Bayes'schen Wahrscheinlichkeitsformel. Unter den gegebenen Bedingungen von U und I hängt die endgültige Ableitung von P | besteht auch aus. Wenn ich gegeben werde, werde ich auf die gleiche Weise von Ki beeinflusst. Der Grund für diese Situation ist, dass die Existenz von D und K zur Existenz von Hintertürpfaden in der Szene führt. Das heißt, ein Backdoor-Pfad, der nicht bei U beginnt, sondern schließlich auf y zeigt (U-D-T-Y- oder I-K-T-Y-Pfad), stellt ein falsches Konzept dar, das heißt, U kann nicht nur y über T, sondern auch y über D beeinflussen. Die Anpassungsmethode besteht darin, den Weg von D nach U künstlich abzuschneiden, sodass U y nur über U-T-Y und U-Y direkt beeinflussen kann. Diese Methode kann falsche Korrelationen entfernen und den wahren Kausalzusammenhang modellieren. Die Hintertüranpassung besteht darin, eine Do-Berechnung für die Beobachtungsdaten durchzuführen und dann den Do-Operator zu verwenden, um die Leistung aller D und aller K zu aggregieren, um zu verhindern, dass U und I durch D und K beeinflusst werden. Auf diese Weise wird eine echte Ursache-Wirkungs-Beziehung modelliert. Die abgeleitete Näherungsform dieser Formel ist in der folgenden Abbildung dargestellt. 4a ist die gleiche Form wie das vorherige 3b, und 4b ist eine Näherung des Probenraums. Da der Probenraum von D und K theoretisch unendlich ist, kann eine Annäherung nur durch die gesammelten Daten erfolgen (D und K des Probenraums nehmen eine Größe an). 4c und 4d sind beide Ableitungen der gewünschten Näherung, so dass letztendlich nur eine zusätzliche erwartungstreue Darstellung T modelliert werden muss. T ist ein zusätzliches Modell der unverzerrten Darstellung T, indem die Summe der Darstellungswahrscheinlichkeitsverteilungen von Benutzern und Elementen in allen Situationen durchlaufen wird, um dem Modell dabei zu helfen, die endgültige erwartungstreue Datenschätzung zu erhalten. Das Experiment verwendet zwei Open-Source-Datensätze, Tianchi- und 84,51-(Coupon-)Datensätze. Simulieren Sie die Auswirkungen dieser Regelstrategie auf die Gesamtdaten durch Stichproben. Gleichzeitig wurden Daten aus einem realen E-Commerce-Marketing-Aktivitätsszenario genutzt, um gemeinsam die Qualität des Algorithmus zu bewerten. Wir haben einige gängige Korrekturmethoden verglichen, wie z. B. IPW, das die Auswirkungen von Bias durch die Entfernung von Bias-Merkmalen korrigiert. MACR verwendet mehrere Fehlerterm-Einschränkungen Die Aufgabe schätzt die Konsistenz des Benutzers bzw. die Beliebtheit des Elements und subtrahiert die Konsistenz und Beliebtheit in der Vorhersagephase, um eine unvoreingenommene Schätzung zu erzielen. Der PDA entfernt die Beliebtheit durch kausale Intervention Hintertür-Anpassung, um Informationsverzerrungen zu beseitigen, aber sie korrigiert nur die Verzerrung der Benutzerperspektive. Der Bewertungsindex des Experiments ist AUC. Da es im Marketing-Promotion-Szenario nur einen empfohlenen Coupon oder ein Empfehlungskandidatenprodukt gibt, handelt es sich im Wesentlichen um ein Problem mit zwei Klassifizierungen. Daher ist es angemessener, AUC zur Bewertung zu verwenden . Beim Vergleich der Leistung von DNN und MMOE unter verschiedenen Architekturen ist ersichtlich, dass das von uns vorgeschlagene DMBR-Modell bessere Ergebnisse liefert als die ursprüngliche Nichtkorrekturmethode und andere Korrekturmethoden. Gleichzeitig haben Ds_A und Ds_B einen größeren Verbesserungseffekt auf den simulierten Datensatz als auf den realen Geschäftsdatensatz erzielt. Dies liegt daran, dass die Daten im realen Geschäftsdatensatz komplexer sind und nicht nur von Regeln beeinflusst werden und Richtlinien, sondern können auch durch andere Faktoren beeinflusst werden. Derzeit wurde das Modell in einem E-Commerce-Marketing-Event-Szenario eingeführt. Die obige Abbildung zeigt den Online-Effekt. Im Vergleich zum Basismodell weist das DMBR-Modell eine gewisse Verbesserung der Abschreibungsrate auf Verkaufsvolumen.
3. Korrektur basierend auf der Hintertür-Anpassung



4. Anwendung in Ant Es können Einschränkungen festgelegt werden. Was die Zielgruppe der Werbung betrifft, so werden einige auf Haustiere ausgerichtete Anzeigen mit größerer Wahrscheinlichkeit an Nutzer geschaltet, die Haustiere haben. Im E-Commerce-Marketing-Szenario werden einige Strategien entwickelt, um den Traffic kleiner Händler sicherzustellen und zu vermeiden, dass der gesamte Traffic von großen Händlern verbraucht wird. Da das Gesamtbudget der Aktivität begrenzt ist, wird nicht nur das Benutzererlebnis bei der Teilnahme an Aktivitäten sichergestellt, sondern auch eine große Menge an Ressourcen beansprucht, wenn einige skrupellose Benutzer wiederholt an der Aktivität teilnehmen, was zu einem schlechten Erlebnis bei der Teilnahme an Aktivitäten führt andere Benutzer. In solchen Szenarien gibt es Anwendungen zur Ursache-Wirkungs-Korrektur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment implémenter un système de recommandation en utilisant le langage Go et Redis
Oct 27, 2023 pm 12:54 PM
Comment implémenter un système de recommandation en utilisant le langage Go et Redis
Oct 27, 2023 pm 12:54 PM
Comment utiliser le langage Go et Redis pour mettre en œuvre un système de recommandation. Le système de recommandation est un élément important de la plate-forme Internet moderne. Il aide les utilisateurs à découvrir et à obtenir des informations intéressantes. Le langage Go et Redis sont deux outils très populaires qui peuvent jouer un rôle important dans le processus de mise en œuvre de systèmes de recommandation. Cet article expliquera comment utiliser le langage Go et Redis pour implémenter un système de recommandation simple et fournira des exemples de code spécifiques. Redis est une base de données open source en mémoire qui fournit une interface de stockage de paires clé-valeur et prend en charge une variété de données
 Algorithmes et applications du système de recommandation implémentés en Java
Jun 19, 2023 am 09:06 AM
Algorithmes et applications du système de recommandation implémentés en Java
Jun 19, 2023 am 09:06 AM
Avec le développement et la vulgarisation continus de la technologie Internet, les systèmes de recommandation, en tant que technologie importante de filtrage des informations, sont de plus en plus largement utilisés et pris en compte. En termes de mise en œuvre d'algorithmes de système de recommandation, Java, en tant que langage de programmation rapide et fiable, a été largement utilisé. Cet article présentera les algorithmes et les applications du système de recommandation implémentés en Java, et se concentrera sur trois algorithmes de système de recommandation courants : l'algorithme de filtrage collaboratif basé sur l'utilisateur, l'algorithme de filtrage collaboratif basé sur les éléments et l'algorithme de recommandation basé sur le contenu. L'algorithme de filtrage collaboratif basé sur l'utilisateur est basé sur le filtrage collaboratif basé sur l'utilisateur
 Exemple d'application : utilisez go-micro pour créer un système de recommandation de microservices
Jun 18, 2023 pm 12:43 PM
Exemple d'application : utilisez go-micro pour créer un système de recommandation de microservices
Jun 18, 2023 pm 12:43 PM
Avec la popularité des applications Internet, l’architecture des microservices est devenue une méthode d’architecture populaire. Parmi eux, la clé de l'architecture des microservices est de diviser l'application en différents services et de communiquer via RPC pour obtenir une architecture de services faiblement couplée. Dans cet article, nous présenterons comment utiliser go-micro pour créer un système de recommandation de microservices basé sur des cas réels. 1. Qu'est-ce qu'un système de recommandation de microservices ? Un système de recommandation de microservices est un système de recommandation basé sur une architecture de microservices qui intègre différents modules dans le système de recommandation (tels que l'ingénierie des fonctionnalités, la classification).
 Le secret d'une recommandation précise : explication détaillée du modèle de rappel impartial d'adaptation de domaine découplé d'Alibaba
Jun 05, 2023 am 08:55 AM
Le secret d'une recommandation précise : explication détaillée du modèle de rappel impartial d'adaptation de domaine découplé d'Alibaba
Jun 05, 2023 am 08:55 AM
1. Introduction au scénario Tout d’abord, introduisons le scénario impliqué dans cet article : le scénario « de bons produits sont disponibles ». Son emplacement se trouve dans la grille à quatre carrés de la page d'accueil de Taobao, qui est divisée en une page de sélection à un saut et une page d'acceptation à deux sauts. Il existe deux formes principales de pages d'hébergement, l'une est une page d'hébergement de graphiques et de textes, et l'autre est une courte page d'hébergement de vidéos. L’objectif de ce scénario est principalement de fournir aux utilisateurs des biens satisfaisants et de stimuler la croissance du GMV, exploitant ainsi davantage l’offre d’experts. 2. Qu'est-ce que le biais de popularité et pourquoi nous abordons ensuite le sujet de cet article, le biais de popularité. Qu’est-ce que le biais de popularité ? Pourquoi un biais de popularité se produit-il ? 1. Qu'est-ce que le biais de popularité ? Le biais de popularité a de nombreux alias, tels que l'effet Matthew et le cocon d'information. Intuitivement, il s'agit d'un carnaval de produits hautement explosifs. Cela entraînera
 Comment le langage Go implémente-t-il les systèmes de recherche et de recommandation dans le cloud ?
May 16, 2023 pm 11:21 PM
Comment le langage Go implémente-t-il les systèmes de recherche et de recommandation dans le cloud ?
May 16, 2023 pm 11:21 PM
Avec le développement et la vulgarisation continus de la technologie du cloud computing, les systèmes de recherche et de recommandation dans le cloud deviennent de plus en plus populaires. En réponse à cette demande, le langage Go apporte également une bonne solution. Dans le langage Go, nous pouvons utiliser ses capacités de traitement simultané à grande vitesse et ses riches bibliothèques standard pour mettre en œuvre un système efficace de recherche et de recommandation dans le cloud. Ce qui suit présentera comment le langage Go implémente un tel système. 1. Recherche sur le cloud Tout d'abord, nous devons comprendre la posture et les principes de la recherche. La posture de recherche fait référence aux pages correspondantes du moteur de recherche en fonction des mots-clés saisis par l'utilisateur.
 Système de recommandation pour la technologie de démarrage à froid NetEase Cloud Music
Nov 14, 2023 am 08:14 AM
Système de recommandation pour la technologie de démarrage à froid NetEase Cloud Music
Nov 14, 2023 am 08:14 AM
1. Contexte du problème : la nécessité et l'importance de la modélisation du démarrage à froid. En tant que plate-forme de contenu, Cloud Music propose chaque jour une grande quantité de nouveaux contenus. Bien que la quantité de nouveau contenu sur la plate-forme musicale cloud soit relativement faible par rapport à d'autres plates-formes telles que les courtes vidéos, la quantité réelle peut dépasser de loin l'imagination de chacun. Dans le même temps, le contenu musical est très différent des courtes vidéos, des actualités et des recommandations de produits. Le cycle de vie de la musique s’étend sur des périodes extrêmement longues, souvent mesurées en années. Certaines chansons peuvent exploser après avoir été inactives pendant des mois ou des années, et les chansons classiques peuvent encore avoir une forte vitalité même après plus de dix ans. Par conséquent, pour le système de recommandation des plateformes musicales, il est plus important de découvrir des contenus impopulaires et de longue traîne de haute qualité et de les recommander aux bons utilisateurs que de recommander d'autres catégories.
 Application de la méthode de correction de cause à effet dans le scénario de recommandation Ant Marketing
Jan 13, 2024 pm 12:15 PM
Application de la méthode de correction de cause à effet dans le scénario de recommandation Ant Marketing
Jan 13, 2024 pm 12:15 PM
1. Contexte de la correction de cause à effet 1. Un écart se produit dans le système de recommandation. Des données sont collectées pour entraîner le modèle de recommandation à recommander les éléments appropriés aux utilisateurs. Lorsque les utilisateurs interagissent avec les éléments recommandés, les données collectées sont utilisées pour entraîner davantage le modèle, formant ainsi une boucle fermée. Cependant, il peut y avoir divers facteurs d'influence dans cette boucle fermée, entraînant des erreurs. La principale raison de l'erreur est que la plupart des données utilisées pour entraîner le modèle sont des données d'observation plutôt que des données d'entraînement idéales, qui sont affectées par des facteurs tels que la stratégie d'exposition et la sélection des utilisateurs. L’essence de ce biais réside dans la différence entre les attentes des estimations empiriques du risque et les attentes des véritables estimations du risque idéal. 2. Biais courants Il existe trois principaux types de biais courants dans les systèmes de marketing de recommandation : Biais sélectif : il est dû à la racine de l'utilisateur.
 Système de recommandation et technologie de filtrage collaboratif en PHP
May 11, 2023 pm 12:21 PM
Système de recommandation et technologie de filtrage collaboratif en PHP
May 11, 2023 pm 12:21 PM
Avec le développement rapide d’Internet, les systèmes de recommandation sont devenus de plus en plus importants. Un système de recommandation est un algorithme utilisé pour prédire les éléments intéressant un utilisateur. Dans les applications Internet, les systèmes de recommandation peuvent fournir des suggestions et des recommandations personnalisées, améliorant ainsi la satisfaction des utilisateurs et les taux de conversion. PHP est un langage de programmation largement utilisé dans le développement Web. Cet article explorera les systèmes de recommandation et la technologie de filtrage collaboratif en PHP. Principes des systèmes de recommandation Les systèmes de recommandation s'appuient sur des algorithmes d'apprentissage automatique et l'analyse des données. Ils analysent et prédisent le comportement historique des utilisateurs.
