

| Présentation | Dans l'environnement de base de données optimisé par DBA, la plupart des problèmes de performances sont en réalité causés par une écriture SQL incorrecte. Le monde de SQL regorge de merveilles. Aujourd'hui, nous allons jeter un œil à un SQL qui tue et qui vous donnera envie de vomir du sang. |
Pour un client d'assurance, ETL a pris plusieurs heures. Nous avons fait un rapport SQL et avons constaté que la pression était principalement sur l'un des SQL.
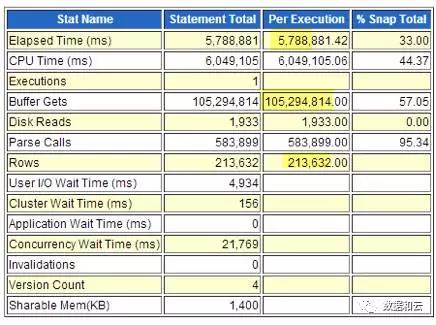
Temps d'exécution unique : 5788 (secondes)
Lecture logique unique : 1 milliard (blocs)
Nombre de lignes renvoyées à la fois : 210 000 (lignes)
Regardons d'abord l'instruction SQL Parce qu'elle est assez longue, nous n'en extrayons qu'une partie ici
.
Voir son plan d'exécution :
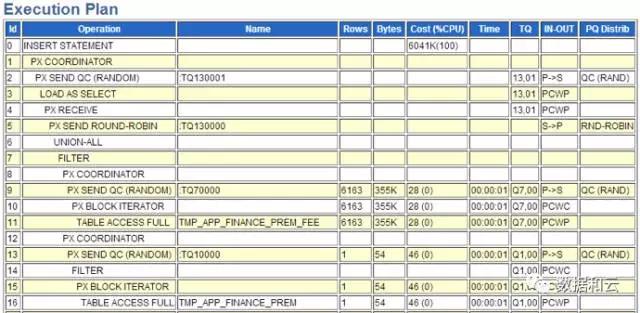
Nous nous concentrons principalement sur les lignes 7 à 16 : nous avons constaté qu'il y a deux analyses de tableau complètes. Un filtre a été réalisé au milieu.
De nombreuses années d'expérience me disent que le filtre composé de deux analyses de table complètes présente de sérieux problèmes car il implique de traiter les données une par une. Dans ce plan d'exécution, la table pilotée est toujours analysée dans son intégralité.
Les opérations Not In/In produisent parfois des opérations de filtrage. Dans les versions antérieures à 11g, l'instruction not in doit être convertie en anti-jointure. La colonne de la condition not in doit avoir l'attribut Not null, ou not null doit être inclus. dans la déclaration Limit, sinon vous ne pouvez utiliser Filter que pour filtrer un par un.
Donnons un exemple :
Voir les propriétés de T_OBJ :

J'ai constaté qu'il n'y a aucune restriction de non null sur les trois colonnes.
Nous prétendons être un optimiseur 10G en ce moment.
SQL> modifier l'ensemble de session optimiseur_features_enable=”10.2.0.5″;
Exécutez le SQL suivant :
SQL> définir l'exp de trace automatique
SQL> SELECT * FROM T_TABLE WHERE TABLE_NAME NOT IN(SELECT OBJECT_NAME FROM T_OBJ);
En regardant le plan d'exécution à ce moment-là, nous avons constaté que le filtre est utilisé :
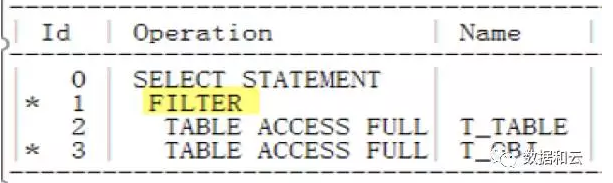
Mais dans la version 11g, l'optimiseur peut automatiquement convertir le filtre non opérationnel d'un filtre coûteux en Null-Aware-Anti-Join.
Si vous ajoutez une condition Non nulle ou définissez l'attribut de champ sur non nul
SQL> modifier la table T_OBJ modifier (OBJECT_NAME NOT NULL);
Exécutez à nouveau la même instruction :
SQL> SELECT * FROM T_TABLE WHERE TABLE_NAME
PAS DANS(SELECT OBJECT_NAME FROM T_OBJ
WHEREOBJECT_NAME N'EST PAS NULL);
Voir à nouveau le plan d'exécution :

À ce moment-là, nous avons constaté que dans le plan d'exécution, le hachage rejoint anti.
Et, en 11g, les colonnes non incluses sont autorisées sans restrictions non nulles, et Anti-Join peut également être converti.
SQL> modifier l'ensemble de session optimiseur_features_enable=”11.2.0.4″;
SQL> modifier la table T_OBJ modifier(OBJECT_NAME NULL);
SQ> SELECT * FROM T_TABLE WHERE TABLE_NAME
PAS DANS (SELECTOBJECT_NAMEFROM T_OBJ);
Voir le plan d'exécution :
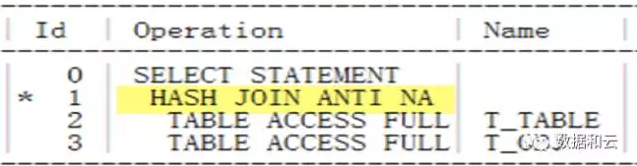
Nous voyons qu'à l'heure actuelle, hash join anti.
est également utilisé sans la restriction non vide.Cette fonctionnalité peut être contrôlée via les paramètres de l'optimiseur.
SQL>alter session set "_optimizer_null_aware_antijoin"=FALSE;
Exécutez à nouveau l'instruction ci-dessus et affichez le plan d'exécution :
SQL> SELECT * FROM T_TABLE WHERE TABLE_NAME
PAS DANS (SELECTOBJECT_NAMEFROM T_OBJ);
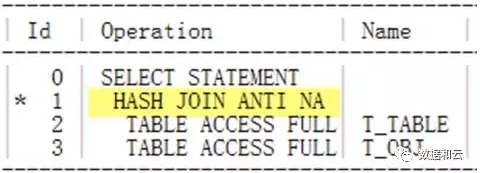
J'ai découvert que j'utilise toujours hash join anti.
Il a été vérifié qu'il n'y a pas de problème avec ce paramétrage
La logique deNot in est l'exclusion mutuelle entre les ensembles de résultats. En fait, il existe de nombreuses façons de la réécrire, telles que :
—N'existe pas
— La jointure externe + est nulle
—Moins
La différence entrenot in et les trois façons d'écrire ci-dessus est la suivante : not in exclura les valeurs nulles.
Nous essayons de réécrire.
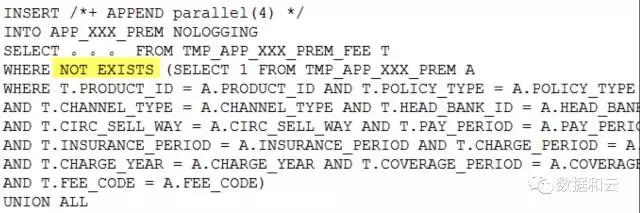
Puis, juste au moment où vous pensiez qu'un miracle allait se produire, la déclaration a signalé une erreur !

Pourquoi une erreur est-elle signalée ?
Si nous convertissons cette déclaration en not in :

Selon la logique de not in, 'A.' devrait être ajouté avant fee_code à ce moment-là. Bien sûr, ce n'est pas un problème, mais si vous regardez à nouveau cette déclaration, elle deviendra :
.
Comme il n'y a pas de champ FEE_CODE dans TMP_APP_xxx_PREM A, Not in ne peut pas être automatiquement modifié en Null Aware ANTI JOIN.
Alors, maintenant que la réponse est révélée, il s'est avéré que c'était une erreur ? ! J'ai deviné le début, mais pas la fin.
Mais dans ce cas, comme il n'y avait pas d'instruction explicite dans l'instruction SQL, cette erreur n'a jamais été découverte au cours du premier processus d'analyse.
Êtes-vous également sans voix ? En fait, ce que je veux demander de plus, c'est : écrivez-vous souvent du SQL qui tue ? Mais ce n'est pas grave si vous êtes malade, j'ai des médicaments. (Visage innocent, ne me frappe pas)
Nous savons tous que dans l'environnement de base de données optimisé par DBA, la grande majorité des problèmes de performances sont en réalité causés par une mauvaise écriture SQL.
Pour les systèmes qui ne sont pas en ligne, grâce à un audit et un contrôle SQL précoces, 80 % des problèmes SQL seront éliminés au stade naissant. Pour les systèmes fonctionnant en ligne, les problèmes de performances potentiels peuvent être découverts et résolus pour les éviter dans l'œuf.
L'audit SQL permet à l'administrateur de base de données de passer du statut de médecin urgentiste du système à celui de médecin de santé du système
1. DBA participe au processus de développement et de test du code d'application : Fournir aux développeurs des suggestions professionnelles de développement et d'optimisation de bases de données
2. Optimiser le front-end : Concevoir un SQL et un index efficaces en fonction des besoins de l'entreprise avant la mise en ligne du code de l'application
3. Contrôler les risques de changement : Pré-évaluer l'impact des modifications de la structure des tables et des modifications SQL pendant le développement de l'application sur les applications en cours d'exécution, et déterminer les fenêtres de modification et les plans de modification appropriés.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



